

Session 229: Using Collections Effectively
所有应用都用到了集合,为了获得最佳性能,了解背后的基础知识,关于如果更好的使用索引、切片、惰性、桥接以及引用类型,本 Session 讲了些 Tips。
集合简介
Swift 中集合类型很多,如:

所有集合类型都有很多共有特性(Common Features),在 Swift 中,它们都遵守 Protocol Collection 协议,官方文档有这样一段话:
If you create a custom sequence that can provide repeated access to its elements, make sure that its type conforms to the
Collectionprotocol in order to give a more useful and more efficient interface for sequence and collection operations. To addCollectionconformance to your type, you must declare at least the following requirements: - ThestartIndexandendIndexproperties - A subscript that provides at least read-only access to your type's elements - Theindex(after:)method for advancing an index into your collection
文档翻译过来就是至少要实现如下协议接口:

基于 Collection 协议类型,我们可以自定义集合并遵守此类协议,并且还可以做一些协议扩展,Swift 标准库还额外提供了四种集合协议类型:
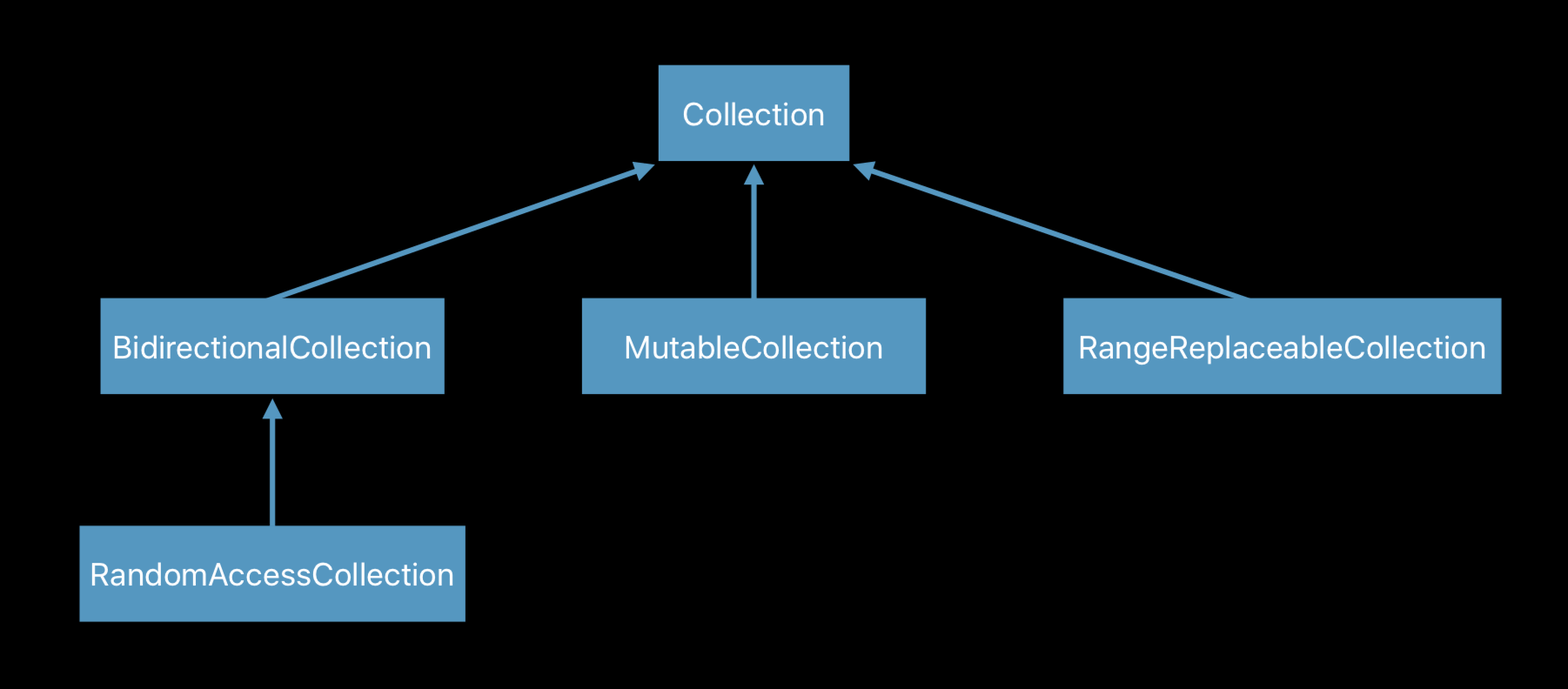
-
双向索引集合:BidirectionalCollection,支持向后并且能够向前遍历的集合
-
随机访问集合:RandomAccessCollection,提供高效的存储方式,跳转到任意索引的时间复杂度为O(1)。
-
可变集合:MutableCollection,支持下标访问修改元素。
-
区间可替换集合:RangeReplaceableCollection,支持通过索引范围替换集合中的元素。
以上四种协议类型本文不做详述。
索引
索引,即在集合中的位置。每种集合类型都定义了自己的索引,并且索引都必须遵守 Comparable 协议。
-
如何取数组中的第一个元素?
- array[0] ?
- array[array.startIndex] ?
- array.first ?
显然第三种方式更加安全,防止潜在的 Crash。
-
如何获取集合中的第二个元素?
-
方式一
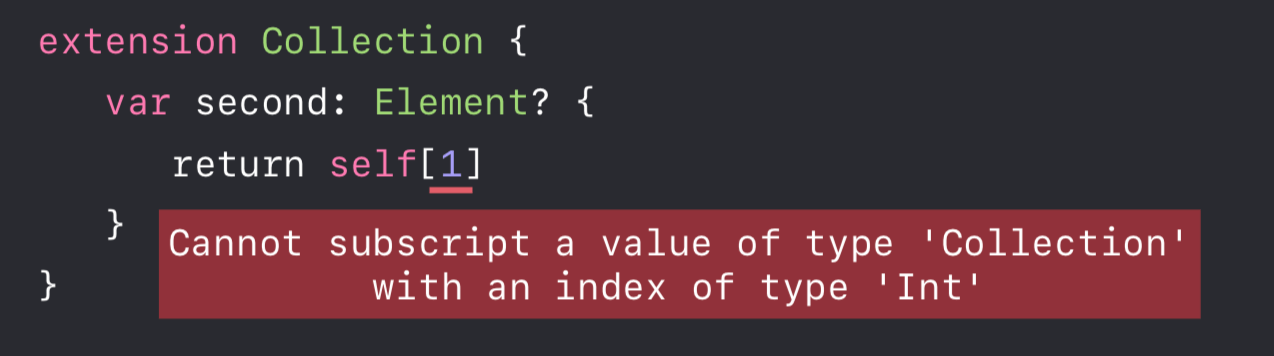
-
方式二
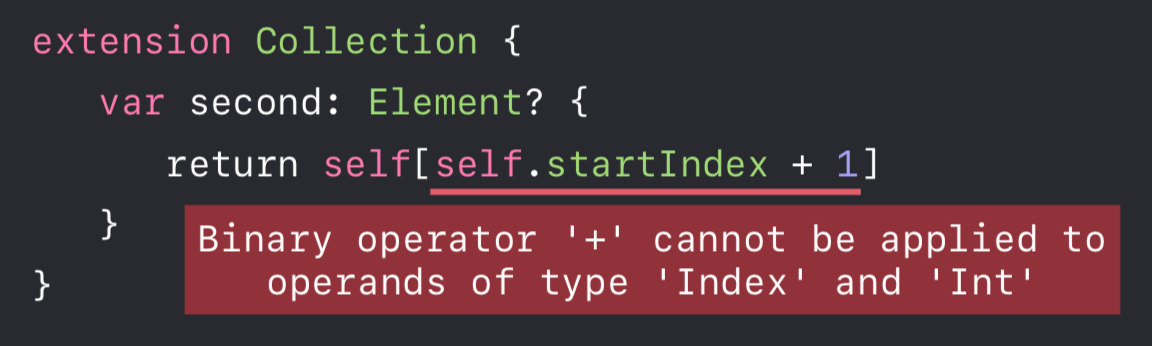
-
方式三
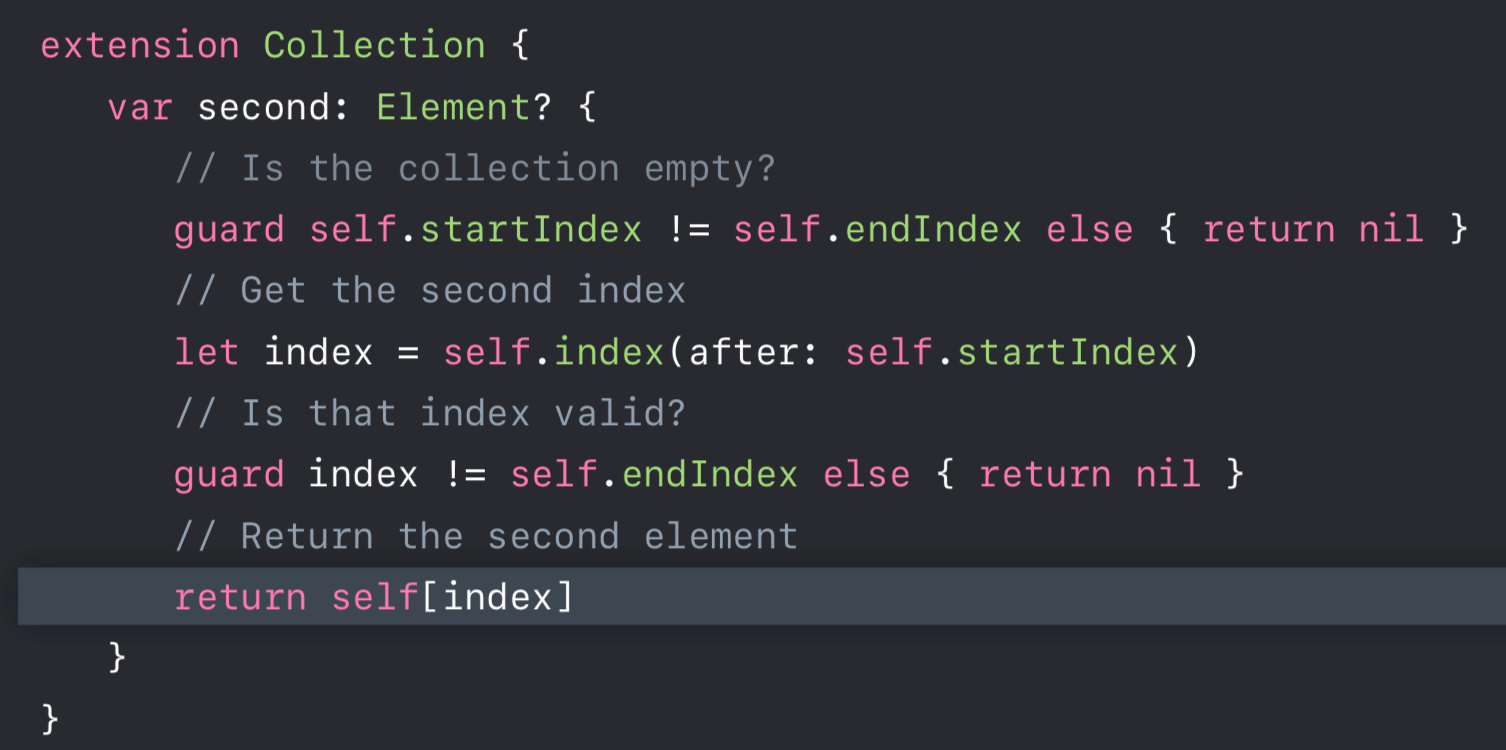
-
针对第二个问题,前两种方式似乎行不通,因为 Index 类型不一定是 Int 类型,那么就只有方式三了, 我们有没有更好的方式来解决呢?当然有,下面笔者先简单介绍下切片(Slice)。
切片
相信大家看到 Slice 这个单词都很熟悉,如:使用数组时,经常会出现 ArraySlice 这种类型。切片其实也是一种类型,基于集合类型的一种封装,通俗点讲,切片就是集合某一部分。
这里有两个关键点:
- 切片与原始集合共享索引。
- 切片会持有集合该块内存。
什么意思呢?Show the code.
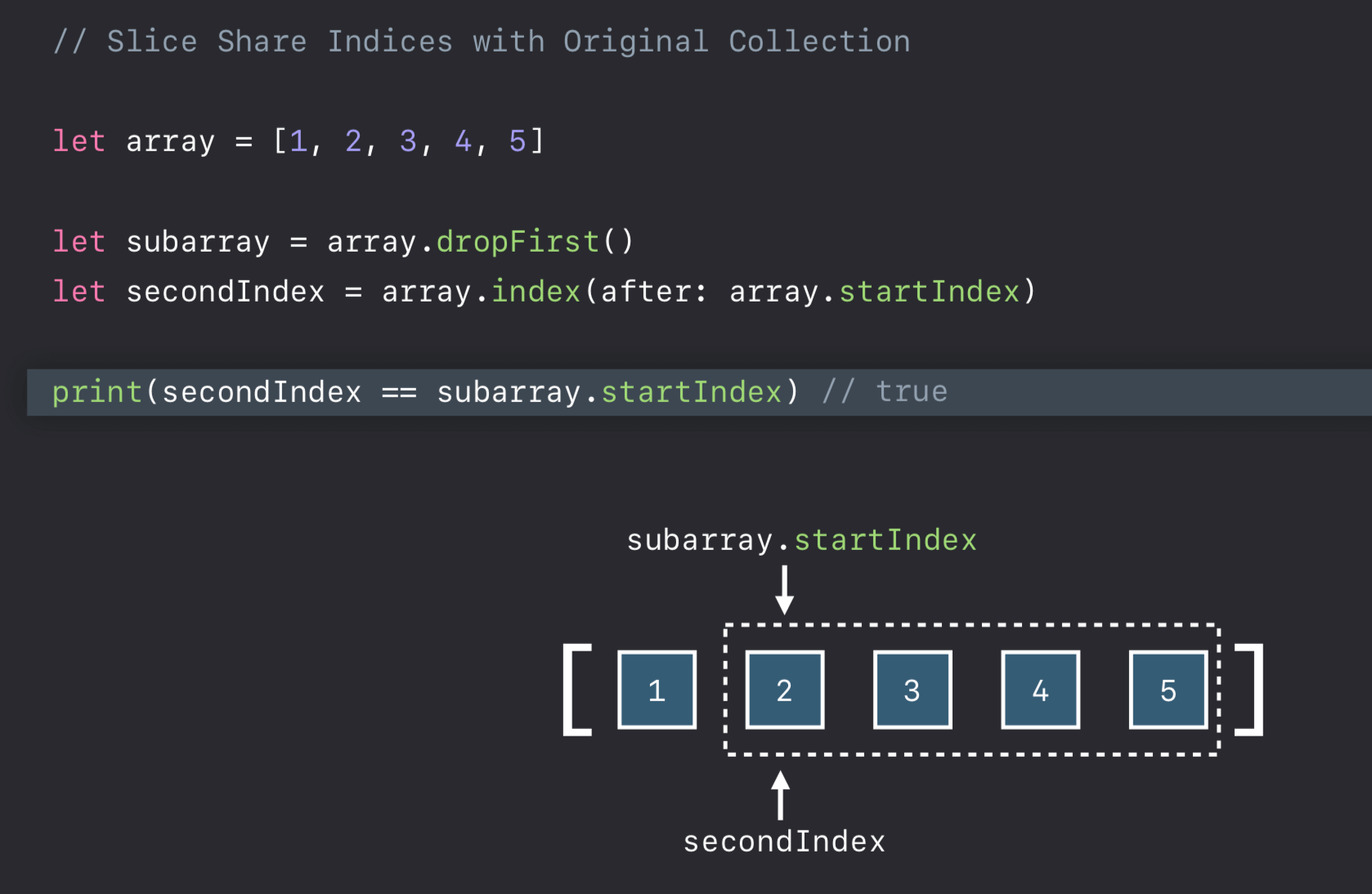
从上图中,我们可以看出 subarray 的 startIndex 等于 array 的 secondIndex。因此针对上述提出的问题如何获取集合中的第二个元素?,更好的处理方式是这样,因为切片与原始集合共享索引:
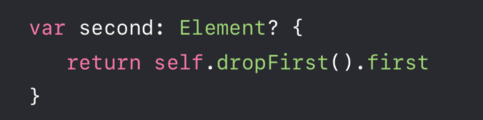
关于切片会“持有”集合该内存块如何理解呢?我们来看看代码:

什么意思呢?当 array = [] 时,集合并没有从内存中销毁,当 firstHalf = [] 时,集合才正真被销毁。官方的这个 CASE,读者可能不怎么好理解,笔者再简单举个例子:
class Person {
var name: String
init(name: String) {
self.name = name
}
deinit {
print("\(#function)###\(name)")
}
}
var persons = [Person(name: "jack"), Person(name: "tom"), Person(name: "john"), Person(name: "tingxins")]
print("集合准备置空处理")
var personsSlices = persons.dropLast(2)
persons = []
print("集合已置空处理")
print("Slice 准备置空处理")
let personsCopy = Array(personsSlices) // 拷贝一份
personsSlices = []
print("Slice 已置空处理")
/** 控制台输出如下
集合准备置空处理
集合已置空处理
Slice 准备置空处理
deinit###john
deinit###tingxins
Slice 已置空处理
deinit###jack
deinit###tom
**/
即,当 persons 和 personsSlices 都被置空时,Person 实例对象才会被释放,如果针对切片进行了一次拷贝(personsCopy),那么被拷贝的这些元素不会被释放。
延迟计算
延迟计算(Lazy Defers Computation),与之相对应的是及早计算(Eager Computation),我们通常调用的函数,都是属于及早计算(立刻求值)。
我们来看段代码:
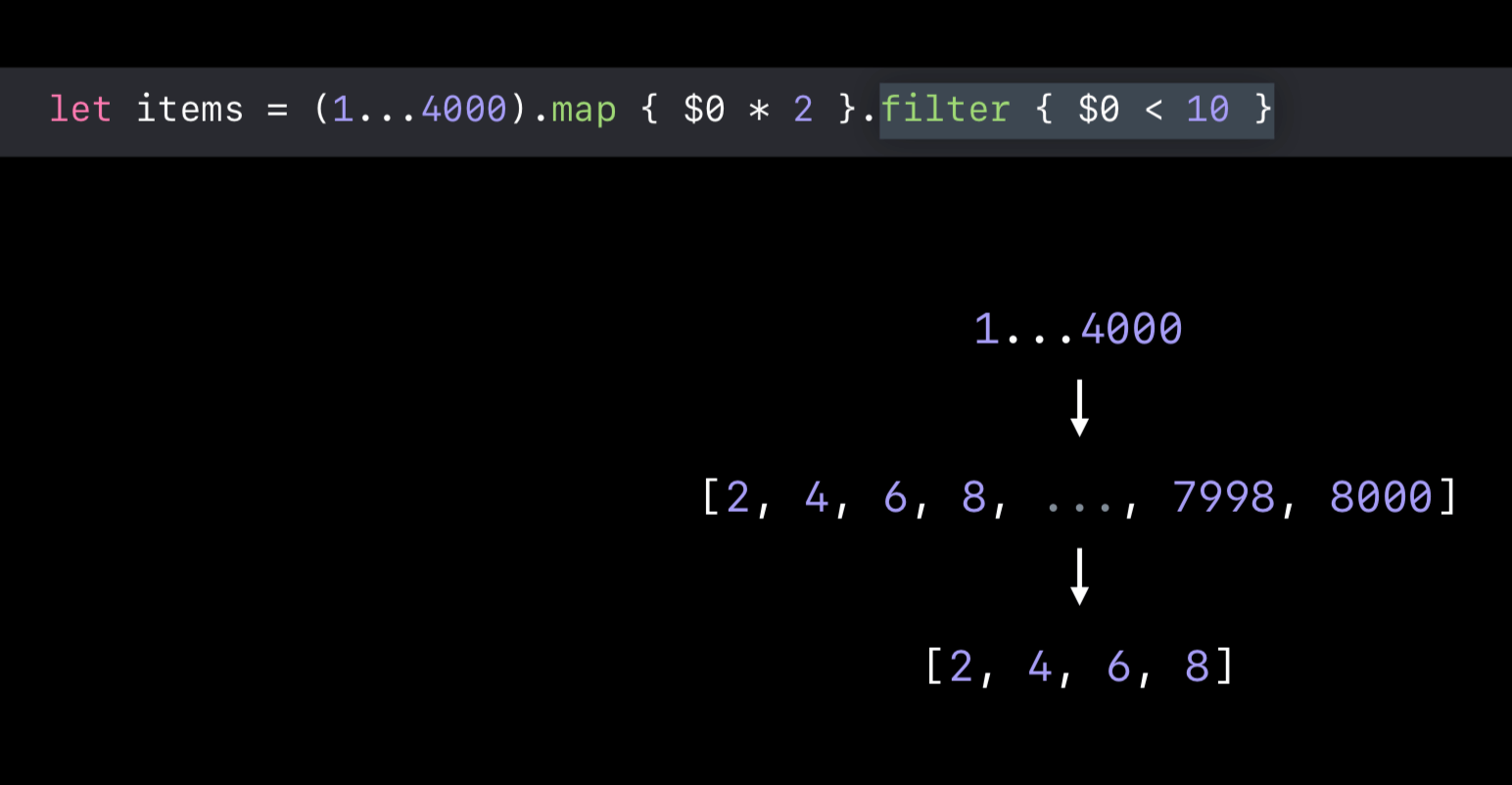
这段代码的性能怎样呢?我们可以看出 map & filter 函数分别会对集合做了遍历一次,并且中途多创建了一个数组(因为 map 是立刻求值函数),如果 map 了多次,那么当数据量非常大的情况下,是可能出现问题的(比如:内存峰值等)。 如:
map {
}.map {
}.flatmap {
}. .......
如果我们仅仅是为了取最后的求值结果,我们是不是可以做些优化呢?
以下面这两个 CASE 为例:
- 取 items 的第一个元素,即 items.first。
- 取 items 中所有元素
由于我们仅仅只需要最后的求值结果甚至结果的某一部分,那么我们可以使用惰性(Lazy)延迟计算来做些优化,使用起来非常简单,在链式调用前加个 Lazy 就 OK 了。

使用 Lazy 后有什么区别呢?我们可以统计 map & filter 函数的 block 的回调次数。
- 取 items.first,map & filter 函数的 block 分别只会调用一次。
- 取 items 集合中所有元素时, map & filter 函数对集合只做了一次遍历
使用 Lazy 的好处主要有两个:
- 我们可以规避中途产生的临时数组,从而在数据量大的情况下,避免内存峰值。
- 只有在访问 items 的元素时,才会进行求值,即延迟求值。
下面我们来举个例子:
// 过滤的最终结果:["2", "4", "6"]
let formats = [1, 2, 3, 4, 5, 6].lazy.filter { (value) -> Bool in
print("filter: \(value)")
return value % 2 == 0
}.map { (value) -> String in
print("map: \(value)")
return "\(value)"
}
// 取结果集的第一个元素 "2"
print(formats[formats.startIndex])
print("####")
// 取结果集的第二个元素 "4"
print(formats[formats.index(after: formats.startIndex)])
print("####")
// 取结果集的第三个元素 "6"
print(formats[formats.index(after: formats.index(after: formats.startIndex))])
print("####")
// 取结果集中元素的个数
print("formats.count \(formats.count)")
/** 控制台输出如下
filter: 1
filter: 2
map: 2
2
####
filter: 1
filter: 2
filter: 3
filter: 4
map: 4
4
####
filter: 1
filter: 2
filter: 3
filter: 4
filter: 5
filter: 6
map: 6
6
####
filter: 1
filter: 2
filter: 3
filter: 4
filter: 5
filter: 6
formats.count 3
**/
读者如果感兴趣可以把 Lazy 去掉后运行下代码,看下输出结果就明白了。
当然,在使用 Lazy 时,也要注意:
- 每次访问 items 中的元素时,都会重新进行求值
如果想解决重新求值的问题,我们可以直接把 Lazy 类型的集合转成普通类型的集合:
let formatsCopy = Array(formats)
但笔者不推荐,这样做使 Lazy 事与愿违。
什么情况下惰性计算呢
- 链式计算
- 仅仅需要求值结果中的某一部分
- 本身的计算不影响外部(no side effects) ......
如何避免集合相关崩溃?
可变性
- 索引失效
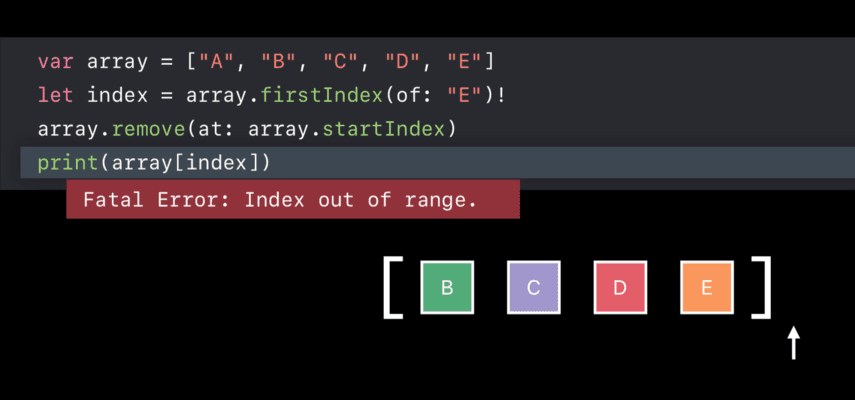
正确的做法应该是这样,使用前更新索引:
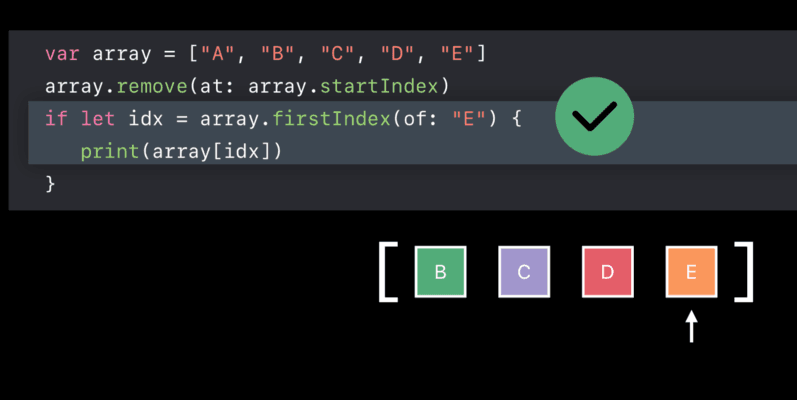
- 复用之前的索引
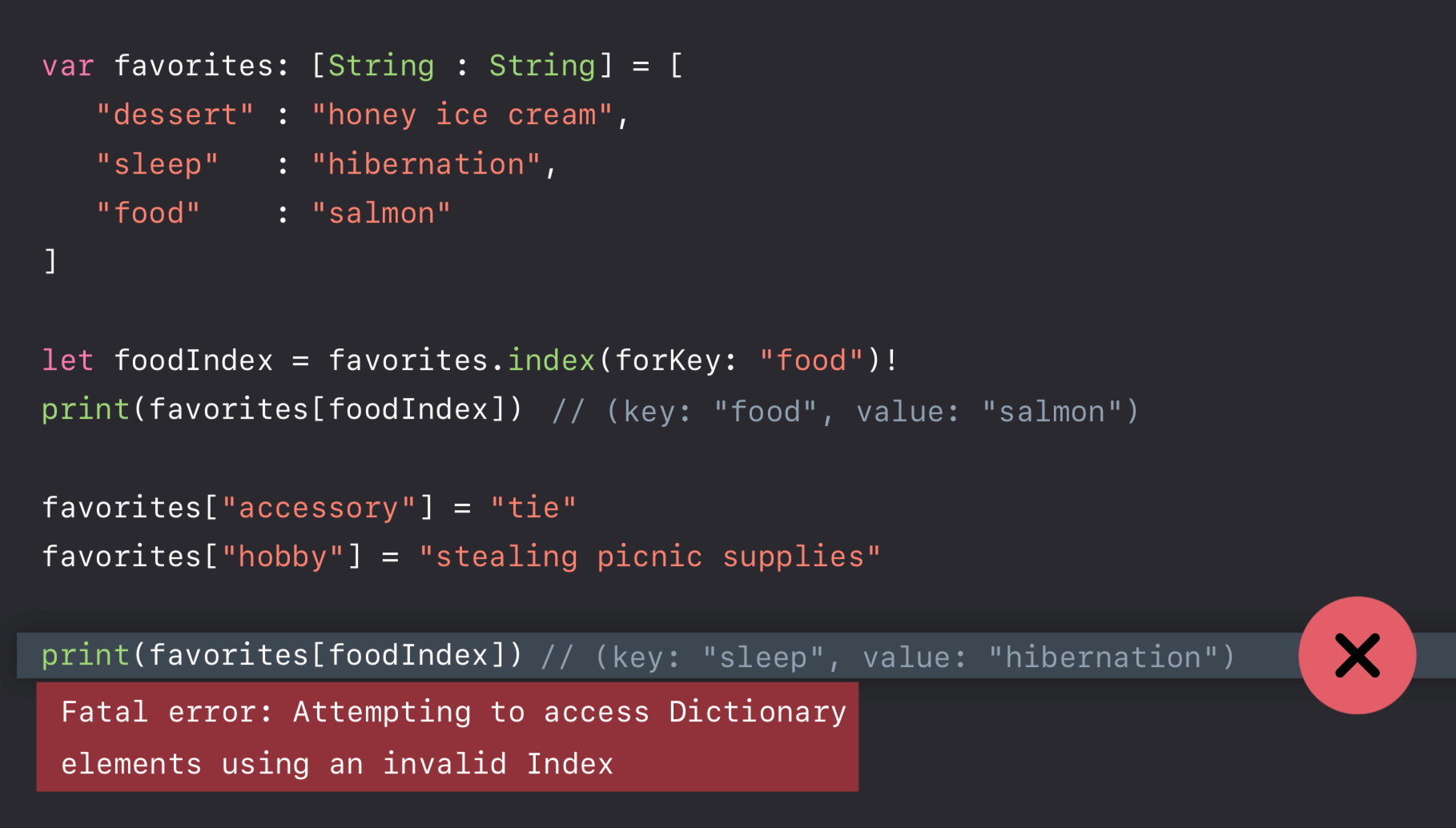
正确姿势:
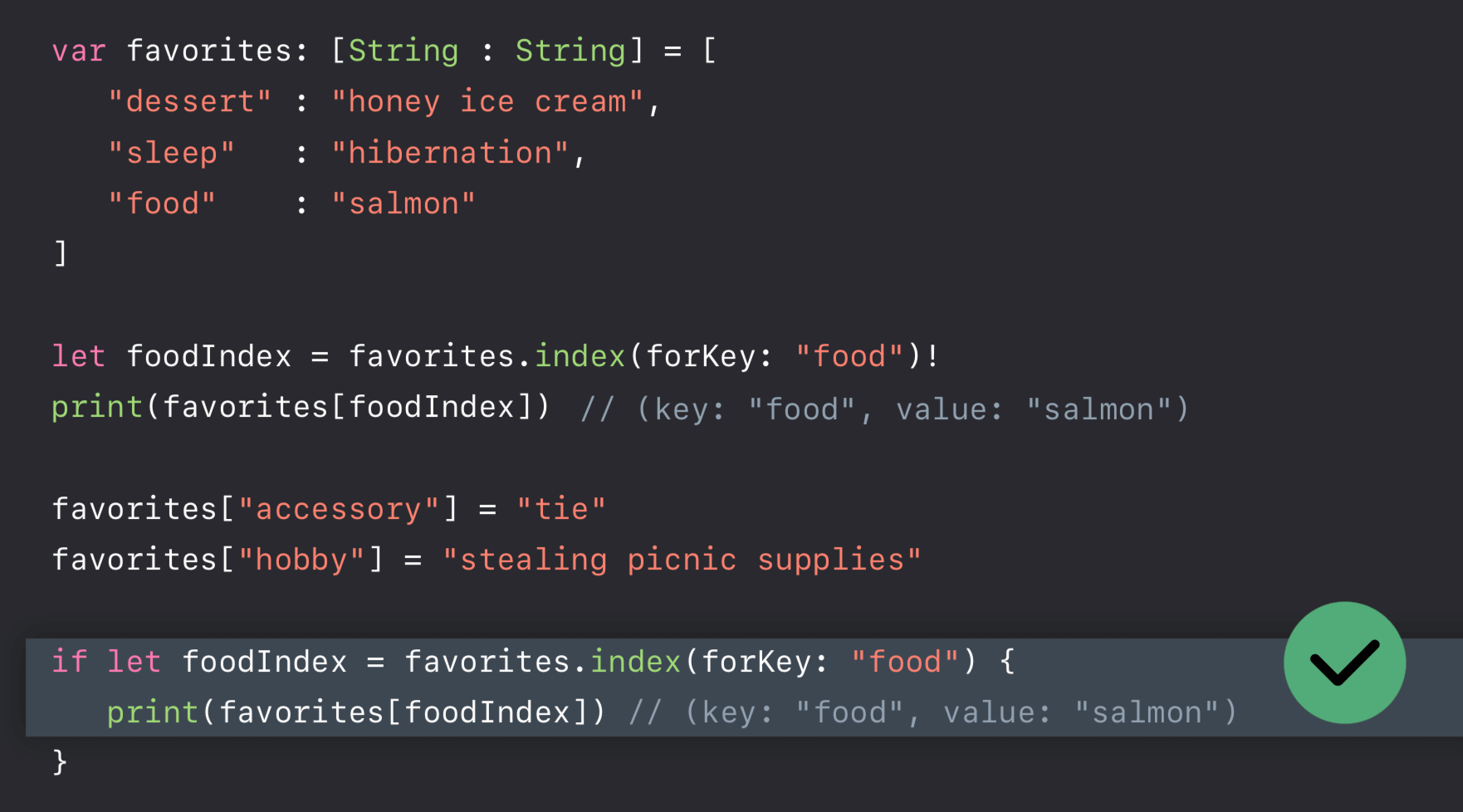
如何规避此类问题呢?
- 在持有索引和切片时,要谨慎处理
- 集合发生改变时,索引会失效,要记得更新
- 在需要索引和切片的情况下才对其进行计算
多线程
- 线程不安全的做法
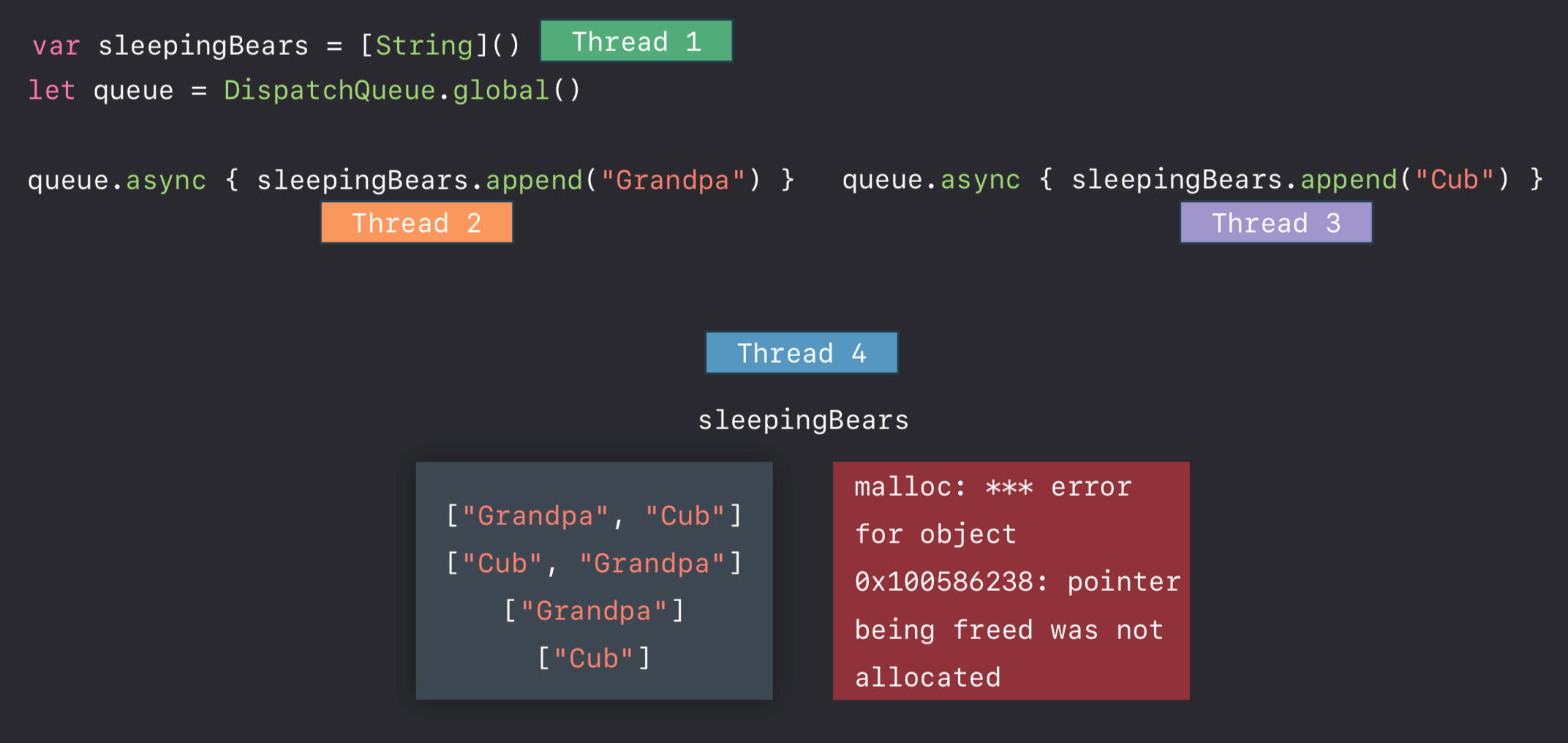
如何规避此类问题呢?
- 单个线程访问
我们可以使用 Xcode 自带的 Thread Sanitizer 来规避此类问题。
其他
- 优先使用不可变的集合类型,只有在你真正需要改变它时,才去使用可变类型。
Foundation 中的集合

值类型与引用类型
Swift 标准库中的集合都是值类型:
Swift only performs an actual copy behind the scenes when it is absolutely necessary to do so. Swift manages all value copying to ensure optimal performance, and you should not avoid assignment to try to preempt this optimization.
我们都知道 Swift 中值类型都是采用写时复制的方式进行性能优化。以 Array 为例:
//Value
var x:[String] = []
x.append("🐻")
var y = x // 未拷贝
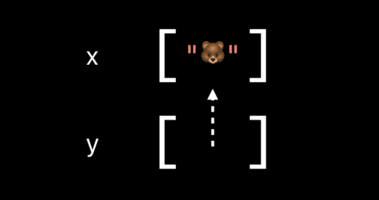
y.append("🐼") // 发生拷贝
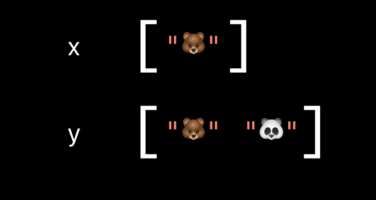
Foundation 中的集合都是引用类型,相比大家都知道,直接上图:

因此在实际开发过程中,我们要非常注意值类型与引用类型集合的选择。
Swift & Objective-C 桥接
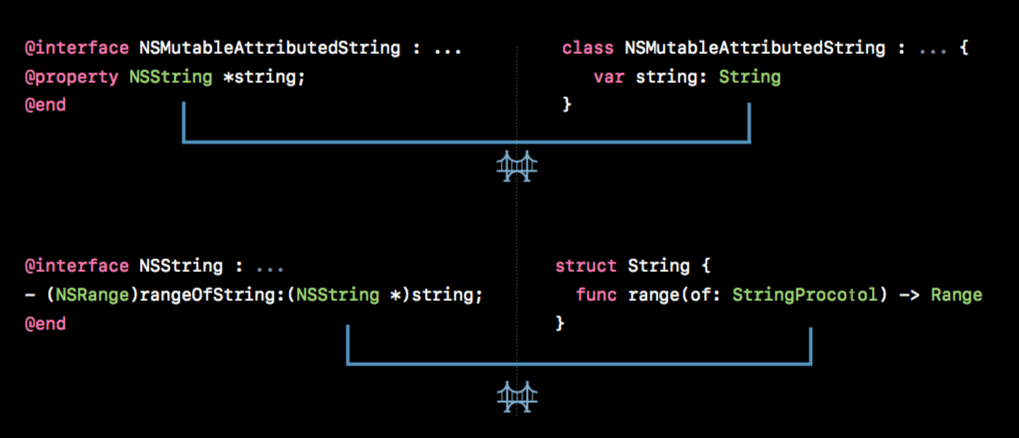
桥接就是把一种语言的某个类型转换为另一种语言的某个类型。桥接在 Swift 和 Objective-C 间是双向的。集合的桥接是很有必要的(如:Swift 数组可以桥接到 Objective-C等),开销也是会有的,因此在使用过程中建议测量并确定其桥接成本。来看个小例子:

假设 story 是一个非常长的字符串,这段代码桥接成本较大的地方有两处,主要是 text.string 的影响,下面我们简单分析一下:
let range = text.string.range(of: "Brown")
这里 NSMutableAttributedString 取 string 的时候发生了桥接,我们可以理解为返回类型桥接(return type)。
let nsrange = NSRange(range, in: text.string)
这行代码的传入参数也发生了桥接,我们可以理解为参数类型桥接(parameter type),下图更加直观的展示哪个地方发生了桥接:
苹果更建议我们采用这种方式来规避不必要的开销:
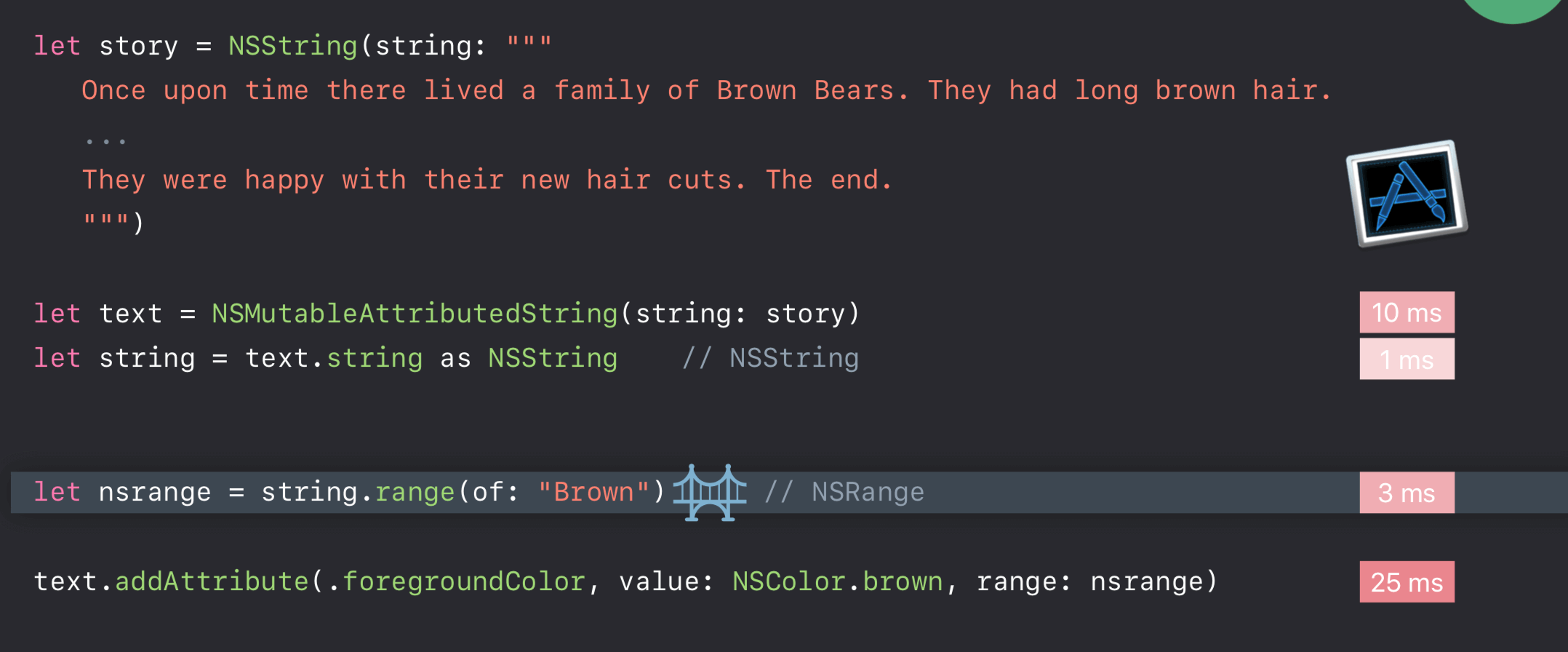
虽然 let range = string.range(of: "Brown")! 也发生了参数类型桥接,但就 “Brown” 字符串而言,桥接成本可忽略不计。
关于桥接(bridge),感兴趣的同学还可以看看往期的几个 Session:
- WWDC 2014:Session 407 Swift Interoperability In Depth(官方貌似找不到了)
- WWDC 2015:Session 401 Swift and Objective-C Interoperability
小结
这个 Session 主要是针对集合类型讲了些使用过程中的 Tips。
