

分库分表的目的是为了解决两个问题:
第一,是数据量太大查询慢的问题。这里面我们讲的“查询”其实主要是事务中的查询和更新操作,因为只读的查询可以通过缓存和主从分离来解决,这个我们在之前的“MySQL 如何应对高并发”的两节课中都讲过。那我们上节课也讲到过,解决查询慢,只要减少每次查询的数据总量就可以了,也就是说,分表就可以解决问题。
第二,是为了应对高并发的问题。应对高并发的思想我们之前也说过,一个数据库实例撑不住,就把并发请求分散到多个实例中去,所以,解决高并发的问题是需要分库的。
简单地说,数据量大,就分表;并发高,就分库。
常用三种分片算法
- 范围分片容易产生热点问题,但对查询更友好,适合适合并发量不大的场景;
- 哈希分片比较容易把数据和查询均匀地分布到所有分片中;
- 查表法更灵活,但性能稍差。
MySQL to Redis同步
- MQ消息同步
- 使用 Binlog 实时更新 Redis 缓存 (使用Canal)
如何实现不停机更换数据库?
- 上线同步程序,从旧库中复制数据到新库中,并实时保持同步;
- 上线双写订单服务,只读写旧库;
- 开启双写,同时停止同步程序;
- 开启对比和补偿程序,确保新旧数据库数据完全一样;
- 逐步切量读请求到新库上;
- 下线对比补偿程序,关闭双写,读写都切换到新库上;
- 下线旧库和订单服务的双写功能。
类似“点击流”这样的海量数据应该如何存储?
对于海量原始数据的存储系统,我们要求的是超高的写入和读取性能,和近乎无限的容量,对于数据的查询能力要求不高。生产上,可以选择 Kafka 或者是 HDFS,Kafka 的优点是读写性能更好,单节点能支持更高的吞吐量。而 HDFS 则能提供真正无限的存储容量,并且对查询更友好。
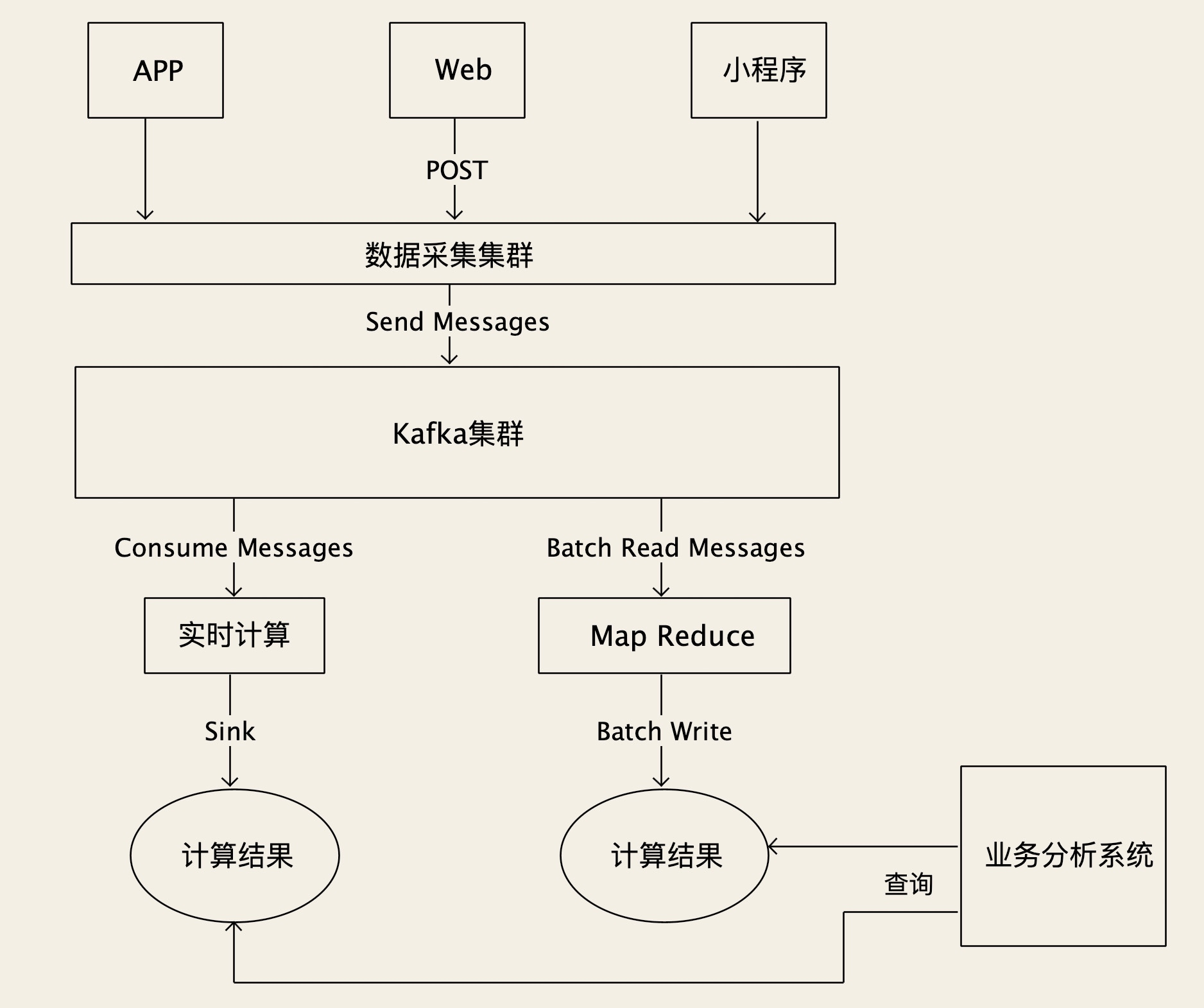
一类是分布式流数据存储,比较活跃的项目有Pravega和 Pulsar 的存储引擎Apache BookKeeper。这些分布式流数据存储系统,走的是类似 Kafka 这种流存储的路线,在高吞吐量的基础上,提供真正无限的扩容能力,更好的查询能力。
还有一类是时序数据库(Time Series Databases),比较活跃的项目有InfluxDB和OpenTSDB等。这些时序数据库,不仅有非常好的读写性能,还提供很方便的查询和聚合数据的能力。但是,它们不是什么数据都可以存的,它们专注于类似监控数据这样,有时间特征并且数据内容都是数值的数据。如果你有存储海量监控数据的需求,可以关注一下这些项目。
