

这系列主要是我对WASM研究的笔记,可能内容比较简略。总共包括:
- 深入浅出WebAssembly(1) Compilation
- 深入浅出WebAssembly(2) Basic Api
- 深入浅出WebAssembly(3) Instructions
- 深入浅出WebAssembly(4) Validation
- 深入浅出WebAssembly(5) Memory
- 深入浅出WebAssembly(6) Binary Format
- 深入浅出WebAssembly(7) Future
- 深入浅出WebAssembly(8) Wasm in Rust(TODO)
The binary format for WebAssembly modules is a dense linear encoding of their abstract syntax.
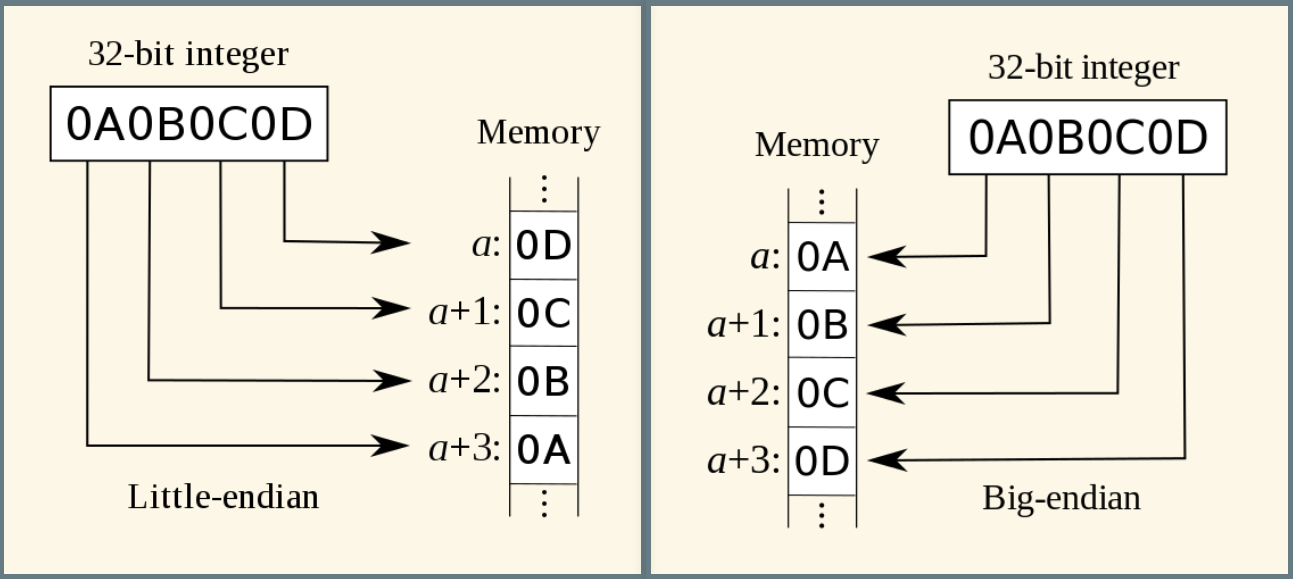
Little Edian and BigEdian
- 小端序(little endian): 数字低位存储在内存低位,方便加法运算
- 大端序(big endian): 数字低位存储在内存高位,方便除法运算
Conventions
\epsilon 代表空byte序列
||B|| 代表过程B产生的byte序列长度
Values
Bytes
bytes encode themselves
Integers
无符号整数:
N < 7 将会导致 ceil(N/7) 为1或0 不需要编码
有符号整数:
-
表达式解释
大概是一个递归的形式,n代表当前整数的低7位字节,m代表其余的高位字节,以一个
N1 = N - 7位的数表示,这个数可以继续变成7位和一个N2 = N1 - 7...无符号整数的编码结果是:如果n不足7位(
n < 2^7),那么等于原值。如果高于7位,那么高位字节左移7位(m*2^7等价于m << 7) ,再把低位字节减去2^7,需要注意的是2^7最高位是在第8位(1后面7个0),减去一个数等于加上这个数的补码。所以意思是把低位的n的8位之后全部置为1。至于为什么中间用+号,我也母鸡事实上这就是LEB128编码的内容,觉得难以理解的可以直接看下文
Float
直接由IEEE 754-2019标准编码,以little endian顺序储存
Name
直接由utf8编码
unsigned LEB128
624485
MSB ------------------ LSB
10011000011101100101 In raw binary
010011000011101100101 Padded to a multiple of 7 bits
0100110 0001110 1100101 Split into 7-bit groups
00100110 10001110 11100101 Add high 1 bits on all but last (most significant) group to form bytes
0x26 0x8E 0xE5 In hexadecimal
→ 0xE5 0x8E 0x26 Output stream (LSB to MSB)
signed LEB128
-123456
MSB ------------------ LSB
11110001001000000 Binary encoding of 123456
000011110001001000000 As a 21-bit number
111100001110110111111 Flipping all bits (one’s complement)
111100001110111000000 Adding one (two’s complement)
1111000 0111011 1000000 Split into 7-bit groups
01111000 10111011 11000000 Add high 1 bits on all but last (most significant) group to form bytes
0x78 0xBB 0xC0 In hexadecimal
→ 0xC0 0xBB 0x78 Output stream (LSB to MSB)
signed 和 unsigned LEB128对正数编码的结果不完全一样:可以用上面的C++代码动手试试 65 的编码结果 这也是为什么规范中的有符号的表达式多了一种条件的原因:保证同样一个正整数在unsigned 或者 signed LEB128编码之后的结果完全一致
Example
下面解读一下一个简单的wasm模块二进制,源代码:Github
~: hexdump -C index.wasm
00000000 00 61 73 6d 01 00 00 00 01 10 03 60 00 00 60 02 |.asm.......`..`.|
00000010 7f 7f 01 7f 60 02 7c 7c 01 7c 03 05 04 00 01 02 |....`.||.|......|
00000020 01 04 05 01 70 01 01 01 05 03 01 00 02 06 15 03 |....p...........|
00000030 7f 01 41 80 88 04 0b 7f 00 41 80 88 04 0b 7f 00 |..A......A......|
00000040 41 80 08 0b 07 48 06 06 6d 65 6d 6f 72 79 02 00 |A....H..memory..|
00000050 0b 5f 5f 68 65 61 70 5f 62 61 73 65 03 01 0a 5f |.__heap_base..._|
00000060 5f 64 61 74 61 5f 65 6e 64 03 02 08 5f 5a 33 61 |_data_end..._Z3a|
00000070 64 64 69 69 00 01 08 5f 5a 33 61 64 64 64 64 00 |ddii..._Z3adddd.|
00000080 02 0a 5f 5a 35 6d 69 6e 75 73 69 69 00 03 0a 1c |.._Z5minusii....|
00000090 04 02 00 0b 07 00 20 01 20 00 6a 0b 07 00 20 00 |...... . .j... .|
000000a0 20 01 a0 0b 07 00 20 00 20 01 6b 0b 00 50 04 6e | ..... . .k..P.n|
000000b0 61 6d 65 01 49 04 00 11 5f 5f 77 61 73 6d 5f 63 |ame.I...__wasm_c|
000000c0 61 6c 6c 5f 63 74 6f 72 73 01 0d 61 64 64 28 69 |all_ctors..add(i|
000000d0 6e 74 2c 20 69 6e 74 29 02 13 61 64 64 28 64 6f |nt, int)..add(do|
000000e0 75 62 6c 65 2c 20 64 6f 75 62 6c 65 29 03 0f 6d |uble, double)..m|
000000f0 69 6e 75 73 28 69 6e 74 2c 20 69 6e 74 29 |inus(int, int)|
Magic Number
[00 61 73 6d]
通过hex to ascii解码可得:"\0asm" Hex to ASCII | Hex to Text String converter
Version
[01 00 00 00]
当前版本号为1
Section
接下来是一系列数据段构成,这些段结构按照索引空间顺序排列,宏观上具有相同的结构:
定义为:
N也就是段的id,对应的含义为:
| 段结构类型 | id字段值 | 描述信息 |
|---|---|---|
| Type | 1 | 模块内函数签名定义 |
| Import | 2 | 模块内导入信息定义 |
| Function | 3 | 模块内函数定义 |
| Table | 4 | 模块表结构定义 |
| Memory | 5 | 模块线性内存段定义 |
| Global | 6 | 模块全局变量定义 |
| Export | 7 | 模块导出信息定义 |
| Start | 8 | 模块初始化钩子 |
| Element | 9 | Table初始化 |
| Code | 10 | 模块内函数的函数体定义 |
| Data | 11 | 模块数据段的定义 |
下面具体分析:
[01]
代表接下来的是Type段,然后再看看:
[10...]
通过解码可以发现 0x10 => 16,说明当前Type段的长度是16,也就是接下来16个数字都是Type:
[03 60 00 60 02 7f 7f 01 7f 60 02 7c 7c 01 7c]
Type
Type段的类型定义为:
[03...]
可以看到包含3个functype, functype的定义为:
根据之前valtype的定义我们可以解析接下来的二进制代码:
06 00 00
将会被解析成一个空函数:
func
接下来:
06 02 7f 7f 01 7f -> func(param i32 i32)(result i32)
60 02 7c 7c 01 7c -> func(param f64 f64)(result f64)
Function
接下来是Function的定义:
03 05 ...
说明接下来5个数字会是Function段:
[04 00 01 02 01]
Function段的定义是:
也即拥有4个function,第一个对应type 0, 第二个对应type 1,第三个对应type2, 第四个对应type1
Table
过程不在赘述,相应OpCode含义可以查看spec。
04 05 01 70 01 01 01 -> table 1 1
Memory
05 03 01 00 02 -> memory 2
Gobal
06 15 03 7f 01 41 80 88 04 0b 7f 00 41 80 88 04 0b 7f 00 41 80 08 0b
7f 01 -> i32 var
41 80 88 04 0b -> i32.const 66560
7f 00 -> i32 const
41 80 88 04 0b -> i32.const 66560
7f 00 -> i32 const
41 80 08 0b -> i32.const 1024
其余请自行查表~
