

背景
informer是kubernetes非常重要的组件,负责各组件与apiserver的资源与事件同步。informer在许多组件中都有用到。乍一看可能比较难理解,但深入之后就会对kubernetes的事件处理机制与未来可能的瓶颈有更深刻的认识。
简单的来说,informer监听某些资源,从apiserver中接受该类型资源的变化,由用户注册的回调函数对资源变化进行处理,并将变化之后的对象持久化到本地缓存中。
源码分析
为了简单起见,我选择kubernetes的custom controller进行分析。该项目位于sample controller,源码比较简单,适合初学者上手理解。
首先看一下整个sample-controller的图解:
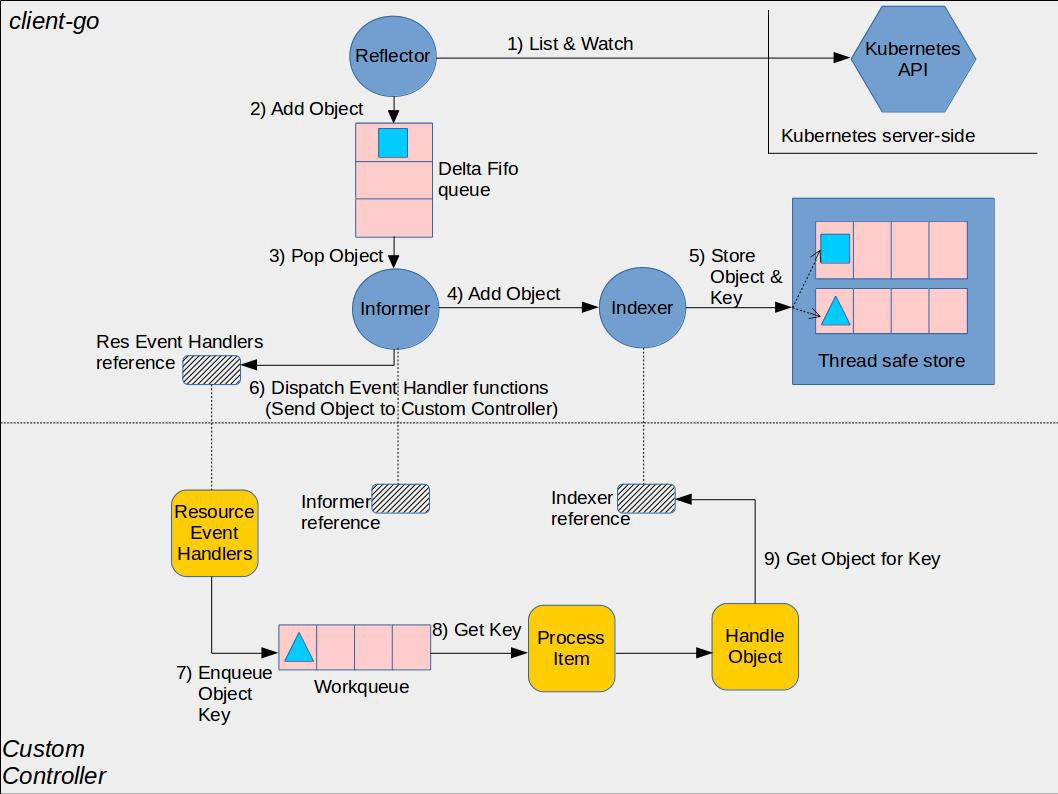
黄色的部分是controller相关的框架,包括workqueue。蓝色部分是client-go的相关内容,包括informer, reflector(其实就是informer的封装), indexer。从流程上看,reflector从apiserver中通过list&watch机制接收事件变化,进入Delta FIFO队列中,由informer进行处理。informer会将delta FIFO队列中的事件交给indexer组件,indexer组件会将事件持久化存储在本地的缓存中。之后,由于用户事先将为informer注册各种事件的回调函数,这些回调函数将针对不同的组件做不同的处理。例如在controller中,将把object放入workqueue中,之后由controller的业务逻辑中进行处理。处理的时候将从缓存中获取object的引用。即各组件对资源的处理仅限于本地缓存中,直到update资源的时候才与apiserver交互。
这里不讨论这个架构采用的种种思想,如消息队列、读写分离,毕竟这些思想早就被大家广泛接受,并应用于各种架构中。我们还是实际一点,看一下sample-controller的工程。包括
- main.go, controller.go
- pkg/apis: 接口的定义文件,types.go需要开发人员修改,包含着自定义资源的结构体。deepcopy函数都是由code-generator生成的
- pkg/signals: 这个包不用纠结,跨平台捕捉终止信号
- pkg/generated: 包含了clientset, informer, lister,这一整个包都是自动生成的
对照上图,可以大致理解整个工程各部件与图中组件的对应关系,下面我们就着源码,看一下informer的具体工作机制。
找到main.go,看其引用的包
kubeinformers "k8s.io/client-go/informers"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/clientcmd"
clientset "k8s.io/sample-controller/pkg/generated/clientset/versioned"
informers "k8s.io/sample-controller/pkg/generated/informers/externalversions"
我们发现用到的库主要是client-go。client-go是
Go clients for talking to a kubernetes cluster.
为用户提供编程接口。client-go可以提供对kubernetes原生资源的编程接口,而若我们要对crd资源进行处理,则需要引用后面两个包:clientset和informers,它们都是根据pkg/apis中自定义的内容,由code-generator生成的。即我们自定义CRD,自定义CRD的informer,自定义回调函数与业务逻辑,由kubernetes提供最基本的框架与机制。
看main函数中的几行代码:
cfg, err := clientcmd.BuildConfigFromFlags(masterURL, kubeconfig)
kubeClient, err := kubernetes.NewForConfig(cfg)
exampleClient, err := clientset.NewForConfig(cfg)
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, time.Second*30)
exampleInformerFactory := informers.NewSharedInformerFactory(exampleClient, time.Second*30)
由kubeconfig文件或masterURL生成config,并由config生成kubeClient和exampleClient,前者用于原生资源,后者用于CRD资源。之后由clientset生成informerFactory。这个函数要重点关注,第一个参数是clientset,第二个time.Second*30是resyncPeriod。resyncPeriod指每过一段时间,清空本地缓存,从apiserver中做一次list。这样可以避免list&watch机制错误导致业务逻辑错误,但在大规模集群中,重新list的代价不容小视。部分人喜欢设成一个较大的值,部分人喜欢设为0,即完全信任etcd的能力。
NewSharedInformerFactory()一路看进去,可以看到下面的函数
// NewSharedInformerFactoryWithOptions constructs a new instance of a SharedInformerFactory with additional options.
func NewSharedInformerFactoryWithOptions(client kubernetes.Interface, defaultResync time.Duration, options ...SharedInformerOption) SharedInformerFactory {
factory := &sharedInformerFactory{
client: client,
namespace: v1.NamespaceAll,
defaultResync: defaultResync,
informers: make(map[reflect.Type]cache.SharedIndexInformer),
startedInformers: make(map[reflect.Type]bool),
customResync: make(map[reflect.Type]time.Duration),
}
// Apply all options
for _, opt := range options {
factory = opt(factory)
}
return factory
}
这里生成的是一个工厂(工厂模式涉及设计模式的知识,如果不了解就补补课吧),该工厂的client就是之前传入的clientset,namespace是v1.NamespaceAll,即捕捉所有命名空间的指定资源,defaultResync之前解释过了,customResync可以为每个Informer制定不同的resync周期。informers是该client可以生成的informer的列表,每一个informer的类型是cache.SharedIndexInformer,startedInformers表示每个informer是否已经启动。
之后的factory=opt(factory),能看到opt是一个函数,从options中传入,而options是一个变长参数(熟悉C的童鞋可以飞快的理解)。
得到两个工厂kubeInformerFactory和exampleInformerFactory之后,我们可以生成一个controller对象:
controller := NewController(kubeClient, exampleClient,
kubeInformerFactory.Apps().V1().Deployments(),
exampleInformerFactory.Samplecontroller().V1alpha1().Foos())
NewController()这个函数包含四个参数,前两个是clientset,后两个是具体资源的informer。我们监听了两种资源: deployment和Foo。kubeInformerFactory.Apps().V1().Deployments()这行代码的意思是,选择factory中apigroups为app,apiversion为v1的deployments资源的informer接口。接口的含义后面会解释。
进入到NewController()内部后,下面的代码是event recorder的内容,用户平时用的kubectl get events命令就和这个相关。这部分不做更多分析了。
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartLogging(klog.Infof)
eventBroadcaster.StartRecordingToSink(&typedcorev1.EventSinkImpl{Interface: kubeclientset.CoreV1().Events("")})
recorder := eventBroadcaster.NewRecorder(scheme.Scheme, corev1.EventSource{Component: controllerAgentName})
之后会新建一个controller对象。
controller := &Controller{
kubeclientset: kubeclientset,
sampleclientset: sampleclientset,
deploymentsLister: deploymentInformer.Lister(),
deploymentsSynced: deploymentInformer.Informer().HasSynced,
foosLister: fooInformer.Lister(),
foosSynced: fooInformer.Informer().HasSynced,
workqueue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "Foos"),
recorder: recorder,
}
clientset都是透传进去的,recorder是上面新鲜出炉的,controller另外包含了lister, workqueue。workqueue的原理不属于client-go informer的范畴,后续如果另外的文章专门分析sample-controller再介绍。我们惊奇的发现,lister居然是informer的一个方法新建出来的,这么来看不是意味着informer的层次高于lister吗?然而我们看deploymentInformer的类型可以看到
// DeploymentInformer provides access to a shared informer and lister for
// Deployments.
type DeploymentInformer interface {
Informer() cache.SharedIndexInformer
Lister() v1.DeploymentLister
}
这个deploymentInformer是一个Interface而已,用过Informer()和Lister()方法才得到真正的informer和lister实例。这就是为什么之前说到传入NewController()的informer只是一个接口。那么看Informer()方法,它其实会初始化informer实例。
func (f *deploymentInformer) Informer() cache.SharedIndexInformer {
return f.factory.InformerFor(&appsv1.Deployment{}, f.defaultInformer)
}
其中InformerFor()在client-go/informers/factory.go中定义具体实现:
// InternalInformerFor returns the SharedIndexInformer for obj using an internal
// client.
func (f *sharedInformerFactory) InformerFor(obj runtime.Object, newFunc internalinterfaces.NewInformerFunc) cache.SharedIndexInformer {
f.lock.Lock()
defer f.lock.Unlock()
informerType := reflect.TypeOf(obj)
informer, exists := f.informers[informerType]
if exists {
return informer
}
resyncPeriod, exists := f.customResync[informerType]
if !exists {
resyncPeriod = f.defaultResync
}
informer = newFunc(f.client, resyncPeriod)
f.informers[informerType] = informer
return informer
}
流程比较简单,如果informer已经存在了,直接返回这个informer实例,否则再判断是否指定了customResync,如果没有沿用defaultResync,要注意的是这个默认值并不是常数,而是我们之前传进去的值,在这里是30s。之后,调用newFunc()生成informer实例。这个newFunc是InformerFor()的一个参数,在上一层的函数中,指定为f.defaultInformer。它的具体调用为return NewFilteredDeploymentInformer(client, f.namespace, resyncPeriod, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc}, f.tweakListOptions)。
如果还记得最开始的流程,我们在创建InformerFactory的时候,指定了namespace为All,tweakListOptions为空,上面的参数到这边才显示出它的作用。另外这儿还有一个伏笔,Indexers指定了NamespaceIndex为MetaNamespaceIndexFunc。这个伏笔涉及到indexer的机制,在当前我们不详细展开,只要知道,它意味着存储对象的时候按照namespace分类即可。接下来看到NewFilteredDeploymentInformer()函数内部:
// NewFilteredDeploymentInformer constructs a new informer for Deployment type.
// Always prefer using an informer factory to get a shared informer instead of getting an independent
// one. This reduces memory footprint and number of connections to the server.
func NewFilteredDeploymentInformer(client kubernetes.Interface, namespace string, resyncPeriod time.Duration, indexers cache.Indexers, tweakListOptions internalinterfaces.TweakListOptionsFunc) cache.SharedIndexInformer {
return cache.NewSharedIndexInformer(
&cache.ListWatch{
ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.AppsV1().Deployments(namespace).List(options)
},
WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.AppsV1().Deployments(namespace).Watch(options)
},
},
&appsv1.Deployment{},
resyncPeriod,
indexers,
)
}
这里面真正的初始化了一个informer实例。这里注册了List&Watch的回调函数,简单提一下,list&watch的回调函数差不多长下面的样子:
err = c.client.Get().
Namespace(c.ns).
Resource("deployments").
VersionedParams(&opts, scheme.ParameterCodec).
Timeout(timeout).
Do().
Into(result)
一个典型的RESTful的请求。
构造一个informer实例通过NewSharedIndexInformer()函数完成,传入的参数有ListWatcher(上面说的回调函数),runtime object(这里是deployment)以及indexers。indexers不是本地缓存,而是一个map[string]Func类型,根据上面的代码,这里string是NamespaceIndex,函数是MetaNamespaceIndexFunc。sharedIndexInformer包含了以下内容:
sharedIndexInformer := &sharedIndexInformer{
processor: &sharedProcessor{clock: realClock},
indexer: NewIndexer(DeletionHandlingMetaNamespaceKeyFunc, indexers),
listerWatcher: lw,
objectType: objType,
resyncCheckPeriod: defaultEventHandlerResyncPeriod,
defaultEventHandlerResyncPeriod: defaultEventHandlerResyncPeriod,
cacheMutationDetector: NewCacheMutationDetector(fmt.Sprintf("%T", objType)),
clock: realClock,
}
processer是一个非常重要的模块,但是仅仅就这儿的代码很难看出Processor究竟干了什么,后面我们会对processor做详细的分析。现在,我们先主要关注一下NewIndex():
// NewIndexer returns an Indexer implemented simply with a map and a lock.
func NewIndexer(keyFunc KeyFunc, indexers Indexers) Indexer {
return &cache{
cacheStorage: NewThreadSafeStore(indexers, Indices{}),
keyFunc: keyFunc,
}
}
它新建了一个cache,它的keyFunc是DeletionHandlingMetaNamespaceKeyFunc,即接受一个object,生成它的namepace/name的字符串。cache顾名思义是一层缓存,但是它并不是真正存储数据的层,而是
- Computing keys for objects via keyFunc
- Invoking methods of a ThreadSafeStorage interface
真正存储数据的是cache的ThreadSafeStore。整理一下思路,首先创建informerFactory,之后在controller的新建过程中触发了informer实例的新建,其中触发了indexer的新建,index又新建了threadSafeStore。NewThreadSafeStore()传入了两个参数:indexers和Indices{}。indexers前面说到了就是一个IndexFunc的map,而Indices{}是Index的map,而Index是map[string]sets.String。
这层存储有点绕,下面结合实例说明一下:比如当我们想添加一个object的时候,cache调用cache.Add(),把object通过keyFunc变成一个key。显然我们的例子中变成namepace/name。之后调用c.cacheStorage.Add(key, obj),我们这里新建的是threadSafeMap,于是在Add()中调用了c.updateIndices()。这个过程比较绕一些,源码贴在了下面。删除旧的object后,遍历所有的c.indexers。上面已经说到indexers只有一个,name是NamespaceIndex,其indexFunc的作用是获取object的namespace。于是我们获取了indexValues,就是object的namespace。于是我们通过indices[NamespaceIndex]获取到了应该在哪个index存储该object,简单地来说,一个index对应一个namespace。之后我们遍历indexValues,由于目前我们只有一个namespace,所以我们直接找到set := index[namespace],这里set是一个map[string]{struct},于是set插入object之后变成key-object的类型。总结来看,indices的k是indexFunc的名称,v是一个index,index的k是indexFunc(obj)的值,v是一个map[string]struct{},其k是keyFunc(obj)的值,v是obj的内容。确实有点绕对吧,不过不影响我们对于informer机制的理解。
func (c *threadSafeMap) updateIndices(oldObj interface{}, newObj interface{}, key string) {
// if we got an old object, we need to remove it before we add it again
if oldObj != nil {
c.deleteFromIndices(oldObj, key)
}
for name, indexFunc := range c.indexers {
indexValues, err := indexFunc(newObj)
if err != nil {
panic(fmt.Errorf("unable to calculate an index entry for key %q on index %q: %v", key, name, err))
}
index := c.indices[name]
if index == nil {
index = Index{}
c.indices[name] = index
}
for _, indexValue := range indexValues {
set := index[indexValue]
if set == nil {
set = sets.String{}
index[indexValue] = set
}
set.Insert(key)
}
}
}
弄清楚了存储的问题,我们回到sharedIndexInformer,看一下还有哪些东西我们没有讲到。indexer是获取底层存储的接口,存储我们弄明白了;processor, resyncCheckPeriod, defaultEventHandlerResyncPeriod, clock也提了一嘴,后面会详细再讲processor究竟干了什么;cacheMutationDetector其实并没有用到,可以不管;listWatcher我们也讲了;objectType, started, stopped不用说了,blockDeltas可以暂停delta FIFO队列中事件的处理,让一个新的event handler安全的加入。现在我们只剩下controller要再研究一下了。
type sharedIndexInformer struct {
indexer Indexer
controller Controller
processor *sharedProcessor
cacheMutationDetector CacheMutationDetector
// This block is tracked to handle late initialization of the controller
listerWatcher ListerWatcher
objectType runtime.Object
// resyncCheckPeriod is how often we want the reflector's resync timer to fire so it can call
// shouldResync to check if any of our listeners need a resync.
resyncCheckPeriod time.Duration
// defaultEventHandlerResyncPeriod is the default resync period for any handlers added via
// AddEventHandler (i.e. they don't specify one and just want to use the shared informer's default
// value).
defaultEventHandlerResyncPeriod time.Duration
// clock allows for testability
clock clock.Clock
started, stopped bool
startedLock sync.Mutex
// blockDeltas gives a way to stop all event distribution so that a late event handler
// can safely join the shared informer.
blockDeltas sync.Mutex
}
现在回到NewController()中,刚才我们分析到了Informer()中,现在看一下deploymentInformer.Informer().HasSynced。之前说明工作流程的时候有说过组件会先进行一次list,再持续的watch。list动作是否完成就是看各个informer的HasSynced是否为真。
之后,我们为informer实例注册事件回调函数:
deploymentInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleObject,
UpdateFunc: func(old, new interface{}) {
newDepl := new.(*appsv1.Deployment)
oldDepl := old.(*appsv1.Deployment)
if newDepl.ResourceVersion == oldDepl.ResourceVersion {
// Periodic resync will send update events for all known Deployments.
// Two different versions of the same Deployment will always have different RVs.
return
}
controller.handleObject(new)
},
DeleteFunc: controller.handleObject,
})
回调函数分为三类:add, update和delete,每个动作可以注册不同的回调函数,这个例子都注册成一样的而已。如果进入handleObject(),能发现它做的事情就是把foo对象加入到控制器的workqueue中。但是这部分我们暂时先不看了。
通过NewController()我们获得了一个controller对象,里面包含着lister, recorder, clientset。而之前我们已经初始化了informer,那么接下来就是启动controller和informer,让他们配合工作了。
kubeInformerFactory.Start(stopCh)
exampleInformerFactory.Start(stopCh)
if err = controller.Run(2, stopCh); err != nil {
klog.Fatalf("Error running controller: %s", err.Error())
}
启动informer的函数是各个工厂的Start()函数,这个函数的真正实现在client-go/informers/factory.go中,
for informerType, informer := range f.informers {
if !f.startedInformers[informerType] {
go informer.Run(stopCh)
f.startedInformers[informerType] = true
}
}
分别启动各个informer,并将它们的状态标记为已启动。Run()函数的实现在client-go/tools/cache/shared_informer.go中,func (s *sharedIndexInformer) Run(stopCh <-chan struct{})表明了这些informer实例会共享Index,即共享本地缓存。Run()函数又引入一个非常重要的组件:delta FIFO。看一下创建过程:fifo := NewDeltaFIFO(MetaNamespaceKeyFunc, s.indexer)。参数有两个,一个是MetaNamespaceKeyFunc,上面已经提过好几次了,是获取object的namespace/name,另一个是s.indexer,是一个获取底层存储的接口。
func NewDeltaFIFO(keyFunc KeyFunc, knownObjects KeyListerGetter) *DeltaFIFO {
f := &DeltaFIFO{
items: map[string]Deltas{},
queue: []string{},
keyFunc: keyFunc,
knownObjects: knownObjects,
}
f.cond.L = &f.lock
return f
}
deltaFIFO比较重要的内容包括items, queue和knownObjects,其中items是map[string]Deltas{},这里引入了delta和knownObjects的概念。delta指object的变化,是资源的增量,这个非常好理解。而从我们的直观感知来说,来了一个事件我们处理即可,为什么还要knownObjects呢?原因是有resync的存在,delta FIFO queue中内容很多,没有处理完时,若此时进行一次resync,有些已经在etcd中删除的object的deletion的delta将永久丢失。此时knownObjects就知道哪些object被删除了,并将没有来得及处理的deletion delta重新生成出来。我们不看knownObjects的细节了,看一下Deltas的细节。Deltas是一组Delta:type Deltas []Delta,而Delta的结构action+content
// Delta is the type stored by a DeltaFIFO. It tells you what change
// happened, and the object's state after* that change.
//
// [*] Unless the change is a deletion, and then you'll get the final
// state of the object before it was deleted.
type Delta struct {
Type DeltaType
Object interface{}
}
Type可以是四种之一
- Added
- Updated
- Deleted
- Sync:只在resync中用到
恰好对应着之前说到的三种eventHandler。这里就有一个问题:为什么一个DeltaFIFO中存的是Deltas而不直接存Delta呢?因为这样可以合并,减少处理事件的次数。当用户连续做多次操作时,这些才做将被合并成一个Deltas,减轻组件的压力。后面详细的讲一下怎么实现Delta的合并。
现在把思维返回到Run()函数中,我们接下来介绍sharedIndexInformer的最后一个组件:controller。这个controller不是sample-controller,而是informer中的一个controller。新建一个delta FIFO后,初始化controller所需的config。
cfg := &Config{
Queue: fifo,
ListerWatcher: s.listerWatcher,
ObjectType: s.objectType,
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
Process: s.HandleDeltas,
}
fifo透传了,现在叫queue;listerWatcher, objectType都透传了;resync有关的都和processor有关,关系着list&watch的机制;要注意config.Process赋值为s.HandleDeltas,这是deltas的处理函数,后面会讲到它与threadSafeStore如何配合工作。初始化config完毕后,用config新建一个controller,之后启动s.processor,启动s.controller。要注意的是defer的顺序,controller接收停止信号stopCh,这个是从顶层一直传下来的,与sample-controller, informer等共享;新建了processorStopCh,当程序终止后,保证了controller收到stopCh,停止controller,关闭processorStopCh,而processor通过wg.StartWithChannel()保证了这个channel关闭后,processor也将终止。这就是注释中说的
Separate stop channel because Processor should be stopped strictly after controller
那么问题在于究竟processor干了什么?wg.StartWithChannel(processorStopCh, s.processor.run)启动了一个sharedProcessor,它先加了一把读写锁,阻塞读,加入所有的listeners。每个listener是一个processorListener,然后分别p.wg.Start(listener.run)和p.wg.Start(listener.pop)。字面上来说,sharedProcessor将事件分发给各个processor处理,然而但从这边我们还是不知道processor的功能。
先把processor放在一边,我们先看看s.controller.Run()都干了什么。
// Run begins processing items, and will continue until a value is sent down stopCh.
// It's an error to call Run more than once.
// Run blocks; call via go.
func (c *controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
go func() {
<-stopCh
c.config.Queue.Close()
}()
r := NewReflector(
c.config.ListerWatcher,
c.config.ObjectType,
c.config.Queue,
c.config.FullResyncPeriod,
)
r.ShouldResync = c.config.ShouldResync
r.clock = c.clock
c.reflectorMutex.Lock()
c.reflector = r
c.reflectorMutex.Unlock()
var wg wait.Group
defer wg.Wait()
wg.StartWithChannel(stopCh, r.Run)
wait.Until(c.processLoop, time.Second, stopCh)
}
这里面又引入一个新的东西reflector。NewReflector()传入了四个变量:listWatcher, objectType, queue, resyncPeriod。queue其实是delta FIFO,再结合listWatcher和resyncPeriod,我们很容易猜测出reflector负责与apiserver交互,获取资源的变化情况。于是我们可以继续看r.Run和wait.Until(c.processLoop, time.Second, stopCh)两个函数了。接收到stopCh后,停止processLoop,终止reflector。先看r.Run,里面的逻辑非常简单,永远循环着做ListAndWatch,即使意外出错了也会重启。
ListWatch的机制这边不做源码的分析了,原理上说,一开始通过list, err = pager.List(context.Background(), options)每一次list获取一个object,做这次list的时候将永远显示的把resourceVersion设为0。之后通过listMetaInterface.GetResourceVersion()获取resourceVersion,并通过syncWith()在本地缓存中替换版本号。list完成后,还会起一个go routine周期性的进行resync。之后会进入一个死循环,执行watch操作。而每次watch到一个事件之后,触发r.watchHandler(),里面会通过reflect机制获取到事件的类型和内容,并根据类型的不同触发不同的回调函数。在代码中,内容的更新会及时的更新到delta FIFO中。即通过list&watch机制,获取到资源的变化。下面的代码可以注意到Type+内容的模式正好与Delta的类型相符合。
switch event.Type {
case watch.Added:
err := r.store.Add(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to add watch event object (%#v) to store: %v", r.name, event.Object, err))
}
case watch.Modified:
err := r.store.Update(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to update watch event object (%#v) to store: %v", r.name, event.Object, err))
}
case watch.Deleted:
// TODO: Will any consumers need access to the "last known
// state", which is passed in event.Object? If so, may need
// to change this.
err := r.store.Delete(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to delete watch event object (%#v) from store: %v", r.name, event.Object, err))
}
看完r.Run,看一下processLoop()。它以1s为周期,周期性的执行,逻辑很简单,调用c.config.Queue.Pop(PopProcessFunc(c.config.Process)),即从delta FIFO中取出一个元素并处理。可以翻一下,上面说到c.config.Process就是s.HandleDeltas。这里面的逻辑也非常简单,就是与sharedIndexInformer的indexer,也就是缓存交互,在底层的threadSafeMap中更新我们从Delta FIFO中取到的内容,之后通过s.processor.distribute()进行消息的分发。
case Sync, Added, Updated:
isSync := d.Type == Sync
s.cacheMutationDetector.AddObject(d.Object)
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
if err := s.indexer.Update(d.Object); err != nil {
return err
}
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
if err := s.indexer.Add(d.Object); err != nil {
return err
}
s.processor.distribute(addNotification{newObj: d.Object}, isSync)
}
case Deleted:
if err := s.indexer.Delete(d.Object); err != nil {
return err
}
s.processor.distribute(deleteNotification{oldObj: d.Object}, false)
}
在distribute中,sharedProcesser通过listener.add(obj)向每个listener分发该object。而该函数中又执行了p.addCh <- notification。看到这儿,我们终于可以结合上面的理顺processor的作用。整理一下思路,controller(非sample-controller)在初始化的时候将自身的模块重新封装为reflector,reflector通过list&watch机制将资源的变化情况变成type+object的Delta放入Delta FIFO queue中,同时controller通过processLoop从delta FIFO queue中获取object,并将最新的资源向threadSafeMa进行更新。其实说白了reflector是controller的一部分,controller是informer的一部分,最终我们可以发现informer自己通过list&watch获取事件、同步资源,只是其中通过delta FIFO做了一个简单的消息队列,一方面方便实现动作+内容的模式,便于处理删除这个行为,一方面消息队列对事件做了压缩,提高了处理效率。
现在,回过头来看一下processer。上面说到在delta FIFO的pop()中,最终将object封装为notifcation,传入addCh。回忆一下在sharedIndexInformer的Run()函数中,最终调用了wg.StartWithChannel(processorStopCh, s.processor.run),其中又对所有的listener,调用了
p.wg.Start(listener.run)和p.wg.Start(listener.pop),先看pop函数:
func (p *processorListener) pop() {
defer utilruntime.HandleCrash()
defer close(p.nextCh) // Tell .run() to stop
var nextCh chan<- interface{}
var notification interface{}
for {
select {
case nextCh <- notification:
// Notification dispatched
var ok bool
notification, ok = p.pendingNotifications.ReadOne()
if !ok { // Nothing to pop
nextCh = nil // Disable this select case
}
case notificationToAdd, ok := <-p.addCh:
if !ok {
return
}
if notification == nil { // No notification to pop (and pendingNotifications is empty)
// Optimize the case - skip adding to pendingNotifications
notification = notificationToAdd
nextCh = p.nextCh
} else { // There is already a notification waiting to be dispatched
p.pendingNotifications.WriteOne(notificationToAdd)
}
}
}
}
上面这段pop()非常的优美,在一个函数中实现了多个功能。当addCh接收到信号时,即从delta FIFO中取出一个delta后,判断notification是否为空。一般来说,notifcation永远从pendingNoditication中读取,当buffer为空时,当前事件处理完成后,nofification为空。这种情况下来了一个新事件,就再次设置nofication。而当notification不为空的时候,则将notification的内容传进nextCh中,并让notification从buffer中再取出一个。解释起来很绕,总之原理就是一个环状队列,通过addCh接受delta FIFO中的事件,通过notification和buffer存储这些事件,并通过nextCh发送出去。
nextCh的逻辑在run()中,看下面的代码就可以理解,根据不同的事件类型,进行不同的处理。这里面p.handler就是我们在工程的main函数中看到的eventHandler,之前我们已经向eventHandler注册了回调函数,这里真正的调用了这些回调函数。
case updateNotification:
p.handler.OnUpdate(notification.oldObj, notification.newObj)
case addNotification:
p.handler.OnAdd(notification.newObj)
case deleteNotification:
p.handler.OnDelete(notification.oldObj)
至此,我们分析完了informer的所有机制。至于一些更细节,如delta FIFO如何合并事件等,限于篇幅不再分析。其实上面所说的内容在上层来看非常简单,开发人员甚至不需要清楚地了解底层的原理是什么,就可以用Informer的机制进行编程,实现一个简单的sample-controller,不得不说informer的设计真的非常精巧。
使用
从一个门外汉的角度看,快速上手informer机制进行编程,只要记住下面的步骤。
- 由
clientcmd.BuildConfigFromFlags生成一个config - 由config通过
NewForConfig生成clientset - 由clientset通过
NewSharedInformerFactory生成工厂 - 向你想要的具体的Informer实例中注册eventHandler
- 调用
factory.Start()
至此,你可用通过clientset获取到etcd中的所有数据了!还有一个小注意点,clientset可以直接和apiserver通信,在写操作时必须通过clientset直接与apiserver通信;读操作时尽量通过lister从本地缓存中获取数据,并且由于获取到的不是副本,而是引用,所以先做一个deepcopy,再进行update才做。
