

作者介绍:邹弓一,美团点评前端工程师,5年 Web 前端开发经验,现在是美团点评点餐团队的一员。
前言
本文主要介绍facebook推出的一个类库immutable.js,以及如何将immutable.js集成到我们团队现有的react+redux架构的移动端项目中。
本文较长(5000字左右),建议阅读时间: 20 min
通过阅读本文,你可以学习到:
- 什么是immutable.js,它的出现能解决什么问题
- immutable.js的特性以及使用api
- 在一个redux+react的项目中,引入immutable.js能带来什么提升
- 如何集成immutable.js到react+redux中
- 集成前后的数据对比
- immutabe.js使用过程中的一些注意点
目录
- 一. immutable.js
- 1.1 原生js引用类型的坑
- 1.2 immutable.js介绍
- 1.2.1 Persistent data structure (持久化数据结构)
- 1.2.2 structural sharing (结构共享)
- 1.2.3 support lazy operation (惰性操作)
- 1.3 常用api介绍
- 1.4 immutable.js的优缺点
- 二. 在react+redux中集成immutable.js实践
- 2.1 点餐H5项目引入immutable.js前的现状
- 2.2 如何将immutableJS集成到一个react+redux项目中
- 2.2.1 明确集成方案,边界界定
- 2.2.2 具体集成代码实现方法
- 2.3 点餐H5项目优化前后对比
- 三. immutable.js使用过程中的一些注意点
- 四. 总结
一. immutable.js
1.1 原生js引用类型的坑
先考虑如下两个场景:
// 场景一
var obj = {a:1, b:{c:2}};
func(obj);
console.log(obj) //输出什么??
// 场景二
var obj = ={a:1};
var obj2 = obj;
obj2.a = 2;
console.log(obj.a); // 2
console.log(obj2.a); // 2 上面两个场景相信大家平日里开发过程中非常常见,具体原因相信大家也都知道了,这边不展开细说了,通常这类问题的解决方案是通过浅拷贝或者深拷贝复制一个新对象,从而使得新对象与旧对象引用地址不同。
在js中,引用类型的数据,优点在于频繁的操作数据都是在原对象的基础上修改,不会创建新对象,从而可以有效的利用内存,不会浪费内存,这种特性称为mutable(可变),但恰恰它的优点也是它的缺点,太过于灵活多变在复杂数据的场景下也造成了它的不可控性,假设一个对象在多处用到,在某一处不小心修改了数据,其他地方很难预见到数据是如何改变的,针对这种问题的解决方法,一般就像刚才的例子,会想复制一个新对象,再在新对象上做修改,这无疑会造成更多的性能问题以及内存浪费。
为了解决这种问题,出现了immutable对象,每次修改immutable对象都会创建一个新的不可变对象,而老的对象不会改变。
1.2 immutable.js介绍
现今,实现了immutable数据结构的js类库有好多,immutable.js就是其中比较主流的类库之一。
Immutable.js出自Facebook,是最流行的不可变数据结构的实现之一。它从头开始实现了完全的持久化数据结构,通过使用像tries这样的先进技术来实现结构共享。所有的更新操作都会返回新的值,但是在内部结构是共享的,来减少内存占用(和垃圾回收的失效)。
immutable.js主要有三大特性:
- Persistent data structure (持久化数据结构)
- structural sharing (结构共享)
- support lazy operation (惰性操作)
下面我们来一一具体介绍下这三个特性:
1.2.1 Persistent data structure (持久化数据结构)
一般听到持久化,在编程中第一反应应该是,数据存在某个地方,需要用到的时候就能从这个地方拿出来直接使用
但这里说的持久化是另一个意思,用来描述一种数据结构,一般函数式编程中非常常见,指一个数据,在被修改时,仍然能够保持修改前的状态,从本质来说,这种数据类型就是不可变类型,也就是immutable
immutable.js提供了十余种不可变的类型(List,Map,Set,Seq,Collection,Range等)
到这,有些同学可能会觉得,这和之前讲的拷贝有什么区别,也是每次都创建一个新对象,开销一样很大。ok,那接下来第二个特性会为你揭开疑惑。
1.2.2 structural sharing (结构共享)
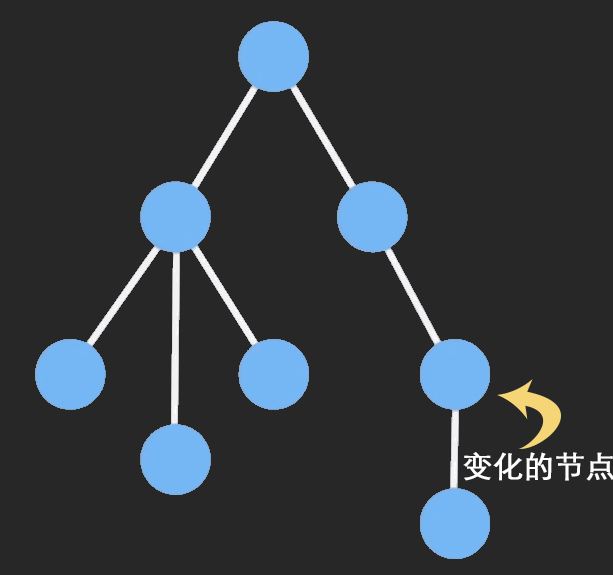
immutable使用先进的tries(字典树)技术实现结构共享来解决性能问题,当我们对一个Immutable对象进行操作的时候,ImmutableJS会只clone该节点以及它的祖先节点,其他保持不变,这样可以共享相同的部分,大大提高性能。
这边岔开介绍一下tries(字典树),我们来看一个例子
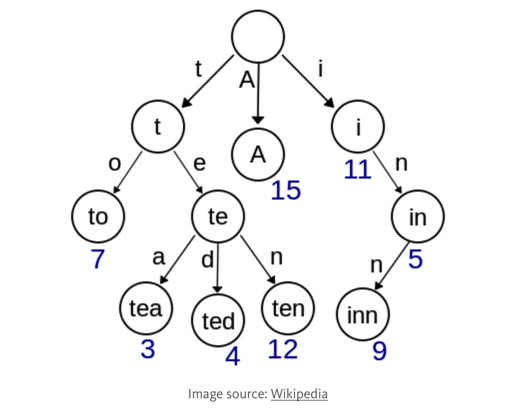
(图片来自网络)
图1就是一个字典树结构object对象,顶端是root节点,每个子节点都有一个唯一标示(在immutable.js中就是hashcode)
假设我们现在取data.in的值,根据标记i和n的路径.可以找到包含5的节点.,可知data.in=5, 完全不需要遍历整个对象
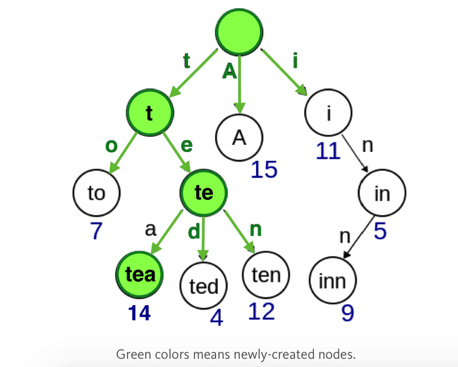
那么,现在我们要把data.tea从3修改成14,怎么做呢?
可以看到图2绿色部分,不需要去遍历整棵树,只要从root开始找就行
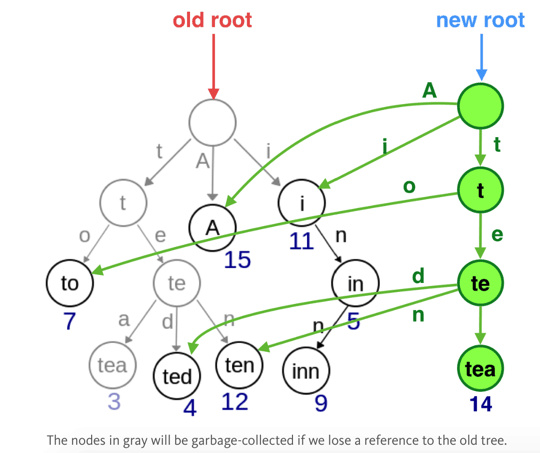
实际使用时,可以创建一个新的引用,如图3,data.tea建一个新的节点,其他节点和老的对象共享,而老的对象还是保持不变
由于这个特性,比较两个对象时,只要他们的hashcode是相同的,他们的值就是一样的,这样可以避免深度遍历
1.2.3 support lazy operation (惰性操作)
- 惰性操作 Seq
- 特征1:Immutable (不可变)
- 特征2:lazy(惰性,延迟)
这个特性非常的有趣,这里的lazy指的是什么?很难用语言来描述,我们看一个demo,看完你就明白了
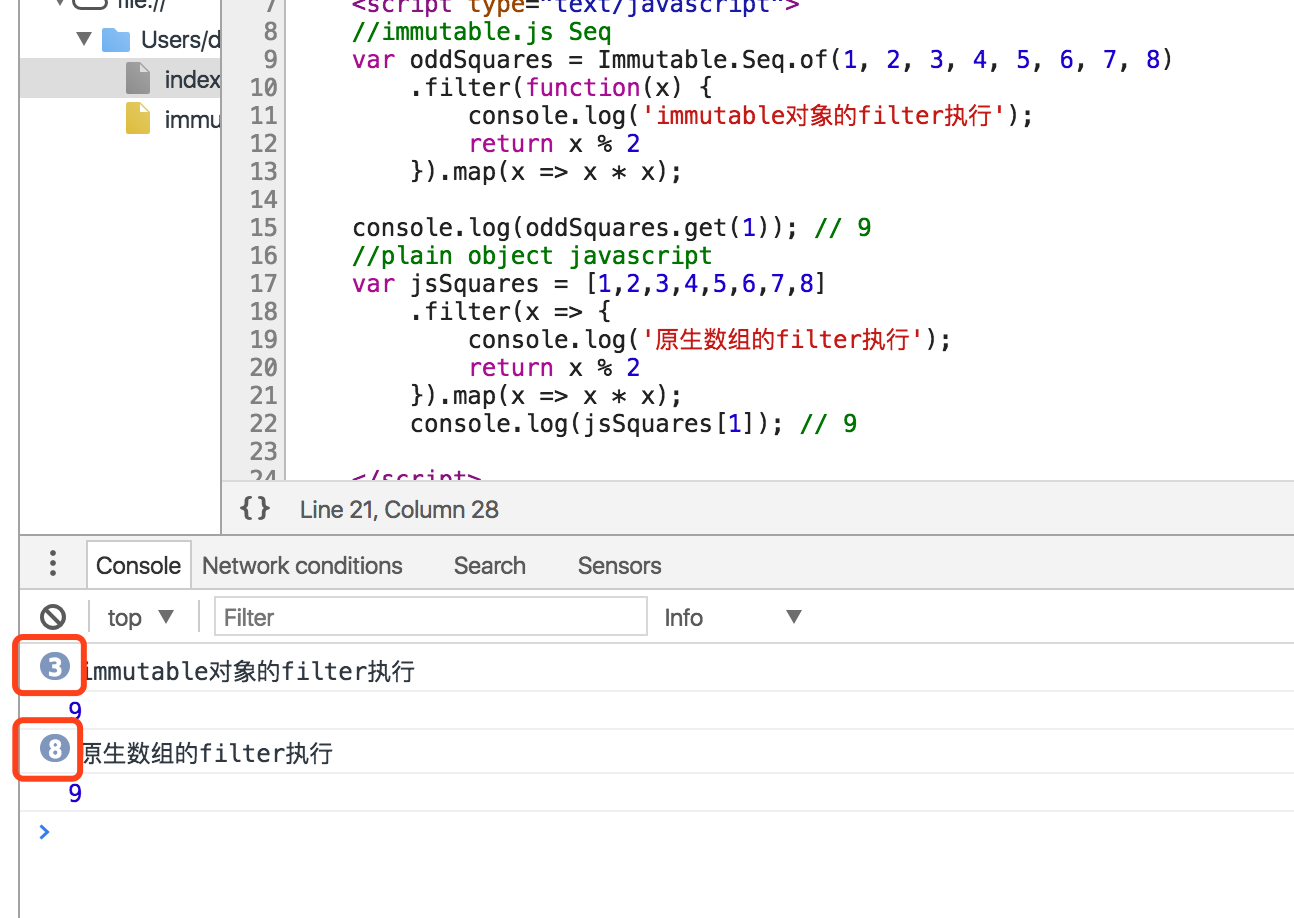
这段代码的意思就是,数组先取奇数,然后再对基数进行平方操作,然后在console.log第2个数,同样的代码,用immutable的seq对象来实现,filter只执行了3次,但原生执行了8次。
其实原理就是,用seq创建的对象,其实代码块没有被执行,只是被声明了,代码在get(1)的时候才会实际被执行,取到index=1的数之后,后面的就不会再执行了,所以在filter时,第三次就取到了要的数,从4-8都不会再执行
想想,如果在实际业务中,数据量非常大,如在我们点餐业务中,商户的菜单列表可能有几百道菜,一个array的长度是几百,要操作这样一个array,如果应用惰性操作的特性,会节省非常多的性能
1.3 常用api介绍
//Map() 原生object转Map对象 (只会转换第一层,注意和fromJS区别)
immutable.Map({name:'danny', age:18})
//List() 原生array转List对象 (只会转换第一层,注意和fromJS区别)
immutable.List([1,2,3,4,5])
//fromJS() 原生js转immutable对象 (深度转换,会将内部嵌套的对象和数组全部转成immutable)
immutable.fromJS([1,2,3,4,5]) //将原生array --> List
immutable.fromJS({name:'danny', age:18}) //将原生object --> Map
//toJS() immutable对象转原生js (深度转换,会将内部嵌套的Map和List全部转换成原生js)
immutableData.toJS();
//查看List或者map大小
immutableData.size 或者 immutableData.count()
// is() 判断两个immutable对象是否相等
immutable.is(imA, imB);
//merge() 对象合并
var imA = immutable.fromJS({a:1,b:2});
var imA = immutable.fromJS({c:3});
var imC = imA.merge(imB);
console.log(imC.toJS()) //{a:1,b:2,c:3}
//增删改查(所有操作都会返回新的值,不会修改原来值)
var immutableData = immutable.fromJS({
a:1,
b:2,
c:{
d:3
}
});
var data1 = immutableData.get('a') // data1 = 1
var data2 = immutableData.getIn(['c', 'd']) // data2 = 3 getIn用于深层结构访问
var data3 = immutableData.set('a' , 2); // data3中的 a = 2
var data4 = immutableData.setIn(['c', 'd'], 4); //data4中的 d = 4
var data5 = immutableData.update('a',function(x){return x+4}) //data5中的 a = 5
var data6 = immutableData.updateIn(['c', 'd'],function(x){return x+4}) //data6中的 d = 7
var data7 = immutableData.delete('a') //data7中的 a 不存在
var data8 = immutableData.deleteIn(['c', 'd']) //data8中的 d 不存在上面只列举了部分常用方法,具体查阅官网api:facebook.github.io/immutable-j…
immutablejs还有很多类似underscore语法糖,使用immutable.js之后完全可以在项目中去除lodash或者underscore之类的工具库。
1.4 immutable.js的优缺点
优点:
- 降低mutable带来的复杂度
- 节省内存
- 历史追溯性(时间旅行):时间旅行指的是,每时每刻的值都被保留了,想回退到哪一步只要简单的将数据取出就行,想一下如果现在页面有个撤销的操作,撤销前的数据被保留了,只需要取出就行,这个特性在redux或者flux中特别有用
- 拥抱函数式编程:immutable本来就是函数式编程的概念,纯函数式编程的特点就是,只要输入一致,输出必然一致,相比于面向对象,这样开发组件和调试更方便
缺点:
- 需要重新学习api
- 资源包大小增加(源码5000行左右)
- 容易与原生对象混淆:由于api与原生不同,混用的话容易出错。
二. 在react+redux中集成immutable.js实践
前面介绍了这么多,其实是想引出这块重点,这章节会结合点评点餐团队在实际项目中的实践,给出使用immutable.js前后对react+redux项目的性能提升
2.1 点餐H5项目引入immutable.js前的现状
目前项目使用react+redux,由于项目的不断迭代以及需求复杂度的提高,redux中维护的state结构日渐庞大,已经不是一个简单的平铺数据了,如菜单页state已经会出现三四层的object以及array嵌套,我们知道,JS中的object与array是引用类型,在不断的操作过程中,state经过多次的action改变之后, 原本复杂state已经变得不可控,结果就是导致了一次state变化牵动了许多自身状态没有发生改动的component去re-render。如下图
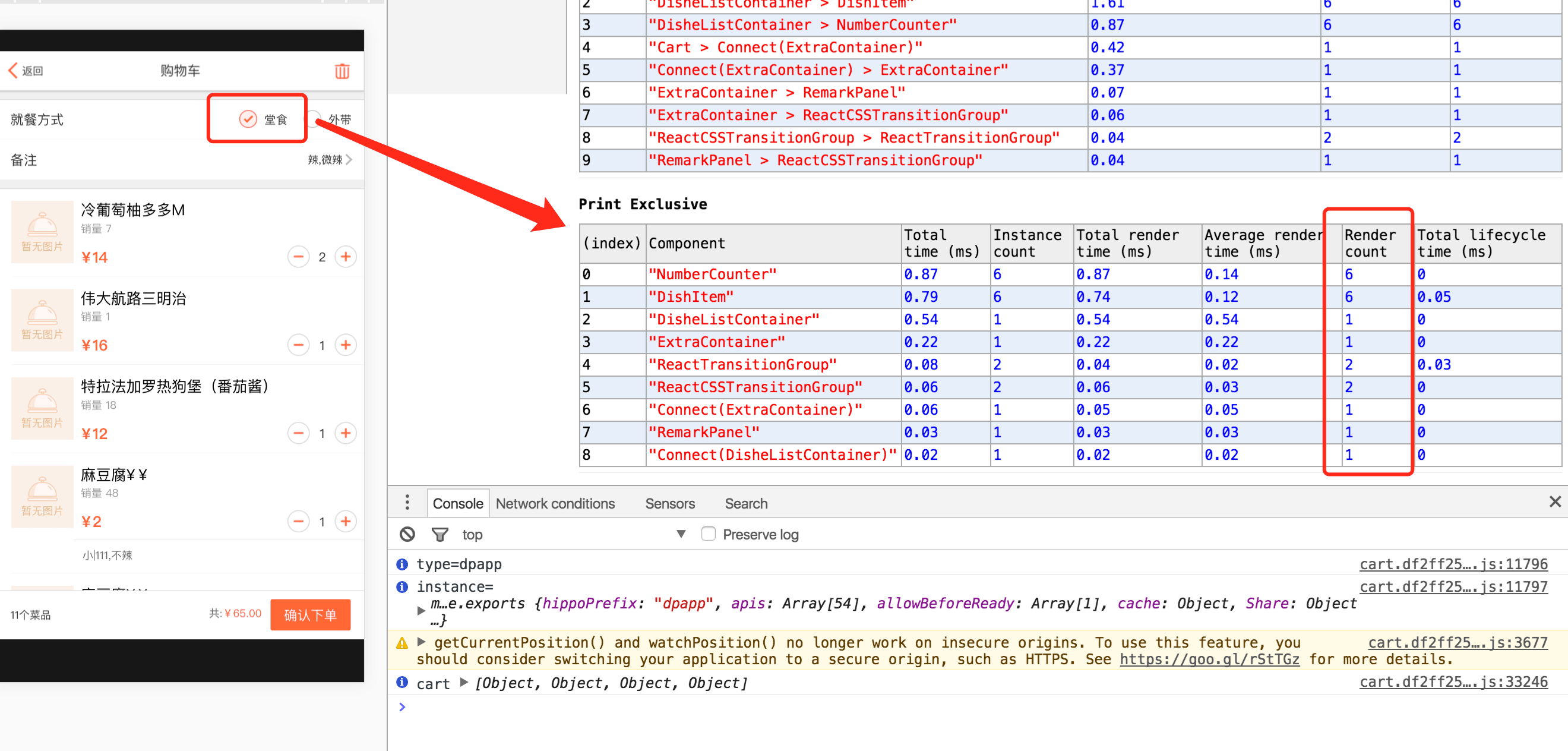
这里推荐一下react的性能指标工具react-addons-perf
如果你没有使用这个工具看之前,别人问你,图中这个简单的堂食/外带的button的变化会引起哪些component去re-render,你可能会回答只有就餐方式这个component。
但当你真正使用react-addons-perf去查看之后你会发现,WTF??!一次操作竟然导致了这么多没任何关系的component重新渲染了??
什么原因??
shouldComponentUpdate
shouldComponentUpdate (nextProps, nextState) {
return nextProps.id !== this.props.id;
}; 相信接触过react开发的同学都知道,react有个重要的性能优化的点就是shouldComponentUpdate,shouldComponentUpdate返回true代码该组件要re-render,false则不重新渲染
那简单的场景可以直接使用==去判断this.props和nextProps是否相等,但当props是一个复杂的结构时,==肯定是没用的
网上随便查一下就会发现shallowCompare这个东西,我们来试一下
使用shallowCompare的例子:
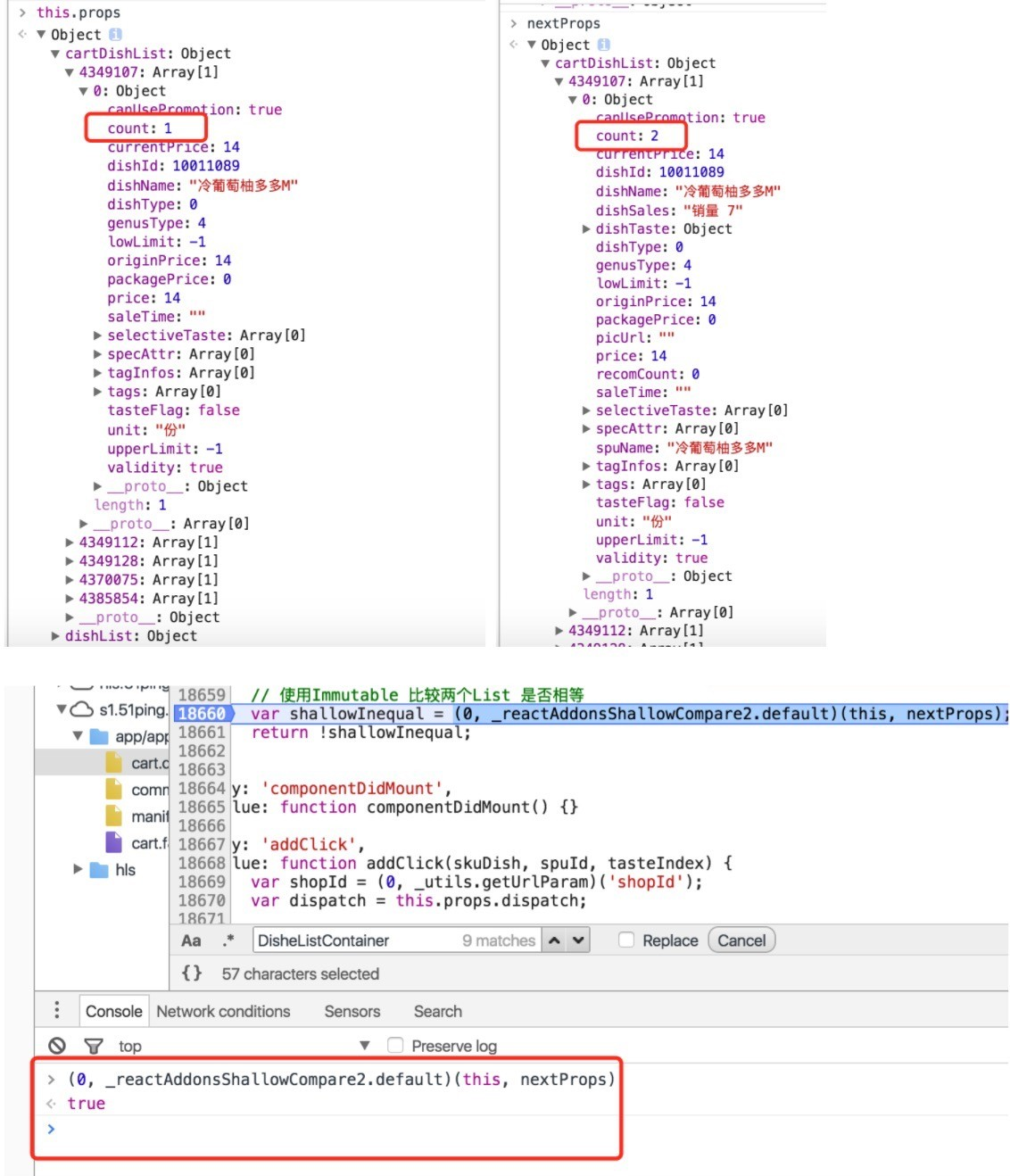
可以看到,其实2个对象的count是不相等的,但shallowCompare返回的还是true
原因:
shallowCompare只是进行了对象的顶层节点比较,也就是浅比较,上图中的props由于结构比较复杂,在深层的对象中有count不一样,所以这种情况无法通过shallowCompare处理。
shallowEqual源码:
function shallowEqual(objA, objB) {
if (is(objA, objB)) {
return true;
}
if (typeof objA !== 'object' || objA === null || typeof objB !== 'object' || objB === null) {
return false;
}
var keysA = Object.keys(objA);
var keysB = Object.keys(objB);
if (keysA.length !== keysB.length) {
return false;
}
//这里只比较了对象A和B第一层是否相等,当对象过深时,无法返回正确结果
// Test for A's keys different from B.
for (var i = 0; i < keysA.length; i++) {
if (!hasOwnProperty.call(objB, keysA[i]) || !is(objA[keysA[i]], objB[keysA[i]])) {
return false;
}
}
return true;
}这里,我们肯定不可能每次比较都是用深比较,去遍历所有的结构,这样带来的性能代价是巨大的,刚才我们说到immutable.js有个特性是引用比较(hashcode),这个特性就完美契合这边的场景
2.2 如何将immutableJS集成到一个react+redux项目中
2.2.1 明确集成方案,边界界定
首先,我们有必要来划分一下边界,哪些数据需要使用不可变数据,哪些数据要使用原生js数据结构,哪些地方需要做互相转换
- 在redux中,全局state必须是immutable的,这点毋庸置疑是我们使用immutable来优化redux的核心
- 组件props是通过redux的connect从state中获得的,并且引入immutableJS的另一个目的是减少组件shouldComponentUpdate中不必要渲染,shouldComponentUpdate中比对的是props,如果props是原生JS就失去了优化的意义
- 组件内部state如果需要提交到store的,必须是immutable,否则不强制
- view提交到action中的数据必须是immutable
- Action提交到reducer中的数据必须是immutable
- reducer中最终处理state必须是以immutable的形式处理并返回
- 与服务端ajax交互中返回的callback统一封装,第一时间转换成immutable数据
从上面这些点可以看出,几乎整个项目都是必须使用immutable的,只有在少数与外部依赖有交互的地方使用了原生js。
这么做的目的其实就是为了防止在大型项目中,原生js与immutable混用,导致coder自己都不清楚一个变量中存储的到底是什么类型的数据。
那有人可能会觉得说,在一个全新项目中这样是可行的,但在一个已有的成熟项目中,要将所有的变量全部改成immutablejs,代码的改动量与侵入性非常大,风险也高。那他们会想到,将reducer中的state用fromJS()改成immutable进行state操作,然后再通过toJS()转成原生js返回出来,这样不就可以即让state变得可追溯,又不用去修改reducer以外的代码,代价非常的小。
export default function indexReducer(state, action) {
switch (action.type) {
case RECEIVE_MENU:
state = immutable.fromJS(state); //转成immutable
state = state.merge({a:1});
return state.toJS() //转回原生js
}
}两点问题:
- fromJS() 和 toJS() 是深层的互转immutable对象和原生对象,性能开销大,尽量不要使用(见下一章节做了具体的对比)
- 组件中props和state还是原生js,shouldComponentUpdate仍然无法做利用immutablejs的优势做深度比较
2.2.2 具体集成代码实现方法
redux-immutable
redux中,第一步肯定利用combineReducers来合并reducer并初始化state,redux自带的combineReducers只支持state是原生js形式的,所以这里我们需要使用redux-immutable提供的combineReducers来替换原来的方法
import {combineReducers} from 'redux-immutable';
import dish from './dish';
import menu from './menu';
import cart from './cart';
const rootReducer = combineReducers({
dish,
menu,
cart,
});
export default rootReducer;reducer中的initialState肯定也需要初始化成immutable类型
const initialState = Immutable.Map({});
export default function menu(state = initialState, action) {
switch (action.type) {
case SET_ERROR:
return state.set('isError', true);
}
}state成为了immutable类型,那相应的页面其他文件都需要做相应的写法改变
//connect
function mapStateToProps(state) {
return {
menuList: state.getIn(['dish', 'list']), //使用get或者getIn来获取state中的变量
CartList: state.getIn(['dish', 'cartList'])
}
}页面中原来的原生js变量需要改造成immutable类型,不一一列举了
服务端交互ajax封装
前端代码使用了immutable,但服务端下发的数据还是json,所以需要统一在ajax处做封装并且将服务端返回数据转成immutable
//伪代码
$.ajax({
type: 'get',
url: 'XXX',
dataType: 'json',
success(res){
res = immutable.fromJS(res || {});
callback && callback(res);
},
error(e) {
e = immutable.fromJS(e || {});
callback && callback(e);
},
});这样的话,页面中统一将ajax返回当做immutable类型来处理,不用担心混淆
shouldComponentUpdate
重中之重!之前已经介绍了很多为什么要用immutable来改造shouldComponentUpdate,这里就不多说了,直接看怎么改造
shouldComponentUpdate具体怎么封装有很多种办法,我们这里选择了封装一层component的基类,在基类中去统一处理shouldComponentUpdate,组件中直接继承基类的方式
//baseComponent.js component的基类方法
import React from 'react';
import {is} from 'immutable';
class BaseComponent extends React.Component {
constructor(props, context, updater) {
super(props, context, updater);
}
shouldComponentUpdate(nextProps, nextState) {
const thisProps = this.props || {};
const thisState = this.state || {};
nextState = nextState || {};
nextProps = nextProps || {};
if (Object.keys(thisProps).length !== Object.keys(nextProps).length ||
Object.keys(thisState).length !== Object.keys(nextState).length) {
return true;
}
for (const key in nextProps) {
if (!is(thisProps[key], nextProps[key])) {
return true;
}
}
for (const key in nextState) {
if (!is(thisState[key], nextState[key])) {
return true;
}
}
return false;
}
}
export default BaseComponent;组件中如果需要使用统一封装的shouldComponentUpdate,则直接继承基类
import BaseComponent from './BaseComponent';
class Menu extends BaseComponent {
constructor() {
super();
}
…………
}当然如果组件不想使用封装的方法,那直接在该组件中重写shouldComponentUpdate就行了
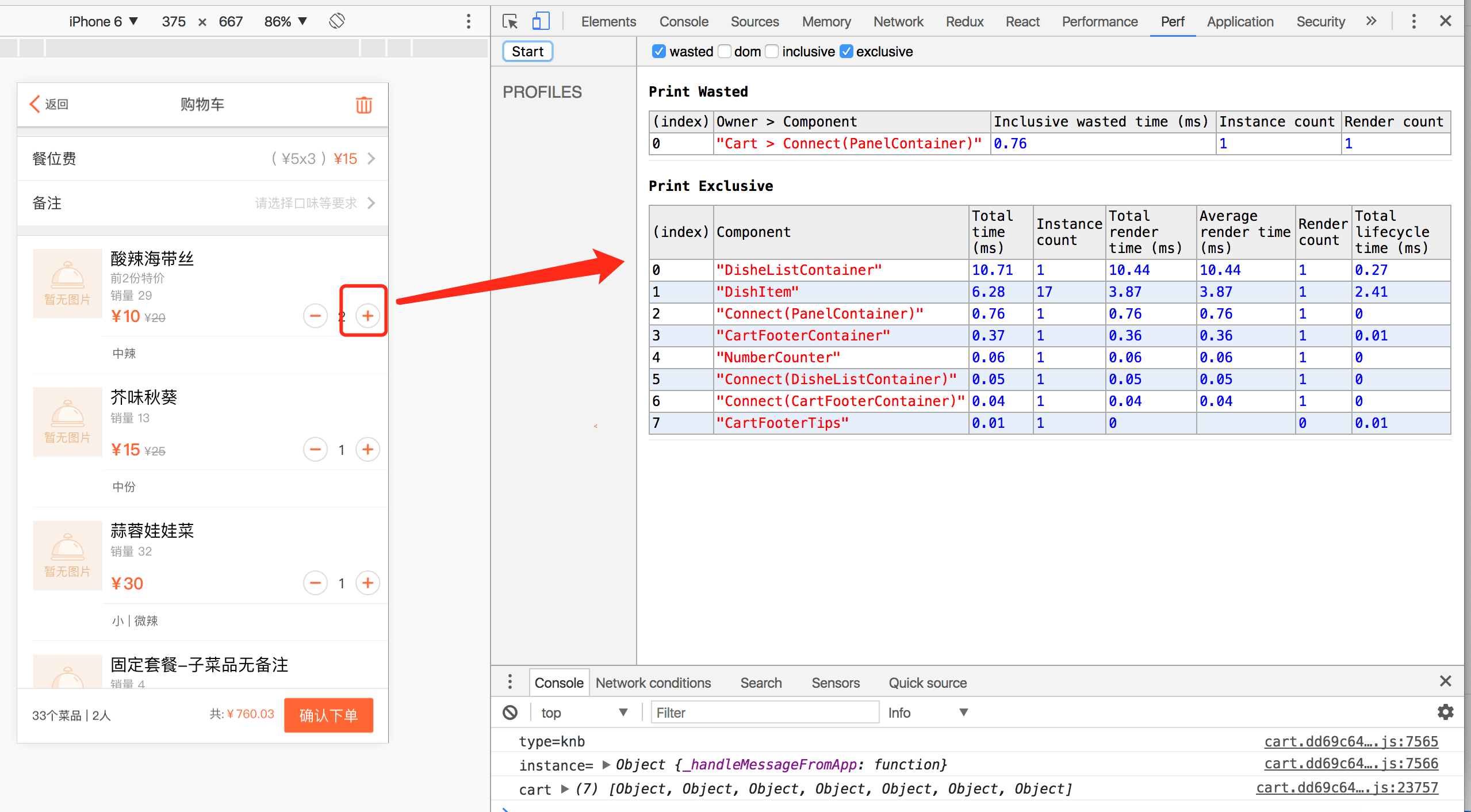
2.3 点餐H5项目优化前后对比
这边只是截了几张图举例
优化前搜索页:
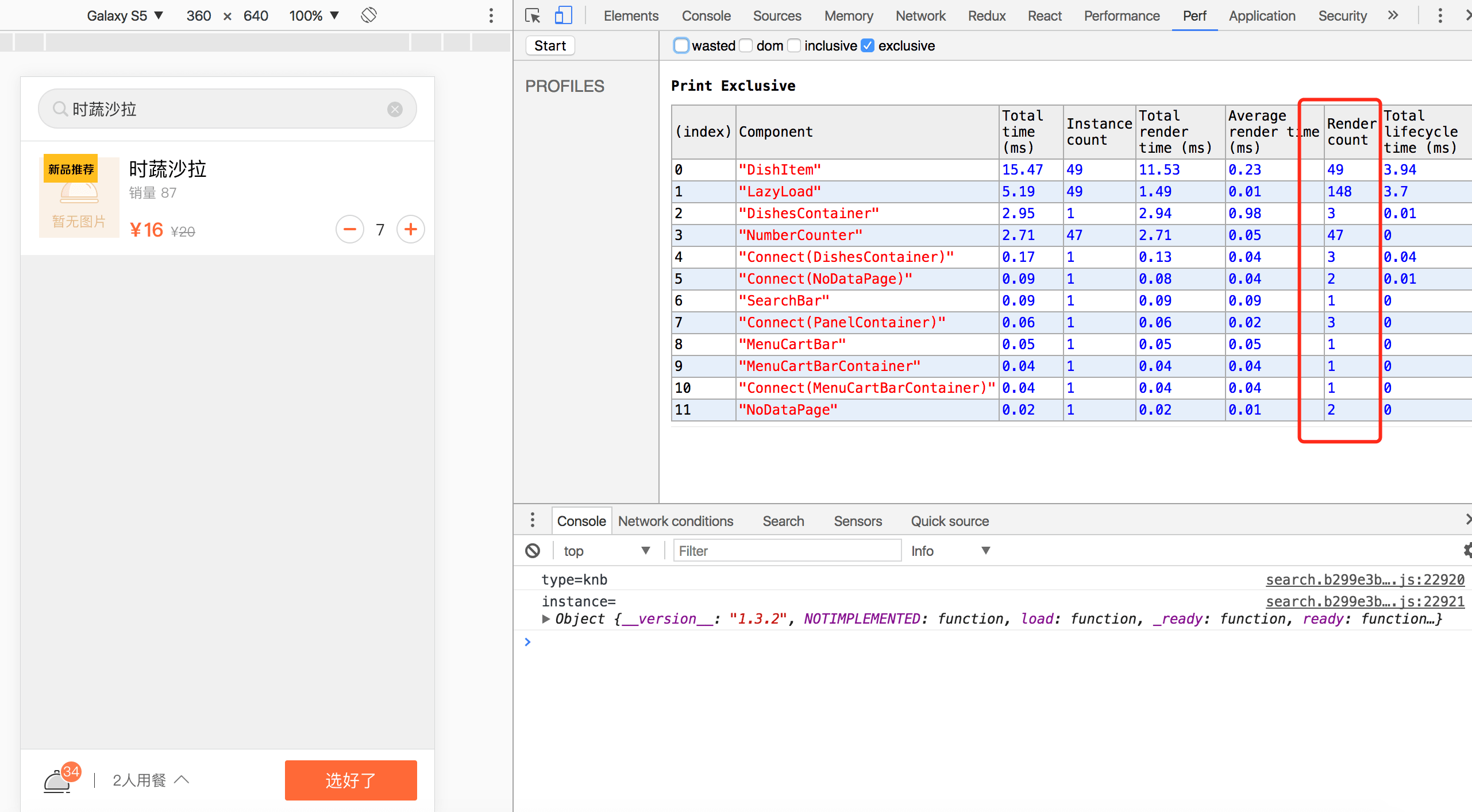
优化后:
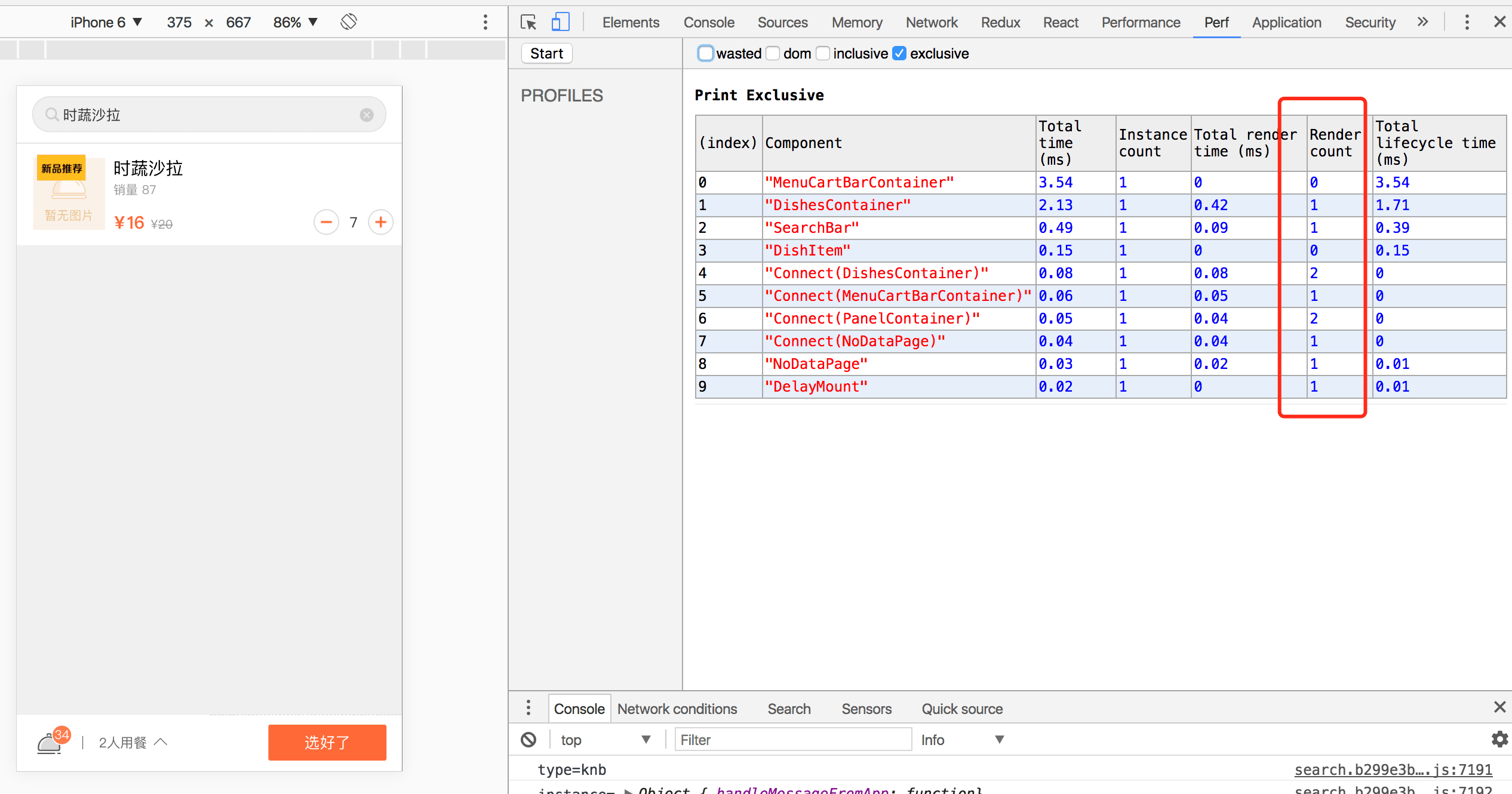
优化前购物车页:
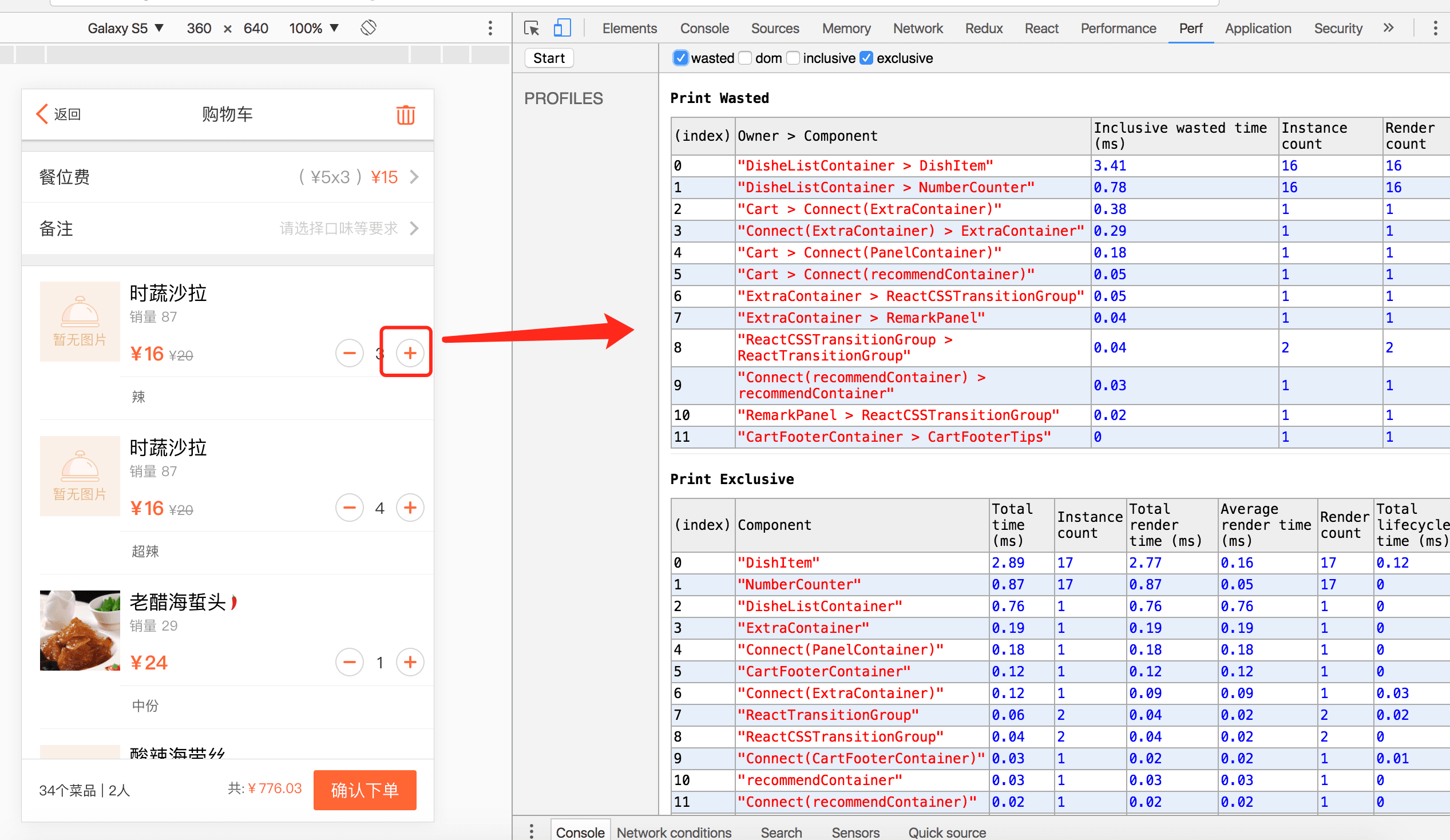
优化后:
三. immutable.js使用过程中的一些注意点
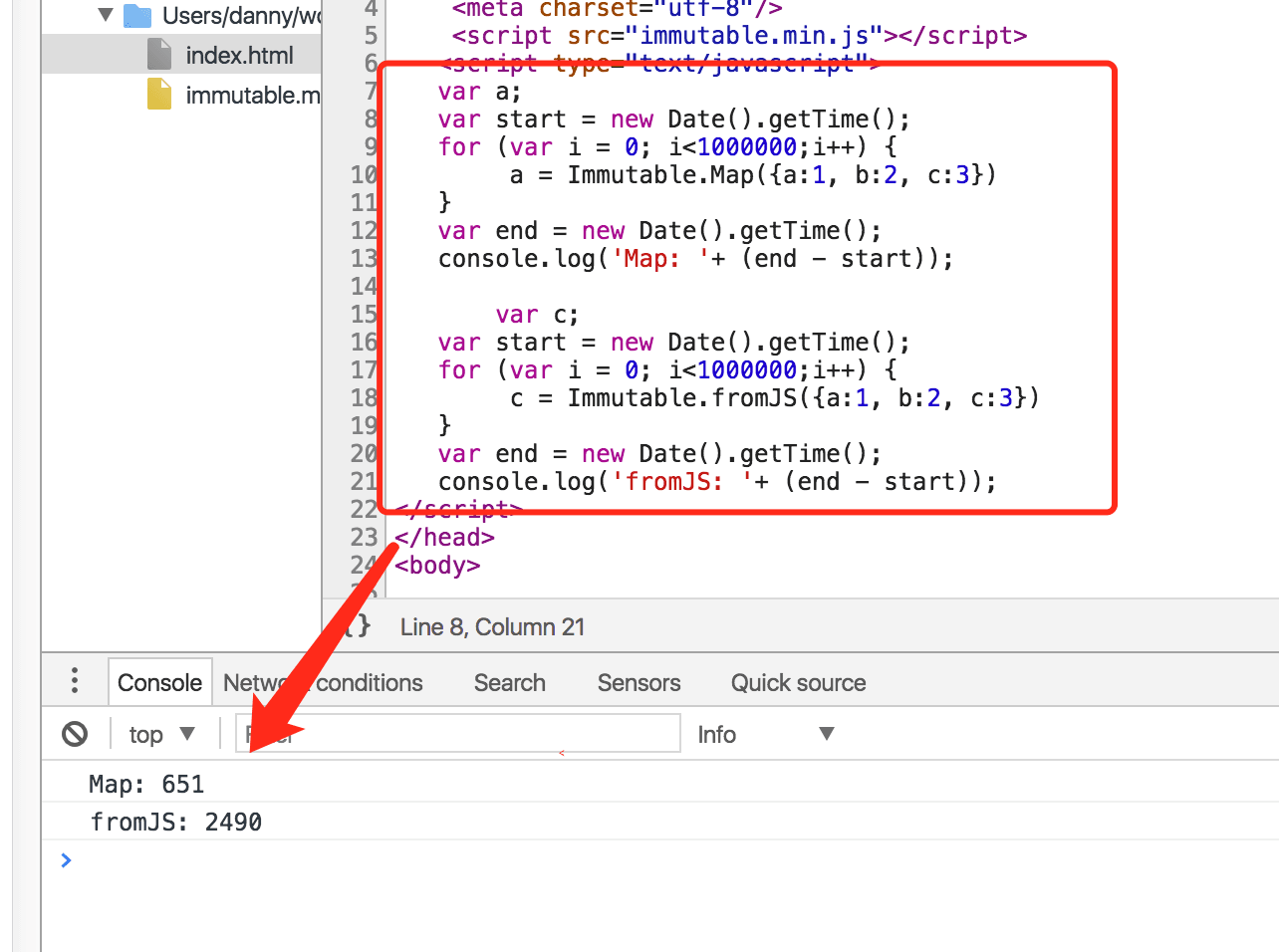
1.fromJS和toJS会深度转换数据,随之带来的开销较大,尽可能避免使用,单层数据转换使用Map()和List()
(做了个简单的fromJS和Map性能对比,同等条件下,分别用两种方法处理1000000条数据,可以看到fromJS开销是Map的4倍)
2.js是弱类型,但Map类型的key必须是string!(看下图官网说明)

3.所有针对immutable变量的增删改必须左边有赋值,因为所有操作都不会改变原来的值,只是生成一个新的变量
//javascript
var arr = [1,2,3,4];
arr.push(5);
console.log(arr) //[1,2,3,4,5]
//immutable
var arr = immutable.fromJS([1,2,3,4])
//错误用法
arr.push(5);
console.log(arr) //[1,2,3,4]
//正确用法
arr = arr.push(5);
console.log(arr) //[1,2,3,4,5]4.引入immutablejs后,不应该再出现对象数组拷贝的代码(如下举例)
//es6对象复制
var state = Object.assign({}, state, {
key: value
});
//array复制
var newArr = [].concat([1,2,3])5. 获取深层深套对象的值时不需要做每一层级的判空
//javascript
var obj = {a:1}
var res = obj.a.b.c //error
//immutable
var immutableData=immutable.fromJS({a:1})
var res = immutableData.getIn(['a', 'b', 'c']) //undefined6.immutable对象直接可以转JSON.stringify(),不需要显式手动调用toJS()转原生
7. 判断对象是否是空可以直接用size
8.调试过程中要看一个immutable变量中真实的值,可以chrome中加断点,在console中使用.toJS()方法来查看
四. 总结
总的来说immutable.js的出现解决了许多原生js的痛点,并且自身对性能方面做了许多的优化处理,而且immuable.js作为和react同期推出的一个产品,完美的契合了react+redux的state流处理,redux的宗旨就是单一数据流,可追溯,这两点恰恰是immutable.js的优势,自然水到渠成,何乐而不为。
当然也不是所有使用react+redux的场景都需要使用immutable.js,建议满足项目足够大,state结构足够复杂的原则,小项目可以手动处理shouldComponentUpdate,不建议使用,得不偿失。
