

前言
上一篇总结了Mysql的锁机制,通过读者的反映和阅读量显示,总体还是不错的,感兴趣的可以阅读一下[]。
写了那么多的Mysql文章,有读者问我是不是dba,工作真的需要掌握那么深吗。我想说的是:我是一名Java全职开发人员不是dba。
假如你只满足于日常的crud,你可以放弃这些底层的知识,可以不必学的那么深,若是你想往高处走,这些底层的知识,是你必备的。
话不多说,这一篇总结是讲解Mysql的索引,之前写过一篇关于索引的,主要是讲解索引的底层的数据结构B+tree。
这一篇是讲解Mysql中做使用到的「索引的种类」,「索引正确使用的原则」、「怎么优化索引」、「以及两种存储引擎InnoDB和MyISAM索引的数据布局原理」。
索引种类
在说索引之前,我们先来说一说什么是索引呢?对于索引个人的理解就是,索引是一种加快查询数据的数据结构。
所以,索引就是一种数据结构,作用就是发挥这种数据结构的作用,加快查询的效率,例如:InnoDB存储引擎中使用的是就是B+tree这种数据结构来组织索引。
Mysql中索引的种类也不是很多,不同类型的索引有不同的作用,索引的作用相互之间也存在交叉关系,Mysql中索引主要分为以下几类:
- 「主键索引」(
PRIMARY KEY):主键索引一般都是在创建表的时候指定,「一个表只有一个主键索引」,特点是「唯一、非空」。 - 「唯一索引」(
UNIQUE):唯一索引具有的特点就是唯一性,可以在创建表的时候指定,也可以在创建表后创建。 - 「普通索引」(
INDEX):普通索引唯一的作用就是加快查询。 - 「组合索引」(
INDEX):组合索引是创建一个「多个字段的索引」,这个概念是相对于上上面的单列索引而言,组合索引查询遵循「最左前缀原则」。 - 「全文索引」(
FULLTEXT):全文索引是针对一些大的「文本字段」创建的索引,也称为「全文检索」。 - 「聚簇索引」和「非聚簇索引」:聚簇索引和非聚簇索引的概念比上面的概念要大,属于包含和被包含的关系。例如:InnoDB中主键索引使用的就是聚簇索引。
若是你想查看一个表的所有索引,可以执行下面的sql来查看:
show index from 表名
例如,查看我自己的测试表里面的索引,如下图所示,Key_name表示索引的名字,Column_name表示索引的字段。
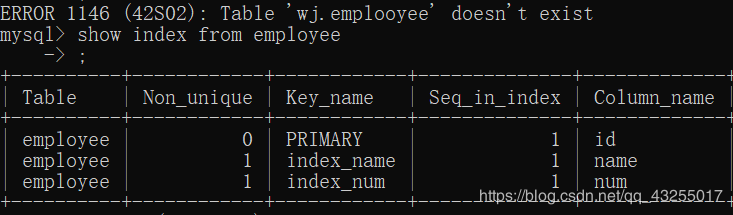
上面大概的说了主要索引的概念,下面详细的介绍一下这几大索引的特点和使用。
主键索引
主键索引在InnoDB存储引擎中是最常见的索引类型,一个表都会有一个主键索引,它索引的字段不允许为空值,并且唯一。
一般是在创建表的时候,可以通过RIMARY KEY指定主键索引,在InnoDB存储引擎中,若是创建表的时候没有主观创建主键索引,Mysql就会看表中是否有唯一索引,有,就会指定「非空的唯一索引」为主键索引;
没有,就会默认生成一个6byte空间的自动增长主键作为主键索引,可以通过select _rowid from 表名查询的是对应的主键值.。
MyISAM储存引擎是可以不存在主键索引,MyISAM和InnoDB储存数据的结构方式还是有明显的区别,这个后面篇章会详细讲解。
唯一索引
唯一索引与主键索引的区别就是,唯一索引允许为空,若是在组合索引中,只要创建的列值是唯一的
唯一索引在实际中更多的是用来保证数据的唯一性,假如你仅仅要数据能够快速查询,你也可以使用普通索引,所以唯一索引重在体现它的唯一性。
实际的业务场景,有些库表字段要求唯一,就可以使用唯一索引,创建唯一索引的方式有三种。
(1)一个是在创建表的时候指定,如下sql:
CREATE TABLE user(
id INT PRIMARY KEY NOT NULL,
name VARCHAR(16) NOT NULL,
UNIQUE unique_name (name(10))
);
(2)也可以在表创建后创建,如下sql:
CREATE UNIQUE INDEX unique_name ON user(name(10));
(3)通过修改表结构创建,如下sql:
ALTER user ADD UNIQUE unique_name ON (name(10))
这里有一个细节要注意的是创建的name字段,指定的长度是16字符,而创建的索引的长度制定的是10字符,因为也没有人的名字长度会超过10个字符,所以减少索引长度,能够减少索引所占的空间的大小。
普通索引
普通索引的唯一作用就是加快数据的查询,一般对查询语句WHERE和ORDER BY后面的字段创建普通索引。
创建普通索引的方式也有三种,基本和创建唯一索引的方式一样,只是把关键字UNIQUE换成INDEX,如下所示:
// 创建表的时候创建
CREATE TABLE user(
id INT PRIMARY KEY NOT NULL,
name VARCHAR(16) NOT NULL,
INDEX index_name (name(10))
);
// 创建表后创建
CREATE INDEX INDEX index_name ON user(name(10));
// 修改表结构创建
ALTER user ADD INDEX index_name ON (name(10))
若是想删除索引,可以通过执行下面的sql进行删除索引:
DROP INDEX index_name ON user;
组合索引
组合索引即用多个字段创建一个索引,组合索引能够避免「回表查询」,相对于多字段的单列索引,组合索引的查询效率更高。
创建组合索引(联合索引)的方式和上面创建普通索引的方式一样,只不过字段的数目多了,如下sql创建:
// 其它方式和上面的一样,这里就只列举修改表结构的方式创建
ALTER TABLE employee ADD INDEX name_age_sex (name(10),age,sex);
回表查询
什么是回表查询呢?回表查询简单来说「通过二级索引查询数据,得不到完整的数据行,需要再次查询主键索引来获得数据行」。
InnoDB存储引擎中,索引分为 「聚簇索引」和「二级索引」,主键索引就是聚簇索引,其它的索引为二级索引。
聚簇索引中的叶子节点保存着完整的数据行,而二级索引的叶子节点并不是保存完整的数据行。
上面提到InnoDB表是一定要有主键索引的,虽然索引占据空间,但是索引符合二分查找的算法,查找数据非常的快。
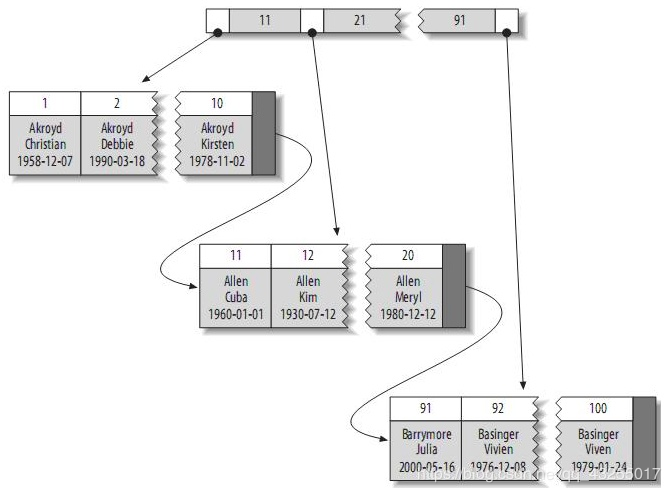
假设还是上面的employee表,里面有主键索引id,和普通的索引name,那么在InnoDB中就会存在两棵B+Tree,一棵是主键索引树:
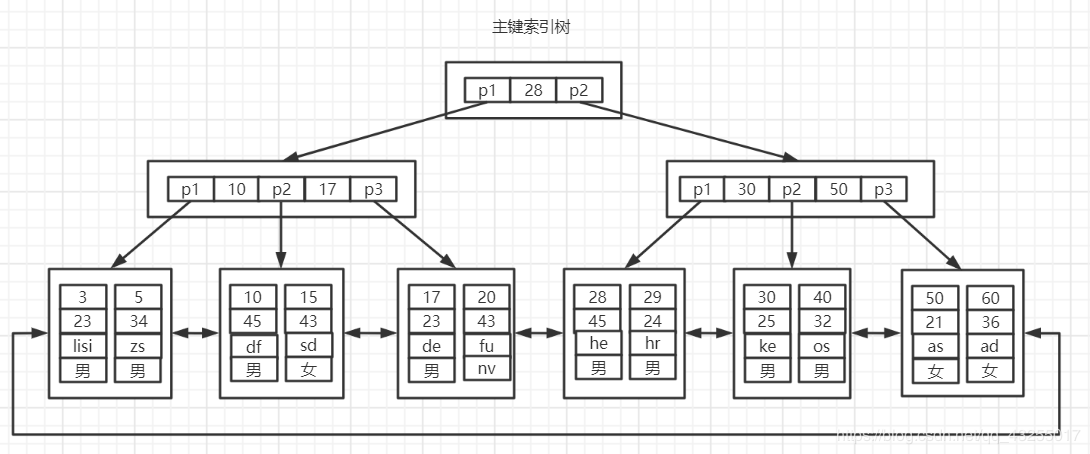
在主键索引树中的叶子节点存储的是完整的数据行,另外一棵是name字段的二级索引树,如下图所示:
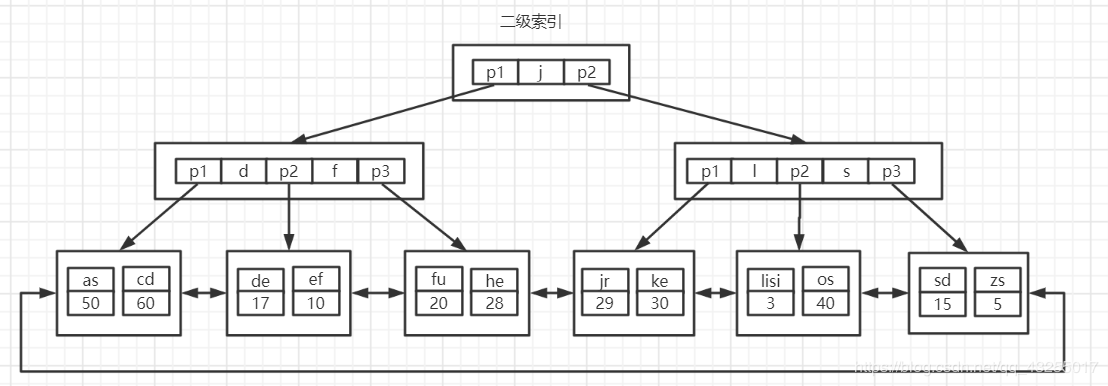
倘若你执行这条sql:select name, age, sex from employee where id ='as';就会先执行二级索引的查询,当查询name='as'时,得到主键为50,再根据主键查询主键索引树,得到完整的数据行,具体的执行流程如下:

这个就是回表查询,回表查询会查询两次,这样就会降低查询的效率,为了避免回表查询,只查询一次就能得到完整的数据呢?
索引覆盖
常见的方式就是「建立组合索引(联合索引)「进行」索引覆盖」,什么是索引覆盖呢?索引覆盖就是「索引的叶子节点已经包含了查询的数据,没必要再回表进行查询。」
假如我还是执行如下sql:select name, age, sex from employee where id ='as';因为普通索引只有name字段才建立了索引,这必然会导致回表查询。
为了提高查询效率,就(name)「单列索引升级为联合索引」(name, age, sex)就不同了。
因为建立的联合索引,在二级节点的叶子阶段就会同时存在name, age, sex三个的值,一次性就会获得所需要的数据,这样就避免了回表,但是所有的方案都不是完美的。
若是这个联合索引哪一天某一个数据行的name值改变了或者age改变了,我就需要同时维护主键索引和联合索引两棵树,这样的维护成本就高了,性能开销也大了。
相比之前数据的改变,我只需要维护主键索引即可,联合索引的创建就导致了需要同时维护两棵树,这样就会影响插入、更新数据的操作,所以并没有哪种方案是完美的。
最左前缀原则
我们知道单列索引是按照索引列有序性的进行组织B+Tree结构的,联合索引又是怎么组织B+Tree呢?
联合索引其实也是按照创建索引的时候,最左边的进行最开始的排序,也就是「最左前缀原则」,比如一个表中有如下数据:
| name | age | sex |
|---|---|---|
| ad | 23 | 男 |
| bc | 21 | 男 |
| bc | 24 | 女 |
| bc | 25 | 男 |
| de | 21 | 女 |
如上图所示,对于联合索引中name字段是放在最前面的,所以name是完全有序的,但是age字段就不是有序的,只有当name相同,例如:name='bc'此时age字段的索引排序才是完全有序的。
所以你会发现,在联合索引中你只有使用以下的规则的方式查询才会使用到索引:
- name,age,sex
- name,age
- name
因为Mysql的底层有查询优化器,会判断sql执行的时候若是使用全表扫描的效率比使用索引的效率更高,就会使用全表扫描。
假如,我查询的时候使用age>=23,sex='男';两个字段作为查询条件,但是没有使用name字段,因为在name不知情的条件下,对于age是无序的。
对于age>=23条件可能在很多的name不同中都有符合条件的出现,所以就没有办法使用索引,这也是索引实现的原因,一定要遵循「查找有序,充分的利用索引的有序性」。
假如你是分别在name,age,sex三个字段中分别建立三个单列索引,就相当于建立三颗索引树,那么它的查询效率,比我们使用一棵索引树查询效率就可想而知了。
有一种情况即使使用到了最左边的name字段也不会使用索引,例如:WHERE name like '%d%';这种like条件的模糊查询是会使索引失效。
我们可以这样理解,「查询字符串也是遵循最左前缀原则的」,字符串的查询是对字符串里面的字符一个一个的匹配,「若是字符串最左边为%表示一个不确定的字符串,那么是没办法利用到索引的有序性」。
但是若是修改为 :WHERE name like 'd%';就可以使用索引,因为最左边的字符串是确定的,这种称为「匹配列前缀」。
实际业务场景中联合索引的创建,「我们应该把识别度比较高的字段放在前面,提高索引的命中率,充分的利用索引」。
索引下推
Mysql5.6版本提出了索引下推的原则,「用于查询优化,主要是用于like关键字的查询的优化」,什么是索引下推呢?
下面通过演示来说明以下他的概念,还是利用原来的employee测试表,假如我要执行下面的sql进行查询:SELECT * from user where name like '张%' and age=40;
假如没有索引下推,执行的过程如下图所示:
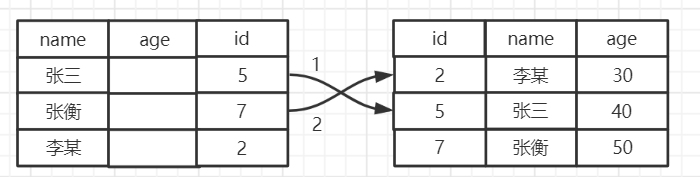
查询会直接忽略age字段,将name查询的张开头的id=5、id=7的结果返回给Mysql服务器,再执行两次的回表查询。
若是上面的查询操作使用了索引下推,执行的过程如下:
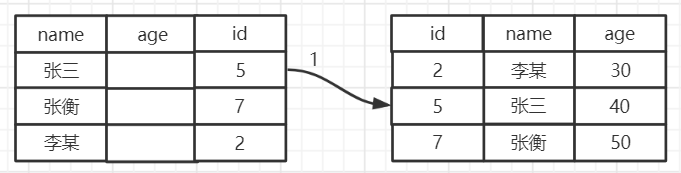
Mysql会将查询条件age=40的查询条件传递给存储引擎,再次过滤掉age=50的数据行,这样回表的次数就变为了一次,提高了查询效率。
总结起来索引下推就是在执行sql查询的时候,会将一部分的索引列的判断条件传递给存储引擎,由存储引擎通过判断是否符合条件,只有符合条件的数据才会返回给Mysql服务器。
全文索引
全文索引也称为全文检索,可以通过以下sql建立全文索引:ALTER TABLE employee ADD FULLTEXT fulltext_name(name);或者CREATE INDEX的方式创建。
全文索引主要是针对CHAR、VARCHAR或TEXT这种文本类的字段有效,有人说不也可以使用like关键字来查询文本吗。
普通索引(单列索引)的查询只能加快字段内容中最前面的字符串的检索,若是对于多个单词组成文本的查询普通索引就无能为力了。
索引一经创建就没有办法修改,若是想要修改索引,必须重建,可以使用以下sql来删除索引:DROP INDEX fulltext_name ON employee;
聚簇索引和非聚簇索引
聚簇索引和非聚簇索引是相对于存储引擎的概念,范围比较大,包含上面所提到的索引类型。
「聚簇索引就是叶子节点中存储的就是完整的行数据,索引和数据存储在一起;而非聚簇索引的索引文件和数据文件是分开的,所以查询数据会多一次查询」。
因此聚簇索引的查询速度会快于非聚簇索引的查询速度,再Mysql的村相互引擎中,「InnoDB支持聚簇索引,MyISAM不支持聚簇索引,MyISAM支持非聚簇索引」。
聚簇索引
下面我们来看看InnoDB中的聚簇索引,前面说到InnoDB都会有一个主键,该主键就是用于支持聚簇索引,聚簇索引结构图,大致如下图所示:
InnoDB中适用于最好的主键选择就是给出一个AUTO_INCREMENT的列作为自增的主键,有的人可能会使用UUID作为随机主键。
因为索引要维持有序性,若是使用随机的主键,主键的插入需要寻找合适的位置进行放置,这样维护主键索引树的成本就会便得更高。
相反的,自增主键,主键都是自增变大,在维护主键索引树的成本就会变得更小,随意应该尽量避免随机主键。
非聚簇索引
MyISAM使用的是非聚簇索引,新插入数据的时候,会按顺序的写入的磁盘中,并且给每一行数据标记一个行号,从小逐渐增大。
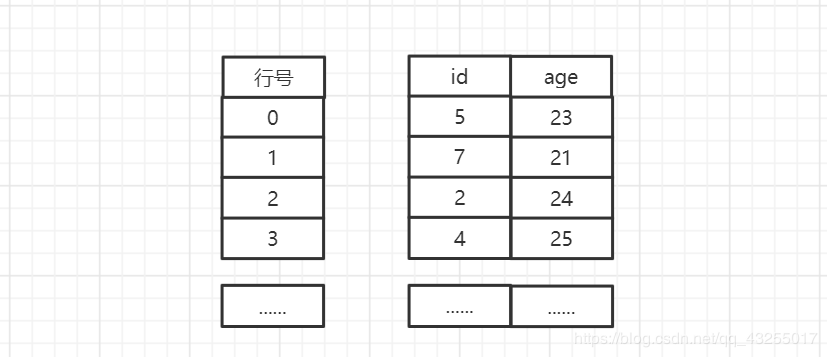
当MyISAM创建主键索引的时候,形成的主键索引树的结构图如下图所示:
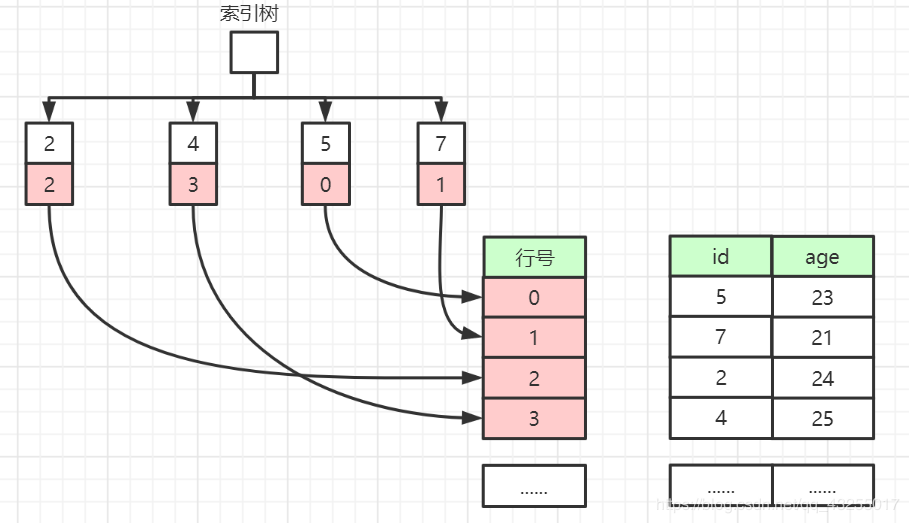
在主键索引中,数据也是非空且唯一,主键索引树中存储的是数据行的行号,当查询数据的时候使用主键索引查询需要查询到行号,然后通过行号获取数据。
非逐渐索引和主键索引一样叶子节点也是存储着行号,唯一的区别就是非逐渐索引不要求非空、唯一。
我们可以通对比图来对比一下「InnoDB(聚簇索引)」 和 「MyISAM(非聚簇索引)」 的索引数据布局,如下图所示:
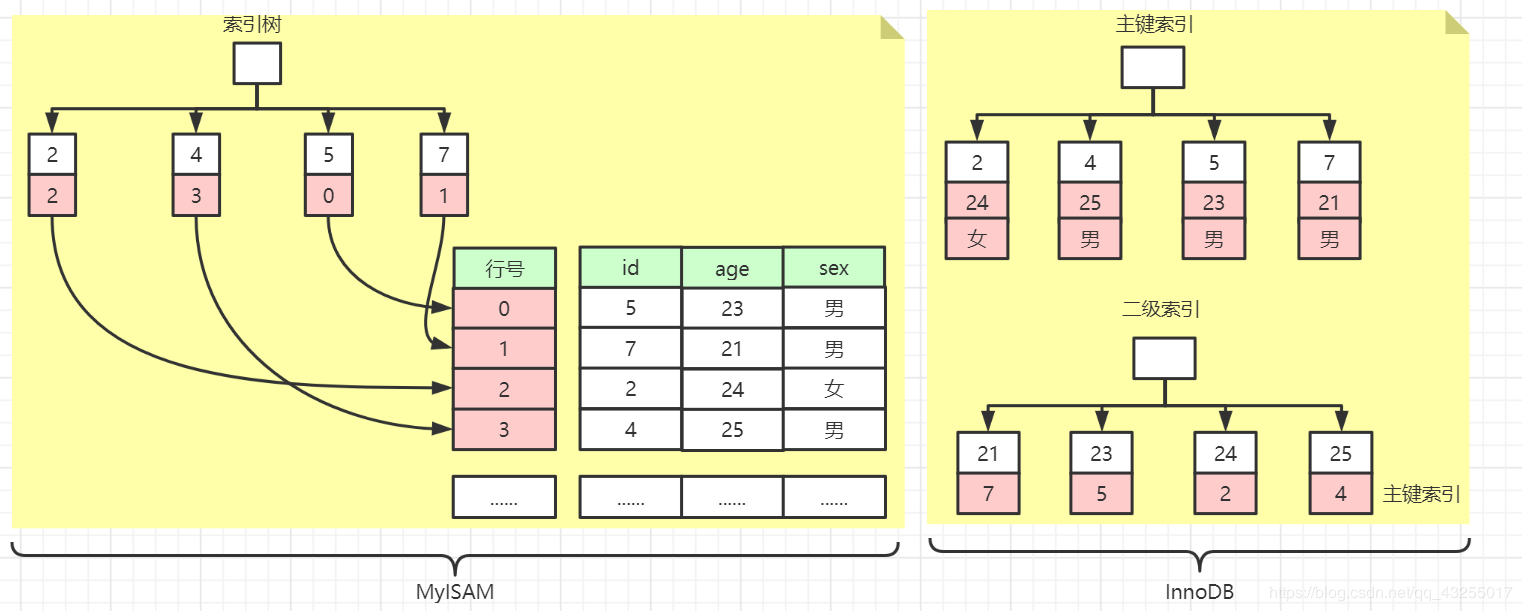
说到这里相信应该大家对于「InnoDB(聚簇索引)」 和 「MyISAM(非聚簇索引)」 有了非常清晰的认识和理解,下面是来说一说索引的优化,这个也是和我们日常开发最密切相关的。
索引原则和优化
要正确的使用索引,就要正确的创建索引,用索引正确的查询,不要使索引失效,因此索引的涉及和优化的原则应该遵循下面的几个原则:
- 索引列不要在表达式中出现,这样会导致索引失效。如:「SELECT ...... WHERE id+1=5」;
- 索引列不要作为函数的参数使用。
- 索引列尽量不要使用like关键字。如:「SELECT ...... WHERE name like '%d%'」;
- 数字型的索引列不要当作字符串类型进行条件查询。如:「SELECT ...... WHERE id = '35'」;
- 尽量不要在条件NOT IN、<>、!= 中使用索引。
- 在索引列的字段中不要出现NULL值,NULL值会使索引失效,可以用特殊的字符比如空字符串' '或者0来代替NULL值。
- 联合索引的查询应该遵循最左前缀原则。
- 一般对于区别性比较大的字段建立索引,在联合索引中区别性比较大(识别度比较高)放在最前面,提高索引的命中率。
- 索引的大小要适度,不易过大,避免索引的冗余。
总结
索引是我们工作经常会使用到的数据查询方式,正确的使用索引可以大大提高查询的效率。
- 一方面索引减少了索引服务器需要扫描的数据行的数量,将原来的全表扫描,使用特定的数据结构,能够快速的定位数据行。
- 另一方面使用有序的索引,避免了排序,将原来的随机的IO操作,变成了顺序的IO操作,执行有序。
但是索引也不是十全十美的,也有自己的缺点,不正确的使用索引,将会导致索引大量的占据空间,索引并非是越多越好,索引文件会越发的膨胀,这样严重的影响查询的性能。
对于插入、更新 、删除数据,除了维护数据以外,还要维护索引文件,这样也会影响这些操作的性能,但是对于查询的频率远高于更新和插入数据的业务场景,索引是再适合不过了。

