

论文提出DRConv,很好地结合了局部共享的思想并且保持平移不变性,包含两个关键结构,从实验结果来看,DRConv符合设计的预期,在多个任务上都有不错的性能提升
来源:晓飞的算法工程笔记 公众号
论文: Dynamic Region-Aware Convolution

Introduction
目前主流的卷积操作都在空间域进行权值共享,而如果想得到更丰富的信息,只能通过增加卷积的数量来实现,这样不仅计算低效,也会带来网络优化困难。与主流卷积不同,local conv在不同的像素位置使用不同的权值,这样能够高效地提取丰富的信息,主要应用在人脸识别领域,但local conv不仅会带来与特征图大小相关的参数量,还会破坏平移不变性。
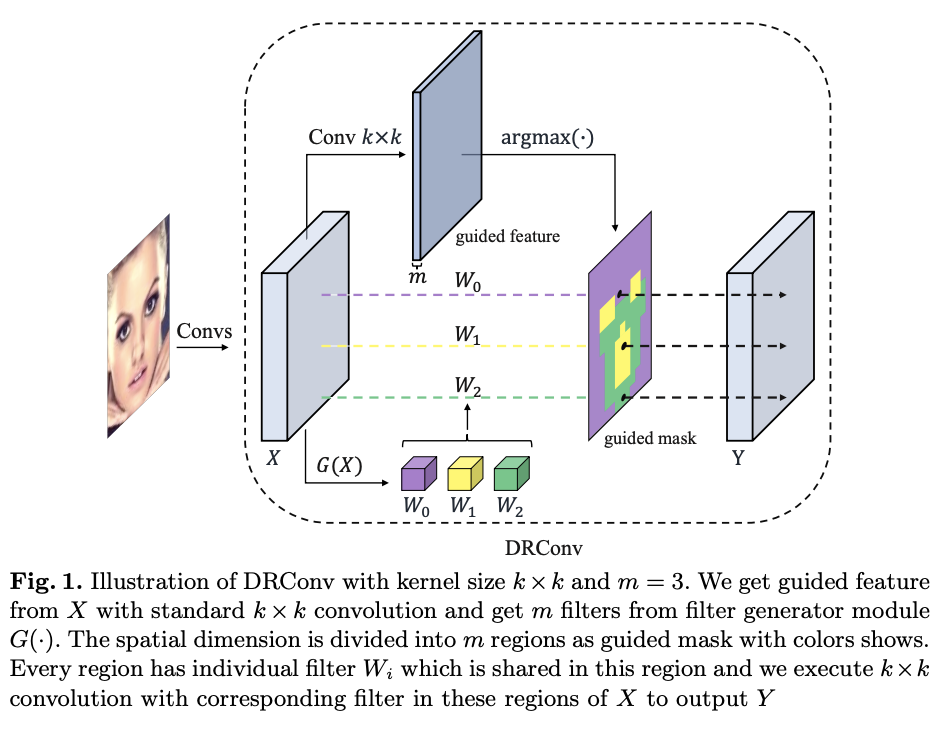
考虑到以上两种卷积的优劣,论文提出了DRConv(Dynamic Region-Aware Convolution),DRConv的结构如图1,首先通过标准卷积来生成guided feature,根据guided feature将空间维度分成多个区域,卷积核生成模块根据输入图片动态生成每个区域对应的卷积核。DRConv能够可学习地为不同的像素位置匹配不同的卷积核,不仅具有强大的特征表达能力,还可以保持平移不变性。由于卷积核是动态生成的,能比local conv减少大量的参数,而整体计算量几乎和标准卷积一致。
论文的主要贡献如下:
- 提出DRConv,不仅具有强大的语义表达能力,还能很好地维持平移不变性。
- 巧妙的设计了可学习guided mask的反向传播,明确区域共享的规则(region-sharing-pattern),并根据损失函数回传的梯度进行更新。
- 只需简单地替换,DRConv就能在图片分类,人脸识别,目标检测和语义分割等多个任务上达到很好的性能。
Our Apporach
Dynamic Region-Aware Convolution
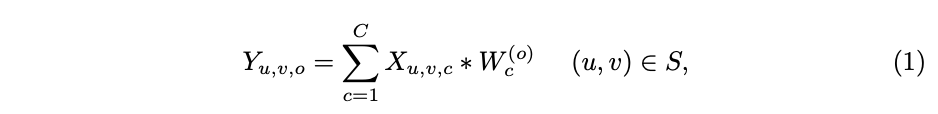
对于标准卷积,定义输入,空间维度
,输出
,权重
,输出的每个channel的计算如公式1,
为二维卷积操作。
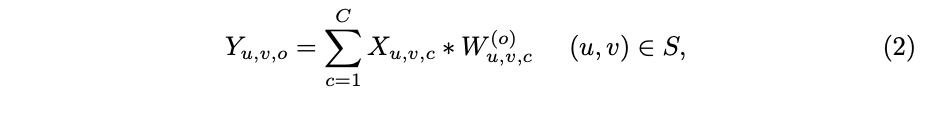
对于基础的local conv,定义非共享权重,输出的每个channel计算如公式2,其中
表示位置
上的独立非共享卷积核,即卷积在特征图上移动时,每次更换不同的卷积核。
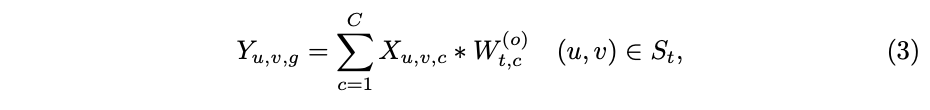
结合以上公式,定义guided mask用来表示空间维度划分的
个区域,
根据输入图片的特征进行提取,每个区域
仅使用一个共享的卷积核。定义卷积核集
,卷积核
对应于区域
。输出的每个channel的计算如公式3,即卷积在特征图上移动时,每次根据guided mask更换对应的卷积核。
从上面的描述可以看到,DRConv包含两个主要部分:
- 使用可学习的guided mask来将空间维度划分为多个区域,如图1所示,guided mask中相同颜色的像素归为同一区域,从语义的角度来看,即将语义相似的特征归为统一区域。
- 对于每个共享区域,使用卷积核生成模块来生成定制的卷积核来进行常规的2D卷积操作,定制的卷积核能够根据输入图片的重要特征自动地进行调节。
Learnable guided mask
作为DRConv的重要部分,guided mask决定了卷积核在空间维度上的分布,该模块由损失函数指导优化,从而能够适应输入的空间信息变化,从而改变卷积核的分布。
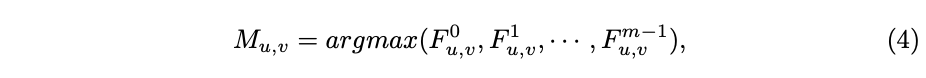
对于包含个channel的
DRConv,定义
为guided feature,
为guided mask,
上的每个位置
的值计算如公式4,函数
输出最大值的下标,
为位置
上的guided feature向量,所以
的值为
,用来指示该位置对应的卷积下标。
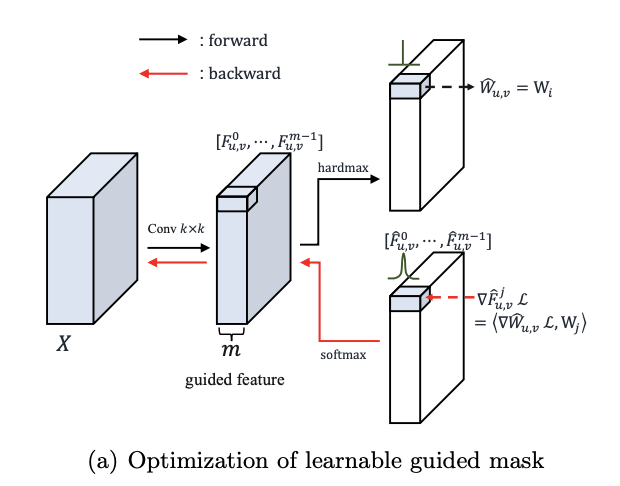
为了让guided mask可学习,必须得到用来生成guided feature的权值的梯度,但由于的使用导致guided feature的梯度无法计算,所以论文设计了类似的梯度。
-
Forward propagation
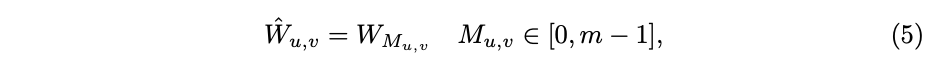
根据公式4获得guided mask,根据公式5得到每个位置得到卷积核
,其中
是
生成的卷积核集
中的一个,
是guided feature在位置
上值最大的channel下标,通过这种方式来
个卷积核与所有位置的关系,将空间像素分为
个组。使用相同卷积核的像素包含相似的上下文信息,主要由于具有平移不变性标准卷积将这些信息传递给了guided feature。
-
Backward propagation
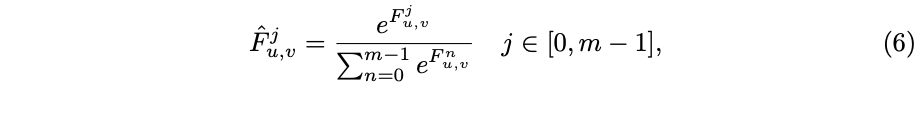
为了使梯度得到回传,首先用来代替guided mask的one-hot表示,计算如公式6所示,在channel维度上进行
,期望
能尽可能地接近0和1,这样
与guided mask的one-hot表示将非常相似。公式5可以看作是卷积核集
乘以
的one-hot表示,这里替换为
。
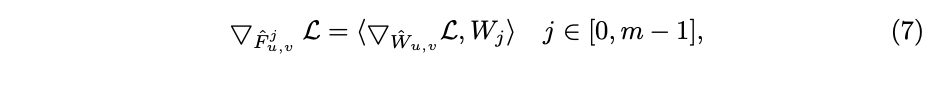
的梯度计算如公式7,
为点积,
表示guided mask对应loss函数的梯度,如图a,公式7近似于公式5的反向传播。
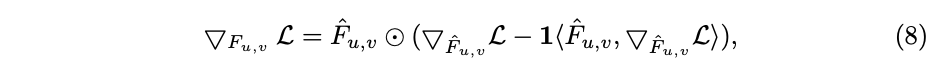
公式8为公式6的反向传播,为逐元素相乘,如果不设计特殊的反向传播,SGD将不能对相关的参数进行优化,因为函数
是不可导的。因此,
是用来接近
,通过替换函数将梯度回传到guided feature,是的guided mask可学习。
Dynamic Filter: Filter generator module
在DRConv中,使用卷积核生成模块来生成不同区域的卷积核,由于不同图片的特征不同,在图片间共享的卷积核不能高效地提取其独有的特征,需要定制化的特征来专注不同图片的特性。
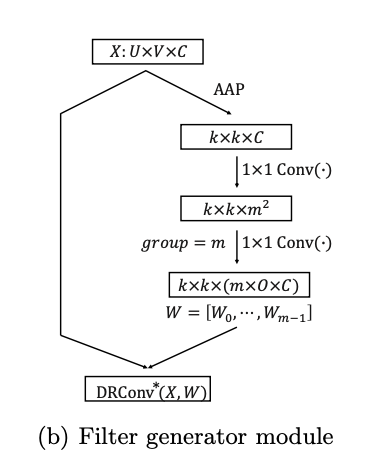
定义输入,包含两层卷积的卷积核生成模块
,
个卷积
,每个卷积仅用于区域
。如图b所示,为了获得
个
卷积,先使用自适应平均池化将
下采样为
,然后使用两个连续的
卷积,第一个使用
进行激活,第二个设定
,不使用激活。卷积核生成模块能够增强网络获取不同图片特性的能力,由于根据输入的特征生成卷积核,每个卷积核的关注点能够根据输入的特性进行自动地调整。
Experiments
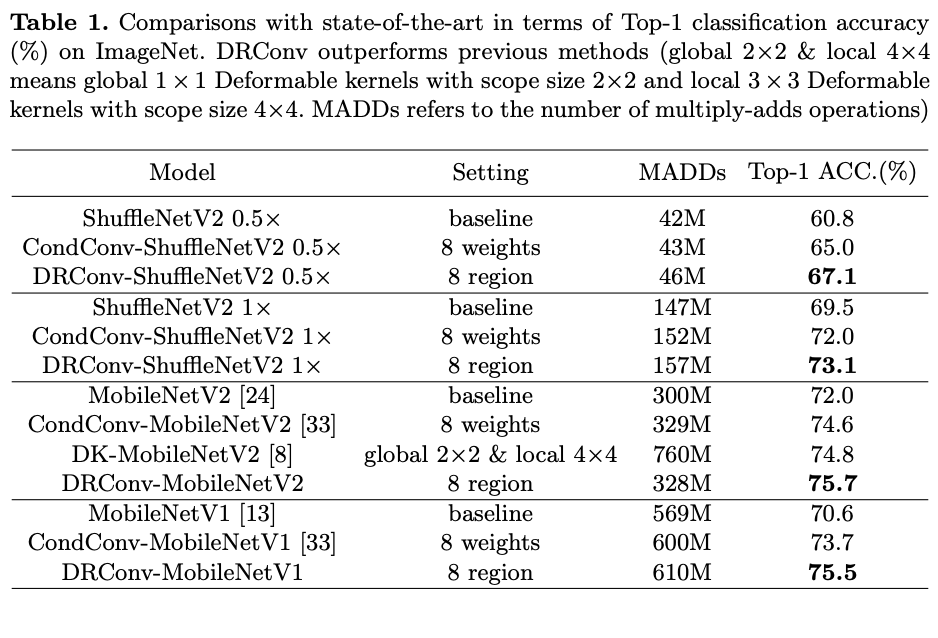
Classification
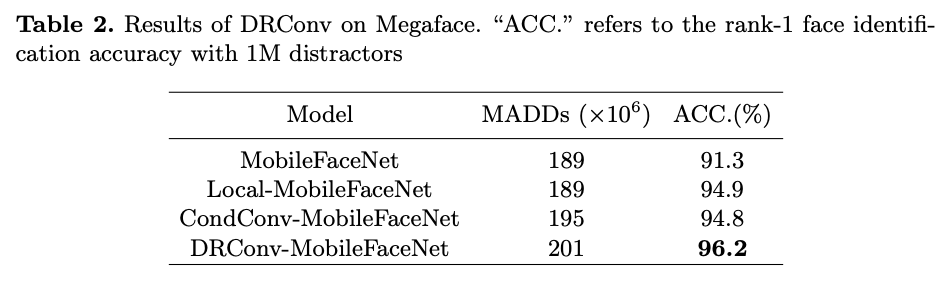
Face Recognition
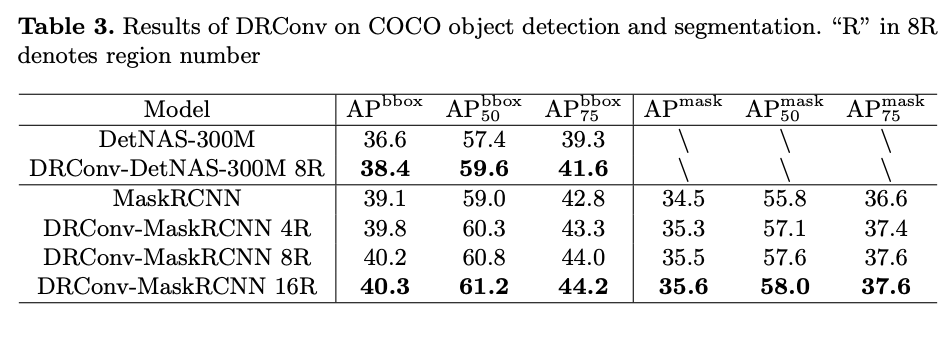
COCO Object Detection and Segmentation
Ablation Study
Visualization of dynamic guided mask

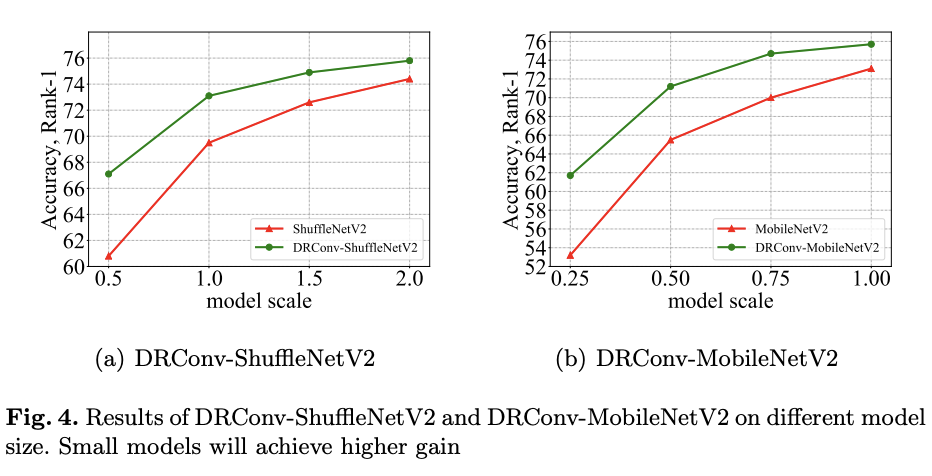
Different model size
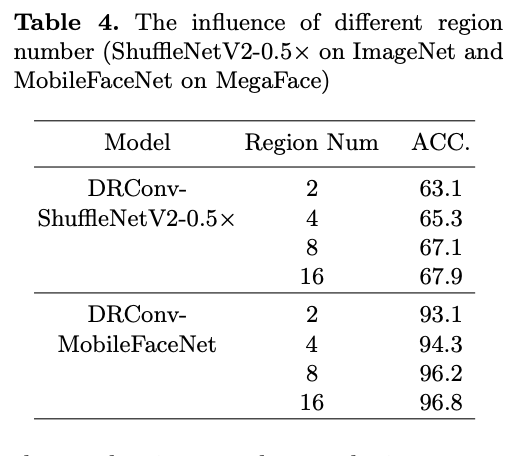
Different region number
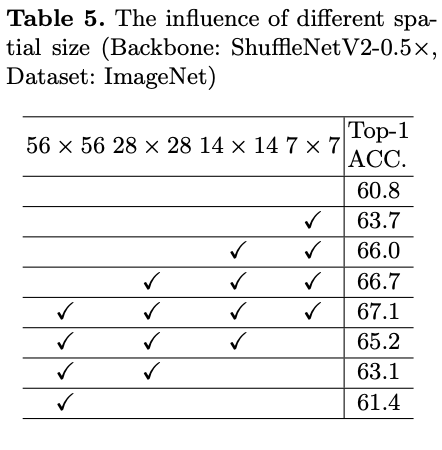
Different spatial size
CONCLUSION
论文提出DRConv,很好地结合了局部共享的思想并且保持平移不变性,包含两个关键结构,首先使用guided mask对特征图中的像素划分到不同的区域,其次使用卷积核生成模块动态生成区域对应的卷积核。从实验结果来看,DRConv符合设计的预期,特别是图3的guided mask的可视化结果,在多个任务上都有不错的性能提升。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

