I/O是任何一个程序设计者都无法忽略的存在,很多高级编程语言都在尝试使用巧妙的设计屏蔽I/O的实际存在,减小它对程序的影响,但是要真正的理解并更好运用这些语言,还是要搞清楚I/O的一些基本理念。本文将从最基本的I/O概念开始,试图理清当前I/O处理存在的问题和与之对应一些手段及背后的思想。
本来这是上个月在公司内部做的一次关于NIO的分享,发现很多概念可能当时理解的很清楚,过了一段时间就会感到模糊了。在这里整理一下,以备以后查看,同时也将作为另一个系列的开端。
由于篇幅限制,本文将只包含I/O模型到Reactor的部分,下一篇会继续讲到Netty和Dubbo中的I/O。本文包含以下内容:
- 五种典型的I/O模型
- 同步&异步、阻塞&非阻塞的概念
- Reactor & Proactor
- Reactor的启发
五种经典的I/O模型
这个部分的内容是理解各种I/O编程的基础,也是网上被讲解的最多的部分,这里将简单介绍一下Unix中5种I/O模型,由于操作系统的理论大多是相通的,所以大致流行的操作系统基本上都是这5中I/O模型。这一节的图例描述的是从网卡读取UDP数据包的过程,但是其模型放到更高层的系统设计中是同样有效的。
这一节的图都可以在「Unix网络编程」这本书里找到
0. 写在前面
从操作系统层面来看,I/O操作是分很多步骤的,如:等待数据、将数据拷贝到内核空间的PageCache(如果是Buffered I/O的话)、将数据拷贝到用户空间等。下面的几个模型有几个可能看起来很相似(在高级语言的环境中看,这TM不就是换了个概念重新讲一次吗),但从操作系统的角度来看他们是不同的。
1. Blocking I/O(阻塞I/O)
这是最基础的I/O模型,也有人会叫它「同步阻塞I/O」,如下图(从网卡读取UDP数据)所示,请求数据的进程需要一直阻塞等待读取完成才能返回,同时整个读取的动作(这里是recvfrom)也是要同步等待I/O操作的完成才返回。
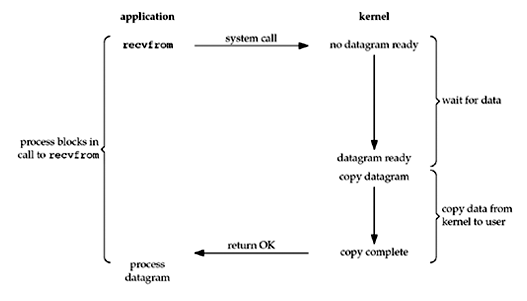
这个模型最大的问题在于比较耗时和浪费CPU资源,I/O设备(这里是网卡)往往是一种传输速率较慢的设备,如果在需要很大吞吐量的系统中这种模型就不太适合了。
但是,有时候我们必须等待从I/O设备中传入的数据或者要向它写入某些数据,这个时候阻塞I/O往往是最适合的。比如你的项目中有一个配置文件,里边包含了很多关于项目的配置信息,那么在启动项目的时候就必须等待这个文件的内容被全部读取并解析后才能继续启动项目,这种场景下BIO是最合适的。
//代码1
//在Java中使用同步阻塞I/O实现文件的读取
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream(new File(PRO_FILE_PATH));
Properties pro = new Properties();
pro.load(fis);
for (Object key : pro.keySet()) {
System.out.println(key);
System.out.println(pro.getProperty((String)key));
}
}2. Nonblocking I/O(非阻塞I/O)
如下图所示,它与BIO刚好相反,当数据没有准备好的时候,recvfrom调用仍然是同步返回结果,只是如果I/O不可用,它会即时返回一个错误结果,然后用户进程不断轮训,那么对于整个用户进程而言,它是非阻塞的。通常情况下,这是一种低效且十分浪费CPU的操作。

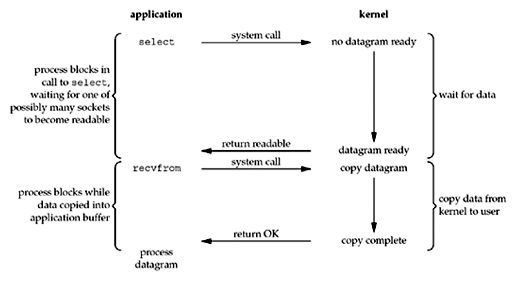
3. I/O Multiplexing(I/O多路复用)
如下图所示,在调用recvfrom之前先调用另外一个系统调用select,当它返回时就表示我们的数据准备好了,然后再调用recvfrom就能直接读取到数据了。在这种场景下,整个读取的动作(由两个系统调用组成)是异步的,同时select动作是会一直阻塞等待I/O事件的到来。
这种模式有个优点,这里的select往往可以监听很多事件,它往往是在多线程的场景下使用,比如在Java的NIO编程中,多个线程可以向同一个Selector注册多个事件,这样就达到了多路复用的效果。
4. Signal-Driven I/O(信号驱动I/O)
如下图所示,用户进程告诉网卡说,你准备好了叫我一声,然后可以去做别的事情,当网卡来叫的时候就可以继续读操作了。按照上边几种模式的分类方法,很容易就把它同样分到了异步非阻塞模型中。
从操作系统的角度来看,「信号驱动I/O」和#3中介绍的「多路复用」还有下面要介绍的「AIO」是有很大的不同的。
但是从概念上讲,它们是很相似的,其他两种其实也可以说是由某种信号驱动的I/O。I/O多路复用的信号是select调用的返回,AIO则是由更底层的实现来传递信号。
当然,还有一个区别是「数据从内核空间拷贝到用户空间」这个动作不再需要recvfrom等待,而是在AIO的信号到来时就已经完成。
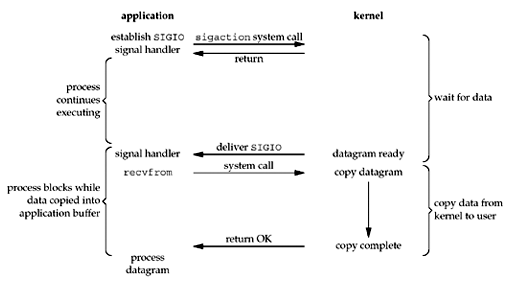
5. Asynchronous I/O (异步I/O)
如下图所示,用户程序使用操作系统提供的异步I/O的系统调用aio_read,这个调用会即时返回,当整个I/O操作完成后它会通知用户进程。典型的异步非阻塞I/O,与「信号驱动I/O」不同的是这个信号是等到所有的I/O动作都执行完之后(数据已经被拷贝到用户空间),才被发送给用户进程。
AIO是一个很好的理念,使用起来也更简单,但是其内部实现就没那么简单了,POSIX中定义的AIO是通过多线程来实现的,它最底层的I/O模块调用还是BIO,而Linux那群人就自己搞了一个真的内核级的异步非阻塞I/O,但是目前仅支持Linux,而且还引入了Direct I/O这个概念。
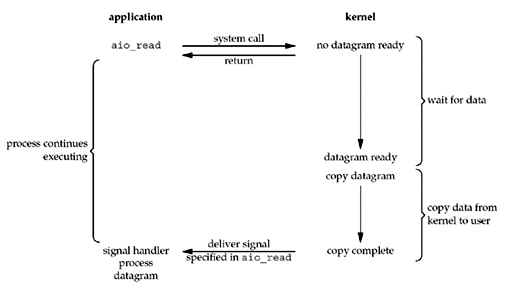
在有些平台中,AIO是默认实现的,比如nodejs,其底层其实也是使用阻塞I/O实现的异步,但是对于开发者来说,可以认为它是完全异步的。下面是nodejs读取文件的一个例子:
//代码2
//node环境下异步读取一个文件
const fs = require('fs')
const file='/Users/lk/Desktop/pro.properties'
fs.readFile(file,'utf-8', (err,data)=>{console.log(data)});同步&异步、阻塞&非阻塞的概念
「Unix网络编程」中说道,按照POSIX标准中的术语,同步指的是I/O动作会导致用户进程阻塞,异步则刚好相反。按照这种分类,上边5种I/O模型中,只有AIO一种是异步的,其他都是同步的。
但是从高级语言的角度看,「I/O多路复用」和「信号驱动I/O」都没有导致用户进程的完全被阻塞,因为在很多高级语言中,程序大多是在多线程环境下运行的,一个线程阻塞并不会阻塞整个程序的执行。从这个角度来看,同步&异步、阻塞&非阻塞这两对概念只是从不同角度对同一个场景的描述。
在Java中,同步异步往往指的是函数是否会等待整个操作处理完成后返回,而阻塞与非阻塞指的往往是用户线程是否需要等待某个事件的到来而阻塞。
Reactor & Proactor
把视线从底层的I/O概念中移开,放到普通的应用层实现上,通常基于以上几种I/O模型,可以对应几个编程模式,这里将重点介绍Reactor和Proactor。
使用Reactor模式构建的服务端
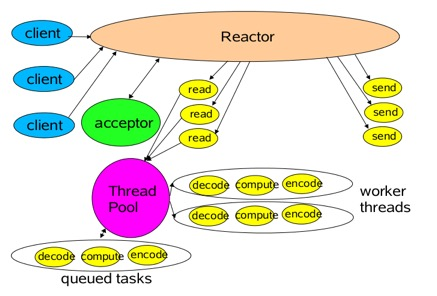
简单来说,Reactor指的是反应器,在这个模式中有一个角色叫分发器(分发器的叫法多种多样,acceptor、selector或者dispatcher),它会分发各种事件给Reactor,Reactor再去根据不同的事件来做相应的动作。在上图中Reactor进行计算的方式是通过线程池实现的,这是在简单的Reactor模式上又添加了更多的能力,来进一步提高吞吐量,这也是Netty的基本架构。
举个栗子-BIO
假设一个初中二年级的班级正在上自习,小红是班上的班花,班上很多男孩子都喜欢她,其中就有小明、小黑和小白,于是他们三个人开始给她写情书,然后通过同学把纸条传给小红。小红一次只能读一封小纸条,所以她只能顺序地拿到小纸条,读小纸条(让老师帮忙读并理解小纸条),思考如何回复,最后把想法写在纸条上(假设后桌1写字好看,小红必须让她来写回信),再发送小纸条发还回去。
这就是普通的BIO(方案#1)。
举个栗子-Reactor
上个例子中的模式中,后边到来的小纸条往往要很久才能收到回信,造成了很坏的用户体验。
假如小红读(看小纸条,耗时t1)、想(回信的内容,耗时t2)、回(把回信的内容写到纸条上,耗时t3)的每个步骤都需要1分钟,则第n个小纸条从收到到发回要耗时:
T = n*(t1 + t2 + t3),那么第一个人只需要3分钟就能拿到回信,第二个人需要6分钟,第3个人就需要9分钟。
于是小红开始想,可以发动四周的同学帮自己思考回复的方案,并让自己的同桌小绿帮自己注意着「老师读完小纸条,后桌1写完小纸条」这两个事件。当有三个纸条同时到来时,小红都放到老师那里,老师顺序的读,每条读完后再交给前桌1和前桌2来思考回复策略,然后交给后桌1写纸条。这样,第n个人拿到回复的时间是T = n*t1 + t2 + t3,它们分别是3分钟、4分钟、5分钟。用户体验明显提高,而且小红自己还可以空出来很多的时间学习(方案#2)。
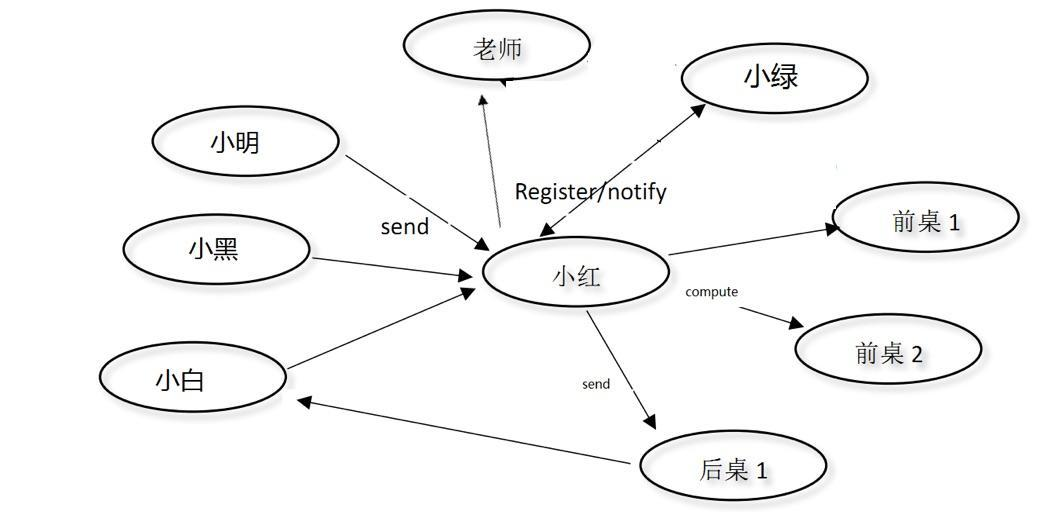
可能有人已经看到问题了,小红可以直接让
小绿,前桌1和前桌2分别处理一张小纸条(方案#3),可以达到同样的效果啊(三张小纸条收到回复的时间同样是3、4、5分钟),干嘛套路这么多。。。
首先,方案#2和方案#3虽然耗时相同,但它们所浪费的资源是不同的,在方案#2里除了老师和后桌1两个不可或缺的资源外,前桌1和前桌2只保留一个人就够了,少一个人帮忙就少一个人分礼物。
其次,在这个例子里刚好t1+t2+t3==3(线程数)*t1,而实际情况是t1+t2+t3>3(线程数)*t1,同时,这里的问题规模也不大,如果只有3个人同时给小红写信,这个方案当然是好的,但是小红太popular了,经常会同时有10个小纸条过来,这种情况下方案#3就要比方案#2慢了(具体的计算过程就不放了)。
Reactor的好处和坏处
Reactor带来的好处是显而易见的:
- 吞吐量大
对小红来说,同样的资源可以传递更多的小纸条 - 对计算资源(CPU)更充分的利用
当然也有一些坏处:
- 系统设计更复杂了
- 由于系统更复杂,导致调试很困难
- 不适合传输大量数据的场景
举个栗子-Proactor
话说,老师发现小绿一直守在自己身边,就问了她是什么情况,然后他跟小红说,「你下次不要让小绿来守着我了,我读完纸条后通知你就行啦」。于是,小绿就不用做分发器的角色了,也被解放出来做计算工作了。
可以看到,分发器的角色其实还在,只是集成在了老师身上了。
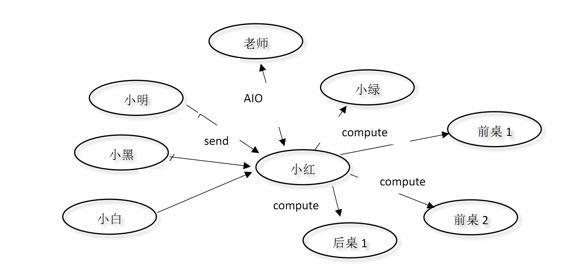
如上图所示,小红收发小纸条的过程变成了这样:
小红拿到小纸条放到老师那里,并且告诉老师读完后通知自己,然后自己就可以去做别的事情了(比如学习)。- 老师读完后通知
小红,小红在小绿、前桌1、前桌2之中找一个人来思考回信。 - 思考完之后告诉
后桌1去写回信。
Proactor模式相比Reactor明显要更好,但唯一的不好的地方就在于,它有一个前提条件是「老师必须支持传递消息」。它与Reactor是一脉相承的,Reactor的缺点同时也是Proactor的缺点。
Reactor的启发
道理是死的,人是活的。对于每一种设计模式或者最佳实践,其最有价值的部分其实是背后的思想。
启发一,事件处理循环
Proactor相比Reactor更好的地方在于,I/O操作和消息通知的过程被下层实现了,业务程序不再需要考虑这些,可以将Proactor看做是对Reactor的又一次封装。根据这个思路可以再进一步,在Reactor模式中不阻塞select,而是在每个业务逻辑执行完后去处理这些事件,也就是在每次循环结束时去处理当前积攒下来的事件(这个模型里如何定义一个循环是很重要的)。
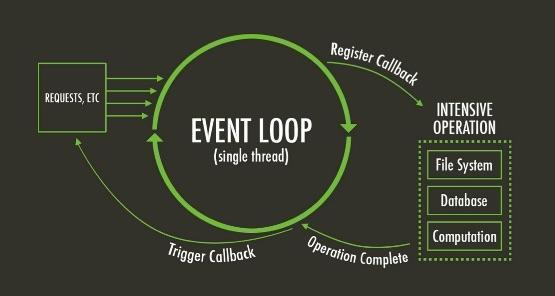
假设在某种场景下,整个程序的目的都是处理单一的事情(比如一个web服务器的目的只是处理请求),我们可以将「与处理请求无关」的逻辑封装到一个框架内,在每次请求处理完后,都执行一次事件的分发和处理,这就是event loop了。很多语言中都有这种概念,如nodejs中的event loop,iOS中的run loop。
启发二,消息通知&多路复用
Reactor和Proactor的思想是一样的,都是要通过「消息通知」和「多路复用」提高整个系统的吞吐量。在I/O之外,其实这两个思想对于我们日常开发也是很有用的,比如我们在某处需要分别执行三个互相不影响(正交)的任务,之后才能做其他事情,根据这两种思想可以写出程序如下:
//代码3
void asyncCall(long millSeconds, Runnable... tasks) {
if (tasks == null || tasks.length < 1) {
return;
}
CountDownLatch latch = new CountDownLatch(tasks.length);
for (Runnable task : tasks) {
Runnable t = () -> {
task.run();
latch.countDown();
};
new Thread(t).start();
}
try {
latch.await(millSeconds, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}这是一个很普通的多线程应用,也可以通过NIO的思想进行解释。这里通过CountDownLatch来进行消息传递,而多个正交的任务复用这一个消息。当然这个例子存在很多问题,每个任务都开一个线程明显造成了资源的浪费,但这些不在这里的考虑范围之内。
还有一个明显的例子是Dubbo的客户端调用,这个下次再说吧。
总结
看了很多概念之后,有时候会突然发现,这不就是之前的某某某概念重新包装了一下吗,如享元模式和单例模式,SOA和微服务,,可能本来就是这样的,我们搞这么多的设计模式,最佳实践,各种花哨的术语和概念,最根本的目的还是要写出更好的代码。或者……也有例外?