

MySQL 服务器上负责对表中数据的读取和写入工作的部分是存储引擎,比如 InnoDB、MyISAM、Memory 等等,不同的存储引擎一般是由不同的人为实现不同的特性而开发的,目前OLTP业务的表如果是使用 MySQL 一般都会使用 InnoDB 引擎,这也是默认的表引擎。
为了能说明 InnoDB 引擎的原理,我们必须先搞清楚 InnoDB 的存储结构,通过这些存储结构才能实现 InnoDB 的事务特性。
首先我们来看看 InnoDB 表的一行数据是如何存储的。InnoDB是一个持久化的存储引擎,也就是数据都是保存在磁盘上面的。但是读写数据,对数据处理,这些是发生在内存中。也就是数据需要从磁盘读取到内存。那么这个读取是如何读取呢?如果处理哪条数据,就读取哪一条到内存中,这样效率也太低了。因为每条数据都是一个硬盘寻址读取,我们要减少这个硬盘寻址读取的次数,可以考虑一块一块的读取数据,这样,我们很可能下次请求需要的数据就已经在内存中了,就省去了从硬盘读取。基于这个思想,InnoDB 将一个表的数据划分成了若干页(pages),这些页通过 B-Tree 索引联系起来。每一页大小默认为 16384 Bytes 也就是 16KB(配置为 innodb_page_size)。
同时,这个 B-Tree 索引就是我们经常听到的聚簇索引(Clustered Index),如果表有主键,那么主键索引就是这个聚簇索引。通过上面的描述,这个索引的节点是包含所有行所有列数据的(就是刚刚我们提到的页)。其他的二级索引的节点只是有指向主键的指针。
对于比较大的字段,例如 Text 类型的字段,如果也存在于这个聚簇索引上,那这个节点数据就会过大,会一下子读取很多页出来,这样读取效率会降低(例如在我们没有想读取这个 Text 列的请求情况下)。所以,InnoDB 对于变长字段,一般倾向于将他们存储在其他地方。至于怎么存储,这个还和 InnoDB **行格式(InnoDB Row Format)**有关。行格式一共有四种:Compact、Redundant、Dynamic和Compressed。
我们可以在创建或修改表的语句中指定行格式:
CREATE TABLE 表 (
)ROW_FORMAT=行格式;
ALTER TABLE 表 ROW_FORMAT=行格式;
Compact 行格式存储
我们来创建一个包含几乎所有基本数据类型的表,其他的例如 geometry,timestamp 等等,也是基于 double 还有 bigint 而来的, text、json、blob等类型,一般不与行数据一起存储,我们之后再说:
create table record_test_1 (
id bigint,
score double,
name char(4),
content varchar(8),
extra varchar(16)
)row_format=compact;
插入如下几条记录:
INSERT INTO `record_test_1`(`id`, `score`, `name`, `content`, `extra`) VALUES (1, 78.5, 'hash', 'wodetian', 'nidetiantadetian');
INSERT INTO `record_test_1`(`id`, `score`, `name`, `content`, `extra`) VALUES (65536, 17983.9812, 'zhx', 'shin', 'nosuke');
INSERT INTO `record_test_1`(`id`, `score`, `name`, `content`, `extra`) VALUES (NULL, -669.996, 'aa', NULL, NULL);
INSERT INTO `record_test_1`(`id`, `score`, `name`, `content`, `extra`) VALUES (2048, NULL, NULL, 'c', 'jun');
目前表结构:
+-------+------------+------+----------+------------------+
| id | score | name | content | extra |
+-------+------------+------+----------+------------------+
| 1 | 78.5 | hash | wodetian | nidetiantadetian |
| 65536 | 17983.9812 | zhx | shin | nosuke |
| NULL | -669.996 | aa | NULL | NULL |
| 2048 | NULL | NULL | c | jun |
+-------+------------+------+----------+------------------+
查看底层存储文件:record_test_1.ibd,用16进制编辑器打开,我这里使用的是Notepad++和他的HEX-Editor插件。可以找到如下的数据域(可能会有其中 mysql 生成的行数据不一样,但是我们创建的行数据内容应该是一样的,而且数据长度应该是一摸一样的,可以搜索其中的字符找到这些数据):

我们这里先直接给出这些数据代表的意义,让大家直观感受下:
变长字段长度列表:10 08
Null值列表:00
记录头信息:00 00 10 00 47
隐藏列DB_ROW_ID:00 00 00 00 08 0c
隐藏列DB_TRX_ID:00 00 00 03 c9 4d
隐藏列DB_ROLL_PTR:b9 00 00 01 2d 01 10
列数据id(1):80 00 00 00 00 00 00 01
列数据score(78.5):00 00 00 00 00 a0 53 40
列数据name(hash):68 61 73 68
列数据content(wodetian):77 6f 64 65 74 69 61 6e
列数据extra(nidetiantadetian):6e 69 64 65 74 69 61 6e 74 61 64 65 74 69 61 6e
变长字段长度列表:06 04
Null值列表:00
记录头信息:00 00 18 00 37
隐藏列DB_ROW_ID:00 00 00 00 08 0d
隐藏列DB_TRX_ID:00 00 00 03 c9 4e
隐藏列DB_ROLL_PTR:ba 00 00 01 2f 01 10
列数据id(65536):80 00 00 00 00 01 00 00
列数据score(17983.9812):b5 15 fb cb fe 8f d1 40
列数据name(zhx):7a 68 78 20
列数据content(shin):73 68 69 6e
列数据extra(nosuke):6e 6f 73 75 6b 65
Null值列表:19
记录头信息:00 00 00 00 27
隐藏列DB_ROW_ID:00 00 00 00 08 0e
隐藏列DB_TRX_ID:00 00 00 03 c9 51
隐藏列DB_ROLL_PTR:bc 00 00 01 33 01 10
列数据score(-669.996):87 16 d9 ce f7 ef 84 c0
列数据name(aa):61 61 20 20
变长字段长度列表:03 01
Null值列表:06
记录头信息:00 00 28 ff 4b
隐藏列DB_ROW_ID:00 00 00 00 08 0f
隐藏列DB_TRX_ID:00 00 00 03 c9 54
隐藏列DB_ROLL_PTR:be 00 00 01 3d 01 10
列数据id(2048):80 00 00 00 00 00 08 00
列数据content(c):63
列数据extra(jun):6a 75 6e
可以看出,在 Compact 行记录格式下,一条 InnoDB 记录,其结构如下图所示:

Compact 行格式存储 - 变长字段长度列表
对于像 varchar, varbinary,text,blob,json以及他们的各种类型的可变长度字段,需要将他们到底占用多少字节存储起来,这样就省去了列数据之间的边界定义,MySQL 就可以分清楚哪些数据属于这一列,那些不属于。Compact行格式存储,开头就是变长字段长度列表,这个列表包括数据不为NULL的每个可变长度字段的长度,并按照列的顺序逆序排列。
例如上面的第一条数据:
+-------+------------+------+----------+------------------+
| id | score | name | content | extra |
+-------+------------+------+----------+------------------+
| 1 | 78.5 | hash | wodetian | nidetiantadetian |
+-------+------------+------+----------+------------------+
有两个数据不为NULL的字段content和extra,长度分别是 8 和 16,转换为 16 进制分别是:0x08,0x10。倒序的顺序排列就是10 08
这是对于长度比较短的情况,用一字节表示长度即可。如果变长列的内容占用的字节数比较多,可能就需要用2个字节来表示。那么什么时候用一个字节,什么时候用两个字节呢?
我们给这张表加一列来测试下:
alter table `record_test_1`
add column `large_content` varchar(1024) null after `extra`;
这时候行数据部分并没有变化。
- 如果 字符集的最大字节长度(我们这里字符集是latin,所以长度就是1)乘以 字段最大字符个数(就是varchar里面的参数,我们这里的
large_content就是1024) < 255,那么就用一个字节表示。这里对于large_content,已经超过了255. - 如果超过255,那么:
- 如果 字段真正占用字节数 < 128,就用一个字节
- 如果 字段真正占用字节数 >= 128,就用两个字节
问题一:那么为什么用 128 作为分界线呢? 一个字节可以最多表示255,但是 MySQL 设计长度表示时,为了区分是否是一个字节表示长度,规定,如果最高位为1,那么就是两个字节表示长度,否则就是一个字节。例如,01111111,这个就代表长度为 127,而如果长度是 128,就需要两个字节,就是 10000000 10000000,首个字节的最高位为1,那么这就是两个字节表示长度的开头,第二个字节可以用所有位表示长度,并且需要注意的是,MySQL采取 Little Endian 的计数方式,低位在前,高位在后,所以 129 就是 10000001 10000000。同时,这种标识方式,最大长度就是 2^15 - 1 = 32767,也就是32 KB。
问题二:如果两个字节也不够表示的长度,该怎么办? innoDB 页大小默认为 16KB,对于一些占用字节数非常多的字段,比方说某个字段长度大于了16KB,那么如果该记录在单个页面中无法存储时,InnoDB会把一部分数据存放到所谓的溢出页中,在变长字段长度列表处只存储留在本页面中的长度,所以使用两个字节也可以存放下来。这个溢出页机制,我们后面和Text字段一起再说。
然后对第一行数据填充large_content字段,对于第二行,将新字段更新为空字符串。
update `record_test_1` set `large_content` = 'abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz' where id = 1;
update `record_test_1` set `large_content` = '' where id = 1;
查看数据:
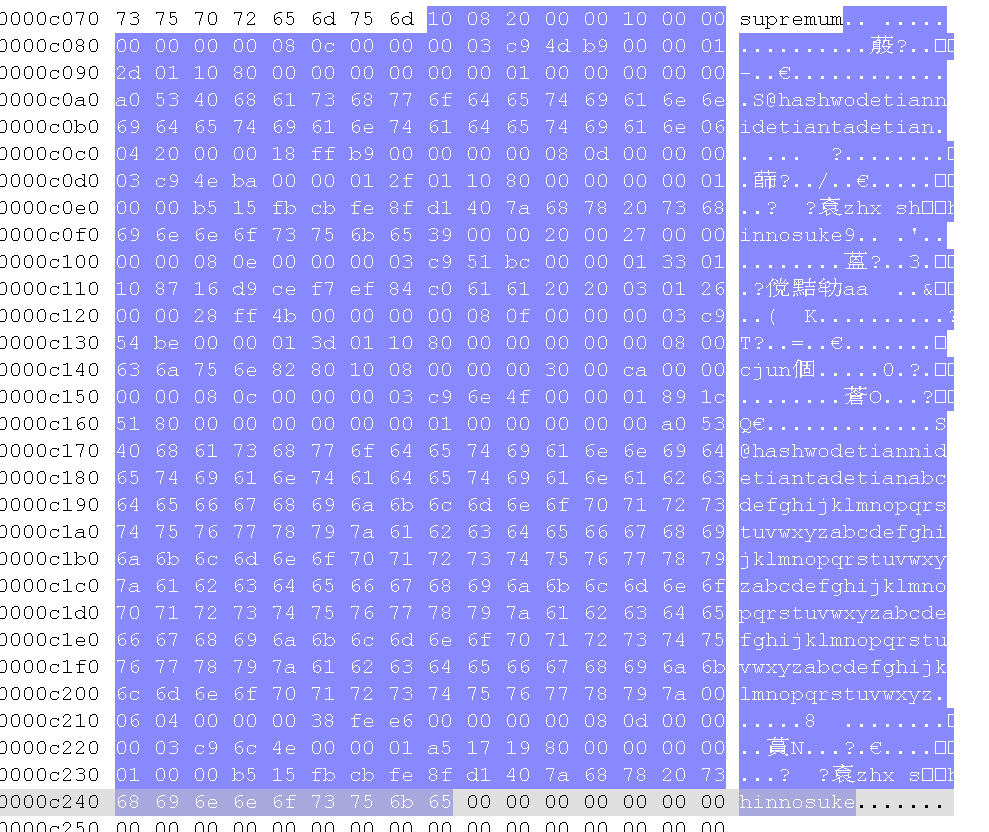
发现COMPACT行记录格式下,对于变长字段的更新,会使原有数据失效,产生一条新的数据在末尾。
第一行数据原有的被废弃,记录头发生变化,主要是打上了删除标记,这个稍后我们就会提到。第一行新数据:
变长字段长度列表:82 80 10 08
Null值列表:00
记录头信息:00 00 30 01 04
隐藏列DB_ROW_ID:00 00 00 00 08 0c
隐藏列DB_TRX_ID:00 00 00 03 c9 6e
隐藏列DB_ROLL_PTR:4f 00 00 01 89 1c 51
列数据id(1):80 00 00 00 00 00 00 01
列数据score(78.5):00 00 00 00 00 a0 53 40
列数据name(hash):68 61 73 68
列数据content(wodetian):77 6f 64 65 74 69 61 6e
列数据extra(nidetiantadetian):6e 69 64 65 74 69 61 6e 74 61 64 65 74 69 61 6e
列数据large_content(abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz):61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 78 79 7a 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 78 79 7a 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 78 79 7a 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 78 79 7a 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 78 79 7a
可以看到,变长字段长度列表变成了82 80 10 08,这里的large_content字符编码最大字节大小为1,字段字符最大个数为1024,这里第一行记录这个字段字符数量是130,所以应该用两个字节。130*1转换成16进制为 0x82 也就是 0x02 + 0x80,最高位标识1之后,就是 0x82 + 0x80,对应咱们的变长字段长度列表的开头。
而新的第二行,变长字段长度列表变成了00 06 04,因为实际large_content占用了0个字节。
Compact 行格式存储 - NULL 值列表
某些字段可能可以为 NULL,如果对于 NULL 还单独存储,是一种浪费空间的行为,和 Compact 行格式存储的理念相悖。采用 BitMap 的思想,标记这些字段,可以节省空间。Null值列表就是这样的一个 BitMap。
NULL 值列表仅仅针对可以为 NULL 的字段,如果一个字段标记了not null,那么这个字段不会进入这个 NUll 值列表的 BitMap 中。
NULL值列表占用几个字节呢?每个不为 NULL 的字段,占用一位,每超过八个字段,就是 8 位,就多一个字节,不足一个字节,高位补0。假如一个表所有字段都是not null,那么就没有NULL 值列表,也就占用 0 个字节。并且,每个字段在这个 bitmap 中,类似于变长字段长度列表,是逆序排列的。
+-------+------------+------+----------+------------------+------------------------------------------------------------------------------------------------------------------------------------+
| id | score | name | content | extra | large_content |
+-------+------------+------+----------+------------------+------------------------------------------------------------------------------------------------------------------------------------+
| 1 | 78.5 | hash | wodetian | nidetiantadetian | abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz |
| 65536 | 17983.9812 | zhx | shin | nosuke | lex |
| NULL | -669.996 | aa | NULL | NULL | NULL |
| 2048 | NULL | NULL | c | jun | NULL |
+-------+------------+------+----------+------------------+------------------------------------------------------------------------------------------------------------------------------------+
针对第一第二行记录,由于没有为 NULL 的字段,所以他们的 NULL 值列表为00. 针对第三行记录,他的 NULL 字段分别是 id,content,extra,large_content,分别是第一,第四,第五,第六列,那么 NULL 值列表为:00111001,也就是 0x39。在加入新字段之前NULL 字段分别是 id,content,extra,分别是第一,第四,第五列,那么 NULL 值列表为:00011001,也就是 0x19 针对第四行记录,他的 NULL 字段分别是score,name,large_content,分别是第二,第三,第六列,那么 NULL 值列表为:00100110,也就是 0x26。在加入新字段之前NULL 字段分别是score,name,分别是第二,第三列,那么 NULL 值列表为:00000110,也就是 0x06。
Compact 行格式存储 - 记录头信息
对于Compact 行格式存储,记录头固定为5字节大小:
| 名称 | 大小(bits) | 描述 |
|---|---|---|
| 无用位 | 2 | 目前没用到 |
| deleted_flag | 1 | 记录是否被删除 |
| min_rec_flag | 1 | B+树中非叶子节点最小记录标记 |
| n_owned | 4 | 该记录对应槽所拥有记录数量 |
| heap_no | 13 | 该记录在堆中的序号,也可以理解为在堆中的位置信息 |
| record_type | 3 | 记录类型,普通数据记录为000,节点指针类型为001,伪记录首记录 infimum 行为010,伪记录最后一个记录 supremum 行为011,1xx的为保留的 |
| next_record pointer | 16 | 页中下一条记录的相对位置 |
对于更新前的第一行和第二行:
第一行记录头信息:00 00 10 00 47
转换为2进制:00000000 00000000 00010000 00000000 01000111
无用位:00,deleted_flag:0,min_rec_flag:0,n_owned:0000,heap_no:0000000000010,record_type:000,next_record:00000000 01000111
第二行记录头信息:00 00 18 00 37
转换为2进制:00000000 00000000 00011000 00000000 00110111
无用位:00,deleted_flag:0,min_rec_flag:0,n_owned:0000,heap_no:0000000000010,record_type:000,next_record:00000000 01000111
对于更新后的原始第一行和第二行:
第一行记录头信息:20 00 10 00 47
转换为2进制:00010000 00000000 00010000 00000000 01000111
无用位:00,deleted_flag:1,min_rec_flag:0,n_owned:0000,heap_no:0000000000010,record_type:000,next_record:00000000 01000111
第二行记录头信息:20 00 18 00 37
转换为2进制:00010000 00000000 00011000 00000000 00110111
无用位:00,deleted_flag:1,min_rec_flag:0,n_owned:0000,heap_no:0000000000010,record_type:000,next_record:00000000 01000111
可以看出,原有的数据 deleted_flag 变成 1,代表数据被删除。
对于更新后的新的第一行和第二行:
第一行记录头信息:00 00 30 00 ca
转换为2进制:00000000 00000000 00110000 00000000 11001010
无用位:00,deleted_flag:0,min_rec_flag:0,n_owned:0000,heap_no:0000000000011,record_type:000,next_record:00000000 11001010
第二行记录头信息:00 00 38 fe e6
转换为2进制:00000000 00000000 00111000 11111110 11100110
无用位:00,deleted_flag:0,min_rec_flag:0,n_owned:0000,heap_no:0000000000111,record_type:000,next_record:11111110 11100110
这些信息的其他字段,在我们之后用到的时候,会详细说明。
Compact 行格式存储 - 隐藏列
隐藏列包含三个:
| 列名 | 大小(字节) | 描述 |
|---|---|---|
| DB_ROW_ID | 6 | 主键ID,这个列不一定会生成。优先使用用户自定义主键作为主键,如果用户没有定义主键,则选取一个 Unique 键作为主键,如果表中连 Unique 键都没有定义的话,则会为表默认添加一个名为 DB_ROW_ID 的隐藏列作为主键 |
| DB_TRX_ID | 6 | 产生当前记录项的事务id,每开始一个新的事务时,系统版本号会自动递增,而事务开始时刻的系统版本号会作为事务id,事务 commit 的话,就会更新这里的 DB_TRX_ID |
| DB_ROLL_PTR | 7 | undo log 指针,指向当前记录项的 undo log,找之前版本的数据需通过此指针。如果事务回滚的话,则从 undo Log 中把原始值读取出来再放到记录中去 |
这里我们先不详细展开这些列的说明,只是先知道这些列即可,只会会在聚簇索引说明以及多版本控制分析的章节中详细说明。
Compact 行格式存储 - 数据列 bigint 存储
对于 bigint 类型,如果不为 NULL,则占用8字节,首位为符号位,剩余位存储数字,数字范围是 -2^63 ~ 2^63 - 1 = -9223372036854775808 ~ 9223372036854775807。如果为 NULL,则不占用任何存储空间。
存储时,如果为正数,则首位 bit 为1,如果为负数,则首位为 0 并用补码的形式存储。
对于我们的四行数据:
第一行列数据id(1):80 00 00 00 00 00 00 01
第二行列数据id(65536):80 00 00 00 00 01 00 00
第三行行列数据id(NULL):空
第四行列数据id(2048):80 00 00 00 00 00 08 00
其他的类似的整数存储,tinyint(1字节),smallint(2字节),mediumint(3字节),int(4字节)等,只是字节长度上面有区别。对应的无符号类型,tinyint unsigned,smallint unsigned, mediumint unsigned,int unsigned,bigint unsigned等等,仅仅是是否有符号位的区别。
同时,这里提一下 bigint(20) 里面这个 20 的作用。他只是限制显示,和底层存储没有任何关系。整型字段有个 zerofill 属性,设置后(例如 bigint(20) zerofill),在数字长度不够 20 的数据前面填充0,以达到设定的长度。这个 20 就是显示长度的设定。
Compact 行格式存储 - 数据列 double 存储
double 的存储对于非 NULL 的列,符合 IEEE 754 floating-point "double format" bit layout 这个统一标准:
- 最高位 bit 表示符号位(0x8000000000000000)
- 第二到第十二的 bit 表示指数(0x7ff0000000000000)
- 剩下的 bit 表示浮点数真正的数字(0x000fffffffffffffL)
同时,Innodb存储在数据文件上的格式为 Little Edian,需要进行反转后,才能取得字段的真实值。 同样的,如果为 NULL, 则不占用空间。
例如:
第一行列数据score(78.5):00 00 00 00 00 a0 53 40
翻转: 40 53 a0 00 00 00 00 00
二进制: 01000000 01010011 10100000 00000000 00000000 00000000 00000000 00000000
符号位:0,指数位10000000101 = 1029,减去阶数 1023 = 实际指数 6,小数部分0.0011101000000000000000000000000000000000000000000000,转换为十进制为0.125 + 0.0625 + 0.03125 + 0.0078125 = 0.2265625, 加上隐含数字 1 为 1.2265625, 之后乘以 2 的 6 次方就是 1.2265625 * 64 = 78.5
计算过程较为复杂,可以利用 Java 的 Double.longBitsToDouble()转换:
public static void main(String[] args) {
System.out.println(Double.longBitsToDouble(0x4053a00000000000L));
}
输出为 78.5
类似的类型,float,也是相同的格式,只是长度减半。
Compact 行格式存储 - 数据列 char 存储
对于定长字段,不需要存长度信息直接存储数据即可,如果不足设定的长度则补充。对于char类型,补充 0x20, 对应的就是空格。
例如:
第一行列数据name(hash):68 61 73 68
第二行列数据name(zhx):7a 68 78 20
第三行列数据name(aa):61 61 20 20
第四行列数据name(NULL):空
对于类似的 binary 类型,补充 0x00。
Compact 行格式存储 - 数据列 varchar 存储
因为数据开头有可变长度字段长度列表,所以 varchar 只需要保存实际的数据即可,不需要填充额外的数据。
正是由于这个特性,对于可变长度字段的更新,一般都是将老记录标记为删除,在记录末尾添加新的一条记录填充更新后的记录。这样提高了更新速度,但是增加了存储碎片。
