


随着近几年分布式、微服务架构的火热,RPC 在开发工作中使用的越来越多,也变的越来越重要。 作为一个学生,在学校接触到的大多都是 SSM 这类单体应用,但实习后发现,基本是接触不到从 0 到 1 的项目的,更多的是在为整个大系统的某个小模块添砖加瓦。因此,模块与模块之间的通信就变得异常重要。
集群、微服务、分布式
《道德经》是老子的宇宙生成论,其中“一生二,二生三”广为流传,对于一个软件系统来说,笔者认为这句话也同样适用。所谓一,便是系统的业务需求,无论何人,其编写的每行代码最后都是为了服务业务,或是实现业务功能,或是提升业务性能,最终目的均无法逃离业务。一般意义上,一个公司的业务系统发展脉络基本都是类似的:从单个应用到多个应用,从本地调用到远程调用,随着业务规模的发展,需要对远程服务进行高效的资源管理。于是分布式、集群、微服务等**“银弹”**便应运而生。
在欧洲民间传说的影响下,银弹往往被描绘成具有驱魔功效的武器。 后来也被比喻为具有极端有效性的解决方法。不过佛瑞德·布鲁克斯所发表一篇关于软件工程的论文中提到在软件工程领域是没有银弹的,复杂的软件工程问题无法靠简单的答案来解决
为了分散业务能力,出现了“微服务”;为了分散机器压力,出现了“集群”和“分布式”。那这三者有何关联?我们以一张图来说明:
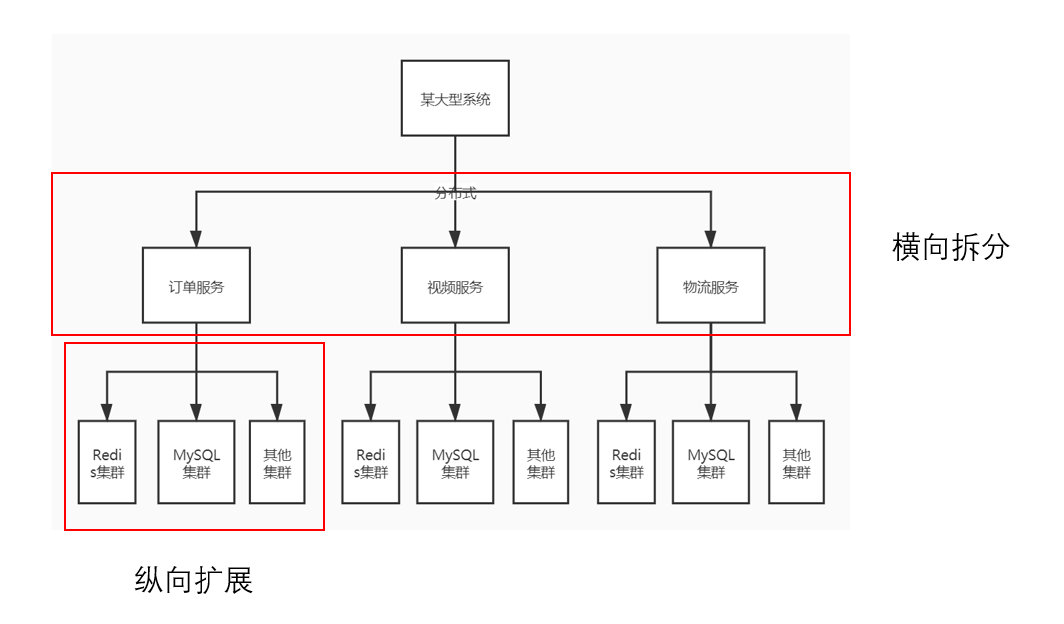
某大型系统下有众多功能,如订单、视频、物流等,项目初期可能是写在一个大的工程里,部署在一台机子上,后来业务发展了,每个子功能都变得相当复杂,用 IDE 打开这个项目都要花好久,为了方便开发,开发团队将每个功能分开,并起名为“服务”。每个服务可以操作自己的数据库、缓存等,也可以在本机与其他服务通信(这时项目仍然部署在一台机子上)。再后来,一个 DB、Redis 已经没办法满足这个服务的需求,所以又将单个 DB 扩展成 DB 集群,单个 Redis 扩展成 Redis 集群以此来分担机器的压力。再后来,这些服务所在服务器的性能被压榨的一滴也没有了,没办法,只能将这些服务一个个的分在不同的机器上,这就是**“分布式”**。
由此可见,集群,是在多台机器上部署相同的程序,对于集群内部而言,每台机器是一个不同的节点。但对于集群外部(调用方)而言,集群就是一个整体,操作起来就和操作单个数据库、单个 Redis 没有任何区别。对于整个项目来说,如果集群中某个节点挂了,整个集群仍然可以正常工作,这是一种纵向的扩展。
而分布式,是指在多台机器上部署不同的模块。这些模块原本可以放在一台机器上,这叫中心化,一旦这台机器崩溃,上面所有的服务就会崩溃,整个项目也就崩溃了。因此我们可以将系统横向拆分成多个服务后部署到不同的服务器上,如果一台机器崩溃,虽然这台机器上的服务也会崩溃,但不至于导致整个系统发生崩溃,这叫去中心化。
所以随着业务的发展,微服务、集群、分布式这些名词的出现是很有必要的。
RPC 的三个问题
上面我们用了一定篇幅解释了微服务、集群、分布式这些比较火的名词,接下来我们回到本文的主角——RPC。
RPC(Remote Procedure Call),即远程过程调用。不同于本地调用,函数与函数之间同属于同一块内存空间,如需调用某个函数,只需要找到所在内存地址即可。远程调用,通俗地说,便是有两台服务器 A,B,一个应用部署在 A 服务器上,想要调用 B 服务器上应用提供的函数/方法,需要通过网络来表达调用的语义和传达调用的数据。
知道了 RPC 是什么,以及为什么需要 RPC 后,接下来我们就要看看如何实现 RPC 了。文末我会给出一个简单的用 Java 实现 RPC 的 demo,这里先从一个有趣例子出发给出需要解决的三个问题:Call ID 映射、序列化和反序列化、网络传输。
从一个有趣的例子出发
笔者之前写过一篇《从找对象到多线程》,文中以找对象这个例子出发,介绍了线程,这次就让我们开一个线程来看一下远程调用 RPC 吧。

笔者的好友在一个男生如云的工科学校,机缘巧合下,喜欢上一个隔壁学校的妹子,终于有一天他决定告白。所以,第一步就是要知道那个女生所在的学校、年级、班级、姓名等相关信息,确定到那个人,这个过程就是Call ID 映射。由于疫情的原因,虽然各自都开学了,但都被学校强制封闭性管理,无法直接见面,因此,男生就想着用**情书的方式表达自己的爱慕之意,这个过程就是序列化**。男生想着,只要女生收到情书后便能**理解自己的爱慕之情,就会和自己在一起了,这就是反序列化**。剩下的就是如何将情书**送过去了。可选的方式有很多,比如找快递小哥送、发微信、发邮件之类的,只要能将信息传送过去就可以。这个过程就是网络传输**。
Call ID 映射
不知道上面的例子有没有很好的解释Call ID 映射、序列化和反序列化、网络传输是什么东西。将上述例子类比到项目中,我们就能很好的理解为什么需要解决这些问题了。
类比本地调用函数,我们需要知道函数名,Call ID 就类似于这样的标志,只有这样才知道你需要的调用的是什么。如果没有 Call ID,我们就无法得知需要调用的方法是什么。
所以,在 RPC 中,所有的函数都必须有自己的一个 ID。这个 ID 在所有进程中都是唯一确定的。客户端在做远程过程调用时,必须附上这个 ID。然后我们还需要在客户端和服务端分别维护一个 {函数 - >Call ID} 的对应表。两者的表不一定需要完全相同,但相同的函数对应的 Call ID 必须相同。当客户端需要进行远程调用时,它就查一下这个表,找出相应的 Call ID,然后把它传给服务端,服务端也通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。
序列化和反序列化
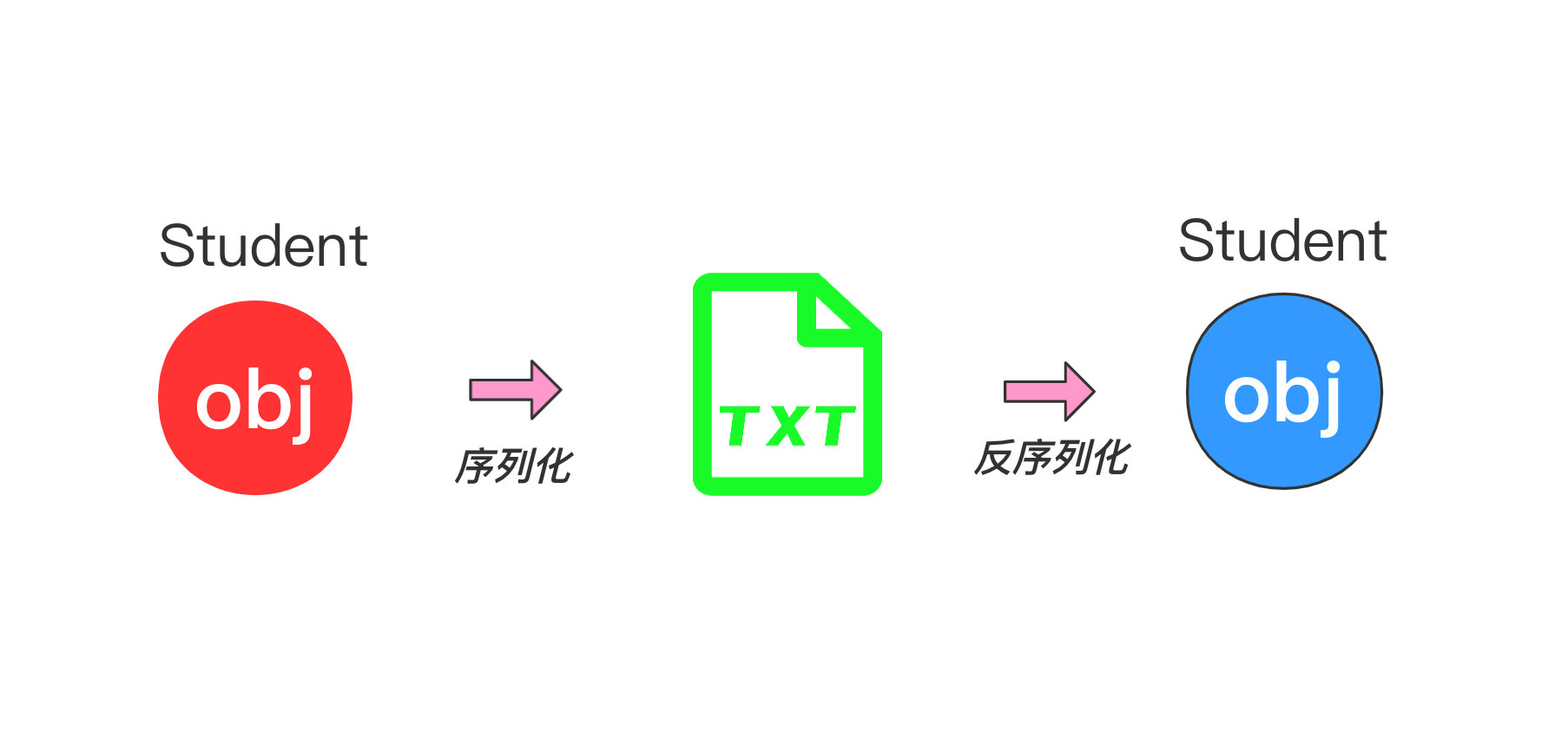
序列化可以简单理解为对象 –> 字节的过程,同理,反序列化则是相反的过程。这一过程的目的可以理解为转义,然后方便传输,就和上文例子中的把爱慕之情->文字(情书)也是为了方便传输。因为网络传输只认字节,所以互信的过程依赖于序列化与反序列化。
我们知道,在本地调用中,我们只需要把参数压到栈里,然后让函数自己去栈里读就行。但是在远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数。甚至有时候客户端和服务端使用的都不是同一种语言(比如服务端用 C++,客户端用 Java 或者 Python)。这时候就需要客户端把参数先转成一个字节流,传给服务端后,再把字节流转成自己能读取的格式。
常见的序列化方式有 JDK 自带序列化(Serializable 接口),HESSIAN 序列化,Kryo 序列化等。后面我们可以详细聊一聊这些序列化方式。
网络传输
不管采取什么样的序列化方式,最终目的都是为了方便传输,所有的数据都需要通过网络传输,因此 RPC 的实现就需要有一个网络传输层。
网络传输层需要把 Call ID 和序列化后的参数字节流传给服务端,然后再把序列化后的调用结果传回客户端。因此,它所使用的协议其实是不限的,能完成传输就行。
常见的有 HTTP、TCP、当然 UDP 也是可以用于 RPC 的。至于为什么已经有了 HTTP 传输协议,为什么许多 RPC 框架还是会使用 TCP,之后我会单独写一篇文章谈谈我自己的看法。
一个简单的RPC实现
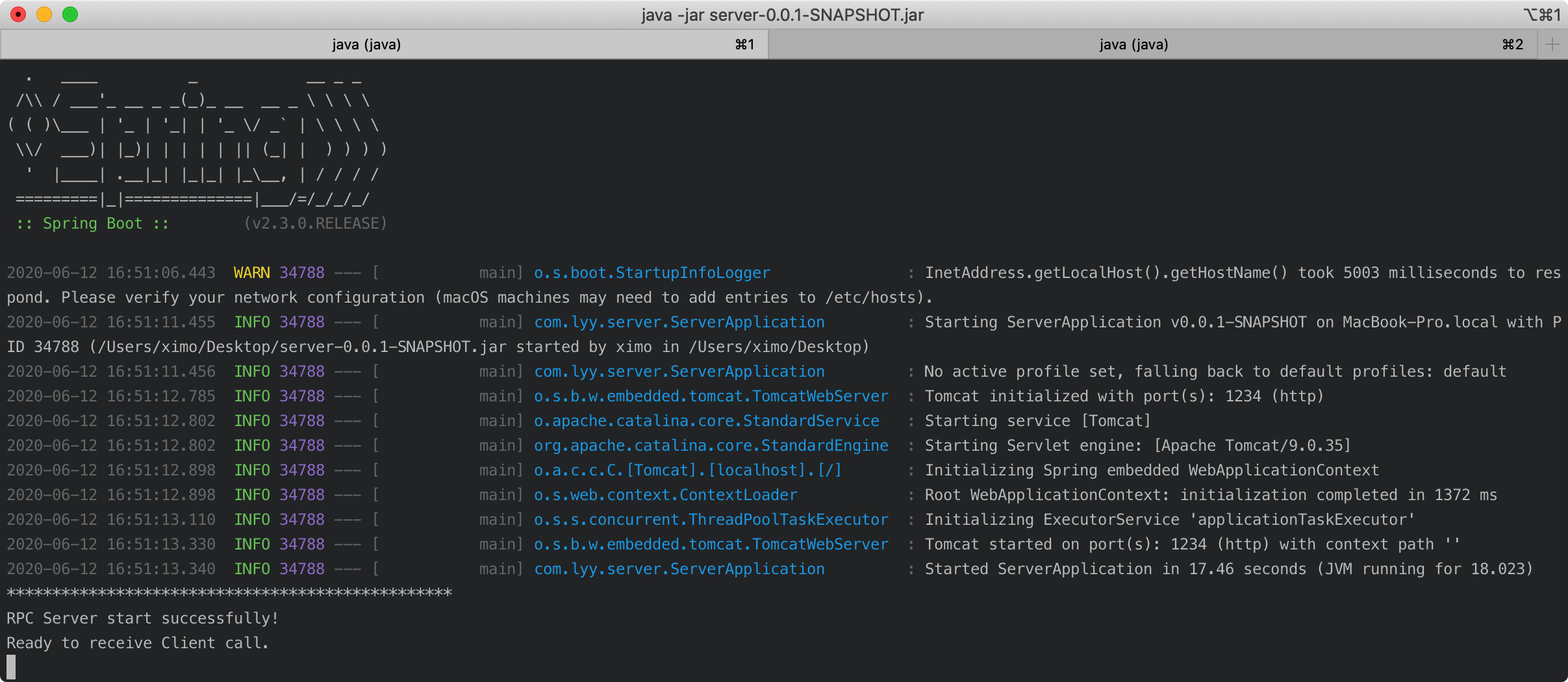
为了直观的感受 RPC 通信,笔者实现了一个简易的 RPC 通信的 demo,开两个 terminal 分别执行 java -jar server-0.0.1-SNAPSHOT.jar 和 java -jar client-0.0.1-SNAPSHOT.jar 便可以在控制台看到相应的输出。
server
client
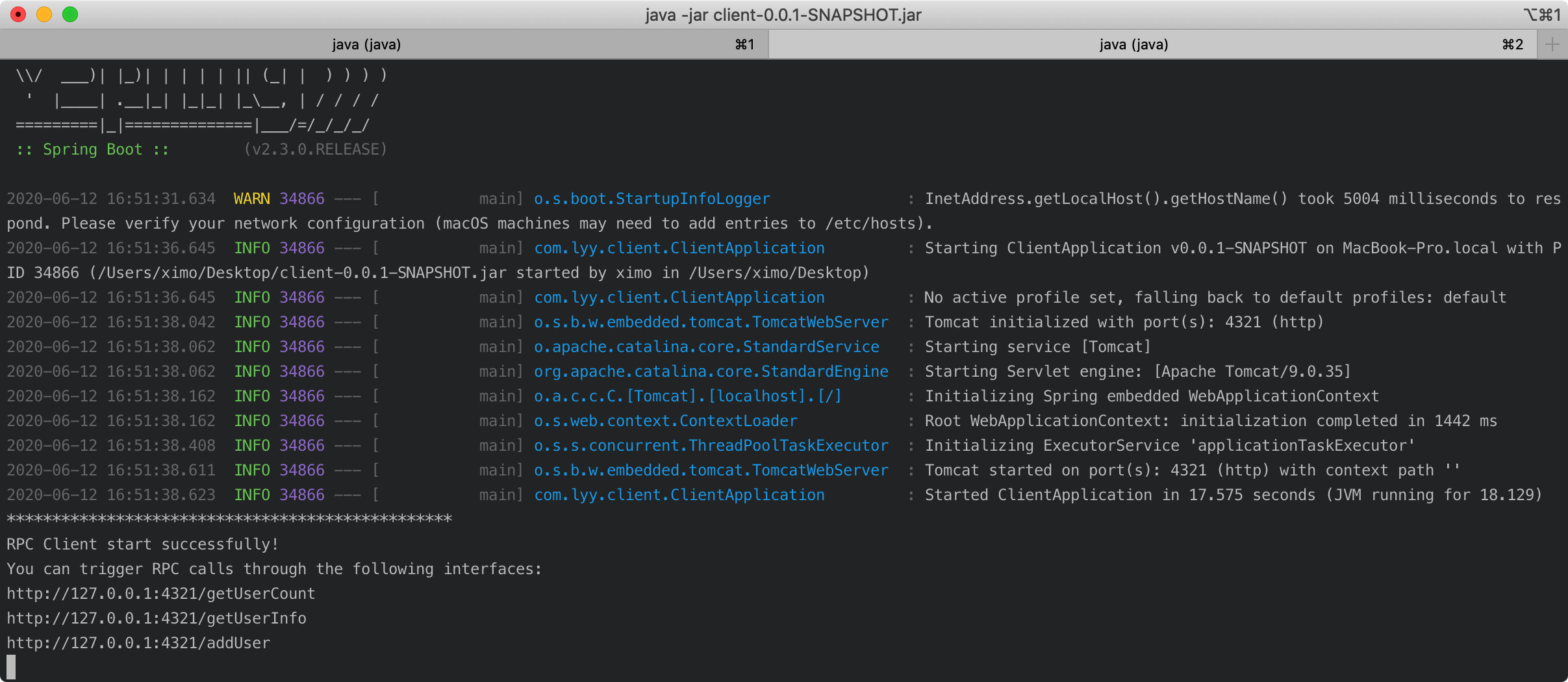
这时,我们再开另一个 terminal 执行 curl http://127.0.0.1:4321/getUserInfo 来模拟请求,我们可以得到如下的响应 body:
➜ curl http://127.0.0.1:4321/getUserInfo
{"sex":0,"name":"name","id":1,"schoolName":"Sunny School","email":"name@sample.com","age":19}
这时我们再来看 server 和 client 的输出有什么变化
server

client

由此我们看见,我们请求 client 的接口,进而转发到 server 上,如果以后想要扩展需要的服务,只需要多加一个服务的 jar 包就可以了(当然这是最简单的实现)。
如果想要了解具体实现的,可以点击下面链接获取代码 👇
该项目简化了 RPC 中的一些操作,例如 Call ID 映射直接通过指定字符串来实现,实际项目中是通常会有一个配置中心负责持久化调用的 ip、端口、函数名、参数等信息。为了简化通信,使用了 HTTP 作为网络传输协议,通信框架采用 OkHttp。另外,本项目涉及到一些前置知识,例如动态代理、自定义注解等,有兴趣的小伙伴也可以学习了解下。
以上就是本篇文章的全部内容了,如果觉得文章对你有所帮助,不妨给个赞支持一下。

