

InnoDB引擎在运行期间,实际上就是一个用户进程来作为客户与磁盘之间交互的一个通道。而在内存上,InnoDB引擎实际上分为两大块区域:后台线程和内存池
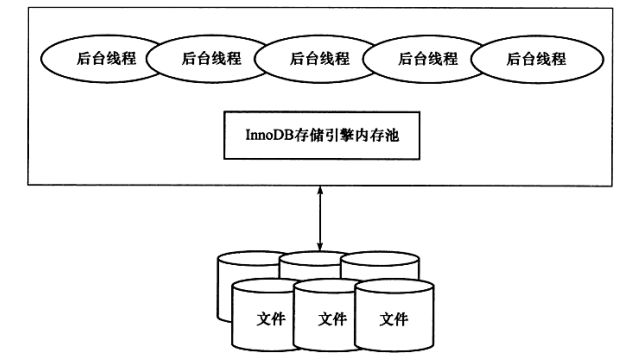
后台线程
InnoDB是多线程模型,所以在运行过程中有多个不同的后台线程,分别执行不同的任务。
Master Thread
Master Thread是所有后台线程中所核心的一个,主要负责脏页的刷新,插入缓冲的合并,Undo log的回收(1.1版本之前)等核心任务
IO Thread
在InnoDB中大量使用了AIO来提升IO效率,而其中的IO线程可以分为四种:write,read,insert,log IO Thread,分别负责对这四种IO操作进行发起和回调。在1.0及其之前的版本中,这四种线程各有一种。而在之后的版本,write金和read线程数就增加到各位4个
Purge Thread
InnoDB实现了事务机制,而事务的一些基础功能如回滚,是通过每个事务的Undo log来实现的,也就是说,当事务提交之后,其内部形成的版本链就没有存在的意义了,所以此时Purge Thread就负责回收这些Undo log(其实在1.1版本之前,这个操作是由Master Thread去做的,后来就加入Purge Thread用来减轻Master Thread的负担)
内存
缓冲池
缓冲池其实包含了挺多东西的:
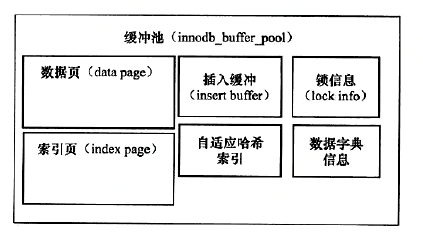
数据页
一般来说为了协调CPU和磁盘处理速度上数量级的差距,操作系统都会有设置缓存的做法, 把多次IO合并变成一次IO,从而提升效率。InnoDB也不例外。InnoDB不会对每一次修改操作都进行一次磁盘IO,那未免也太慢了。所以在内存上,InnoDB维护了一个数据页区域,对该数据页的修改,都会先在内存上找到该数据页(如果内存中没有怎么办?稍后再说),这个数据页修改之后,就变成了一个脏页,等待合适的时机,再会把这个脏页刷新回磁盘中。因此,为了防止存在内存的这部分数据因为宕机而丢失,从而违背事务的持久性,InnoDB还会有一个Redo log机制来保证持久性。 那问题来了,既然是作为一个缓存,那大小肯定有限制,总不能把所有的数据页都读到内存中来吧,所以缓存淘汰机制肯定是会有的,最典型的不就是LRU算法(最近最久未使用)么?没错,InnoDB用的也是LRU,但不同的是,它用的并不是朴素的LRU算法:当有一个最新的页插入时,它并不是插入到队列头,而是默认会插入到队列5/8的的位置,为啥要这么设计呢?实际上是为了让真正的热门数据页不要为刷出去。 考虑这样的情况:内存中存有一堆热门数据页,此时来了一个很少执行的大范围查询,涉及很多数据页,如果使用朴素的LRU,那么原来真正的热门数据页就全被刷走了,从而对性能产生影响。
Redo log Buffer
Redo log的存在就是为了保证事务的持久性,它记录的内容并不是像bin log那样的sql语句,它记录的实际上是数据页的物理偏移量,一条修改操作的执行,实际上得先在redo log buffer中记录,然后再去到内存中的数据页进行更新,redo log buffer会在合适的时机刷新到磁盘中的redo log file里面,后续如果需要重启恢复数据,都是基于redo log file去做的,刷新的时机有几个:
- 当事务提交时,会将redo log buffer的修改刷新到redo log file中
- Master Thread会以每秒一次的频率进行数据刷新
- 当redo log buffer大小占用达到阈值(默认是8M)的一半时,就进行一次刷新 那这样的话,又衍生了两个问题:文件大小和脏页刷新到一半宕机,这两个分别使用checkpoint和**双写(double write)**来解决
Check Point
因为redo log file是以一种增量追加的方式写入,所以随着进程运行,file会一直膨胀,这涉及到一个空间问题;并且进行重做的时候,需要对整个file进行重做,这又是一个时间问题。然而事实上,重做日志里面记录的信息,有很多是已经落盘了,对于这些信息是没必要进行重做的,所以就有了CheckPoint这个机制 Check Point可以理解为在重做日志中的一个指针,当一个脏页刷新回磁盘的时候,Check Point就向前移动,意义就是:Check Point之前的修改已经落盘了,重做的时候可以忽视,并且可以被覆盖;Check Point之后的数据还没落盘,恢复的时候需要重做,且不能被覆盖。 这样就解决了文件大小和恢复时间的问题
双写(double write)
由于redo log file记录的只是数据页的一个物理偏移量,所以如果原来的数据页发生了变换,那它是无法正常重做的。比如说,Mysql的一个数据页默认是16Kb大,在进行脏页刷新的时候,如果刷了前面的8Kb,然后宕机了,这样磁盘中的数据页已经被修改了,再根据重做日志进行恢复是没有意义的,所以必须有一个机制,在脏页完全刷新之前,必须维护着一个原始的副本,这样即使脏页刷新到一半失败了,还可以将数据页恢复成副本,然后再进行重做
此时就是double write大显身手的时候了。double wirite机制相关的有两个部分:存在于内存上的double write buffer和磁盘上的共享表空间
脏页在进行刷新之前,必须把对应的脏页复制到doule write buffer中
第一次写
把double write buffer中的脏页写到磁盘的共享表空间上,作为该数据页的一个备份
第二次写
把double write buffer中的脏页刷新到磁盘表数据文件中
若第二次写发生了错误,那直接从共享表空间上进行恢复,然后进行redo,就可以完成数据的备份
插入缓冲
前面提到了,对于一些修改操作比如插入,InnoDB会将插入操作先同步到内存中的数据页使之成为脏页,那问题来了,如果对应的数据页没有在内存中呢?要从磁盘中拿出来吗?那也太麻烦了。所以Insert Buffer就出现了,当对应的数据页没有在内存中的话,那这条插入记录会先记录在Insert Buffer中,等到合适的时机再会合并到数据页上,那这个时机主要有两个:
- 对应的数据页从磁盘中被读到内存中了,此时恰好可以写入
- Master Thread会以每10秒一次的概率进行一次插入缓冲的合并 当然了,插入缓冲也是在任何时候都会使用的,有一些限制:
- 对应的数据存在辅助索引(也就是非主键索引)
- 对应的索引不是唯一索引,因为唯一索引每次插入之前都得判断一下是否破坏了唯一性,这种数据是没办法缓冲的
那说了这么多,Insert Buffer到底是个啥?其实它就是一个B+树的结构,在之前的版本中,每个表都有这么一个Insert Buffer B+树,而在之后,变成了全局一个,按照表的全局唯一Id进行区分
自适应哈希索引
当以相同的模式(指的是相同的条件条件)对同一个页进行连续访问后,InnoDB会认为这些页是热门页,为这些页建立哈希索引,这种哈希索引就叫做自适应哈希索引。自适应哈希索引的建立有两个条件,满足其中一个即可:
- 以相同的模式对该数据页查询了100次
- 以相同的模式对该数据页查询了N次,N为该数据页数据行总数的1/16
