

本系列文章是对 metalkit.org 上面MetalKit内容的全面翻译和学习.
在深入内存管理时有很多话题需要探讨.上次我们已经了解了创建MTLBuffer对象有三种选项设置:用新数据分配一块新内存,用已存在区域复制数据到一块新内存,重用一块已经存在的分配区不复制数据.因为我们以前并不关注内存,就让我们验证一下证明这确实是真的.首先我们复制数据到另一分配区:
let count = 2000
let length = count * MemoryLayout< Float >.stride
var myVector = [Float](repeating: 0, count: count)
let myBuffer = device.makeBuffer(bytes: myVector, length: length, options: [])
withUnsafePointer(to: &myVector) { print($0) }
print(myBuffer.contents())
注意: withUnsafePointer() 函数提供给我们的实际数据的内存地址在堆上,而不是指向数据的指针(在栈上)的地址.
你的输出看起来会像这样:
0x000000010043e0e0
0x0000000102afd000
注意到上面地址的最后三位数字了吗?这是来自于页对齐数据,因为地址是以0 mod pageSize确定的,因为最后三位是0,因为我们的页尺寸是0x1000.
现在我们接着看Storage Modes,我们上次曾简短提到过.至少需要记住四条主要规则,每种储存模式一条:
| Mode | Description |
|---|---|
| Shared | 在macOS缓冲器,iOS/tvOS资源上为默认;masOS纹理上不可用. |
| Private | 主要用于数据只被GPU访问的情况下 |
| Memoryless | 仅用于iOS/tvOS芯片的临时渲染目标(纹理). |
| Managed | macOS纹理的默认模式;在iOS/tvOS资源上不可用. |
对于一个更好的大图片,下面是完整的作弊表,让你无需记忆上面的规则,更容易使用:
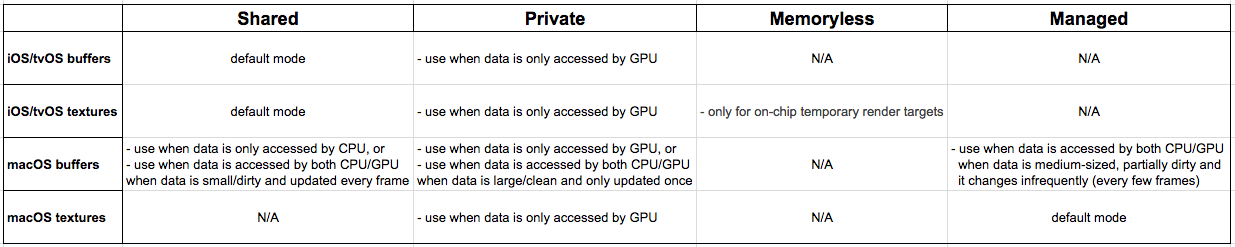
最复杂的情况是,在当masOS处理缓冲器时,数据需要同时被CPU和GPU访问.我们选择储存模式时,是基于下面一个或多个条件为真来决定的:
- Private - 对于最多只改变一次的大尺寸数据,那它就不是"脏"的.创建一个
Shared模式的源缓冲器,然后位块传送它的数据到一个Private模式的目标缓冲器中.在本例中资源一致不是必须的,因为数据只被GPU访问.该操作是花费最低的(一个一次性花费). - Managed - 对于很少改变(每几帧)的中等尺寸数据,它就是部分"脏"的.一个数据副本储存在系统内存中给
CPU使用,另一份储存在GPU内存中.资源一致性通过同步两份副本来严格控制. - Shared - 对于每帧都更新的小尺寸数据,那它就是完全"脏"的.数据存放在系统内存中,并同时对
CPU和GPU可见,可修改.资源一致性只在命令缓冲器界限内被保证.
如何保证资源的一致性?首先,确保所有的来自CPU的修改已经在命令缓冲器被提交(检查命令缓冲器状态属性是否是MTLCommandBufferStatusCommitted)之前完成了.在GPU结束执行命令缓冲器后,CPU只应该在GPU发信号给CPU,告知CPU命令缓冲器结束执行(检查命令缓冲器状态属性是否是MTLCommandBufferStatusCompleted)之后,再开始着手修改.
最后,让我们看看masOS的资源是如何同步完成的.对于缓冲器:在CPU写入后使用didModifyRange() 将修改项通知GPU,这样Metal可以只更新这个数据区域;
在GPU写入后,在一个位块传送操作内,用synchronize(resource:) 来刷新缓存,这样CPU就可以访问更新后的数据.
对于纹理:在CPU写入后,使用两个replace() 区域函数中的一个,将修改项通知GPU,这样Metal可以只更新这个数据区域;在GPU写入后,在一个位块传送操作内,使用两个synchronize() 函数中的一个,来允许Metal在GPU结束修改数据后再更新系统缓存副本.
源代码source code已发布在Github上.
下次见!
