

索引是什么?
索引是依靠某些数据结构和算法来组织数据,最终引导用户快速检索出所需要的数据。 工作方式: 利用b+树,链表,二分法查找,做到了快速定位目标数据,快速范围查找。
索引有2个特点:
- 通过数据结构和算法来对原始的数据进行一些有效的组织
- 通过这些有效的组织,可以引导使用者对原始数据进行快速检索
索引的本质:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
索引的数据结构:B+树
InnoDB 的数据是按数据页为单位来读写的。也就是说,当需要读取一条记录的时候,并不是将这个记录本身从磁盘读取出来,而是以页为单位,将整个也加载到内存中,一个页中可能有很多记录,然后在内存中对页进行检索。在innodb中,每个页的大小默认是16kb。
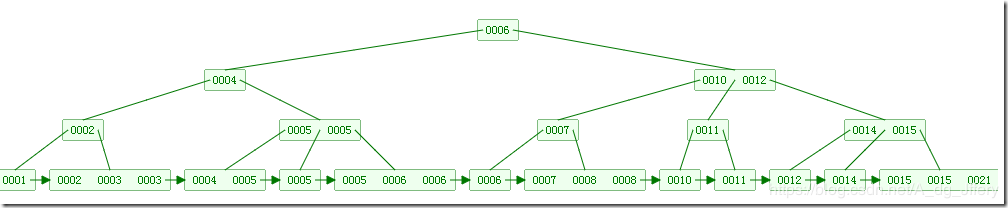
- 每个结点至多有m个子女
- 除根结点外,每个结点至少有[m/2]个子女,根结点至少有两个子女
- 有k个子女的结点必有k个关键字
- 父节点中持有访问子节点的指针
- 父节点的关键字在子节点中都存在,要么是最小值,要么是最大值,如果节点中关键字是升序的方式,父节点的关键字是子节点的最小值
- 最底层的节点是叶子节点
- 除叶子节点之外,其他节点不保存数据,只保存关键字和指针
- 叶子节点包含了所有数据的关键字以及data,叶子节点之间用链表连接起来,可以非常方便的支持范围查找
- 有k个子树的中间节点包含有一个k元素(B树中是k-1个元素),每个元素不保存数据,所有的数据均保存在叶子节点上。
- 所有的叶子节点中包含了全部元素的信息及指向含这些元素记录的指针,且叶子节点本身以关键字的大小自小到大顺序连接。
- 所有的中间节点元素都同时存在与子节点中,在子节点元素中为最大值或者最小值。
B+树的优势:
- 单一节点存储更多的元素,使得查询的IO次数更少。
- 所有查询都要查找叶子节点,查询性能稳定。
- 所有叶子节点形成有序链表,便于范围查询。
索引分类
分为聚集索引和非聚集索引。
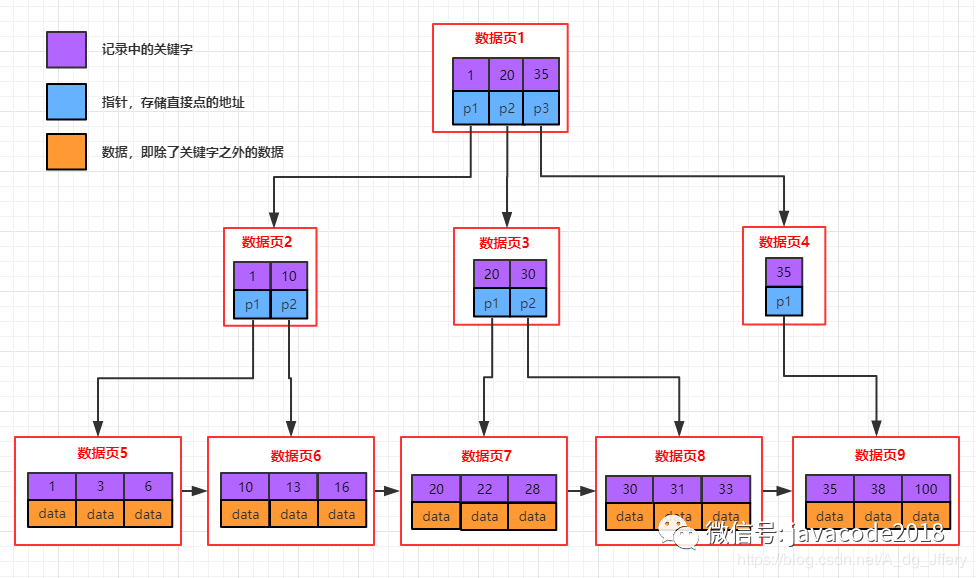
- 聚集索引
每个表有且一定会有一个聚集索引,整个表的数据存储在聚集索引中,mysql索引是采用B+树结构保存在文件中,叶子节点存储主键的值以及对应记录的数据,非叶子节点不存储记录的数据,只存储主键的值。当表中未指定主键时,mysql内部会自动给每条记录添加一个隐藏的rowid字段(默认4个字节)作为主键,用rowid构建聚集索引。 聚集索引在mysql中又叫主键索引。
- 非聚集索引(辅助索引)
也是b+树结构,不过有一点和聚集索引不同,非聚集索引叶子节点存储字段(索引字段)的值以及对应记录主键的值,其他节点只存储字段的值(索引字段)。 每个表可以有多个非聚集索引。
mysql中非聚集索引分为:
- 单列索引:即一个索引只包含一个列。
- 多列索引(又称复合索引):即一个索引包含多个列。
- 唯一索引:索引列的值必须唯一,允许有一个空值。
索引常见问题:
- 回表:根据where条件找到主键ID,利用主键ID再去查询当前的这条数据的过程叫回表。
- 索引覆盖:查询中采用的索引树中包含了查询所需要的所有字段的值,不需要再去聚集索引检索数据,这种叫索引覆盖。
- 索引下推:简称ICP,Index Condition Pushdown(ICP)是MySQL 5.6中新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式,ICP可以减少存储引擎访问基表的次数以及MySQL服务器访问存储引擎的次数。
建议:
-
在区分度高的字段上面建立索引可以有效的使用索引,区分度太低,无法有效的利用索引,可能需要扫描所有数据页,此时和不使用索引差不多
-
联合索引注意最左匹配原则:必须按照从左到右的顺序匹配,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整
-
查询记录的时候,少使用*,尽量去利用索引覆盖,可以减少回表操作,提升效率
-
有些查询可以采用联合索引,进而使用到索引下推(IPC),也可以减少回表操作,提升效率
-
禁止对索引字段使用函数、运算符操作,会使索引失效
-
字符串字段和数字比较的时候会使索引无效
-
模糊查询'%值%'会使索引无效,变为全表扫描,但是'值%'这种可以有效利用索引
-
排序中尽量使用到索引字段,这样可以减少排序,提升查询效率
额外知识:
以机械硬盘来说,先了解几个概念。
-
扇区:磁盘存储的最小单位,扇区一般大小为512Byte。
-
磁盘块:文件系统与磁盘交互的的最小单位(计算机系统读写磁盘的最小单位),一个磁盘块由连续几个(2^n)扇区组成,块一般大小一般为4KB。 磁盘读取数据:磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右,听起来还挺不错的,但要知道一台500 -MIPS的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以执行40万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难。
-
mysql中的页 mysql中和磁盘交互的最小单位称为页,页是mysql内部定义的一种数据结构,默认为16kb,相当于4个磁盘块,也就是说mysql每次从磁盘中读取一次数据是16KB,要么不读取,要读取就是16KB,此值可以修改的。
-
数据检索过程 我们对数据存储方式不做任何优化,直接将数据库中表的记录存储在磁盘中,假如某个表只有一个字段,为int类型,int占用4个byte,每个磁盘块可以存储1000条记录,100万的记录需要1000个磁盘块,如果我们需要从这100万记录中检索所需要的记录,需要读取1000个磁盘块的数据(需要1000次io),每次io需要9ms,那么1000次需要9000ms=9s,100条数据随便一个查询就是9秒,这种情况我们是无法接受的,显然是不行的。
