

概念说明
通常一个消息队列需要掌握的知识点有Topic(主体)、Producer(生产者)、Consumer(消费者)、Queue(队列)、Delivery Semantics(消息传递范式)
蛋疼的是不同的消息队列关于这些名词叫法不一样,含义也不是很精确。所以阿里起了一个项目OpenMessaging去发起首个分布式消息领域的国际标准。不过好像并没有多少人买账,但这并不妨碍我们按照这个规范去梳理学习消息队列的知识。
有兴趣的可以对照着看:github.com/openmessagi…
rocketmq官方文档已经说的比较清楚了,不再赘述
核心流程
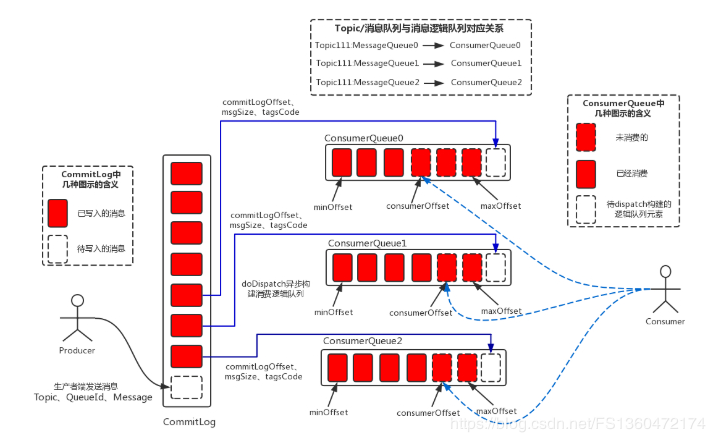
消息写入与存储
消息是存储到broker中的,写到commit log中,先写内存,在刷盘。 存储到磁盘中是直接以文件系统的方式。为了提高磁盘写入效率,都是顺序写,这样所有的topic都放在了一起,这一点与kafka不同,kafka以topic作为基本单元。
单个commitlog 文件大小为1G,之后滚动写入不同文件。
消息读取
消费者先从ConsumeQueue(消息逻辑队列)读取持久化消息的offset(偏移量)、size(大小)和消息Tag的HashCode值,再从CommitLog中读取消息的真正实体内容部分;
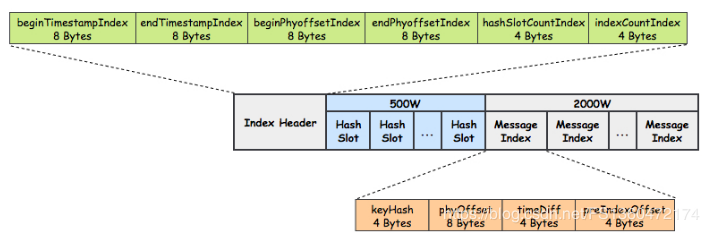
此外为了快速定位消息,还有一种文件叫index,在给定消息 Topic 和 Key 的前提下,可以快速定位消息
注意点
使用消息队列时,需要注意的地方
消息保存时间
rocketmq默认保存72小时,超过了,无论有没有消费都会丢弃,通过参数fileReserverdTime来配置。
注意这个配置是全局配置,没法针对不同的topic设置不同的值,原因在上面已经提到过了,因为rocketmq存储消息是所有的topic放在一起的。
消息有序
MessageListenerOrderly
消息丢失
理论上可以保证不丢失(接受消息重复,以及一定程度的写入性能下降),
生产端 同步模式,或者异步模式时需要处理发送失败情况
所以保证消费的幂等性是必须的
broker端
为了保证不丢,需要开启同步刷盘(防止内存数据丢失),同步复制(防止单点故障)。
这样是有性能损失的。刷盘机制参数flushDiskType 默认是ASYNC_FLUSH,broker 会消息一定量后再刷盘,显然性能更好。
消费端
消费完再CONSUME_SUCCESS
生产端,消费端都有可能因为网络问题导致消息成功了,但是ack没有成功,所以会重复投递/消费。所以Delivery Semantics一般选择At least once。应用程序必须要保证消费的幂等性
写入效率/消费效率/消费积压
发送端 异步刷盘,异步复制情况下,两台4核8G,大小100Byte,写入速度能够达到几万。
通常broker端不存在瓶颈。但是由于一般业务是是共用一个集群的,各个业务线都使用起来,流量还是很高的,需要监控报警,及时进行水平扩容。 如果能够接受延迟,producer可以批量提交,发送效率更高。
消费端
取决于消费逻辑是否耗时,默认单机处理线程consumeThreadMax (默认20)如果消费端服务时独立的,可以调整调整更大,提高单机处理速度。
无法提高单机处理速度的时候,可以集群水平扩展。不过不是无限水平扩展的,超过defaultTopicQueueNums 订阅队列数无效,该值默认值为4
应用场景
为什么需要消息队列,这个问题都被讲烂了,经典三大场景还是削峰填谷、异步处理、服务解耦。 个人觉得这边总结的比较全面。github.com/openmessagi…
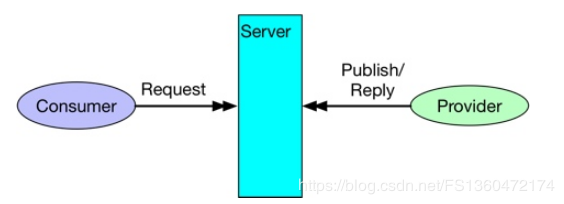
重点介绍下rpc场景,注意这个rpc不是rpc调用。是同步消息,相当于两次rpc。client发到server。server处理完再发到client。
rpc
