


By Chris McCormick and Nick Ryan
原文链接:tinyurl.com/y74pvgyc
介绍
历史
2018 年是 NLP 突破的一年,迁移学习、特别是 Allen AI 的 ELMO,OpenAI 的 Open-GPT,以及 Google 的 BERT,这些模型让研究者们刷新了多项任务的基线(benchmark),并提供了容易被微调预训练模型(只需很少的数据量和计算量),使用它们,可产出当今最高水平的结果。但是,对于刚接触 NLP 甚至很多有经验的开发者来说,这些强大模型的理论和应用并不是那么容易理解。
什么是 BERT
2018年底发布的BERT(Bidirectional Encoder Representations from Transformers)是我们在本教程中要用到的模型,目的是让读者更好地理解和指导读者在 NLP 中使用迁移学习模型。BERT是一种预训练语言表征的方法,NLP实践者可以免费下载并使用这些模型。你可以用这些模型从文本数据中提取高质量的语言特征,也可以用自己的数据对这些模型在特定的任务(分类、实体识别、问答问题等)上进行微调,以产生高质量的预测结果。
本文将解释如何修改和微调 BERT,以创建一个强大的 NLP 模型。
Fine-tuning 的优势
在本教程中,我们将使用BERT来训练一个文本分类器。具体来说,我们将采取预训练的 BERT 模型,在末端添加一个未训练过的神经元层,然后训练新的模型来完成我们的分类任务。为什么要这样做,而不是训练一个特定的深度学习模型(CNN、BiLSTM等)?
-
更快速的开发
首先,预训练的 BERT 模型权重已经编码了很多关于我们语言的信息。因此,训练我们的微调模型所需的时间要少得多——就好像我们已经对网络的底层进行了广泛的训练,只需要将它们作为我们的分类任务的特征,并轻微地调整它们就好。事实上,作者建议在特定的 NLP 任务上对 BERT 进行微调时,只需要 2-4 个 epochs 的训练(相比之下,从头开始训练原始 BERT 或 LSTM 模型需要数百个 GPU 小时)。
-
更少的数据
此外,也许同样重要的是,预训练这种方法,允许我们在一个比从头开始建立的模型所需要的数据集小得多的数据集上进行微调。从零开始建立的 NLP 模型的一个主要缺点是,我们通常需要一个庞大的数据集来训练我们的网络,以达到合理的精度,这意味着我们必须投入大量的时间和精力在数据集的创建上。通过对 BERT 进行微调,我们现在可以在更少的数据集上训练一个模型,使其达到良好的性能。
-
更好的结果
最后,这种简单的微调程过程(通常在 BERT 的基础上增加一个全连接层,并训练几个 epochs)被证明可以在广泛的任务中以最小的调节代价来实现最先进的结果:分类、语言推理、语义相似度、问答问题等。与其实现定制的、有时还很难理解的网络结构来完成特定的任务,不如使用 BERT 进行简单的微调,也许是一个更好的(至少不会差)选择。
NLP 的转变
这种向迁移学习的转变,与几年前计算机视觉领域发生的转变相似。为计算机视觉任务创建一个好的深度学习网络可能需要数百万个参数,并且训练成本非常高。研究人员发现,深度网络的特征表示可以分层进行学习(在最底层学习简单的特征,如物体边缘等,在更高的层逐渐增加复杂的特征)。与其每次从头开始训练一个新的网络,不如将训练好的网络的低层泛化图像特征复制并转移到另一个有不同任务的网络中使用。很快,下载一个预训练过的深度网络,然后为新任务快速地重新训练它,或者在上面添加额外的层,这已成为一种常见的做法——这比从头开始训练一个昂贵的网络要好得多。对许多人来说,2018年推出的深度预训练语言模型(ELMO、BERT、ULMFIT、Open-GPT等),预示着和计算机视觉一样,NLP 正在向迁移学习发生转变。
让我们开始行动吧!
1. 安装
1.1. 使用 Colab GPU 来训练
Google Colab 提供免费的 GPU 和 TPU!由于我们将训练一个大型的神经网络,所以最好使用这些硬件加速(本文中,我们将使用一个 GPU),否则训练将需要很长时间。
你可以在目录中选择添加 GPU
Edit -> Notebook Settings -> Hardware accelerator -> (GPU)
接着运行下面代码来确认 GPU 被检测到:
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
-----
device(type='cuda')
1.2. 安装 Hugging Face 库
下一步,我们来安装 Hugging Face 的 transformers 库,它将为我们提供一个 BERT 的 pytorch 接口(这个库包含其他预训练语言模型的接口,如 OpenAI 的 GPT 和 GPT-2)。我们选择了 pytorch 接口,因为它在高层次的API(很容易使用,但缺乏细节)和 tensorflow 代码(其中包含很多细节,这往往会让我们陷入关于 tensorflow 的学习中,而这里的目的是 BERT!)之间取得了很好的平衡。
目前来看,Hugging Face 似乎是被广泛接受的、最强大的 Bert 接口。除了支持各种不同的预训练模型外,该库还包含了适应于不同任务的模型的预构建。例如,在本教程中,我们将使用 BertForSequenceClassification 来做文本分类。
该库还为 token classification、question answering、next sentence prediction 等不同 NLP 任务提供特定的类库。使用这些预构建的类,可以简化定制 BERT 的过程。安装 transformer:
!pip install transformers
本教程中的代码实际上是 huggingface 样例代码 run_glue.py 的简化版本。
run_glue.py 是一个有用的工具,它可以让你选择你想运行的 GLUE 任务,以及你想使用的预训练模型。它还支持使用 CPU、单个 GPU 或多个 GPU。如果你想进一步提高速度,它甚至支持使用 16 位精度。
遗憾的是,所有这些配置让代码的可读性变得很差,本教程会极大的简化这些代码,并增加大量的注释,让大家知其然,并知其所以然。
2. 加载 CoLA 数据集
我们将使用 The Corpus of Linguistic Acceptability(CoLA)数据集进行单句分类。它是一组被标记为语法正确或错误的句子。它于2018年5月首次发布,是 "GLUE Benchmark" 中的数据集之一。
2.1. 下载 & 解压
我们使用 wget 来下载数据集,安装 wget:
!pip install wget
下载数据集
import wget
import os
print('Downloading dataset...')
# 数据集的下载链接
url = 'https://nyu-mll.github.io/CoLA/cola_public_1.1.zip'
# 如本地没有,则下载数据集
if not os.path.exists('./cola_public_1.1.zip'):
wget.download(url, './cola_public_1.1.zip')
解压之后,你就可以在 Colab 左侧的文件系统窗口看到这些文件:
# 如果没解压过,则解压zip包
if not os.path.exists('./cola_public/'):
!unzip cola_public_1.1.zip
2.2. 解析
从解压后的文件名就可以看出哪些文件是分词后的,哪些是原始文件。
我们使用未分词版本的数据,因为要应用预训练 BERT,必须使用模型自带的分词器。这是因为: (1) 模型有一个固定的词汇表, (2) BERT 用一种特殊的方式来处理词汇外的单词(out-of-vocabulary)。
先使用 pandas 来解析 in_domain_train.tsv 文件,并预览这些数据:
import pandas as pd
# 加载数据集到 pandas 的 dataframe 中
df = pd.read_csv("./cola_public/raw/in_domain_train.tsv", delimiter='\t', header=None, names=['sentence_source', 'label', 'label_notes', 'sentence'])
# 打印数据集的记录数
print('Number of training sentences: {:,}\n'.format(df.shape[0]))
# 抽样10条数据来预览一下
df.sample(10)
| sentence_source | label | label_notes | sentence | |
|---|---|---|---|---|
| 1406 | r-67 | 1 | NaN | A plan to negotiate an honorable end to the wa... |
| 7315 | sks13 | 0 | * | I said. |
| 8277 | ad03 | 0 | * | What Julie did of Lloyd was become fond. |
| 621 | bc01 | 1 | NaN | The ball lies completely in the box. |
| 6646 | m_02 | 1 | NaN | Very heavy, this parcel! |
| 361 | bc01 | 0 | ?? | Which problem do you wonder whether John said ... |
| 7193 | sks13 | 0 | * | Will put, this girl in the red coat will put a... |
| 4199 | ks08 | 1 | NaN | The papers removed from the safe have not been... |
| 5251 | b_82 | 1 | NaN | He continued writing poems. |
| 3617 | ks08 | 1 | NaN | It was last night that the policeman met sever... |
上表中我们主要关心 sentence 和 label 字段,label 中 0 表示“语法不可接受”,而 1 表示“语法可接受”。
下面是 5 个语法上不可接受的例子,可以看到相对于情感分析来说,这个任务要困难很多:
df.loc[df.label == 0].sample(5)[['sentence', 'label']]
| sentence | label | |
|---|---|---|
| 4867 | They investigated. | 0 |
| 200 | The more he reads, the more books I wonder to ... | 0 |
| 4593 | Any zebras can't fly. | 0 |
| 3226 | Cities destroy easily. | 0 |
| 7337 | The time elapsed the day. | 0 |
我们把 sentence 和 label 字段加载到 numpy 数组中
# 构建 sentences 和 labels 列表
sentences = df.sentence.values
labels = df.label.values
3. 分词 & 格式化输入层
在本小节中,我们会将数据集转化为可被 BERT 训练的格式。
3.1. BERT 分词器
要将文本输入到 BERT 中,必须先对它们分词,并使用模型内部提供的词汇表,把这些词转换为词的下标。
先在代码中导入 BERT 库,这里使用 "uncased" 小写版本的预训练模型:
from transformers import BertTokenizer
# 加载 BERT 分词器
print('Loading BERT tokenizer...')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)
我们输入一个句子试试:
# 输出原始句子
print(' Original: ', sentences[0])
# 将分词后的内容输出
print('Tokenized: ', tokenizer.tokenize(sentences[0]))
# 将每个词映射到词典下标
print('Token IDs: ', tokenizer.convert_tokens_to_ids(tokenizer.tokenize(sentences[0])))
-----
Original: Our friends won't buy this analysis, let alone the next one we propose.
Tokenized: ['our', 'friends', 'won', "'", 't', 'buy', 'this', 'analysis', ',', 'let', 'alone', 'the', 'next', 'one', 'we', 'propose', '.']
Token IDs: [2256, 2814, 2180, 1005, 1056, 4965, 2023, 4106, 1010, 2292, 2894, 1996, 2279, 2028, 2057, 16599, 1012]
在真正训练的时候,我们使用 tokenize.encode 这个函数来完成上面 tokenize 和 convert_tokens_to_ids 两个步骤。
在这之前,我们先介绍下 BERT 的格式化要求。
3.2. 格式化要求
BERT 要求我们:
- 在句子的句首和句尾添加特殊的符号
- 给句子填充 or 截断,使每个句子保持固定的长度
- 用 “attention mask” 来显示的区分填充的 tokens 和非填充的 tokens。
特殊符号
[SEP]
在每个句子的结尾,需要添加特殊的 [SEP] 符号。
在以输入为两个句子的任务中(例如:句子 A 中的问题的答案是否可以在句子 B 中找到),该符号为这两个句子的分隔符。
目前为止我还不清楚为什么要在单句中加入该符号,但既然这样要求我们就这么做吧。
[CLS]
在分类任务中,我们需要将 [CLS] 符号插入到每个句子的开头。
这个符号有特殊的意义,BERT 包含 12 个 Transformer 层,每层接受一组 token 的 embeddings 列表作为输入,并产生相同数目的 embeddings 作为输出(当然,它们的值是不同的)。
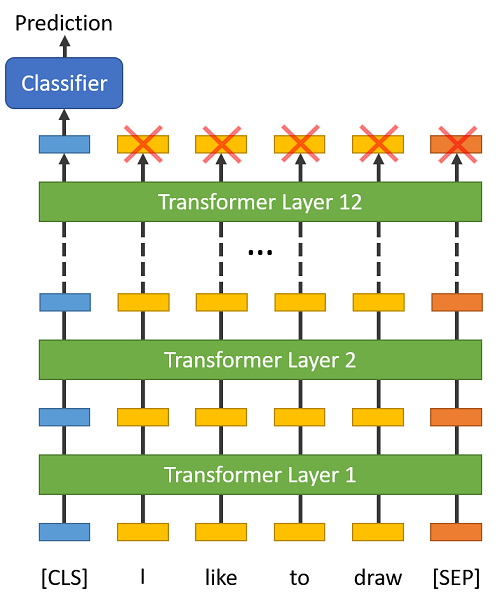
最后一层 transformer 的输出,只有第 1 个 embedding(对应到 [CLS] 符号)会输入到分类器中。
“The first token of every sequence is always a special classification token (
[CLS]). The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks.” (from the BERT paper)
你也许会想到对最后一层的 embeddings 使用一些池化策略,但没有必要。因为 BERT 就是被训练成只使用 [CLS] 来做分类,它会把分类所需的一切信息编码到 [CLS] 对应的 768 维 embedding 向量中,相当于它已经为我们做好了池化工作。
句长 & 注意力掩码(Attention Mask)
很明显,数据集中句子长度的取值范围很大,BERT 该如何处理这个问题呢?
BERT 有两个限制条件:
-
所有句子必须被填充或截断到固定的长度,句子最大的长度为 512 个 tokens。
-
填充句子要使用
[PAD]符号,它在 BERT 词典中的下标为 0,下图是最大长度为 8 个 tokens 的填充说明:
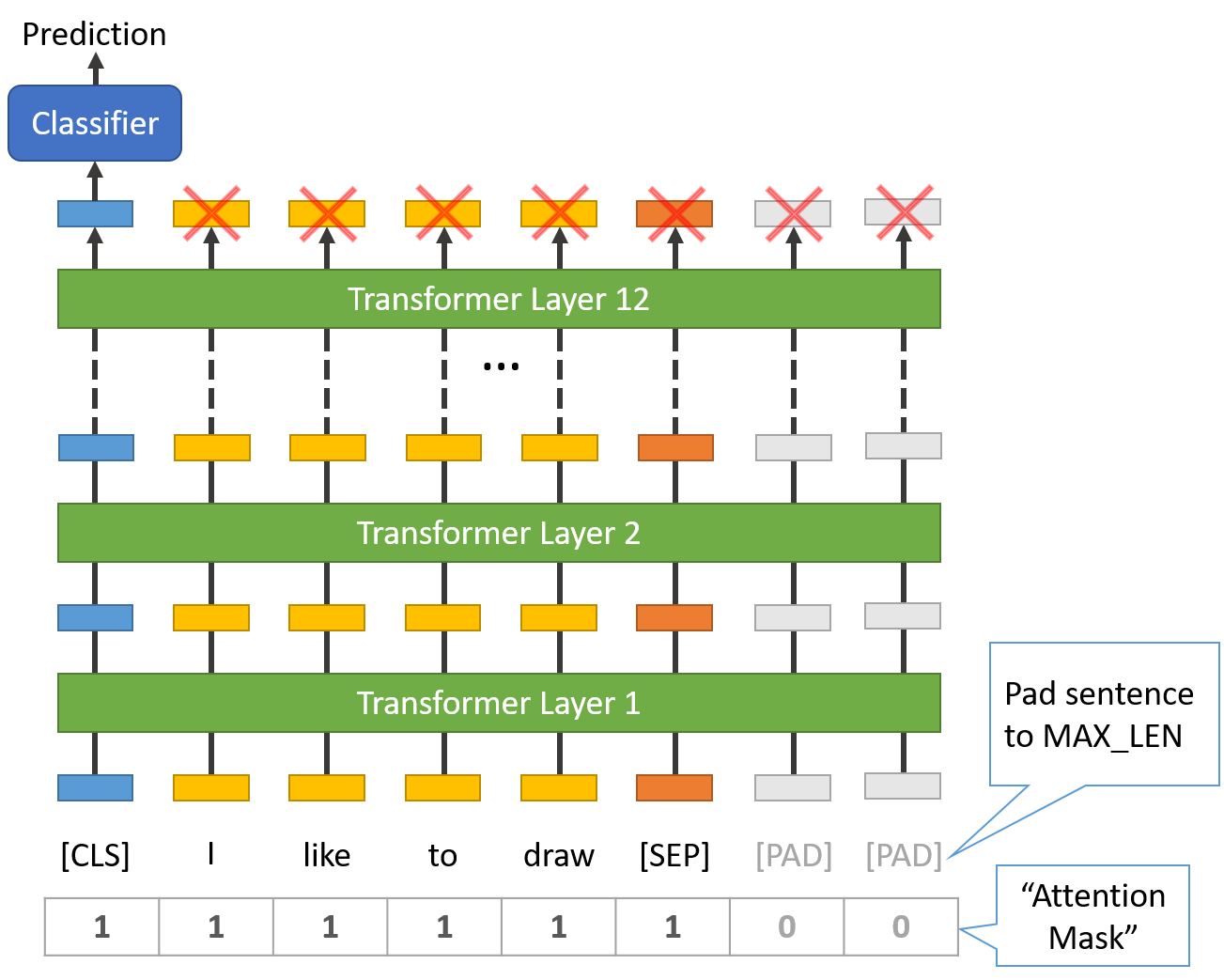
“Attention Mask” 是一个只有 0 和 1 组成的数组,标记哪些 tokens 是填充的,哪些不是的。掩码会告诉 BERT 中的 “Self-Attention” 机制不去处理这些填充的符号。
句子的最大长度配置会影响训练和评估速度,例如,在 Tesla K80 上有以下测试:
MAX_LEN = 128 # 每个 epoch 要训练 5'28''
MAX_LEN = 64 # 每个 epoch 要训练 2'27''
3.3. 对数据集分词
transformers 库提供的 encode 函数会为我们处理大多数解析和数据预处理的工作。
在编码文本之前,我们需要确定 MAX_LEN 这个参数,下面的代码可以计算数据集中句子的最大长度:
max_len = 0
for sent in sentences:
# 将文本分词,并添加 `[CLS]` 和 `[SEP]` 符号
input_ids = tokenizer.encode(sent, add_special_tokens=True)
max_len = max(max_len, len(input_ids))
print('Max sentence length: ', max_len)
为了避免不会出现更长的句子,这里我们将 MAX_LEN 设为 64。下面我们正式开始分词。
函数 tokenizer.encode_plus 包含以下步骤:
- 将句子分词为 tokens。
- 在两端添加特殊符号
[CLS]和[SEP]。 - 将 tokens 映射为下标 IDs。
- 将列表填充或截断为固定的长度。
- 创建 attention masks,将填充的和非填充 tokens 区分开来。
# 将数据集分完词后存储到列表中
input_ids = []
attention_masks = []
for sent in sentences:
encoded_dict = tokenizer.encode_plus(
sent, # 输入文本
add_special_tokens = True, # 添加 '[CLS]' 和 '[SEP]'
max_length = 64, # 填充 & 截断长度
pad_to_max_length = True,
return_attention_mask = True, # 返回 attn. masks.
return_tensors = 'pt', # 返回 pytorch tensors 格式的数据
)
# 将编码后的文本加入到列表
input_ids.append(encoded_dict['input_ids'])
# 将文本的 attention mask 也加入到 attention_masks 列表
attention_masks.append(encoded_dict['attention_mask'])
# 将列表转换为 tensor
input_ids = torch.cat(input_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
labels = torch.tensor(labels)
# 输出第 1 行文本的原始和编码后的信息
print('Original: ', sentences[0])
print('Token IDs:', input_ids[0])
3.4. 拆分训练集和验证集
将 90% 的数据集作为训练集,剩下的 10% 作为验证集:
from torch.utils.data import TensorDataset, random_split
# 将输入数据合并为 TensorDataset 对象
dataset = TensorDataset(input_ids, attention_masks, labels)
# 计算训练集和验证集大小
train_size = int(0.9 * len(dataset))
val_size = len(dataset) - train_size
# 按照数据大小随机拆分训练集和测试集
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
print('{:>5,} training samples'.format(train_size))
print('{:>5,} validation samples'.format(val_size))
我们使用 DataLoader 类来读取数据集,相对于一般的 for 循环来说,这种方法在训练期间会比较节省内存:
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
# 在 fine-tune 的训练中,BERT 作者建议小批量大小设为 16 或 32
batch_size = 32
# 为训练和验证集创建 Dataloader,对训练样本随机洗牌
train_dataloader = DataLoader(
train_dataset, # 训练样本
sampler = RandomSampler(train_dataset), # 随机小批量
batch_size = batch_size # 以小批量进行训练
)
# 验证集不需要随机化,这里顺序读取就好
validation_dataloader = DataLoader(
val_dataset, # 验证样本
sampler = SequentialSampler(val_dataset), # 顺序选取小批量
batch_size = batch_size
)
4. 训练分类模型
现在模型的输入数据已经准备好了,是时候开始微调了。
4.1. BertForSequenceClassification
在本任务中,我们首先需要将预训练 BERT 模型改为分类模型。接着,用我们的数据集来训练这个模型,以使该模型能够端到端的、很好的适应于我们的任务。
幸运的是,huggingface 的 pytorch 实现包含一系列接口,就是为不同的 NLP 任务设计的。这些接口无一例外的构建于 BERT 模型之上,对于不同的 NLP 任务,它们有不同的结构和不同的输出类型。
以下是当前提供给微调的类列表:
- BertModel
- BertForPreTraining
- BertForNextSentencePrediction
- BertForNextSentencePrediction
- BertForSequenceClassification - 我们使用这个
- BertForTokenClassification
- BertForQuestionAnswering
这些类的文档在这里。
我们将使用 BertForSequenceClassification,它由一个普通的 BERT 模型和一个单线性分类层组成,而后者主要负责文本分类。当我们向模型输入数据时,整个预训练 BERT 模型和额外的未训练的分类层将会一起被训练。
好了, 我们现在加载 BERT!有几种不同的预训练模型可供选择,"bert-base-uncased" 是只有小写字母的版本,且它是 "base" 和 "large" 中的较小版。
接口 from_pretrained 的文档在这里,额外的参数说明在这里。
from transformers import BertForSequenceClassification, AdamW, BertConfig
# 加载 BertForSequenceClassification, 预训练 BERT 模型 + 顶层的线性分类层
model = BertForSequenceClassification.from_pretrained(
"bert-base-uncased", # 小写的 12 层预训练模型
num_labels = 2, # 分类数 --2 表示二分类
# 你可以改变这个数字,用于多分类任务
output_attentions = False, # 模型是否返回 attentions weights.
output_hidden_states = False, # 模型是否返回所有隐层状态.
)
# 在 gpu 中运行该模型
model.cuda()
好奇心使然,我们可以根据参数名来查看所有的模型参数。
下面会打印参数名和参数的形状:
- embedding 层
- 12 层 transformers 的第 1 层
- 输出层
# 将所有模型参数转换为一个列表
params = list(model.named_parameters())
print('The BERT model has {:} different named parameters.\n'.format(len(params)))
print('==== Embedding Layer ====\n')
for p in params[0:5]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
print('\n==== First Transformer ====\n')
for p in params[5:21]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
print('\n==== Output Layer ====\n')
for p in params[-4:]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
输出
The BERT model has 201 different named parameters.
==== Embedding Layer ====
bert.embeddings.word_embeddings.weight (30522, 768)
bert.embeddings.position_embeddings.weight (512, 768)
bert.embeddings.token_type_embeddings.weight (2, 768)
bert.embeddings.LayerNorm.weight (768,)
bert.embeddings.LayerNorm.bias (768,)
==== First Transformer ====
bert.encoder.layer.0.attention.self.query.weight (768, 768)
bert.encoder.layer.0.attention.self.query.bias (768,)
bert.encoder.layer.0.attention.self.key.weight (768, 768)
bert.encoder.layer.0.attention.self.key.bias (768,)
bert.encoder.layer.0.attention.self.value.weight (768, 768)
bert.encoder.layer.0.attention.self.value.bias (768,)
bert.encoder.layer.0.attention.output.dense.weight (768, 768)
bert.encoder.layer.0.attention.output.dense.bias (768,)
bert.encoder.layer.0.attention.output.LayerNorm.weight (768,)
bert.encoder.layer.0.attention.output.LayerNorm.bias (768,)
bert.encoder.layer.0.intermediate.dense.weight (3072, 768)
bert.encoder.layer.0.intermediate.dense.bias (3072,)
bert.encoder.layer.0.output.dense.weight (768, 3072)
bert.encoder.layer.0.output.dense.bias (768,)
bert.encoder.layer.0.output.LayerNorm.weight (768,)
bert.encoder.layer.0.output.LayerNorm.bias (768,)
==== Output Layer ====
bert.pooler.dense.weight (768, 768)
bert.pooler.dense.bias (768,)
classifier.weight (2, 768)
classifier.bias (2,)
4.2. 优化器 & 学习率调度器
加载了模型后,下一步我们来调节超参数。
在微调过程中,BERT 的作者建议使用以下超参 (from Appendix A.3 of the BERT paper)::
- 批量大小:16, 32
- 学习率(Adam):5e-5, 3e-5, 2e-5
- epochs 的次数:2, 3, 4
我们的选择如下:
- Batch size: 32(在构建 DataLoaders 时设置)
- Learning rate:2e-5
- Epochs: 4(我们将看到这个值对于本任务来说有点大了)
参数 epsilon = 1e-8 是一个非常小的值,他可以避免实现过程中的分母为 0 的情况 (from here)。
你可以在 run_glue.py 中找到优化器 AdamW 的创建:
# 我认为 'W' 代表 '权重衰减修复"
optimizer = AdamW(model.parameters(),
lr = 2e-5, # args.learning_rate - default is 5e-5
eps = 1e-8 # args.adam_epsilon - default is 1e-8
)
from transformers import get_linear_schedule_with_warmup
# 训练 epochs。 BERT 作者建议在 2 和 4 之间,设大了容易过拟合
epochs = 4
# 总的训练样本数
total_steps = len(train_dataloader) * epochs
# 创建学习率调度器
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = 0,
num_training_steps = total_steps)
4.3. 训练循环
下面是训练循环,有很多代码,但基本上每次循环,均包括训练环节和评估环节。
训练:
- 取出输入样本和标签数据
- 加载这些数据到 GPU 中
- 清除上次迭代的梯度计算
- pytorch 中梯度是累加的(在 RNN 中有用),本例中每次迭代前需手动清零
- 前向传播
- 反向传播
- 使用优化器来更新参数
- 监控训练过程
评估:
- 取出输入样本和标签数据
- 加载这些数据到 GPU 中
- 前向计算
- 计算 loss 并监控整个评估过程
定义计算准确率的函数:
import numpy as np
# 根据预测结果和标签数据来计算准确率
def flat_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)
将训练耗时格式化成 hh:mm:ss 的帮助函数:
import time
import datetime
def format_time(elapsed):
'''
Takes a time in seconds and returns a string hh:mm:ss
'''
# 四舍五入到最近的秒
elapsed_rounded = int(round((elapsed)))
# 格式化为 hh:mm:ss
return str(datetime.timedelta(seconds=elapsed_rounded))
全部训练代码:
import random
import numpy as np
# 以下训练代码是基于 `run_glue.py` 脚本:
# https://github.com/huggingface/transformers/blob/5bfcd0485ece086ebcbed2d008813037968a9e58/examples/run_glue.py#L128
# 设定随机种子值,以确保输出是确定的
seed_val = 42
random.seed(seed_val)
np.random.seed(seed_val)
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)
# 存储训练和评估的 loss、准确率、训练时长等统计指标,
training_stats = []
# 统计整个训练时长
total_t0 = time.time()
for epoch_i in range(0, epochs):
# ========================================
# Training
# ========================================
print("")
print('======== Epoch {:} / {:} ========'.format(epoch_i + 1, epochs))
print('Training...')
# 统计单次 epoch 的训练时间
t0 = time.time()
# 重置每次 epoch 的训练总 loss
total_train_loss = 0
# 将模型设置为训练模式。这里并不是调用训练接口的意思
# dropout、batchnorm 层在训练和测试模式下的表现是不同的 (source: https://stackoverflow.com/questions/51433378/what-does-model-train-do-in-pytorch)
model.train()
# 训练集小批量迭代
for step, batch in enumerate(train_dataloader):
# 每经过40次迭代,就输出进度信息
if step % 40 == 0 and not step == 0:
elapsed = format_time(time.time() - t0)
print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(train_dataloader), elapsed))
# 准备输入数据,并将其拷贝到 gpu 中
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
# 每次计算梯度前,都需要将梯度清 0,因为 pytorch 的梯度是累加的
model.zero_grad()
# 前向传播
# 文档参见:
# https://huggingface.co/transformers/v2.2.0/model_doc/bert.html#transformers.BertForSequenceClassification
# 该函数会根据不同的参数,会返回不同的值。 本例中, 会返回 loss 和 logits -- 模型的预测结果
loss, logits = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
# 累加 loss
total_train_loss += loss.item()
# 反向传播
loss.backward()
# 梯度裁剪,避免出现梯度爆炸情况
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# 更新参数
optimizer.step()
# 更新学习率
scheduler.step()
# 平均训练误差
avg_train_loss = total_train_loss / len(train_dataloader)
# 单次 epoch 的训练时长
training_time = format_time(time.time() - t0)
print("")
print(" Average training loss: {0:.2f}".format(avg_train_loss))
print(" Training epcoh took: {:}".format(training_time))
# ========================================
# Validation
# ========================================
# 完成一次 epoch 训练后,就对该模型的性能进行验证
print("")
print("Running Validation...")
t0 = time.time()
# 设置模型为评估模式
model.eval()
# Tracking variables
total_eval_accuracy = 0
total_eval_loss = 0
nb_eval_steps = 0
# Evaluate data for one epoch
for batch in validation_dataloader:
# 将输入数据加载到 gpu 中
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
# 评估的时候不需要更新参数、计算梯度
with torch.no_grad():
(loss, logits) = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
# 累加 loss
total_eval_loss += loss.item()
# 将预测结果和 labels 加载到 cpu 中计算
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
# 计算准确率
total_eval_accuracy += flat_accuracy(logits, label_ids)
# 打印本次 epoch 的准确率
avg_val_accuracy = total_eval_accuracy / len(validation_dataloader)
print(" Accuracy: {0:.2f}".format(avg_val_accuracy))
# 统计本次 epoch 的 loss
avg_val_loss = total_eval_loss / len(validation_dataloader)
# 统计本次评估的时长
validation_time = format_time(time.time() - t0)
print(" Validation Loss: {0:.2f}".format(avg_val_loss))
print(" Validation took: {:}".format(validation_time))
# 记录本次 epoch 的所有统计信息
training_stats.append(
{
'epoch': epoch_i + 1,
'Training Loss': avg_train_loss,
'Valid. Loss': avg_val_loss,
'Valid. Accur.': avg_val_accuracy,
'Training Time': training_time,
'Validation Time': validation_time
}
)
print("")
print("Training complete!")
print("Total training took {:} (h:mm:ss)".format(format_time(time.time()-total_t0)))
我们一起来看一下整个训练的概要:
import pandas as pd
# 保留 2 位小数
pd.set_option('precision', 2)
# 加载训练统计到 DataFrame 中
df_stats = pd.DataFrame(data=training_stats)
# 使用 epoch 值作为每行的索引
df_stats = df_stats.set_index('epoch')
# 展示表格数据
df_stats
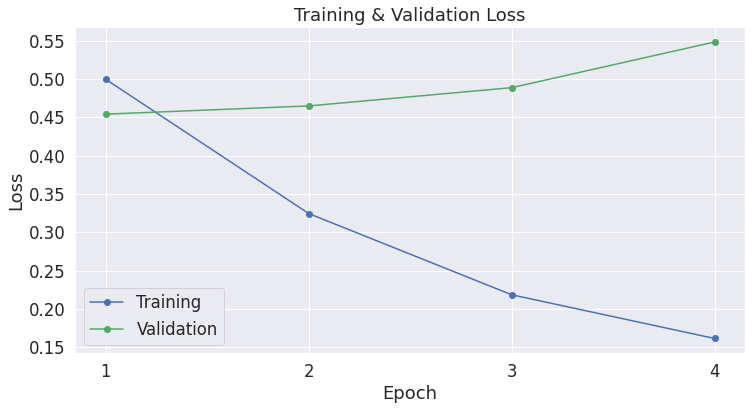
| epoch | Training Loss | Valid. Loss | Valid. Accur. | Training Time | Validation Time |
|---|---|---|---|---|---|
| 1 | 0.50 | 0.45 | 0.80 | 0:00:51 | 0:00:02 |
| 2 | 0.32 | 0.46 | 0.81 | 0:00:51 | 0:00:02 |
| 3 | 0.22 | 0.49 | 0.82 | 0:00:51 | 0:00:02 |
| 4 | 0.16 | 0.55 | 0.82 | 0:00:51 | 0:00:02 |
注意到,每次 epoch,训练误差都会降低,而验证误差却在上升!这意味着我们的训练模型的时间过长了,即模型过拟合了。
在评估过程中,验证集误差相对于准确率来说更为精细,因为准确率并不关心具体的输出值,而仅仅考虑给定一个阈值,样本会落在哪个分类上。
当我们预测正确,但信心依然不足时,可以使用验证误差来评估,而准确率却做不到这一点,对比每次 epoch 的训练误差和验证误差:
import matplotlib.pyplot as plt
% matplotlib inline
import seaborn as sns
# 绘图风格设置
sns.set(style='darkgrid')
# Increase the plot size and font size.
sns.set(font_scale=1.5)
plt.rcParams["figure.figsize"] = (12,6)
# 绘制学习曲线
plt.plot(df_stats['Training Loss'], 'b-o', label="Training")
plt.plot(df_stats['Valid. Loss'], 'g-o', label="Validation")
# Label the plot.
plt.title("Training & Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.xticks([1, 2, 3, 4])
plt.show()
5. 在测试集上测试性能
下面我们加载测试集,并使用 Matthew相关系数来评估模型性能,因为这是一种在 NLP 社区中被广泛使用的衡量 CoLA 任务性能的方法。使用这种测量方法,+1 为最高分,-1 为最低分。于是,我们就可以在特定任务上,横向和最好的模型进行性能对比了。
5.1. 数据准备
对测试集的处理,和处理训练数据集的步骤是一致的,如下
import pandas as pd
# 加载数据集
df = pd.read_csv("./cola_public/raw/out_of_domain_dev.tsv", delimiter='\t', header=None, names=['sentence_source', 'label', 'label_notes', 'sentence'])
# 打印数据集大小
print('Number of test sentences: {:,}\n'.format(df.shape[0]))
# 将数据集转换为列表
sentences = df.sentence.values
labels = df.label.values
# 分词、填充或截断
input_ids = []
attention_masks = []
for sent in sentences:
encoded_dict = tokenizer.encode_plus(
sent,
add_special_tokens = True,
max_length = 64,
pad_to_max_length = True,
return_attention_mask = True,
return_tensors = 'pt',
)
input_ids.append(encoded_dict['input_ids'])
attention_masks.append(encoded_dict['attention_mask'])
input_ids = torch.cat(input_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
labels = torch.tensor(labels)
batch_size = 32
# 准备好数据集
prediction_data = TensorDataset(input_ids, attention_masks, labels)
prediction_sampler = SequentialSampler(prediction_data)
prediction_dataloader = DataLoader(prediction_data, sampler=prediction_sampler, batch_size=batch_size)
5.2. 评估测试集性能
准备好测试集数据后,就可以用之前微调的模型来对测试集进行预测了
# 预测测试集
print('Predicting labels for {:,} test sentences...'.format(len(input_ids)))
# 依然是评估模式
model.eval()
# Tracking variables
predictions , true_labels = [], []
# 预测
for batch in prediction_dataloader:
# 将数据加载到 gpu 中
batch = tuple(t.to(device) for t in batch)
b_input_ids, b_input_mask, b_labels = batch
# 不需要计算梯度
with torch.no_grad():
# 前向传播,获取预测结果
outputs = model(b_input_ids, token_type_ids=None,
attention_mask=b_input_mask)
logits = outputs[0]
# 将结果加载到 cpu 中
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
# 存储预测结果和 labels
predictions.append(logits)
true_labels.append(label_ids)
print(' DONE.')
使用 Mathews 相关性系数(MCC)来评估测试集性能,原因在于类别的分布是不均匀的:
print('Positive samples: %d of %d (%.2f%%)' % (df.label.sum(), len(df.label), (df.label.sum() / len(df.label) * 100.0)))
-----
Positive samples: 354 of 516 (68.60%)
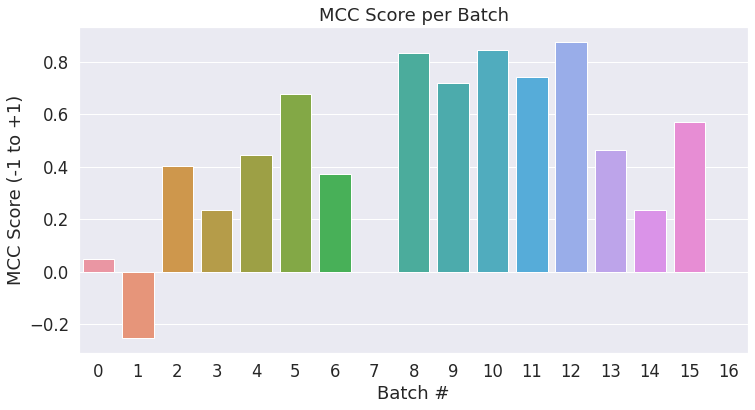
最终评测结果会基于全量的测试数据,不过我们可以统计每个小批量各自的分数,以查看批量之间的变化。
from sklearn.metrics import matthews_corrcoef
matthews_set = []
# 计算每个 batch 的 MCC
print('Calculating Matthews Corr. Coef. for each batch...')
# For each input batch...
for i in range(len(true_labels)):
pred_labels_i = np.argmax(predictions[i], axis=1).flatten()
# 计算该 batch 的 MCC
matthews = matthews_corrcoef(true_labels[i], pred_labels_i)
matthews_set.append(matthews)
# 创建柱状图来显示每个 batch 的 MCC 分数
ax = sns.barplot(x=list(range(len(matthews_set))), y=matthews_set, ci=None)
plt.title('MCC Score per Batch')
plt.ylabel('MCC Score (-1 to +1)')
plt.xlabel('Batch #')
plt.show()
我们将所有批量的结果合并,来计算最终的 MCC 分:
# 合并所有 batch 的预测结果
flat_predictions = np.concatenate(predictions, axis=0)
# 取每个样本的最大值作为预测值
flat_predictions = np.argmax(flat_predictions, axis=1).flatten()
# 合并所有的 labels
flat_true_labels = np.concatenate(true_labels, axis=0)
# 计算 MCC
mcc = matthews_corrcoef(flat_true_labels, flat_predictions)
print('Total MCC: %.3f' % mcc)
-----
Total MCC: 0.498
Cool!只用了半个小时,在没有调整任何超参数的情况下(调整学习率、epochs、批量大小、ADAM 属性等),我们却得到了一个还不赖的分数。
库文档期望的准确率 benchmark 在此查看。你也可以在这里查看官方的排行榜。
总结
本教程主要描述了在预训练 BERT 模型的基础上,你可以使用较少数据和训练时间,快速且高效的创建一个高质量的 NLP 模型。
附录
A.1. 存储 & 加载微调的模型
下面的代码(源自 run_glue.py)将模型和分词器写到磁盘上
import os
# 模型存储到的路径
output_dir = './model_save/'
# 目录不存在则创建
if not os.path.exists(output_dir):
os.makedirs(output_dir)
print("Saving model to %s" % output_dir)
# 使用 `save_pretrained()` 来保存已训练的模型,模型配置和分词器
# 它们后续可以通过 `from_pretrained()` 加载
model_to_save = model.module if hasattr(model, 'module') else model # 考虑到分布式/并行(distributed/parallel)训练
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
# Good practice: save your training arguments together with the trained model
# torch.save(args, os.path.join(output_dir, 'training_args.bin'))
将 Colab Notebook 中的模型存储到 Google Drive 上
# 挂载 Google Drive
from google.colab import drive
drive.mount('/content/drive')
# 拷贝模型文件到 Google Drive
!cp -r ./model_save/ "./drive/Shared drives/AI/BERT Fine-Tuning/"
下面的代码将从磁盘上加载模型
# 加载微调后的模型的词汇表
model = model_class.from_pretrained(output_dir)
tokenizer = tokenizer_class.from_pretrained(output_dir)
# 将模型 copy 到 GPU/CPU 中运行
model.to(device)
A.2. 权重衰减
huggingface 的例子中包含以下代码来设置权重衰减(weight decay),但默认的衰减率为 "0",所以我把这部分代码移到了附录中。
这个代码段本质上告诉优化器不在 bias 参数上运用权重衰减,权重衰减实际上是一种在计算梯度后的正则化。
# 代码来源于:
# https://github.com/huggingface/transformers/blob/5bfcd0485ece086ebcbed2d008813037968a9e58/examples/run_glue.py#L102
# 不在包含以下字符串的参数名对应的参数上运用权重衰减
# (Here, the BERT doesn't have `gamma` or `beta` parameters, only `bias` terms)
no_decay = ['bias', 'LayerNorm.weight']
# 将`weight`参数和`bias`参数分开
# - 对于`weight`参数, 'weight_decay_rate'设为 0.01
# - 对于`bias`参数, 'weight_decay_rate'设为 0.0
optimizer_grouped_parameters = [
# Filter for all parameters which *don't* include 'bias', 'gamma', 'beta'.
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.1},
# Filter for parameters which *do* include those.
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.0}
]
# 注意 - `optimizer_grouped_parameters` 仅包含参数值,不包含参数名
译者注:经验证,以上代码均可在 Google Colab 上运行,链接如下:colab.research.google.com/drive/1sfAy…
