

作者简介
张振华,携程旅行网机票研发部资深软件工程师,目前主要负责携程机票大数据基础平台的建设、运维、迭代,以及基于此的实时和非实时应用解决方案研发。
携程机票实时数据种类繁多,体量可观,主要包括携程机票用户访问、搜索、下单等行为日志数据;各种服务调用与被调用产生的请求响应数据;机票服务从外部系统(如GDS)获取的机票产品及实时状态数据等等。这些实时数据可以精确反映用户与系统交互时每个服务模块的状态,完整刻画用户浏览操作轨迹,对生产问题排查、异常侦测、用户行为分析等方面至关重要。
回到数据本身,当我们处理数据的时候,往往会遇到两类数据,一类是已经存在的有界(bounded)数据(比如hdfs的某个数据文件),一类是持续不断生成的无界(unbounded)数据(如某个活跃的Kafka topic),对应着这两类数据的处理也被分为批处理(batch processing)和流式处理(stream processing)。
批处理针对有界数据,处理完所有数据后释放计算资源;而流式处理则需要持续地处理不断产生的数据。随着大数据社区的发展,各类优秀成熟的计算框架不断涌现。众所周知,当前比较成熟的批处理计算框架主要包括Hadoop、Spark等,实时处理计算框架主要包括Storm、Spark Streaming、Flink等。
从大数据技术发展历史来看,海量历史数据的处理需求提出要早于实时流式数据,因此批处理计算框架出现和趋于成熟得更早。然而,互联网时代的来临,高吞吐的实时数据处理也成了在线平台的刚需,这也极大促进了实时计算框架的发展。
一、流数据处理框架

流数据处理框架按照其实现的方式,也可以分为逐条处理和微批量(micro-batching)处理两种(如图1所示),Storm和Flink属于前者,Spark Streaming属于后者。
 图1 实时处理实现两种方式
图1 实时处理实现两种方式
介绍三个计算框架特性的文章很多,本文不再过多赘述。
在Storm里,通过定义Spout数据来源和后续一系列的Bolt处理流程组成完整拓扑Topology,从而实现整套处理逻辑。利用Topology定义的Storm流程是无状态的,无法实现exactly once处理容错语义,如果应用场景中需求严格的一次处理,如统计一个小时内IOS用户的PV,可以用Storm Trident API,确保每条消息只会被处理一次。
Flink和Spark则既可以支持批处理,也可以支持流处理,但两者对数据处理的设计似乎正好相反,Flink会把所有数据处理当成流数据来处理,即使处理静态的有界数据;Spark则将所有数据处理转化为批处理,即使在处理流式数据,也会将流数据切分成微批来进行计算。Flink这种流处理优先的方式叫做Kappa架构,而Spark这种批处理优先的方式被称作为Lambda架构。
在大多数公开的性能测试报告中,Flink吞吐、延时方面的性能指标最优,Spark Streaming受限于micro-batching处理的机制,时延方面最好只能达到秒级,无法满足严苛的实时需求,Storm的时延能达到亚秒,但吞吐指标稍显不足。在数据处理一致性方面,Flink通过state snapshot优雅地实现了exactly once保证,Spark streaming则利用WAL(Write Ahead Log)和RDD本身特性保证了exactly once,storm由于其容错采用的ack机制只能保证at least once,而其Trident则采用封装tuple到batch的方式,并保存元数据和中间状态,从而实现了exactly once的语义。
那么如何选择合适的流处理框架呢?主要看应用场景,如果应用需要亚秒级的时延,Storm和Flink是不错的选择,特别是Flink;如果对时延的要求不是特别高,可以选择Spark Streaming,毕竟Spark目前社区的活跃度、产品成熟度、生态圈丰富度、SQL支持这块都优于其余两者。
二、Kafka
在实时计算的很多场景中,消息队列扮演着绝对重要的角色,是解耦生产和BI、复用生产数据的解决方案。Kafka作为消息队列中最流行的代表之一,在各大互联网企业、数据巨头公司广泛使用。
Kafka出身LinkedIn,是一个分布式的发布/订阅系统。集群由多个Broker节点组成,通过Zookeeper维护元数据信息、选举Partition的Leader、记录消费端状态。在Broker节点上,每个Topic的Partition对应着一个文件系统目录,并以topic_name-partition_index命名,最终数据会被写入到Partition对应的目录,并以index文件和segment文件成对出现的方式存储。众所周知,即使数据写入到普通的SATA硬盘上,Kafka依然具有非常高的吞吐性能。究其本质,还是因为Kafka的顺序读写、系统级的PageCache利用,绕过用户态buffer数据拷贝的sendfile优化。
Kafka作为生产环境和数据分析环境的数据枢纽环节,其稳定性至关重要。表1为一个可以作为生产环境Kafka的配置。
|
操作系统 |
CentOS 7.1 |
|
Open files |
100000 |
|
文件系统 |
Ext4 |
|
JVM |
1.8 |
|
GC |
G1 |
|
Broker节点配置 |
12核/48G内存/4*4T硬盘/万兆网卡 |
|
JVM堆大小 |
4G |
|
Zookeeper节点配置 |
12核/48G内存/2*4T硬盘 |
表 1 生产环境推荐Kafka配置
携程机票从2015年开始使用Kafka,发生过多次大小故障,踩过的坑也不少,下面罗列些琐碎的经验。
1、Partition的默认数目设置成与Broker节点数一致,这样在默认配置的情况下,不至于因为某些体量超大的Topic造成Broker节点硬盘负载和网络负载倾斜
2、做手工维护强制让某些体量大的Topic瘦身时(如retention.ms和retention.bytes变小),要注意节奏,尽量不要同时修改多个,造成集群IO尖刺
3、某些写入端确实需要写入大报文数据并且超过默认设置(1MB)时,需要在Topic配置中增大max.message.bytes,并且在写入端Producer侧增大max.request.size
4、Producer默认开启压缩,compression.codec=gzip/snappy,这样可以有效降低副本同步的网络IO开销,当然同样会带来消费解压引起的集群CPU开销
5、扩容新节点需要超过一台,并且应该尽快将已有Topic的Partition数目调整与扩容后节点数目一致
6、可以考虑独立出一个SOA写入服务供生产环境各服务使用,一方面减少生产环境对大数据组件的依赖,一方面可以让后续的版本升级,集群迁移等操作对调用端透明
7、启动Kafka进程时打开JMX参数,在KafkaManager里可以轻松观察各个节点的写入qps
8、定期清理dead Consumer,为zookeeper减负
9、设置 auto.leader.rebalance.enable=true,让partitionLeader的分布更均衡
10、num.io.threads配置成min(2*disk_num , cpu_core+1),以达到较高的IO处理速率
三、携程机票实时数据处理架构实践及应用
携程机票实时数据主要来源于用户与机票系统交互产生的业务数据流和日志流,业务数据最终会被写入关系型数据库SQLServer和MySQL中,日志数据则通过SOA服务写入消息队列Kafka中,目前机票BI实时应用使用的数据源主要来自于Kafka的日志消息数据。
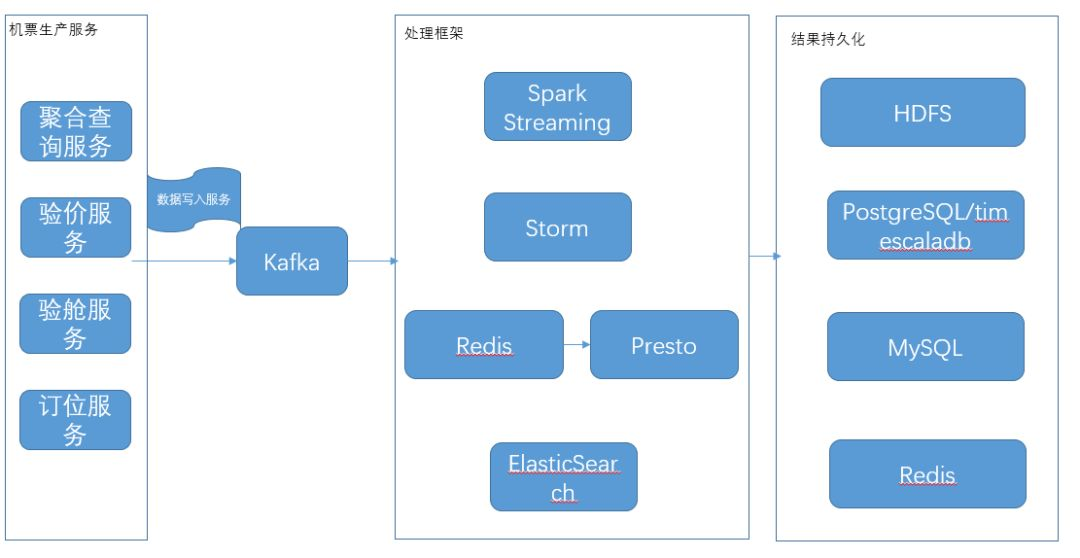
图2 携程机票实时数据处理架构
图2为携程机票当前采用的实时数据处理技术栈。在实时处理框架选择上,我们采用了Storm和Spark Streaming,主要针对不同时延需求的业务场景。没有采用Flink,一方面由于公司暂时没有部署计划,另一方面没有高迭代并且对时延要求很高的应用场景。
Spark Streaming目前主要用来实时解析机票查询日志,用户搜索呈现在机票App/Online界面上的航班价格列表在查询服务返回时其实是一个经过序列化压缩的报文,我们将Kafka Direct Stream接收到数据流DStream,并经过计算处理,将大报文解析成航班价格列表,并存储至Hive,进而支持机票价格监控、舱位实时分析、价格实时优劣势展现、各引擎优劣势实时分析等多个应用,每天解析出来的航班价格数据量大约60亿。另外Spark Streaming也被用来支持ABT实验的指标统计,从而近实时获悉新版接入流量后的表现。
Storm主要用来实时识别舱位虚占,从下单服务推送到Kafka的明细下单日志,经过过滤、提取相应字段后,进行统计和虚占识别规则匹配,从而实时标记虚占用户,并将虚占识别结果写入redis供下单服务使用。
除了经典的Spark Streaming和Storm流计算框架外,为了支持机票数据监控系统灵活动态配置取数SQL的需求,我们采用了Redis+Presto这种方案,以分钟粒度的时间戳为key,将kafka对应该时间戳的数据以Json列表的格式跟key作关联,并利用Presto Redis Connector通过SQL的方式聚合计算该key对应列表数据,并将聚合结果写入DB供监控系统前端调用,实时监控机票各项指标。
我们利用Logstash将Kafka内的各服务日志topic实时ETL至ElasticSearch,并利用实时更新的二级索引(存储于redis,记录唯一标识与ElasticSearchindex的对应关系)和并发查询支持唯一标识所有相关日志数据的串联,在展示界面里完整回溯用户在携程系统里的行为。
另外,相关前端埋点数据和后台访问日志被实时同步至timescaledb的超表中,通过灵活可配的SQL执行对应的反爬识别规则,并适用机器学习模型将爬虫IP尽快甄别出来,进而实施反爬策略。
四、总结
随着大数据开源社区的蓬勃发展,越来越多的计算框架涌现并趋于成熟,应用框架各自有各自的特性,只有最适合自身应用项目的框架才是最好的选择。当然,随时关注社区发展,调研了解新技术的特点也是非常有必要的。
参考
-
Kafka官方文档
-
Flink官方文档
-
Storm官方文档
-
三种流框架的对比分析
https://bigdata.163yun.com/product/article/5
-
大数据处理引擎Spark与Flink大比拼https://www.douban.com/group/topic/95561683/
【推荐阅读】

