

转载自浅尝辄止,React是如何工作的
大神们可以写出“深入浅出”系列,小白就写点"真·浅尝辄止"系列的吧,主要便于自己理解和巩固,毕竟一开始就上源码还是会头大滴,于是就准备浅尝辄止的了解下"React是如何工作的?"
React是怎么工作的? 你知道Diff算法吗 ---xx面试官
小白的前端排坑指南:
How React.js works
Virtual Dom VS Browser Dom
React除了是MVC框架,数据驱动页面的特点之外,核心的就是他很"快"。 按照普遍的说法:"因为直接操作DOM会带来重绘、回流等,带来巨大的性能损耗而导致渲染慢等问题。React使用了虚拟DOM,每次状态更新,React比较虚拟DOM的差异之后,再更改变化的内容,最后统一由React去修改真实DOM、完成页面的更新、渲染。"
上面这段话,是我们都会说的,那么一般到这里,面试官就问了:"什么是虚拟DOM,React是怎么进行比较的?Diff算法了解吗?"。之前是有点崩溃的,于是决定浅尝一下:
- 虚拟DOM是React的核心,它的本质是JavaScript对象;
- BrowserDOM(也就是页面真实DOM)就是Browser对象了。
DOM没什么好说的,主要说下虚拟DOM的一些特点:
- 本质是JS对象,代表着真实的DOM
- 比真实DOM的比较和操作快的多
- 每秒可创建200,000个虚拟DOM节点
- 每次setState或despatch一个action,都会创建一次全新的虚拟dom
前几点没什么好说的,注意第四点,也就是你每一个改动,每一个动作都会让React去根据当前的状态创建一个全新的Virtual DOM。

这里每当Virtual DOM生成,都打印了出来,可以看到,它代表着真实DOM,而每次生成全新的,也是为了能够比较old dom和new dom之前的差别。
Diff算法
刚才提到了,React会抓取每个状态下的内容,生成一个全新的Virtual DOM,然后通过和前一个的比较,找出不同和差异。React的Diff算法有两个约定:
- 两个不同类型的元素,会产生两个不同的树
- 开发者,可以使用key关键字,告诉React哪些子元素在DOM下是稳定存在的、不变的。
第二点着重说一下,举个例子:比如真实DOM的ul标签下,有一系列的<li>标签,然而当你想要重新排列这个标签时,如果你给了每个标签一个key值,React在比较差异的时候,就能够知道"你还是你,只不过位置变化了"。 React除了要最快的找到差异外,还希望变化是最小的。如果加了key,react就会保留实例,而不像之前一样,完全创造一个全新的DOM。
来个更具体的:
1234
下一个状态后,序列变为
1243
对于我们来讲,其实就是调换了4和3的顺序。可是怎么让React知道,原来的那个3跑到了原来的4后面了呢? 就是这个唯一的key起了作用。
相关面试题:为什么React中列表模板中要加入key
Diff运算实例
Diff在进行比较的时候,首先会比较两个根元素,当差异是类型的改变的时候,可能就要花更多的“功夫”了
不同类型的dom元素
比如现在状态有这样的一个改变:
<div>
<Counter />
</div>
<span>
<Counter />
</span>
复制代码
可以看到,从<div>变成了<span>,这种类型的改变,带来的是直接对old tree的整体摧毁,包括子元素Counter。 所以旧的实例Counter会被完全摧毁后,创建一个新的实例来,显然这种效率是低下的
同类型dom元素
当比较后发现两个是同类型的,那好办了,React会查看其属性的变化,然后直接修改属性,原来的实例都得意保留,从而使得渲染高效,比如:
<div className="before" title="stuff" />
<div className="after" title="stuff" />
复制代码
除了className,包括style也是一样,增加、删除、修改都不会对整个 dom tree进行摧毁,而是属性的修改,保留其下面元素和节点
相同类型的组件元素
与上面类似,相同类型的组件元素,子元素的实力会保持,不会摧毁。 当组件更新时,实例保持不变,以便在渲染之间保持状态。React更新底层组件实例的props以匹配新元素,并在底层实例上调用componentWillReceiveProps()和componentWillUpdate()。
接下来,调用render()方法,diff算法对前一个结果和新结果进行递归
key props
如果前面对key的解释,还不够清除,这里用一个真正的实例来说明key的重要性吧。
- 场景一:在一个列表最后增加一个元素
<ul>
<li>first</li>
<li>second</li>
</ul>
------
<ul>
<li>first</li>
<li>second</li>
<li>third</li>
</ul>
复制代码可以看到,在这种情况下,React只需要在最后insert一个新元素即可,其他的都不需要变化,这个时候React是高效的,但是如果在场景二下:
- 场景二:在列表最前面插入一个元素
<ul>
<li>Duke</li>
<li>Villanova</li>
</ul>
---
<ul>
<li>Connecticut</li>
<li>Duke</li>
<li>Villanova</li>
</ul>
复制代码这对React可能就是灾难性的,因为React只知道前两个元素不同,因此会完全创新一个新的元素,最后导致三个元素都是重新创建的,这大大降低了效率。这个时候,key就排上用场了。当子元素有key时,React使用key将原始树中的子元素与后续树中的子元素相匹配。例如,在上面的低效示例中添加一个key可以使树转换更高效:
<ul>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
------
<ul>
<li key="2014">Connecticut</li>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
复制代码这样,只有key值为2014的是新创建的,而2015和2016仅仅是移动了位置而已。
策略
React是用什么策略来比较两颗tree之间的差异呢?这个策略是最核心的部分:
两个树的完全的 diff 算法是一个时间复杂度为 O(n^3) 的问题。但是在前端当中,你很少会跨越层级地移动DOM元素。所以 Virtual DOM 只会对同一个层级的元素进行对比:
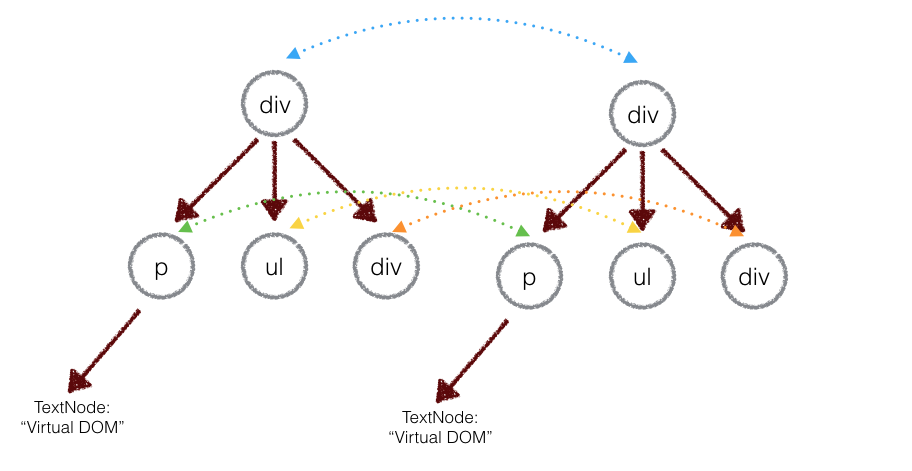
上面的div只会和同一层级的div对比,第二层级的只会跟第二层级对比。这样算法复杂度就可以达到 O(n)。
深度优先遍历
在实际代码中,会对新旧两棵树进行一个深度优先的遍历,这样每个节点都会有一个唯一的标记,然后记录差异
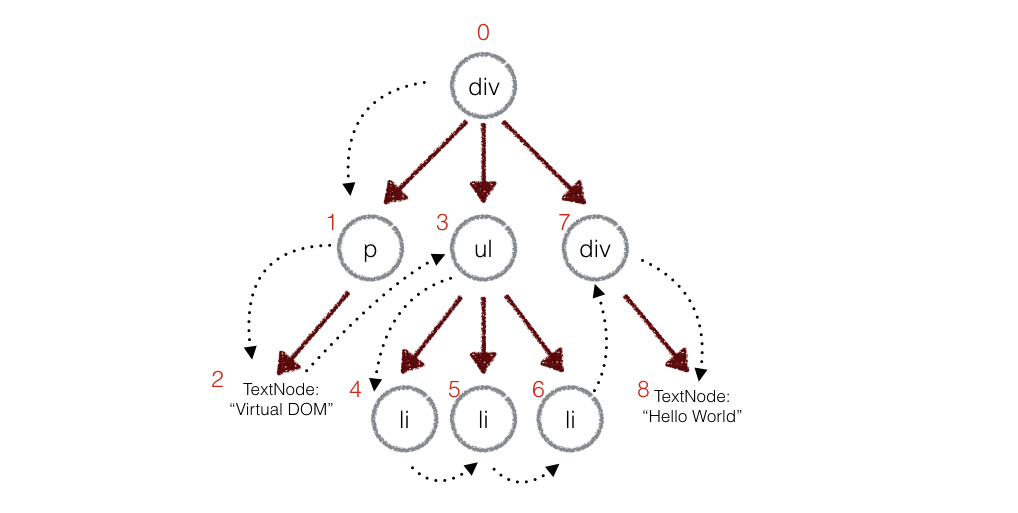
在深度优先遍历的时候,每遍历到一个节点就把该节点和新的的树进行对比。如果有差异的话就记录到一个对象里面。
比如第上图中的1号节点p,有了变化,这样子就记录如下:
patches[1] = [{difference}, {difference}...]//用数组存储新旧节点的差异
复制代码ok,那么差异类型呢,在上一节中已经说了,包括根元素的类型的不同分为两大类,然后根据不同的情况采取不同的更换策略。
最后,就是在真实DOM进行操作,apply这些差异,更新和渲染了。
为什么Redux 需要 reducers是纯函数?
这又是一个很厉害的问题了,使用Redux的都知道,reducers会接收上一个state和action作为参数,然后返回一个新的state,这个新的state不能是在原来state基础上的修改。所以经常可以看到以下的写法:
return Object.assign(...)
//或者----------
return {...state,xx:xxx}
复制代码其作用,都是为了返回一个全新的对象。
为什么reducers要求是纯函数(返回全新的对象,不影响原对象)? --某面试官
纯函数
从本质上讲,纯函数的定义如下:不修改函数的输入值,依赖于外部状态(比如数据库,DOM和全局变量),同时对于任何相同的输入有着相同的输出结果。
举个例子,下面的add函数不修改变量a或b,同时不依赖外部状态,对于相同的输入始终返回相同的结果。
const add = (a,b) => {a + b};
复制代码这就是一个纯函数,结果对a、b没有任何影响,回头去看reducer,它符合纯函数的所有特征,所以就是一个纯函数
为什么必须是纯函数?
先告诉你结果吧,如果在reducer中,在原来的state上进行操作,并返回的话,并不会让React重新渲染。 完全不会有任何变化!
接下来看下Redux的源码:
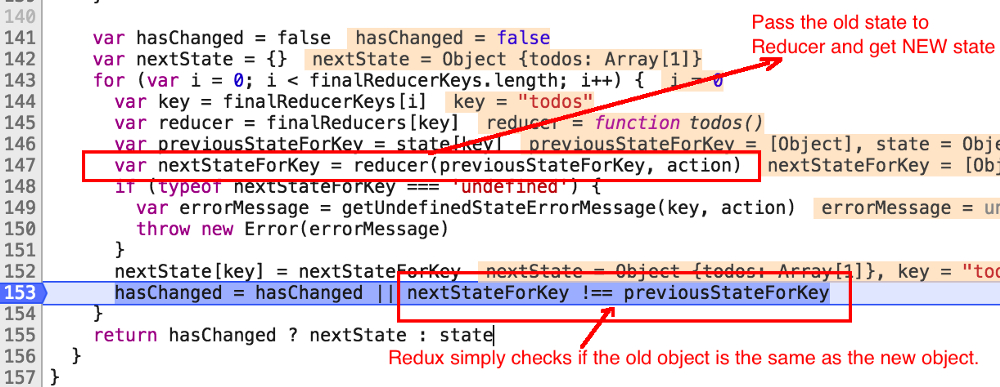
Redux接收一个给定的state(对象),然后通过循环将state的每一部分传递给每个对应的reducer。如果有发生任何改变,reducer将返回一个新的对象。如果不发生任何变化,reducer将返回旧的state。
Redux只通过比较新旧两个对象的存储位置来比较新旧两个对象是否相同。如果你在reducer内部直接修改旧的state对象的属性值,那么新的state和旧的state将都指向同一个对象。因此Redux认为没有任何改变,返回的state将为旧的state。
好了,也就是说,从源码的角度来讲,redux要求开发者必须让新的state是全新的对象。那么为什么非要这么麻烦开发者呢?
请看下面的例子:尝试比较a和b是否相同
var a = {
name: 'jack',
friend: ['sam','xiaoming','cunsi'],
years: 12,
...//省略n项目
}
var b = {
name: 'jack',
friend: ['sam','xiaoming','cunsi'],
years: 13,
...//省略n项目
}
复制代码
思路是怎样的?我们需要遍历对象,如果对象的属性是数组,还需要进行递归遍历,去看内容是否一致、是否发生了变化。 这带来的性能损耗是非常巨大的。 有没有更好的办法?
有!
//接上面的例子
a === b //false
复制代码我不要进行深度比较,只是浅比较,引用值不一样(不是同一个对象),那就是不一样的。 这就是redux的reducer如此设计的原因了
