

啥是ZAB协议?
ZAB其实就是Zookeeper Atomic Broadcast,也就是zookeeper原子广播,是zookeeper用来保持分布式事务一致性的一种协议
ZAB其实就是定义了zookeeper集群在运行过程中的一些通信准则,包括像信息同步,选举,故障转移等机制的一些实现。
ZAB协议的内容其实主要包括两个模块:消息广播和崩溃恢复
消息广播
当zookeeper集群在正常进行的时候,各个结点之间需要保持最终一致性,此时就需要消息广播机制。
在zookeeper集群中,节点分为一个leader节点和若干个follower节点。当Client向集群发送请求时,该请求有可能落在集群中的任何一个节点上(当然,准确来说不是全部,在启动zookeeper-cli的时候可以指定若干个节点的 ip:port,请求只会落在这些节点上),这个节点如果是leader的话,那么直接对该请求进行处理,如果该节点是follower的话,那么follower还需要把该请求转发给集群中的leader,让leader来处理
所以,该请求最终都会落在leader上,leader收到该请求,会将该请求解析成一个对应的事务proposql,同时为该proposql分配一个全局唯一且递增的id(zxid),该id为64位的值,高32位为epoch,低32位为自增值。
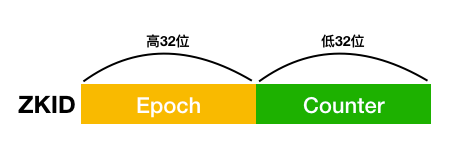
epoch是一个与选举相关的自增数字,整个zookeeper集群每经历一次选举,epoch的值就+1
而低32位,每次选举完一次后就归零,然后自增,以此来保证事务id在全局的递增(这一点在进行崩溃恢复的时候很重要)
而生成这个事务proposql之后,leader就会将该事务持久化到磁盘中,leader会为每个follower都维护一个单独的FIFO(先来先服务)队列,将该事务加入队列中进行发送,以此来保证全局顺序性。follower收到之后,就会将该事务持久化到磁盘中,然后向leader发送一个ack。当leader收到超过半数的follower发来的ack后,就可以向它们发送commit指令,然后follower们进行commit
是不是有点像两阶段提交?确实很像,但和两阶段提交最大的区别就是,两阶段阶段中,leader必须收到所有follower的ack,而在zookeeper的ZAB中,只需要收到过半的ack即可进行ack
崩溃恢复
如果所有的集群在整个服务期间都能正常运行而不发生崩溃就好了~但这可能嘛?(哭
很明显是不可能的,所以跟大多数集群一样,zookeeper集群也应该有故障转移和恢复的机制,主要是针对leader节点的崩溃而进行的。有三种情况会触发leader
选举
恢复的方法也很简单,重新选举出一个新的leader不就好了?用的也是类似于paxos算法的思想,各个节点进行多轮投票,然后互相交换投票,再根据zxid修改投票,然后进行下一轮投票,直到过半的票数都指向同一个节点,那么该节点就成为了leader。
选举原则大致为: 1)epoch 最大的 2)若 epoch 相等,选 zxid 最大的 3)若 epoch 和 zxid 都相等,则选择 server_id 最大的(也就是zoo.cfg中的myid)
发现
选出一个leader之后,下一步就是发现阶段。发现阶段其实主要就是收集follower最近接受的事务,为下一步的数据同步作准备
并且可以肯定的是,选出来的这个leader拥有最大的zxid,为啥要选出一个拥有最大zxid的节点呢?考虑这两种情况:
同步
- leader节点生成了事务proposql,且持久化到了磁盘中,然后还没来得及发送给follower们,就宕机了
- leader节点收到了过半的ack,commit还没发送,就宕机了
对于情况一,需要对这种事务进行丢弃;而对情况二,需要对follower进行协同,使得全部follower都变成提交状态
那为什么要选一个zxid最大的节点作为leader就清楚了,其实以上两种情况如果发生了,那么最大zxid的那个事务就是出问题的那个事务,根据这个事务的执行程度来进行协同,最后保证最终一致性即可。
选举完了,协同完了,那下一步干啥?此时集群已经恢复到正常情况了,所以直接切换成消息广播模式,进行信息同步即可
所以,总结一下,崩溃恢复分为三步:1.选举 2.同步 3.同步 4.切换为广播模式
