

掘金中文地址《揭秘在安卓平台上奇慢无比的 ClassLoader.getResourceAsStream》,欢迎参加「掘金翻译计划」,翻译优质的技术文章。
Through our extensive analysis at NimbleDroid, we’ve picked up on a few tricks that help prevent monolithic lags in Android apps, boosting fluidity and response time. One of the things we’ve learned to watch out for is the dreaded ClassLoader.getResourceAsStream, a method that allows an app to access a resource with a given name. This method is pretty popular in the Java world, but unfortunately it causes gigantic slowdown in an Android app the first time it is invoked.
Of all the apps and SDKs we’ve analyzed (and we’ve analyzed a ton), we’ve seen that over 10% of apps and 20% of SDKs are slowed down significantly by this method. What exactly is going on? Let’s take an in-depth look in this post.
Example Slowdowns in Top Apps
Amazon’s Kindle app for Android, which has over 100 million downloads, has 1315ms of delay (app version 4.15.0.48) as a result of the method’s usage.
Another example is TuneIn 13.6.1, which is delayed by 1447ms.
Here TuneIn calls getResourceAsStream twice, and the second
call is much faster (6ms).
Here are some more apps that suffer from this problem:
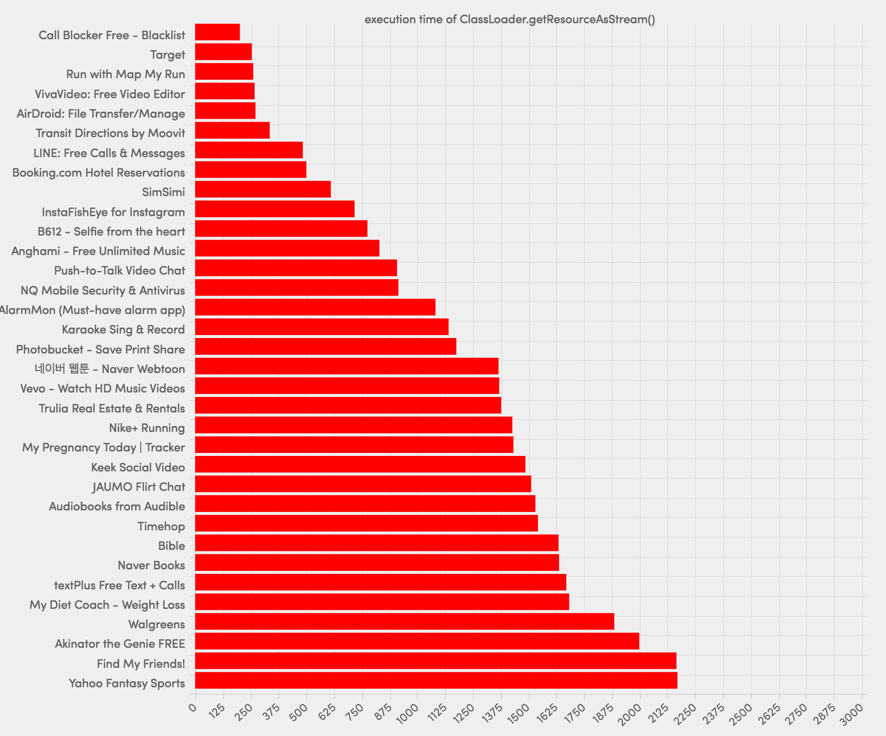
Again, more than 10% of the apps we analyzed suffer from this issue.
SDKs That Call getResourceAsStream
For brevity, we use SDKs to refer to both libraries that are attached to certain services, such as Amazon AWS, and those that aren’t, such as Joda-Time.
Oftentimes, an app doesn’t call getResourceAsStream directly;
instead, the dreaded method is called by one of the SDKs used by the app.
Since developers don’t typically pay attention to an SDK’s internal
implementation, they often aren’t even aware that their app contains the
issue.
Here is a partial list of the most popular SDKs that call
getResourceAsStream:
- mobileCore
- SLF4J
- StartApp
- Joda-Time
- TapJoy
- Google Dependency Injection
- BugSense
- RoboGuice
- OrmLite
- Appnext
- Apache log4j
- Twitter4J
- Appcelerator Titanium
- LibPhoneNumbers (Google)
- Amazon AWS
Overall, 20% of the SDKs we analyzed suffer from this issue - the list above
covers only a small number of these SDKs because we don’t have space
to list them all here. One reason that this issue plagues so many SDKs is
that getResourceAsStream() is pretty fast outside of Android,
despite the method’s slow implementation in Android.
Consequently, many Android apps are affected by this issue because many
Android developers come from the Java world and want to use familiar
libraries in their Android apps (e.g., Joda-Time instead of
Dan Lew’s Joda-Time-Android).
Why getResourceAsStream Is So Slow in Android
A logical thing to be wondering right now is why this method takes so long in Android. After a long investigation, we discovered that the first time this method is called, Android executes three very slow operations: (1) it opens the APK file as a zip file and indexes all zip entries; (2) it opens the APK file as a zip file again and indexes all zip entries; and (3) it verifies that the APK is correctly signed. All three operations are cripplingly slow, and the total delay is proportional to the size of the APK. For example, a 20MB APK induces a 1-2s delay. We describe our investigation in greater detail in Appendix.
Recommendation: Avoid calling ClassLoader.getResource*(); use Android's Resources.get*(resId) instead.
Recommendation: Profile your app to see if any SDKs call ClassLoader.getResource*(). Replace these SDKs with more efficient ones, or at the very least don't do these slow calls in the main thread.
Appendix: How We Pinpointed the Slow Operations in getResourceAsStream
To really understand the issue here, let’s investigate some actual code. We will use branch android-6.0.1_r11 from AOSP. We’ll begin by taking a look at the ClassLoader code:
libcore/libart/src/main/java/java/lang/ClassLoader.java
public InputStream getResourceAsStream(String resName) {
try {
URL url = getResource(resName);
if (url != null) {
return url.openStream();
}
} catch (IOException ex) {
// Don't want to see the exception.
}
return null;
}Everything looks pretty straightforward here. First we find a path for resources, and if it’s not null, we open a stream for it. In this case, the path is java.net.URL class, which has method openStream().
Ok, let’s check out the getResource() implementation:
public URL getResource(String resName) {
URL resource = parent.getResource(resName);
if (resource == null) {
resource = findResource(resName);
}
return resource;
}Still nothing interesting. Let’s dive into findResource():
protected URL findResource(String resName) {
return null;
}So findResource() isn’t implemented. ClassLoader is an abstract class, so we need to find the subclass that is actually implemented in real apps. If we open android docs, we see that Android provides several concrete implementations of the class, with PathClassLoader being the one typically used.
Let’s build AOSP and trace the call to getResourceAsStream and getResource in order to determine which ClassLoader is used:
public InputStream getResourceAsStream(String resName) {
try {
Logger.getLogger("NimbleDroid RESEARCH").info("this: " + this);
URL url = getResource(resName);
if (url != null) {
return url.openStream();
}
...
}We get what we expected, dalvik.system.PathClassLoader. However, checking the methods of PathClassLoader, we don’t find an implementation for findResource. This is because findResource() is implemented in the parent of PathClassLoader - BaseDexClassLoader.
/libcore/dalvik/src/main/java/dalvik/system/BaseDexClassLoader.java:
@Override
protected URL findResource(String name) {
return pathList.findResource(name);
}Let’s find pathList:
public class BaseDexClassLoader extends ClassLoader {
private final DexPathList pathList;
/**
* Constructs an instance.
*
* @param dexPath the list of jar/apk files containing classes and
* resources, delimited by {@code File.pathSeparator}, which
* defaults to {@code ":"} on Android
* @param optimizedDirectory directory where optimized dex files
* should be written; may be {@code null}
* @param libraryPath the list of directories containing native
* libraries, delimited by {@code File.pathSeparator}; may be
* {@code null}
* @param parent the parent class loader
*/
public BaseDexClassLoader(String dexPath, File optimizedDirectory,
String libraryPath, ClassLoader parent) {
super(parent);
this.pathList = new DexPathList(this, dexPath, libraryPath, optimizedDirectory);
}And now DexPathList:
/libcore/dalvik/src/main/java/dalvik/system/DexPathList.java
/**
* A pair of lists of entries, associated with a {@code ClassLoader}.
* One of the lists is a dex/resource path — typically referred
* to as a "class path" — list, and the other names directories
* containing native code libraries. Class path entries may be any of:
* a {@code .jar} or {@code .zip} file containing an optional
* top-level {@code classes.dex} file as well as arbitrary resources,
* or a plain {@code .dex} file (with no possibility of associated
* resources).
*
* This class also contains methods to use these lists to look up
* classes and resources.
*/
/*package*/ final class DexPathList {Let’s check out DexPathList.findResource:
/**
* Finds the named resource in one of the zip/jar files pointed at
* by this instance. This will find the one in the earliest listed
* path element.
*
* @return a URL to the named resource or {@code null} if the
* resource is not found in any of the zip/jar files
*/
public URL findResource(String name) {
for (Element element : dexElements) {
URL url = element.findResource(name);
if (url != null) {
return url;
}
}
return null;
}Element is just a static inner class in DexPathList. Inside there is much more interesting code:
public URL findResource(String name) {
maybeInit();
// We support directories so we can run tests and/or legacy code
// that uses Class.getResource.
if (isDirectory) {
File resourceFile = new File(dir, name);
if (resourceFile.exists()) {
try {
return resourceFile.toURI().toURL();
} catch (MalformedURLException ex) {
throw new RuntimeException(ex);
}
}
}
if (zipFile == null || zipFile.getEntry(name) == null) {
/*
* Either this element has no zip/jar file (first
* clause), or the zip/jar file doesn't have an entry
* for the given name (second clause).
*/
return null;
}
try {
/*
* File.toURL() is compliant with RFC 1738 in
* always creating absolute path names. If we
* construct the URL by concatenating strings, we
* might end up with illegal URLs for relative
* names.
*/
return new URL("jar:" + zip.toURL() + "!/" + name);
} catch (MalformedURLException ex) {
throw new RuntimeException(ex);
}
}Let’s stop and think for a bit. We know that the APK file is just a zip file. As we see here:
if (zipFile == null || zipFile.getEntry(name) == null) {We try to find ZipEntry by a given name. If we do this successfully, we return the corresponding URL. This can be a slow operation, but if we check the implementation of getEntry, we see that it’s just iterating over LinkedHashMap:
/libcore/luni/src/main/java/java/util/zip/ZipFile.java
...
private final LinkedHashMap entries = new LinkedHashMap();
...
public ZipEntry getEntry(String entryName) {
checkNotClosed();
if (entryName == null) {
throw new NullPointerException("entryName == null");
}
ZipEntry ze = entries.get(entryName);
if (ze == null) {
ze = entries.get(entryName + "/");
}
return ze;
}This isn’t a super fast operation, but it can’t take too long.
We missed one thing though - before working with zip files, they should be opened. If we look once again at the DexPathList.Element.findResource() method implementation, we will find the maybeInit() call. Let’s check it out:
public synchronized void maybeInit() {
if (initialized) {
return;
}
initialized = true;
if (isDirectory || zip == null) {
return;
}
try {
zipFile = new ZipFile(zip);
} catch (IOException ioe) {
/*
* Note: ZipException (a subclass of IOException)
* might get thrown by the ZipFile constructor
* (e.g. if the file isn't actually a zip/jar
* file).
*/
System.logE("Unable to open zip file: " + zip, ioe);
zipFile = null;
}
}Here it is! This line
zipFile = new ZipFile(zip);opens a zip file for reading:
public ZipFile(File file) throws ZipException, IOException {
this(file, OPEN_READ);
}This constructor initializes a LinkedHashMap object called entries. (To investigate more about the internal structure of ZipFile, check this out.) Obviously, as our APK file gets larger, we will need more time to open the zip file.
We’ve found the first slow operation of getResourceAsStream. The journey so far has been interesting (and complicated), but still only the beginning. If we patch the source code like the following:
public InputStream getResourceAsStream(String resName) {
try {
long start; long end;
start = System.currentTimeMillis();
URL url = getResource(resName);
end = System.currentTimeMillis();
Logger.getLogger("NimbleDroid RESEARCH").info("getResource: " + (end - start));
if (url != null) {
start = System.currentTimeMillis();
InputStream inputStream = url.openStream();
end = System.currentTimeMillis();
Logger.getLogger("NimbleDroid RESEARCH").info("url.openStream: " + (end - start));
return inputStream;
}
...We see that the zip file operation cannot account for all the delay in getResourceAsStream: url.openStream() takes much longer than getResource(), so let’s investigate further.
Following the call stack of url.openStream(), we get to /libcore/luni/src/main/java/libcore/net/url/JarURLConnectionImpl.java
@Override
public InputStream getInputStream() throws IOException {
if (closed) {
throw new IllegalStateException("JarURLConnection InputStream has been closed");
}
connect();
if (jarInput != null) {
return jarInput;
}
if (jarEntry == null) {
throw new IOException("Jar entry not specified");
}
return jarInput = new JarURLConnectionInputStream(jarFile
.getInputStream(jarEntry), jarFile);
}Let’s check connect() first:
@Override
public void connect() throws IOException {
if (!connected) {
findJarFile(); // ensure the file can be found
findJarEntry(); // ensure the entry, if any, can be found
connected = true;
}
}Nothing interesting, so let’s dive deeper.
private void findJarFile() throws IOException {
if (getUseCaches()) {
synchronized (jarCache) {
jarFile = jarCache.get(jarFileURL);
}
if (jarFile == null) {
JarFile jar = openJarFile();
synchronized (jarCache) {
jarFile = jarCache.get(jarFileURL);
if (jarFile == null) {
jarCache.put(jarFileURL, jar);
jarFile = jar;
} else {
jar.close();
}
}
}
} else {
jarFile = openJarFile();
}
if (jarFile == null) {
throw new IOException();
}
}Calling getUseCaches() should return true because:
public abstract class URLConnection {
...
private static boolean defaultUseCaches = true;
...Let’s look at the openJarFile() method:
private JarFile openJarFile() throws IOException {
if (jarFileURL.getProtocol().equals("file")) {
String decodedFile = UriCodec.decode(jarFileURL.getFile());
return new JarFile(new File(decodedFile), true, ZipFile.OPEN_READ);
} else {
...As you can see, here we open a JarFile, not a ZipFile. However, JarFile extends ZipFile. Here we’ve found the second slow operation in getResourceAsStream - Android needs to open the APK file again as a ZipFile and index all its entries.
Opening the APK file as a zip file twice doubles the overhead, which is already significantly noticeable. However, this overhead still doesn’t account for all observed overhead. Let’s look at the JarFile constructor:
/**
* Create a new {@code JarFile} using the contents of file.
*
* @param file
* the JAR file as {@link File}.
* @param verify
* if this JAR filed is signed whether it must be verified.
* @param mode
* the mode to use, either {@link ZipFile#OPEN_READ OPEN_READ} or
* {@link ZipFile#OPEN_DELETE OPEN_DELETE}.
* @throws IOException
* If the file cannot be read.
*/
public JarFile(File file, boolean verify, int mode) throws IOException {
super(file, mode);
// Step 1: Scan the central directory for meta entries (MANIFEST.mf
// & possibly the signature files) and read them fully.
HashMap metaEntries = readMetaEntries(this, verify);
// Step 2: Construct a verifier with the information we have.
// Verification is possible *only* if the JAR file contains a manifest
// *AND* it contains signing related information (signature block
// files and the signature files).
//
// TODO: Is this really the behaviour we want if verify == true ?
// We silently skip verification for files that have no manifest or
// no signatures.
if (verify && metaEntries.containsKey(MANIFEST_NAME) &&
metaEntries.size() > 1) {
// We create the manifest straight away, so that we can create
// the jar verifier as well.
manifest = new Manifest(metaEntries.get(MANIFEST_NAME), true);
verifier = new JarVerifier(getName(), manifest, metaEntries);
} else {
verifier = null;
manifestBytes = metaEntries.get(MANIFEST_NAME);
}
}So here we find the third slow operation. All APK files are signed, so JarFile will execute the “verify” path. This verification process is cripplingly slow. While further discussion regarding verification is outside the scope of this post, you can learn more about it here.
Summary
To summarize, ClassLoader.getResourceAsStream is slow because of three slow operations: (1) opening the APK as a ZipFile; (2) opening the APK as JarFile which requires opening the APK as ZipFile again; (3) verifying that the JarFile is properly signed.
Additional Notes
Q: Is ClassLoader.getResource*() slow for both Dalvik and ART?
A: Yes. We checked 2 branches, android-6.0.1_r11 with ART and android-4.4.4_r2 with Dalvik. The slow operations in getResource*() are present in both versions.
Q: Why doesn’t ClassLoader.findClass() have a similar slowdown?
A: Android extracts DEX files from an APK during installation. Therefore, to find a class, there is no need to open the APK as a ZipFile or JarFile.
Specifically, if we go to class DexPathList we will see
public Class findClass(String name, List suppressed) {
for (Element element : dexElements) {
DexFile dex = element.dexFile;
if (dex != null) {
Class clazz = dex.loadClassBinaryName(name, definingContext, suppressed);
if (clazz != null) {
return clazz;
}
}
}
if (dexElementsSuppressedExceptions != null) {
suppressed.addAll(Arrays.asList(dexElementsSuppressedExceptions));
}
return null;
}There is no ZipFile or JarFile involved.
Q: Why doesn’t Android’s Resources.get*(resId) have this issue?
A: Android has its own way to index and load resources, avoiding the costly ZipFile and JarFile operations.
