

简介
由Scala开发的高性能跨语言分布式消息队列,单机吞吐量可以达到10W级,消息延迟在ms级。Kafka是完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,依赖于Zookeeper做分布式协调。Kafka支持一写多读,消息可以被多个客户端消费,消息可能会有重复,但不会丢失。
Kafka核心组成
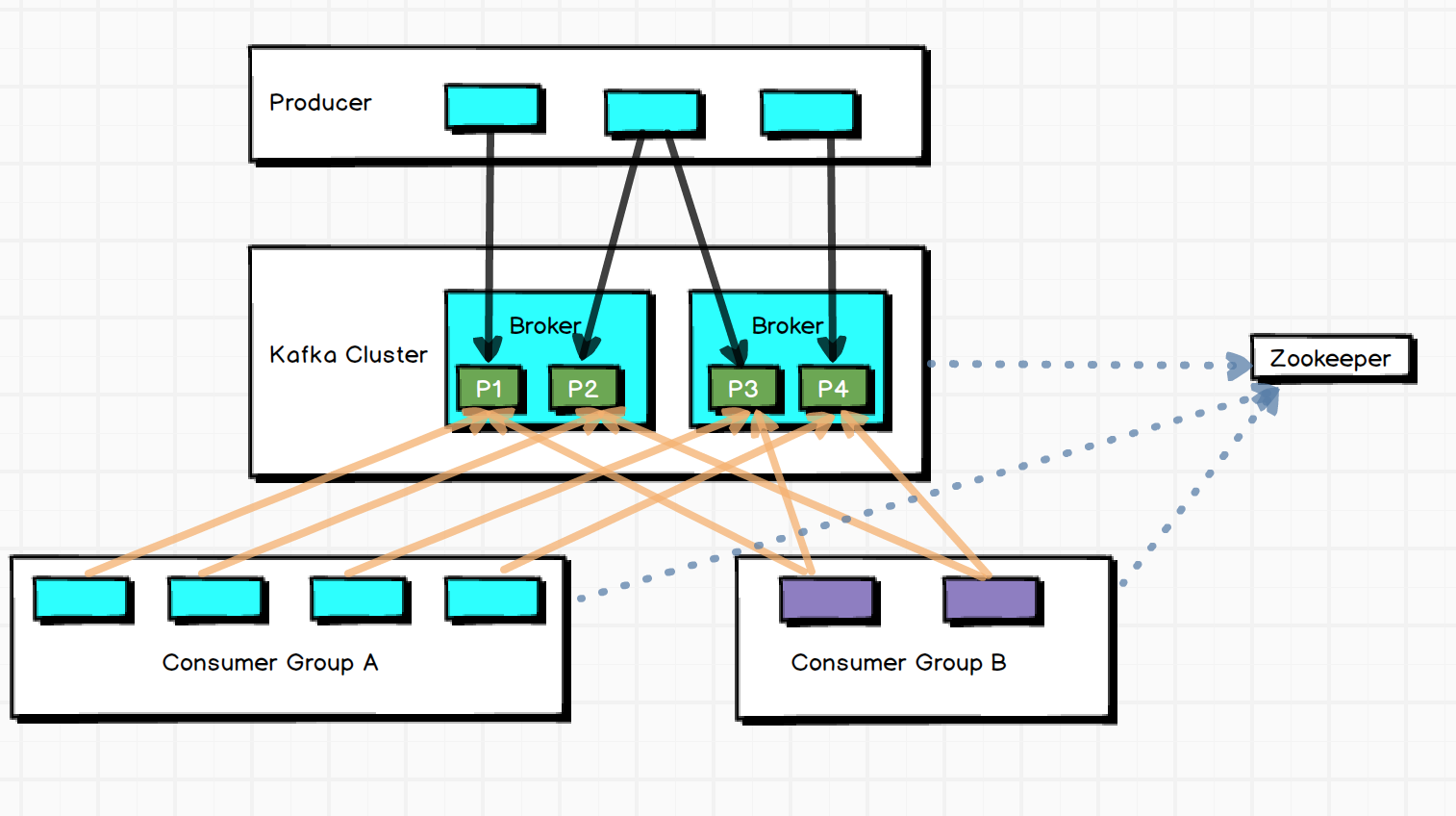
-
写入方式 producer采用push模式将消息发布到broker,每条消息被append到partition中,属于顺序写磁盘
-
topic本质是目录,由Partition Logs组成
- 分区原因:方便在集群中扩展;提高并发,以partition为读写单位
- 分区原则:指定了partition则直接使用;未指定partition但指定了key,则通过key的value进行hash选出partition;两者均没有时,使用轮询选出一个partition
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); if (keyBytes == null) { int nextValue = nextValue(topic); List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic) if (availabelPartitions.size() > 0) { int part = Utils.toPositive(nextValue) % availablePartitions.size(); return availablePartitions.get(part).partition(); } else { return Utils.toPositive(nextValue) % numPartitions; } } else { return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } } -
同一个partition可能有多个replication(server.properties中的default.replication.factor=N)。没有replication的情况下,一旦broker宕机,其上的所有partition数据不可消费,producer也不能将数据写入该partition。引入replication后,同一partition可能会有多个replication,这时需要选出一个leader,producer、consumer和leader交互,其他replication作为Follower从leader中复制数据。
-
写入流程
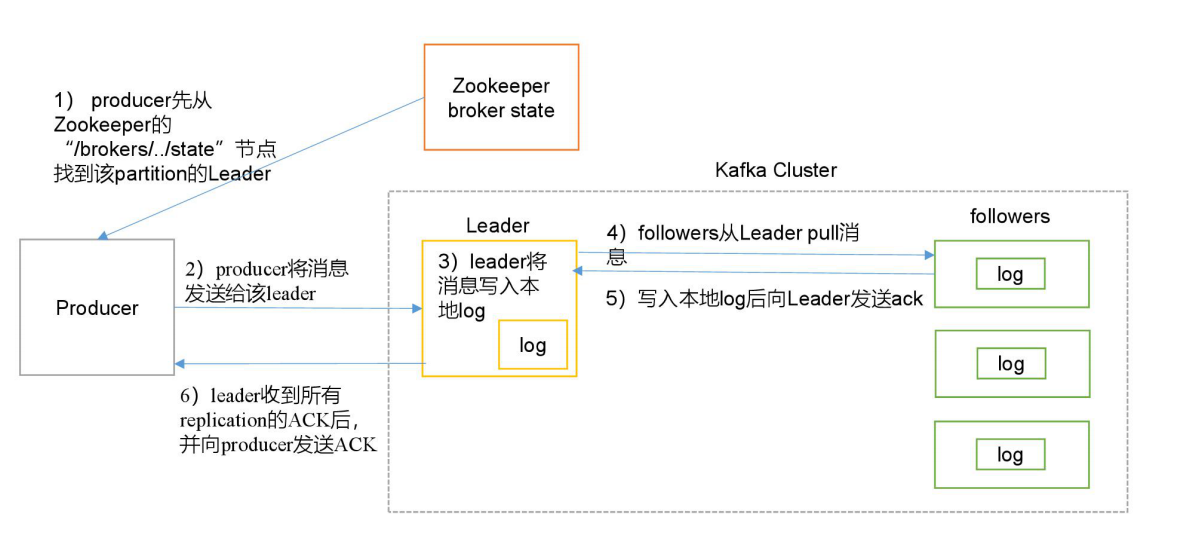
- producer从Zookeeper的"/brokers/.../state"节点找到该partition的leader
- producer将消息发送给leader
- leader将消息写入本地log
- followers从leaderpull消息,写入本地log后向leader发ACK
- leader收到所有ISR的replication的ack后,增加HW(high watermark,最后提交Offset)并向producer发送ack
// 自定义分区生产者
import java.util.Map
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster
public class CustomPartitioner implements Partitioner {
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return 0;
}
@Override
public void close() {
}
}
// 使用
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class PartitionerProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("boostrap.servers", "hadoop102:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
// 增加服务器请求延时
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 自定义分区
props.put("partitioner.class", "com.arkmu.kafka.CustomPartitioner");
KafkaProducer<String, String> producer = new KafkaProducerM<>(props);
producer.send(new ProducerRecord<String, String>("first", "1", "arkmu"));
producer.close();
}
}
拦截器
Producer拦截器(interceptor)实在kafka0.10版本引入的,主要实现clients段的定制化控制。
// 时间拦截器
import java.util.Map
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
public class TimerInterceptor implements ProducerInterceptor<String, String> {
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
return new ProducerRecord(record.topic(), record.partition(), record.timestamp(), record.key(), System.currentTimeMillis() + "," + record.value().toStrng());
}
@Override
public void onAcknowledgement(RecordMetadata, Exception exception) {
}
@Override
public void close() {
}
}
// 使用
......
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, "com.arkmu.kafka.interceptor.TimeInterceptor");
......
Kafka分区数
- 创建一个只有一个分区的Topic
- 测试该Topic的Producer(Tp)和Consumer(Tc)的吞吐量
- 假设总的目标吞吐量为Tt,则分区数=Tt/min(Tp, Tc)
分区数一般设置为3-10个
ISR副本同步队列
ISR(In-Sync Replicas),副本同步队列。ISR中包含Leader和Follower。如果Leader进程挂掉,会在ISR队列中选择一个服务器作为新的Leader。由replica.lag.max.messages(延迟条数)和replica.lag.time.max.ms(延迟时间)决定一台服务器是否可以加入ISR副本队列。在0.10版本中移除了replica.lag.max.message,防止服务频繁进入ISR队列。
任意一个维度超过阈值都会把Follower剔除ISR,存入OSR(Outof-Sync Replicas),新加入的Follower也会先存放在OSR中。
分区分配策略
在Kafka内部存在两种默认的分区分配策略:Range和RoundRobin。
-
Range:
- 对同一个Topic里面的分区按照序号进行排序,并对消费者按照字母顺序排序。
- 用Partitions分区的个数除以消费者线程的总数来决定每个消费者线程消费的分区个数
-
RoundRobin
- 所有主题分区组成TopicAndPartition列表
- 对TopicAndPartition列表按照hashCode进行排序
- 按照轮询的方式发送给每一个消费者线程
数据丢失
- Ack = 0,消息发送完毕即Offset增加
- Ack = 1,Leader收到Leader Replica对一个消息的接收Ack后增加Offset
- Ack = -1 Leader收到所有Replica对一个消息的接收Ack后增加Offset
消息积压
- 如果是Kafka消费能力不足,增加Topic分区数,并同时提升消费组的消费者数量
- 如果是下游数据处理不及时,提高每批次的拉取数量
参数优化
- Broker参数配置(server.properties)
// 日志保留策略配置
# 保留三天,也可以更短(log.cleaner.delete.retention.ms)
log.retention.hours = 72
// Replica相关配置
default.replication.factor:1 默认副本1
// 网络延时
replica.socket.timeout.ms:30000 # 集群之间网络不稳定是,调大该参数
replica.lag.time.max.ms = 600000 # 如果网络不好,或者kafka集群压力较大,会出现副本丢失,然后频繁复制副本,导致集群压力更大,此时可以调大该参数
- Producer优化(producer.properties)
compression.type:none # 默认发送不进行压缩,推荐配置一种适合的压缩算法,可以大幅度的减缓网络压力和Broker的存储压力
- Kafka内存调整(kafka-server-start.sh)
# 默认内存1G,生产环境尽量不要超过6G
export KAFKA_HEAP_OPTS="-Xms4g -Xmx4g"
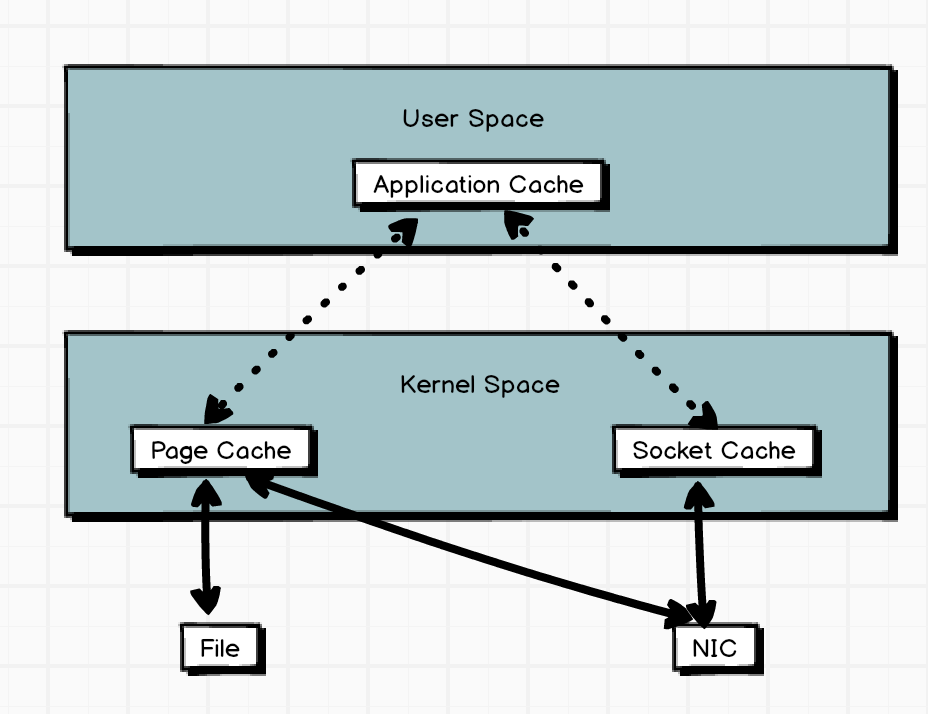
高效读取数据
- 分布式集群,同时采用分区技术,并发度高
- 顺序写磁盘:kafka的Producer生产数据,写入log文件中,写过程为追加文件末端的顺序写。官网数据表明,磁盘顺序写能到600M/s,而随机写只有100K/s
- 零复制技术
单条日志大小
kafka对于消息体大小默认为单条最大值1M,但在应用场景中经常出现消息大于1M,需要在server.properties中进行设置
replica.fetch.max.bytes: 1048576 # broker可复制消息的最大字节数,默认为1M
replica.max.bytes: 1000012 # kafka接收单个消息size的最大限制,默认为1M
过期数据清理
log.cleanup.policy=delete # 删除策略
log.cleanup.policy=compact # 压缩策略
按照时间消费数据
Map<TopicPartition, offsetAndTimestamp> startOffsetMap = KafkaUtil.fetchOffsetsWithTimestamp(topic, sTime, kafkaProp);
kafka命令行操作
- bin/kafka-server-start.sh config/server.properties
- bin/kafka-server.stop.sh stop
- bin/kafka-topics.sh --zookeeper hadoop102:2181 --list
- bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 3 --partitions 1 --topic first
- bin/kafka-topics.sh --zookeeper hadoop102:2181 --delete -- topic first
- bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
- bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --from-beginning --topic first
- bin/kafka-topics.sh --zookeeper hadoop102:2181 --describe --topic first
Flume和Kafka集成
a1.sources = r1;
a1.sinks = k1;
a1.channels = c1;
a1.sources.r1.type = exec;
a1.sources.r1.command = tail -F -c +0 /opt/module/datas/flume.log
a1.sources.r1.shell = /bin/bash -c
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop100:9092,hadoop101:9092,hadoop102:9092
a1.sinks.k1.kafka.topic = first
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.source.r1.channels = c1
a1.source.k1.channels = c1
