

- 魔盒是禧云自研的大数据开发协作平台,前一篇介绍了魔盒在离线任务打包过程中怎么提高RabbitMQ消费速度;
- 数据开发人员通过魔盒不仅可以很方便的进行离线任务的打包、测试、上线,还可以方便的设置离线任务的串行、并行工作流调度;
- 本文以创建一个需要依赖多个并行job的工作流为例,来介绍魔盒集成 Azkaban实现离线任务工作流调度的思路和流程。
一. 离线计算
魔盒管理离线任务
- 禧云离线计算支持 Hive,Spark 等计算框架;
- 数据开发人员用 Spark 编写完分析代码后,通过使用魔盒可以打包、测试、上线(详细可以看这篇文章)。
二. 任务调度
为什么需要工作流调度器
- 一个完整的数据分析系统通常都是由大量任务单元组成: shell 脚本程序、java 程序、mapreduce 程序、hive 脚本等;
- 各任务单元之间存在时间先后及前后依赖关系,禧云每天运行着上百个离线分析任务,不同优先级的任务调度时机也不同;
- 为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行。
crontab+shell
为了解决上述问题,我们早期使用的是 crontab+shell 的方式来执行,但是这种方式的弊端如下:
- 任务之间的依赖关系完全依靠脚本来控制;
- 在任务比较多的情况下,管理和维护起来比较麻烦;
- 出现问题也难以排查。
Azkaban
Azkaban是由 Linkedin 开源的一个批量工作流任务调度器,优势如下:
- 可以在一个工作流内以一个特定的顺序运行一组工作和流程;
- 可以通过一种 KV 文件格式来建立任务之间的依赖关系;
- 并提供一个易于使用的 web 用户界面维护,通过它可以跟踪你的工作流。
三.魔盒实现工作流调度
魔盒的离线计算部分集成了 Azkaban,通过 ajax 调用接口的方式与 Azkaban 进行交互,用户不用登陆 Azkaban 的 web UI,直接通过魔盒就可以完成:
- 工作流的创建;
- 工作流的删除;
- 执行工作流;
- 取消执行工作流;
- 查看工作流执行记录、执行状态、执行时长等。
下面我会介绍一下在魔盒中怎么去创建一个多个Job并行的工作流,要创建的工作流任务依赖关系图如下所示:
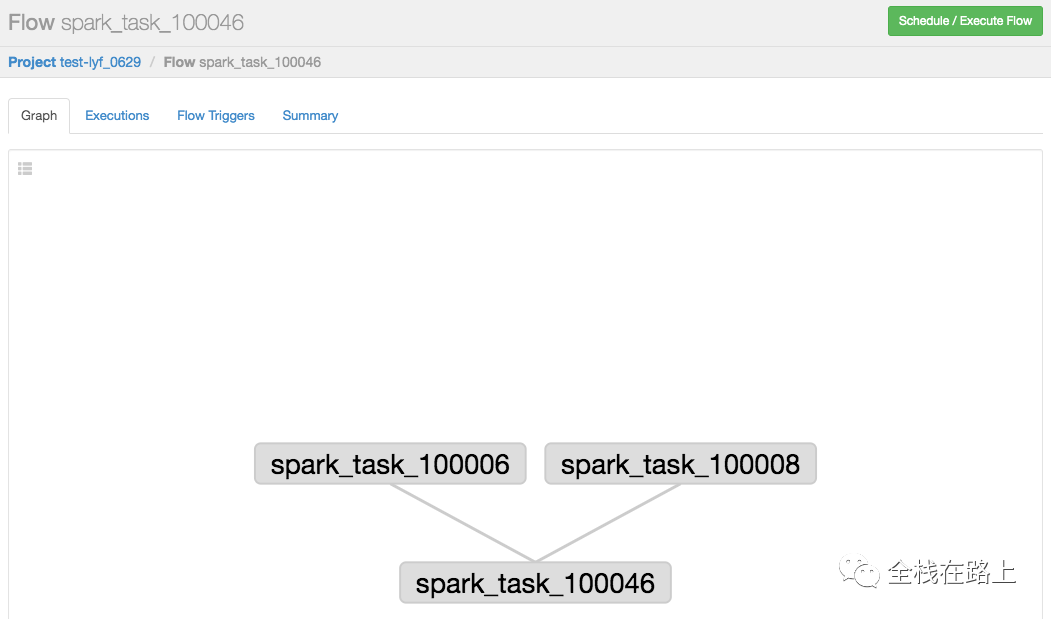
备注
- Azkaban 流程名称以最后一个没有依赖的 job 定义的。
1. 创建Spark任务
工作流会依赖一个或多个任务,因此在创建工作流之前,需要准备好任务:
- 在魔盒中,通过指定任务处理类、设置执行任务所需的参数来创建 Spark 任务;
- 任务创建成功后,通过魔盒的项目构建、测试无误后,会将运行任务所需要的 jar 包自动上传至 HDFS 中。
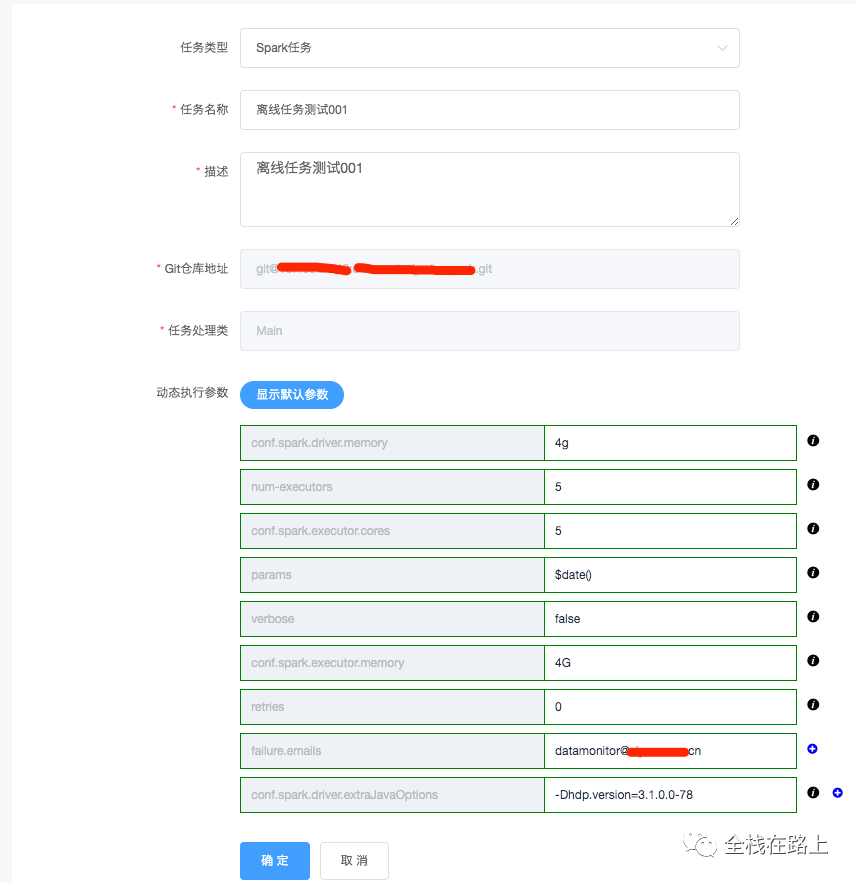
执行参数会以 JSON 字符串的格式存入表中去,大概格式如下:
{
"type":"spark",
"conf.spark.yarn.am.extraJavaOptions":"-Dhdp.version=3.1.0.0-78",
"conf.spark.history.fs.logDirectory":"hdfs://dconline/spark/eventlog",
"conf.spark.driver.extraJavaOptions":"-Dhdp.version=3.1.0.0-78",
"conf.spark.eventLog.enabled":"true",
"master":"yarn",
"conf.spark.dynamicAllocation.executorIdleTimeout":"60",
"deploy-mode":"cluster",
"queue":"develop",
// 创建spark任务时表单里填写的任务处理类
"class":"...Main",
// 默认为空,会在创建工作流时赋值
"name":"",
// 默认为空,会在创建工作流时赋值
"execution-jar":"",
// 默认为空,会在创建工作流时赋值
"dependencies":"",
}
主要执行参数解释
- name:spark 任务提交到 Yarn 平台上时的 application 名字;
- execution-jar: 为执行该任务时依赖的 jar 包;
- dependencies:在这里设置依赖关系(比如:
task_a,task_b,则表明该工作流依赖task_a和task_b);
这三个参数默认值为空,在创建工作流的时候,会根据配置的工作流依赖关系,动态更新赋值。
备注
- 上图中,我创建了一个 spark 任务:离线任务测试001(离线任务测试001为魔盒中记录的任务名字,对应到 Azkaban 中的 job 名称为为:
spark_task_10046); - 照此步骤,还需要创建二个 spark 任务,分别对应job:
spark_task_10006和spark_task_10008,这里不再截图展示。
2. 身份验证
所有 Azkaban API 调用都需要进行身份验证,其实就是模拟一个用户登录的过程。因此在与 Azkaban 进行交互之前,首先需要进行身份验证。
请求参数
| Parameter | Description |
|---|---|
| action=login | The fixed parameter indicating the login action. |
| username | The Azkaban username. |
| password | The corresponding password. |
主要代码
/**
* 登录Azkaban,并返回sessionId
* @公众号 全栈在路上
*
* @return string
* @throws Exception
*/
@Override
public String login() throws Exception {
SSLUtil.turnOffSslChecking();
HttpHeaders hs = new HttpHeaders();
hs.add("Content-Type", CONTENT_TYPE);
hs.add("X-Requested-With", X_REQUESTED_WITH);
LinkedMultiValueMap<String, String> linkedMultiValueMap = new LinkedMultiValueMap<String, String>();
linkedMultiValueMap.add("action", "login");
linkedMultiValueMap.add("username", username);
linkedMultiValueMap.add("password", password);
HttpEntity<MultiValueMap<String, String>> httpEntity = new HttpEntity<>(linkedMultiValueMap, hs);
RestTemplate client = new RestTemplate();
String result = client.postForObject(AzkabanUrl, httpEntity, String.class);
log.info("--------Azkaban返回登录信息:" + result);
return new Gson().fromJson(result, JsonObject.class).get("session.id").getAsString();
}
备注
- 通过执行身份验证,会为用户提供一个会话(会在 Response 里返回一个 session.id);
- 在会话到期(默认是24 hours)之前,可以执行任何 API 请求;
- 当然,如果你有注销、改变机器、改变浏览器这些动作或者 Azkaban 服务重新启动等,会话就会到期。
3. 创建工作流
创建工作流时可以选择所依赖的任务单元,既可以设置串行,也可以设置并行。
下面来展示怎么在魔盒中创建前面需求中的工作流(依赖多个并行job)。
3.1 创建工作流(多job并行)
选择任务:
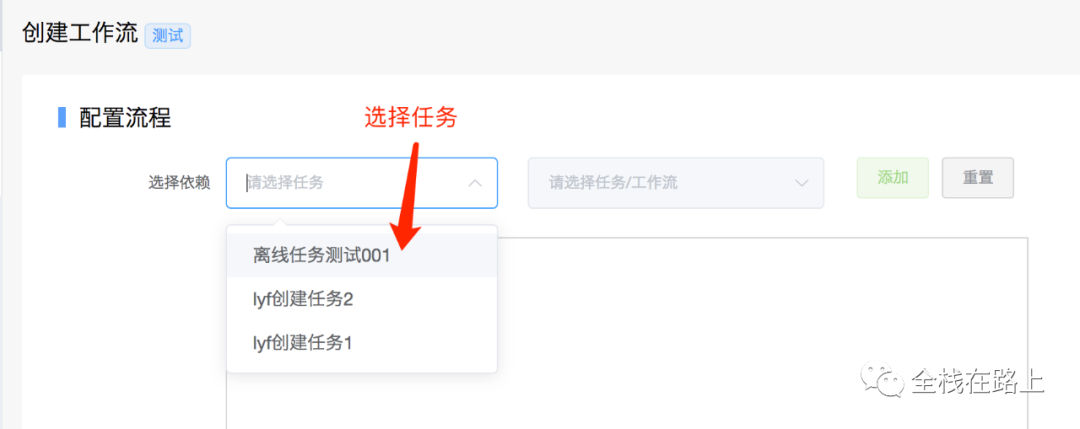
选择依赖任务:
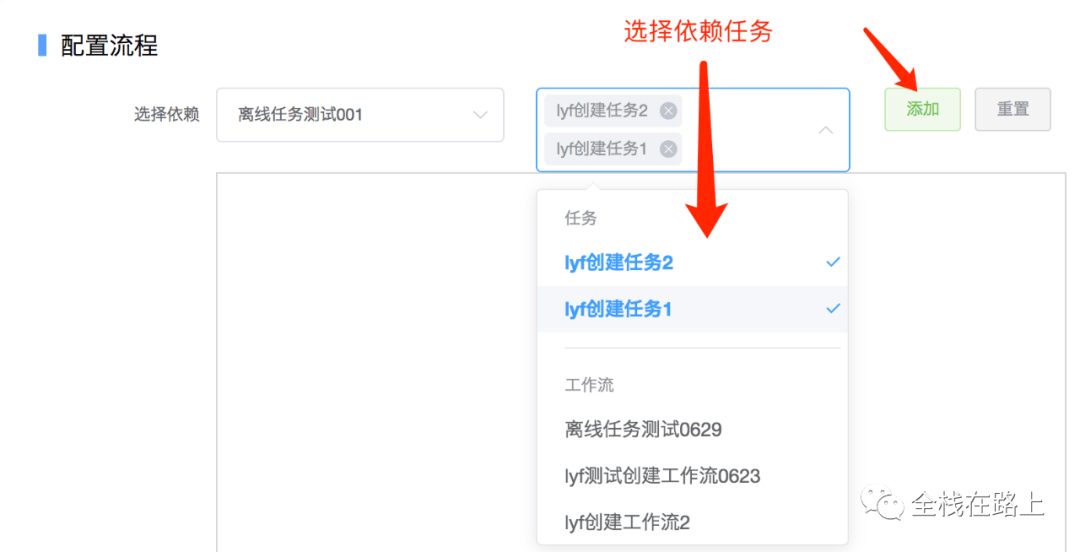
点击【添加】按钮:
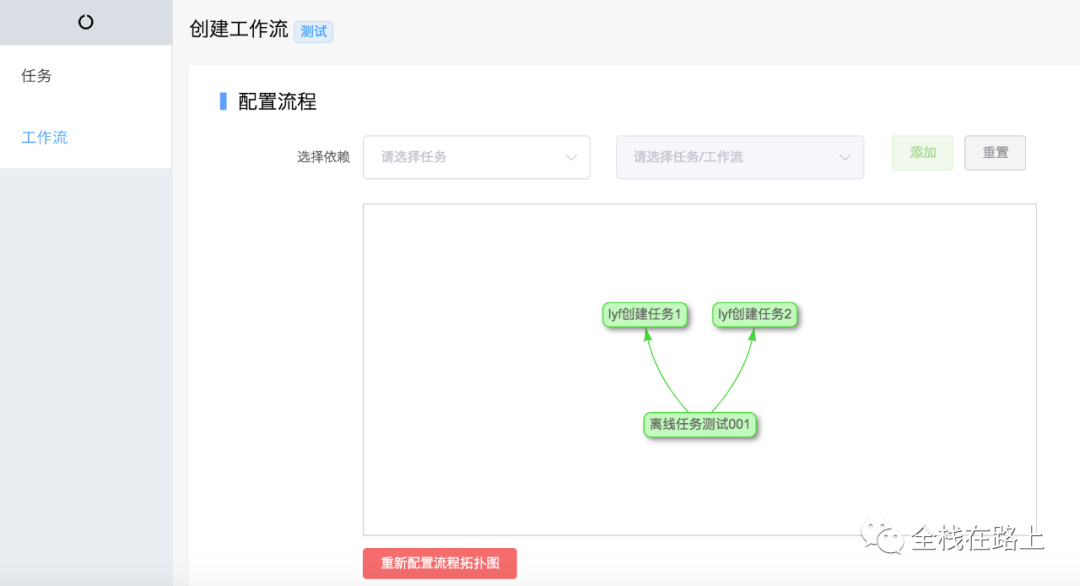
备注
- 魔盒使用 vis.js 来配置和展示流程拓扑图(本篇不做为介绍的重点)。
3.2 前端处理:工作流传参
前端会将创建的工作流(包含的任务单元依赖数据)组装为一个叫dependList的 JSON 字符串,传递给服务端:
[
{
"id":"task_100046",
"depId":"task_100008"
},
{
"id":"task_100046",
"depId":"task_100006"
}
]

备注
- 如果子级也有需要依赖的任务,则该数据结构会是一个典型的树状结构(本 demo 展示的依赖关系只有两级)。
3.3 服务端处理:得到依赖关系
服务端接收到本次前端提交的工作流数据(dependList)后,会对数据进行处理,得到一个存储工作流任务单元依赖关系的 dependencies:
[
{
"task_100046": [
"spark_task_10008",
"spark_task_10006"
]
}
]
备注
- 如果子级也有需要依赖的任务,则该数组会存在多个元素,数据格式类似(本 demo 展示的依赖关系只有两级);
- 处理树状结构的工作流依赖数据时需要借助多个递归方法得到所有依赖关系。
3.4 服务端处理:更新执行参数
循环存储依赖关系的 dependencies,主要逻辑如下:
- 通过截取任务名称 spark_task_10008 得到任务id: 10008;
- 由任务id从表中取出创建spark任务时保存的 JSON 格式的执行参数
config_params; - 更新
config_params,为config_params里部分参数(name、execution-jar、dependencies)赋值。
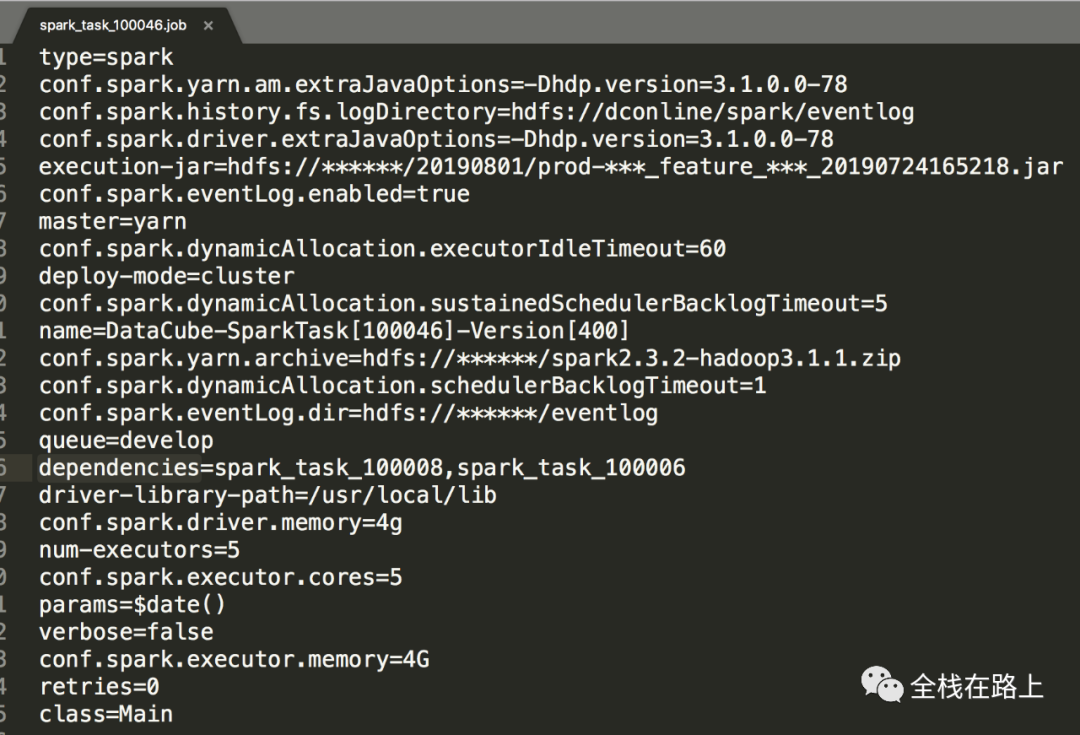
离线任务测试001最终的执行参数config_params为:
{
"type":"spark",
"conf.spark.yarn.am.extraJavaOptions":"-Dhdp.version=3.1.0.0-78",
"conf.spark.history.fs.logDirectory":"hdfs://******/eventlog",
"conf.spark.driver.extraJavaOptions":"-Dhdp.version=3.1.0.0-78",
"conf.spark.eventLog.enabled":"true",
"master":"yarn",
"conf.spark.dynamicAllocation.executorIdleTimeout":"60",
"deploy-mode":"cluster",
"queue":"develop",
// 创建spark任务时表单里填写的任务处理类
"class":"...Main",
// 该spark任务提交至yarn平台中的application名字
"DataCube-SparkTask[100046]",
// 该spark任务的jar包在HDFS中的存储路径
"execution-jar":"hdfs://******/20190801/prod-***_feature_***_20190724165218.jar",
// 该工作流的依赖任务
"dependencies":"spark_task_100008,spark_task_100006",
}
lyf创建任务1的执行参数config_params为:
{
"type":"spark",
"conf.spark.yarn.am.extraJavaOptions":"-Dhdp.version=3.1.0.0-78",
"conf.spark.history.fs.logDirectory":"hdfs://******/eventlog",
"conf.spark.driver.extraJavaOptions":"-Dhdp.version=3.1.0.0-78",
"conf.spark.eventLog.enabled":"true",
"master":"yarn",
"conf.spark.dynamicAllocation.executorIdleTimeout":"60",
"deploy-mode":"cluster",
"queue":"develop",
// 创建spark任务时表单里填写的任务处理类
"class":"...Main",
// 该spark任务提交至yarn平台中的application名字
"name":"DataCube-SparkTask[10006]",
// 该spark任务的jar包在HDFS中的存储路径
"execution-jar":"hdfs://******/20190801/prod-***_feature_***_20190724165218.jar",
// 该工作流的依赖任务(该任务没有依赖任务,所以这里为空)
"dependencies":"",
}
lyf创建任务2的执行参数config_params为:
{
"type":"spark",
"conf.spark.yarn.am.extraJavaOptions":"-Dhdp.version=3.1.0.0-78",
"conf.spark.history.fs.logDirectory":"hdfs://******/eventlog",
"conf.spark.driver.extraJavaOptions":"-Dhdp.version=3.1.0.0-78",
"conf.spark.eventLog.enabled":"true",
"master":"yarn",
"conf.spark.dynamicAllocation.executorIdleTimeout":"60",
"deploy-mode":"cluster",
"queue":"develop",
// 创建spark任务时表单里填写的任务处理类
"class":"...Main",
// 该spark任务提交至yarn平台中的application名字
"name":"DataCube-SparkTask[10008]",
// 该spark任务的jar包在HDFS中的存储路径
"execution-jar":"hdfs://******/20190801/prod-***_feature_***_20190724789620.jar",
// 该工作流的依赖任务(该任务没有依赖任务,所以这里为空)
"dependencies": ""
}
3.5 准备job资源文件所需要的数据
更新完每个 spark 任务需要使用的执行参数后,开始组装 jobLists,用来存放 job 资源文件所需要的数据,格式如下:
[
{
"newId": "spark_task_100046",
"config": 该任务更新后的config_params变量值,
},
{
"newId": "spark_task_100008",
"config": 该任务更新后的config_params变量值,
},
{
"newId": "spark_task_100006",
"config": 该任务更新后的config_params变量值,
},
]
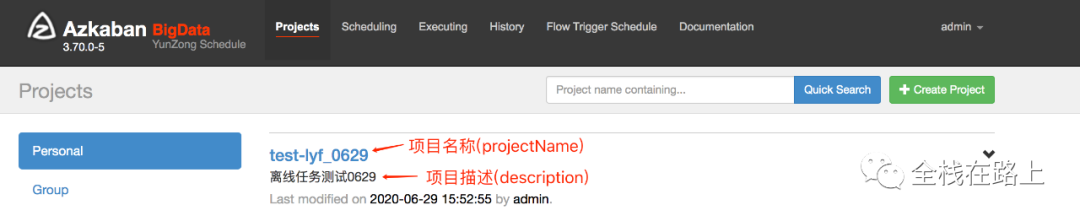
3.6 创建Azkaban项目
请求参数
| Parameter | Description |
|---|---|
| session.id | The user session id. |
| action=create | The fixed parameter indicating the create project action. |
| name | The project name to be uploaded. |
| description | The description for the project. This field cannot be empty. |
主要代码
/**
* 创建项目
* @公众号 全栈在路上
*
* @param projectName 项目名字
* @param description 项目描述
* @throws Exception
*/
@Override
public void createProject(String projectName, String description) throws Exception {
SSLUtil.turnOffSslChecking();
HttpHeaders hs = new HttpHeaders();
hs.add("Content-Type", CONTENT_TYPE);
hs.add("X-Requested-With", X_REQUESTED_WITH);
LinkedMultiValueMap<String, String> linkedMultiValueMap = new LinkedMultiValueMap<String, String>();
linkedMultiValueMap.add("session.id", login());
linkedMultiValueMap.add("action", "create");
linkedMultiValueMap.add("name", projectName);
linkedMultiValueMap.add("description", description);
HttpEntity<MultiValueMap<String, String>> httpEntity = new HttpEntity<>(linkedMultiValueMap, hs);
String result = restTemplate.postForObject(azkabanUrl + "/manager", httpEntity, String.class);
log.info("--------Azkaban返回创建Project信息:" + result);
// 创建成功和已存在,都表示创建成功
JsonObject jsonObject = new Gson().fromJson(result, JsonObject.class);
String status = jsonObject.get("status").getAsString();
if (!AZK_SUCCESS.equals(status)) {
String message = jsonObject.get("message").getAsString();
if (!"Project already exists.".equals(message)) {
throw new Exception("创建Azkaban Project失败");
}
}
}
备注
- 该方法中如果 projectName 已经存在也表示创建成功。
效果展示
3.7 生成压缩包
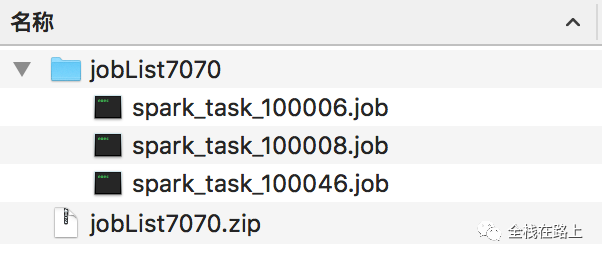
循环 jobLists,生成该工作流需要的一个或多个 .job 文件,并将文件打包,主要逻辑如下:
- 生成以 newId 为名字,以 .job 为后缀的文件;
- 将 config 的值写入文件;
- 将当前目录下的所有文件压缩为一个由不会重复的随机数命名的 .zip 文件。
主要代码
/**
* 循环jobList里的执行参数,写入到文件(newId.job)中,然后将文件写入到压缩包中去
* @公众号 全栈在路上
*
* @param jobLists
* @return
* @author liuyongfei
* @date 2019/04/03
*/
Map<String, Object> zipJobFile(List<Map<String, String>> jobLists) {
int randomNumber = (int) Math.round(Math.random() * (9999 - 1000) + 1000);
String zipName = "jobList" + randomNumber + ".zip";
// 定义压缩文件
String zipFilePath = CommonUtils.handleMultiDirectory("data/zip") + "/" + zipName;
// 创建输出流
FileOutputStream fos = null;
try {
fos = new FileOutputStream(zipFilePath);
ZipOutputStream zipOut = new ZipOutputStream(fos);
for (Map<String, String> map : jobLists) {
try {
// 取出configParams内容,写入到newId.job文件中去
File file = new File(map.get("newId") + ".job");
if (!file.exists()) {
file.createNewFile();
}
// 获取执行参数
String configParams = map.get("config");
// 将执行参数写入到file中去
FileWriter fw = new FileWriter(file.getAbsoluteFile());
BufferedWriter bw = new BufferedWriter(fw);
bw.write(configParams);
bw.close();
// 将文件写入到压缩包中去
FileInputStream fis = new FileInputStream(file);
ZipEntry zipEntry = new ZipEntry(file.getName());
zipOut.putNextEntry(zipEntry);
byte[] bytes = new byte[1024];
int length;
while ((length = fis.read(bytes)) >= 0) {
zipOut.write(bytes, 0, length);
}
fis.close();
file.delete();
} catch (IOException e) {
e.printStackTrace();
}
}
zipOut.close();
fos.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
Map<String, Object> zipFileMap = new HashMap<>();
zipFileMap.put("zipFilePath", zipFilePath);
zipFileMap.put("zipFile", new File(zipFilePath));
return zipFileMap;
}
/**
* 创建目录
* 支持多级目录创建
* @公众号 全栈在路上
*
* @date 2019/04/03
* @return String
*/
public static String handleMultiDirectory(String multiDirectory) {
File savePath = null;
try {
savePath = new File(getJarRootPath(), multiDirectory);
//判断上传文件的保存目录是否存在
if (!savePath.exists() && !savePath.isDirectory()) {
log.info(savePath + "目录不存在,需要创建");
//创建目录
boolean created = savePath.mkdirs();
if (!created) {
log.error("路径: '" + savePath.getAbsolutePath() + "'创建失败");
throw new RuntimeException("路径: '" + savePath.getAbsolutePath() + "'创建失败");
}
}
log.info("文件存储路径为: {}", savePath.getAbsolutePath());
} catch (FileNotFoundException e) {
e.printStackTrace();
}
return savePath.getAbsolutePath();
}
生成的job文件和压缩包
至此,包含工作流任务依赖关系的 zip 压缩包准备完成。
4. 上传压缩包至Azkaban
请求参数
| Parameter | Description |
|---|---|
| session.id | The user session id. |
| ajax=upload | The fixed parameter to the upload action. |
| project | The project name to be uploaded. |
| file | The project zip file. The type should be set as application/zip or application/x-zip-compressed. |
主要代码
/**
* 上传文件至Azkaban
* @公众号 全栈在路上
*
* @param projectName
* @param file
* @return
* @throws Exception
*/
@Override
public String uploadZip(String projectName, File file) throws Exception {
SSLUtil.turnOffSslChecking();
FileSystemResource resource = new FileSystemResource(file);
LinkedMultiValueMap<String, Object> linkedMultiValueMap = new LinkedMultiValueMap<String, Object>();
linkedMultiValueMap.add("session.id", login());
linkedMultiValueMap.add("ajax", "upload");
linkedMultiValueMap.add("project", projectName);
linkedMultiValueMap.add("file", resource);
String result = restTemplate.postForObject(AzkabanUrl + "/manager", linkedMultiValueMap, String.class);
if (result.length() < 10) {
throw new BusinessException("上传文件包到Azkaban失败,请检查工作流是否正确!");
}
log.info("--------Azkaban返回上传文件信息:" + result);
String projectId = new Gson().fromJson(result, JsonObject.class).get("projectId").getAsString();
if (StringUtils.isEmpty(projectId)) {
throw new Exception("上传文件至Azkaban失败");
}
return projectId;
}
备注
- 上传zip压缩包成功后,会返回在 Azkaban 中创建成功的项目id。
5. 查看创建的工作流
5.1 在魔盒查看
在工作流列表里可以看到刚刚创建的工作流,点击工作流可以进入详情页:
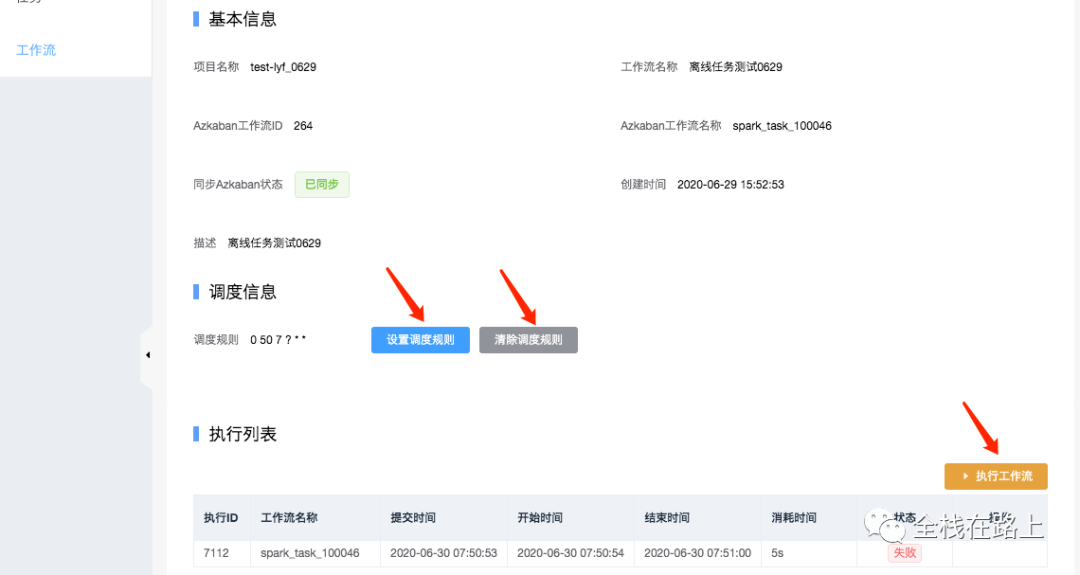
备注
- 在详情页为该工作流设置和清除 cron 调度规则;
- 在详情页可以执行工作流,查看工作流执行记录、执行状态;
- 返回工作流列表,可以对已经创建的工作流进行删除(同时会删除Azkaban中的数据)。
我们在魔盒中集成了Azkaban web UI 中提供的常见主要功能,如果有非常用操作则可以去 Azkaban web UI 里去执行。
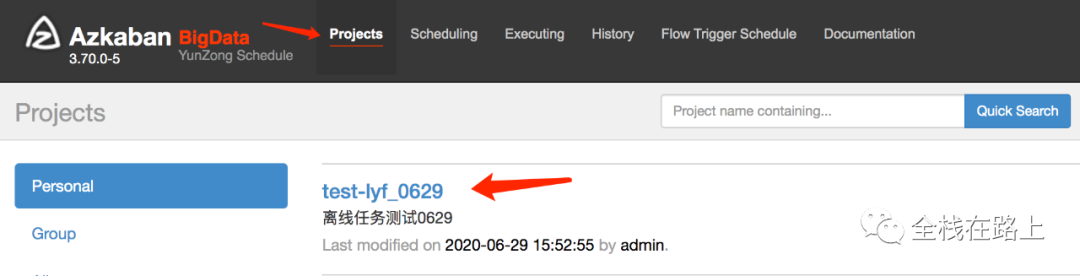
5.2 在Azkaban的 web UI 查看
zip 压缩包上传成功之后,我们可以到 Azkaban 的 web UI 里去查看已经创建的工作流。 在 Projects 栏里可以看到刚刚通过魔盒创建成功的工作流:
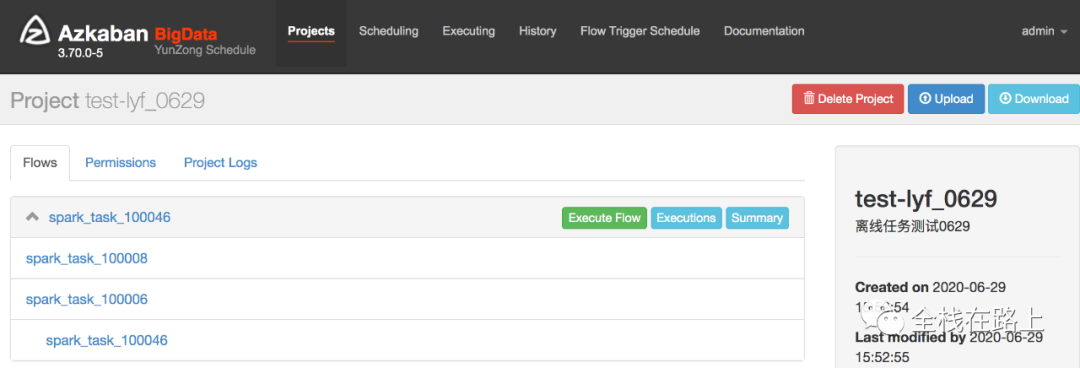
点击 project 名称可以进入到详情页:
四. 总结
魔盒集成 Azkaban 的好处
- 数据开发人员在魔盒这个大数据协作开发平台中,可以很方便的完成
spark任务的打包和上线; - 数据开发人员可以很方便的完成串行、并行等复杂工作流设置,使禧云的离线计算任务管理更加有序可依;
- 数据开发人员不用在魔盒和Azkaban web UI 两个平台之间频繁切换,在任务比较多的情况下,管理起来也比较方便,提高了数据开发人员的效率;
- 配合魔盒灵活的、完善的异常监控报警机制,数据质量保障的稳定性得到很大的提高,从而可以更好的发挥大数据平台支撑体系的价值。
更多
通过调用 Azkaban 的 api ,结合 Azkaban 元数据库数据查询,我们在魔盒中还可以完成对工作流的以下操作:
- 删除工作流;
- 设置 cron 定时任务;
- 执行工作流、取消执行工作流;
- 查看看该工作流执行日志;
- 获取该工作流的依赖任务及任务信息;
- 工作流执行情况的监控报警。
关注微信公众号
欢迎大家关注我的微信公众号阅读更多文章:

