

本文始发于个人公众号:TechFlow,原创不易,求个关注
今天这篇是算法与数据结构专题的第23篇文章,我们继续数论相关的算法,来看看大名鼎鼎的埃式筛法。
我们都知道在数学领域,素数非常重要,有海量的公式和研究关于素数,比如那个非常著名至今没有人解出来的哥德巴赫猜想。和数学领域一样,素数在信息领域也非常重要,有着大量的应用。举个简单的例子,很多安全加密算法也是利用的质数。我们想要利用素数去进行各种计算之前,总是要先找到素数。所以这就有了一个最简单也最不简单的问题,我们怎么样来寻找素数呢?
判断素数
寻找素数最朴素的方法当然是一个一个遍历,我们依次遍历每一个数,然后分别判断是否是素数。所以问题的核心又回到了判断素数上,那么怎么判断一个数是不是素数呢?
素数的性质只有一个,就是只有1和它本身这两个因数,我们要判断素数也只能利用这个性质。所以可以想到,假如我们要判断n是否是素数,可以从2开始遍历到n-1,如果这n-1个数都不能整除n,那么说明n就是素数。这个我没记错在C语言的练习题当中出现过,总之非常简单,可以说是最简单的算法了。
def is_prime(n):
for i in range(2, n):
if n % i == 0:
return False
return n != 1
显然,这个算法是可以优化的,比如当n是偶数的时候,我们根本不需要循环,除了2意外的偶数一定是合数。再比如,我们循环的上界其实也没有必要到n-1,到就可以了。因为因数如果存在一定是成对出现的,如果存在小于根号n的因数,那么n除以它一定大于根号n。
这个改进也很简单,稍作改动即可:
def is_prime(n):
if n % 2 == 0 and n != 2:
return False
for i in range(3, int(math.sqrt(n) + 1)):
if n % i == 0:
return False
return n != 1
这样我们把O(n)的算法优化到了O()也算是有了很大的改进了,但是还没有结束,我们还可以继续优化。数学上有一个定理,只有形如6n-1和6n+1的自然数可能是素数,这里的n是大于等于1的整数。
这个定理乍一看好像很高级,但其实很简单,因为所有自然数都可以写成6n,6n+1,6n+2,6n+3,6n+4,6n+5这6种,其中6n,6n+2,6n+4是偶数,一定不是素数。6n+3可以写成3(2n+1),显然也不是素数,所以只有可能6n+1和6n+5可能是素数。6n+5等价于6n-1,所以我们一般写成6n-1和6n+1。
利用这个定理,我们的代码可以进一步优化:
def is_prime(n):
if n % 6 not in (1, 5) and n not in (2, 3):
return False
for i in range(3, int(math.sqrt(n) + 1)):
if n % i == 0:
return False
return n != 1
虽然这样已经很快了,但仍然不是最优的,尤其是当我们需要寻找大量素数的时候,仍会消耗大量的时间。那么有没有什么办法可以批量查找素数呢?
有,这个方法叫做埃拉托斯特尼算法。这个名字念起来非常拗口,这是一个古希腊的名字。此人是个古希腊的大牛,是大名鼎鼎的阿基米德的好友。他虽然没有阿基米德那么出名,但是也非常非常厉害,在数学、天文学、地理学、文学、历史学等多个领域都有建树。并且还自创方法测量了地球直径、地月距离、地日距离以及黄赤交角等诸多数值。要知道他生活的年代是两千五百多年前,那时候中国还是春秋战国时期,可以想见此人有多厉害。
埃式筛法
我们今天要介绍的埃拉托斯特尼算法就是他发明的用来筛选素数的方法,为了方便我们一般简称为埃式筛法或者筛法。埃式筛法的思路非常简单,就是用已经筛选出来的素数去过滤所有能够被它整除的数。这些素数就像是筛子一样去过滤自然数,最后被筛剩下的数自然就是不能被前面素数整除的数,根据素数的定义,这些剩下的数也是素数。
举个例子,比如我们要筛选出100以内的所有素数,我们知道2是最小的素数,我们先用2可以筛掉所有的偶数。然后往后遍历到3,3是被2筛剩下的第一个数,也是素数,我们再用3去筛除所有能被3整除的数。筛完之后我们继续往后遍历,第一个遇到的数是7,所以7也是素数,我们再重复以上的过程,直到遍历结束为止。结束的时候,我们就获得了100以内的所有素数。
如果还不太明白,可以看下下面这张动图,非常清楚地还原了这整个过程。
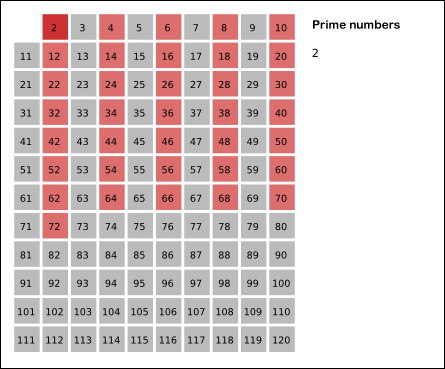
这个思想非常简单,理解了之后写出代码来真的很容易:
def eratosthenes(n):
primes = []
is_prime = [True] * (n + 1)
for i in range(2, n+1):
if is_prime[i]:
primes.append(i)
# 用当前素数i去筛掉所有能被它整除的数
for j in range(i * 2, n+1, i):
is_prime[j] = False
return primes
我们运行一次代码看看:

和我们的预期一样,获得了小于100的所有素数。我们来分析一下筛法的复杂度,从代码当中我们可以看到,我们一共有了两层循环,最外面一层循环固定是遍历n次。而里面的这一层循环遍历的次数一直在变化,并且它的运算次数和素数的大小相关,看起来似乎不太方便计算。实际上是可以的,根据素数分布定理以及一系列复杂的运算(相信我,你们不会感兴趣的),我们是可以得出筛法的复杂度是。
极致优化
筛法的复杂度已经非常近似了,因为即使在n很大的时候,经过两次ln的计算,也非常近似常数了,实际上在绝大多数使用场景当中,上面的算法已经足够应用了。
但是仍然有大牛不知满足,继续对算法做出了优化,将其优化到了的复杂度。虽然从效率上来看并没有数量级的提升,但是应用到的思想非常巧妙,值得我们学习。在我们理解这个优化之前,先来看看之前的筛法还有什么可以优化的地方。比较明显地可以看出来,对于一个合数而言,它可能会被多个素数筛去。比如38,它有2和19这两个素因数,那么它就会被置为两次False,这就带来了额外的开销,如果对于每一个合数我们只更新一次,那么是不是就能优化到
了呢?
怎么样保证每个合数只被更新一次呢?这里要用到一个定理,就是每个合数分解质因数只有的结果是唯一的。既然是唯一的,那么一定可以找到最小的质因数,如果我们能够保证一个合数只会被它最小的质因数更新为False,那么整个优化就完成了。
那我们具体怎么做呢?其实也不难,我们假设整数n的最小质因数是m,那么我们用小于m的素数i乘上n可以得到一个合数。我们将这个合数消除,对于这个合数而言,i一定是它最小的质因数。因为它等于i * n,n最小的质因数是m,i 又小于m,所以i是它最小的质因数,我们用这样的方法来生成消除的合数,这样来保证每个合数只会被它最小的质因数消除。
根据这一点,我们可以写出新的代码:
def ertosthenes(n):
primes = []
is_prime = [True] * (n+1)
for i in range(2, n+1):
if is_prime[i]:
primes.append(i)
for j, p in enumerate(primes):
# 防止越界
if p > n // i:
break
# 过滤
is_prime[i * p] = False
# 当i % p等于0的时候说明p就是i最小的质因数
if i % p == 0:
break
return primes
总结
到这里,我们关于埃式筛法的介绍就告一段落了。埃式筛法的优化版本相对来说要难以记忆一些,如果记不住的话,可以就只使用优化之前的版本,两者的效率相差并不大,完全在可以接受的范围之内。
筛法看着代码非常简单,但是非常重要,有了它,我们就可以在短时间内获得大量的素数,快速地获得一个素数表。有了素数表之后,很多问题就简单许多了,比如因数分解的问题,比如信息加密的问题等等。我每次回顾筛法算法的时候都会忍不住感慨,这个两千多年前被发明出来的算法至今看来非但不过时,仍然还是那么巧妙。希望大家都能怀着崇敬的心情,理解算法当中的精髓。
如果喜欢本文,可以的话,请点个关注,给我一点鼓励,也方便获取更多文章。
本文使用 mdnice 排版

