

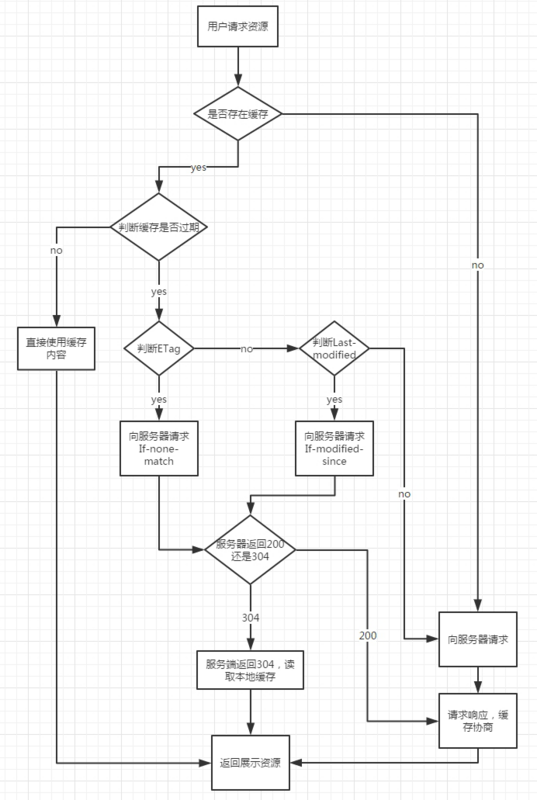
浏览器缓存步骤
1)浏览器在加载资源时,先根据这个资源的一些http header判断它是否命中强缓存,强缓存如果命中,浏览器直接从自己的缓存中读取资源,不会发请求到服务器。比如某个css文件,如果浏览器在加载它所在的网页时,这个css文件的缓存配置命中了强缓存,浏览器就直接从缓存中加载这个css,连请求都不会发送到网页所在服务器;
2)当强缓存没有命中的时候,浏览器一定会发送一个请求到服务器,通过服务器端依据资源的另外一些http header验证这个资源是否命中协商缓存,如果协商缓存命中,服务器会将这个请求返回,但是不会返回这个资源的数据,而是告诉客户端可以直接从缓存中加载这个资源,于是浏览器就又会从自己的缓存中去加载这个资源;
3)强缓存与协商缓存的共同点是:如果命中,都是从客户端缓存中加载资源,而不是从服务器加载资源数据;区别是:强缓存不发请求到服务器,协商缓存会发请求到服务器。
4)当协商缓存也没有命中的时候,浏览器直接从服务器加载资源数据。
实例: 以常见的请求一个CSS样式来说。
第一次请求
通常服务器会传送这4个字段过来, 可能是4个都要,也可能一个字段也没有。这里主要讲解4个字段都存在的情况。
第二次请求
前端:首先,浏览器会检查Cache-Control与Expires,有Cache-Control的情况下,以其为标准,如果超时,则向后端发送请求,请求中会带上 If-Modified-Since,If-None-Match。
后台:后端服务器接收到请求之后,会对这两个字段进行对比,同样以If-None-Match为标准,没有If-None-Match的情况下,比对If-Modified-Since,如果比对后发现文件没有过期,即Etag没有发生变化,或者Last-Modified与If-Modified-Since一致(只存在If-Modified-Since时)。如果改变了,就会发送新的文件,反之,则直接返回304。
浏览器缓存分类
强缓存
客户端第一次问服务器要某个资源时,服务器丢还给客户端所请求的这个资源同时,告诉客户端将这个资源保存在本地,并且在未来的某个时点之前如果还需要这个资源,直接从本地获取就行了,不用向服务器请求。这种方式缓存下来的资源称为强缓存。 强缓存利用http的返回头部的中Expires(实体首部字段)或者Cache-Control(通用首部字段)两个字段来控制的,用来表示资源的缓存时间。服务器通过这两个首部字段告知客户端资源的缓存过期时间和缓存最大生命周期。客户端得知资源的缓存过期时间和最大生命周期后,即可自行判断是否可不建立与服务器的链接,直接从浏览器缓存中获取资源。
命中强缓存时,浏览器同样会受到status=200的response,chrome中可通过size区分从服务器返回的资源还是强缓存获得的资源。
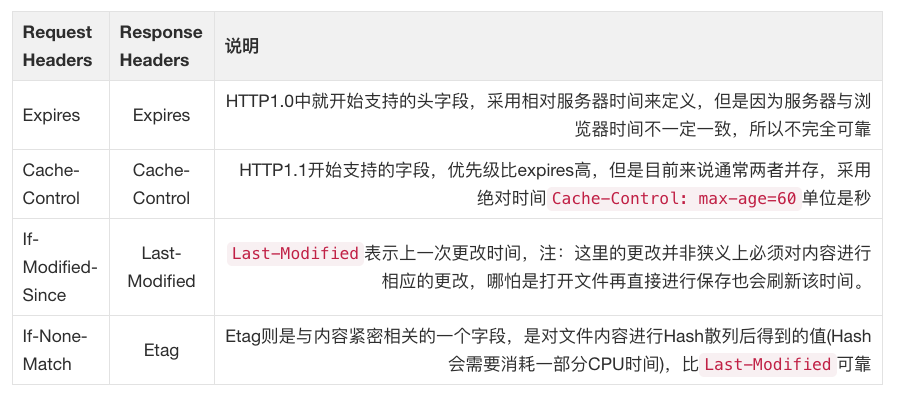
Expires
该字段是http1.0时的规范,值为一个绝对时间的GMT格式的时间字符串,代表缓存资源的过期时间,在这个时点之前,即命中缓存。其过程如下:
浏览器第一次跟服务器请求一个资源时,服务器在返回这个资源时,在相应头部会加上Expires,如图: clipboard.png
浏览器接收到该资源后,会把这个资源连同response header一起缓存下来;
浏览器再次请求这个资源时,会先从缓存中找到这个资源,然后获取Expires时间与当前的请求时间比较,如果Expires时间比当前浏览器的请求时间晚,说明缓存未过期,即命中缓存;
如果当前请求时间比Expires晚,说明缓存过期,即未命中缓存,浏览器就会发送请求到服务器申请获取资源。
缺点:服务器返回的Expires时点是服务器上的时间,可能与客户端有时间差,时间差太大时可能造成缓存混乱。
Cache-Control:max-age
Cache-Control有很多属性,不同的属性代表的意义也不同。
private:客户端可以缓存
public:客户端和代理服务器都可以缓存
max-age=t:缓存内容将在t秒后失效
no-cache:需要使用协商缓存来验证缓存数据
no-store:所有内容都不会缓存。
该字段是http1.1的规范,强缓存利用其max-age值来判断缓存资源的最大生命周期,它的值单位为秒,Cache-Control : max-age=3600代表缓存资源有效时间为1小时,即从第一次获取该资源起一小时内的请求都被认为可命中强缓存。其过程如下:
浏览器第一次跟服务器请求一个资源时,服务器在返回这个资源时,在相应头部会加上Cache-Control:max-age=XXXXXXXX,如图: clipboard.png
浏览器接收到资源后,连同response header一起缓存下来;
浏览器再次跟服务器请求同一个资源时,会先从缓存中找到这个资源,获取date(第一次资源返回的响应时间)和max-age并计算出一个有效期(date + max-age),然后再和浏览器请求时间比较最后判断是否命中缓存(逻辑同Expires);
如果没有命中缓存,浏览器直接从服务器请求资源,Cache-Control会在重新获取到服务器返回资源时更新。
Cache-Control描述的是相对时间,采用本地时间来计算资源的有效期,所以相比Expires更可靠。
这两个Header可以只用其一,也可以一起使用。一起使用时以Cache-Control为准。
协商缓存
客户端第一次问服务器要某个资源时,服务器丢还给客户端所请求的这个资源同时,将该资源的一些信息(文件摘要、或者最后修改时间)也返回给客户端,告诉客户端将这个资源缓存在本地。当客户端下一次需要这个资源时,将请求以及相关信息(文件摘要、或者最后修改时间)一并发送给服务器,由服务器来判断客户端缓存的资源是否需要更新:如不需要更新,就直接告诉客户端获取本地缓存资源;如需要更新,则将最新的资源连同相应的信息一并返回给客户端。 当强缓存未命中时,浏览器就会发送请求到服务器,服务器会验证协商缓存是否命中,如果协商缓存命中,请求返回的http状态为304,并会显示说明Not Modified,浏览器收到该返回后,就会从缓存中加载了。
协商缓存利用[Last-Modified , If-Modified-Since] 和 [ETag , If-None-Match]这两对Header来管理。
Last-Modified & If-Modified-Since
Last-Modified为实体首部字段,值为资源最后更新时间,随服务器response返回。
If-Modified-Since为请求首部字段,通过比较两个时间来判断资源在两次请求期间是否有过修改,如果没有修改,则命中协商缓存,浏览器从缓存中获取资源;如果有过修改,则服务器返回资源,同时返回新的Last-Modified时间。其过程如下:
-
浏览器第一次请求服务器资源,且服务器返回了该资源时,会在response headers中加上Last-Modified,这个header表示这个资源在服务器上的最后一次修改时间;
-
当浏览器再次请求该资源时,会在request headers中加上If-Modified-Since,这个值即为上一次服务器返回的Last-Modified时间;
-
服务器再次收到资源请求时,将If-Modified-Since时间和资源在服务器上的最后修改时间与对比,如果If-Modifid-Since与最后修改时间一致,则命中缓存,服务器返回304,浏览器从缓存中获取资源;若未命中缓存,服务器返回资源同时,浏览器缓存资源的Last-Modified会被更新。
ETag & If-None-Match
有些情况下仅判断最后修改日期来验证资源是否有改动是不够的:
存在周期性重写某些资源,但资源实际包含的内容并无变化;
被修改的信息并不重要,如注释等;
Last-Modified无法精确到毫秒,但有些资源更新频率有时会小于一秒。
为解决这些问题,http允许用户对资源打上标签(ETag)来区分两个相同路径获取的资源内容是否一致。通常会采用MD5等密码散列函数对资源编码得到标签(强验证器);或者通过版本号等方式,如W/”v1.0”(W/表示弱验证器)。
ETag为相应头部字段,表示资源内容的唯一标识,随服务器response返回;
If-None-Match为请求头部字段,服务器通过比较请求头部的If-None-Match与当前资源的ETag是否一致来判断资源是否在两次请求之间有过修改,如果没有修改,则命中协商缓存,浏览器从缓存中获取资源;如果有过修改,则服务器返回资源,同时返回新的ETag。其过程如下:
-
服务器第一次收到浏览器发出的资源请求时,会在response headers中加上ETag,这个ETag是根据该资源生成的唯一标识,这个唯一标识是个字符串,只要服务器认为资源有变化且应该提供新的资源,则ETag就必须有变化。浏览器将资源连同ETag一并缓存。
-
当浏览器再一次向服务器发送该资源的请求时,会在request headers中加上If-None-Match,该值即为第一次服务器返回的ETag值;
-
服务器收到资源请求后,会根据要请求的资源重新计算生成相应的ETag,然后与If-None-Match比较。对比结果一致即命中缓存,不一致则未命中缓存,返回资源同时将新的ETag发送至浏览器。
协商缓存管理 [Last-Modified , If-Modified-Since]和[ETag , If-None-Match]一般同时启用,这是为了处理Last-Modified不可靠的情况。
前端部署方案
之前大家可能都知道 一般的公司对于静态资源以及缓存的处理方式无非就这么几种。 1 在静态资源后面加一个版本号 v=1.111

2 为了准确的确定文件是否修改,将后面的版本号修改为文件摘要(主要根据文件内容生成的一个值)。

3 直接将资源文件名使用文件摘要或者说某个固定的字符串加上一个文件摘要拼接成一个文件名。

(彩蛋:有意思的,找了几个TX的网站,发现其实并不是所有的网站都采用了最后一种方式。我想应该技术都是用来追求完美的,但实现还是人实现的,毕竟人的天性是喜欢偷懒的。)
那么问题来了? 以上三种方式的区别是什么?为什么最后会最终演变为第三种方式?
1 第一种方式,需要维护版本号,如果在一个文件中,存在多个资源,那么没有被修改过的资源文件也会被修改版本号,导致不必要的资源加载。(当然,如果需要加上时间戳之类的,就已经不属于第一个的范围了)
2 第二种方式,可以精确的发现哪一个文件被修改过。从而要求客户端进行重新加载。但是同样会存在一些问题。 一般能做到第二种方式的公司,网页流量自然可以想像(小公司请自动忽略)。 那么当在发布版本的时候,会存在两个类型的文件需要发布: 1) html文件,上面有资源文件的引用 2 )资源文件
那么发布以上两个文件的顺序就成问题了。
如果先发 html文件: 那么会导致重新加载资源,但一样还是无法访问到最新的特性。(毕竟资源文件还没有真正的更新。),如是Html页面的结构有更新,但加载了旧的资源,很有可能导致页面结构的错乱。并且会缓存资源,直到资源过期,否则除非强制刷新,会一直是错误页面。(这里要注意到,由于第一次加载了旧的资源,版本号又是新的版本号,所以即使在这之后上了资源,这里依旧会读取旧的资源.)
如果先发资源文件: 如果之前访问过页面,那就会有保存有本地缓存,那么由于访问的还是缓存文件,不会出现问题。但如果是新用户,那么就会访问到新的资源文件,很有可能导致页面错乱。而等到页面html也发布之后,页面又恢复了正常。
PS: 当然有的人可能会说,发布就那么一会的时间,有必要那么在乎这些一点点时间么? 如果你这么想,那么我只能说,我无话可说。
发上两种都是属于覆盖式资源发布,不管如何处理,都会存在这样的问题。那么解决方案就是第三种。非覆盖式发布。
3 第三种方式,应该是最完美的解决方案: 1 首先发资源文件,由于文件名已经不一样了,所以不会覆盖掉之前存在的资源文件,客户端依旧可以安全的访问。 2 再发客户端文件,在客户端文件一旦发布成功,那么就会立马切成新的特性,中间可以做到无缝衔接。 这就是所谓的非覆盖发布的方案。
