

本系列文章是对 metalkit.org 上面MetalKit内容的全面翻译和学习.
今天我们关注一下使用GPU时的内存管理.Metal框架将内存资源定义为MTLBuffer对象,它是分配的无类型,无格式的内存(任何数据类型),MTLTexture对象则是分配的格式化内存来保存图片数据.我们在本文中只关注缓冲器.
创建MTLBuffer对象时有三种选项:
- makeBuffer(length:options:) 创建一个
MTLBuffer对象并分配一块新内存. - makeBuffer(bytes:length:options:) 从一片已经存在的区域复制数据到一块新分配的内存.
- makeBuffer(bytesNoCopy:length:options:deallocator:) 重用一块已经存在的内存.
让我们创建一组缓冲器,看看数据是如何被传递到GPU的,及如何回传给CPU.我们首先创建一块缓冲器给输入和输出数据,并给它们初始化一些值:
let count = 1500
var myVector = [Float](repeating: 0, count: count)
var length = count * MemoryLayout< Float >.stride
var outBuffer = device.makeBuffer(bytes: myVector, length: length, options: [])
for (index, value) in myVector.enumerated() { myVector[index] = Float(index) }
var inBuffer = device.makeBuffer(bytes: myVector, length: length, options: [])
新的MemoryLayout< Type >.stride语法在Swift 3被引入,来替代老的strideof(Type)函数.同时,因为内存排列的原因我们用.stride替代了.size.stride是指针增长时移动的字节数.下一步是把我们缓冲器告诉命令编码器:
encoder.setBuffer(inBuffer, offset: 0, at: 0)
encoder.setBuffer(outBuffer, offset: 0, at: 1)
注意: <Metal最佳实践指南>指出当我们的数据小于4KB(例如一个千位的浮点数)时就避免创建缓冲器.在本例中我们应该使用setBytes()函数来代替创建缓冲器.
最后一步是读取GPU通过contents() 函数返回的数据,绑定内存数据到我们的输出缓冲器上:
let result = outBuffer.contents().bindMemory(to: Float.self, capacity: count)
var data = [Float](repeating:0, count: count)
for i in 0 ..< count { data[i] = result[i] }
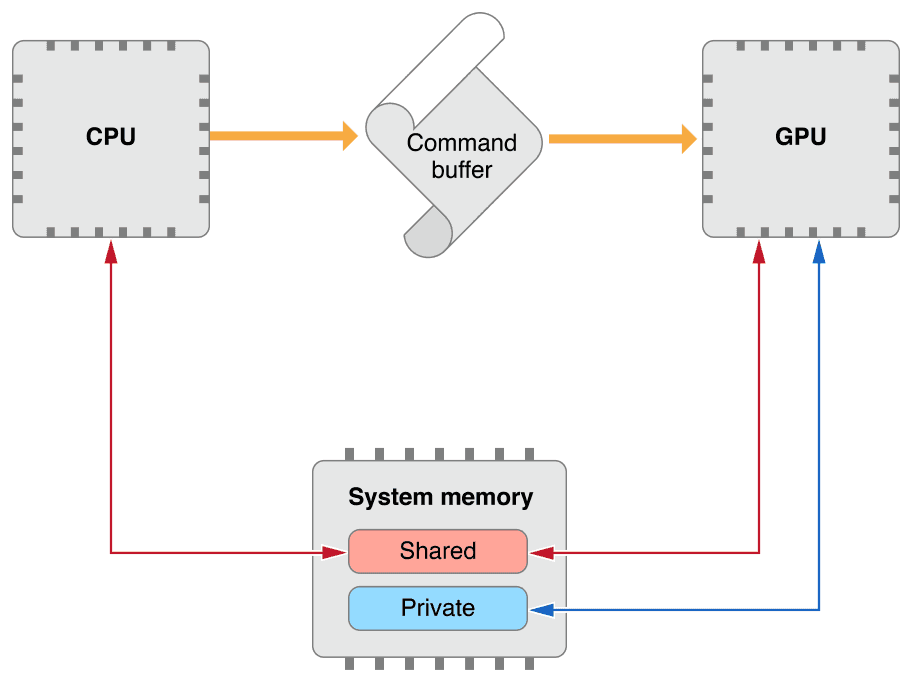
Metal资源必须被配置好,以便快速内存访问和驱动器性能优化.资源的储存模式允许我们定义缓冲器和纹理的储存位置和访问权限.如果你再看一眼上面我们创建缓冲器的地方,我们使用了默认([])的储存模式.
所有的iOS和tvOS设备支持unified memory model统一内存模型,它可以让CPU和GPU共享系统内存,而macOS设备支持discrete memory model离散内存模型即GPU拥有自己的内存.在iOS和tvOS中,Shared模式(MTLStorageModeShared)定义了系统内存可以被CPU和GPU访问,而Private模式(MTLStorageModePrivate)定义系统内存只能被GPU访问.Shared模式是所有三种操作系统中的默认储存模式.
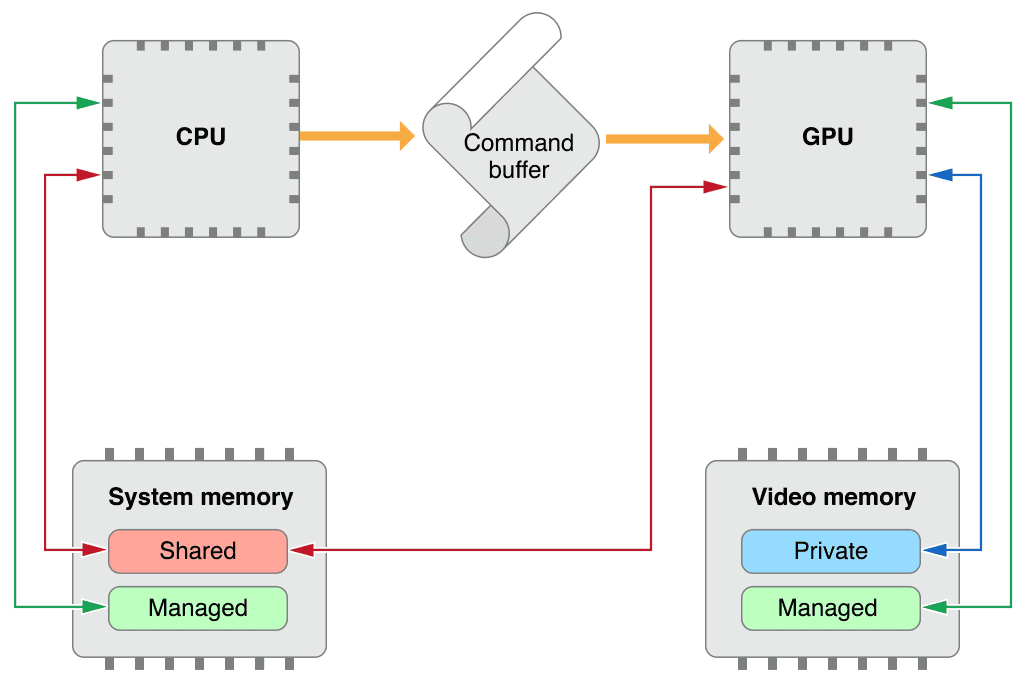
除了这两种储存模式外,macOS还有一种Managed模式(MTLStorageModeManaged),它为一种资源定义了一对同步内存,一个副本在系统内存中,另一个在视频内存中来获得更快的CPU和GPU本地访问.
现在让我们看看当我们将数据缓冲器发送给GPU时,GPU上面发生了什么.下面是个典型的顶点着色器例子:
vertex Vertices vertex_func(const device Vertices *vertices [[buffer(0)]],
constant Uniforms &uniforms [[buffer(1)]],
uint vid [[vertex_id]])
{
...
}
Metal Shading Language实现了地址空间修饰词来指定当函数变量或参数分配时的内存区域:
- device - 指缓冲器内存对象,从设备内存池中分配,既可读又可写除非前面有const关键词就是只读的.
- constant - 指缓冲器内存对象,从设备内存池中分配,但是是
read-only只读的.程序作用域内的变量必须被声明为常量地址空间,并在声明语句中被初始化.常量地址空间为多个实例在执行图形或内核函数时访问缓冲器中的同一块位置的做了优化. - threadgroup - 仅用来分配内核函数中使用的变量,它们是为每个执行内核的线程组分配的,被线程组内的所有线程共享,只在执行内核的线程组的生命周期内才存在.
- thread - 指每个线程的内存地址空间.分配在这个地址空间的变量对其它线程是不可见的.在图形或内核函数中声明的变量是分配在线程地址空间的.
作为奖励,让我们也看一下在Swift 3中另一种访问内存位置的方法.这段代码是从前面的文章The Model I/O framework中摘抄的,所以我们就不再讲解体素的细节了.只要想着我们需要遍历一个数组来获取值:
let url = Bundle.main.url(forResource: "teapot", withExtension: "obj")
let asset = MDLAsset(url: url)
let voxelArray = MDLVoxelArray(asset: asset, divisions: 10, patchRadius: 0)
if let data = voxelArray.voxelIndices() {
data.withUnsafeBytes { (voxels: UnsafePointer<MDLVoxelIndex>) -> Void in
let count = data.count / MemoryLayout<MDLVoxelIndex>.size
let position = voxelArray.spatialLocation(ofIndex: voxels.pointee)
print(position)
}
}
在本例中,MDLVoxelArray对象有了个名为spatialLocation()的函数,它让我们用一个MDLVoxelIndex类型的UnsafePointer指针来遍历数组,并通过每个位置的pointee来访问数据.在本例中,我们只打印出地址中的第一个值,但一个简单的循环可以让我们得到所有的数,像这样:
var voxelIndex = voxels
for _ in 0..<count {
let position = voxelArray.spatialLocation(ofIndex: voxelIndex.pointee)
print(position)
voxelIndex = voxelIndex.successor()
}
源代码source code已发布在Github上.
下次见!
