

作为前端大佬的你,想必对于 JavaScript 的正则表达式非常熟悉了,甚至随手就能利用正则表达式写出一些惊世骇俗的代码。只是不知道你是否有和我一样的疑惑:正则表达式是怎么执行的呢?
我们写下这样的正则表达式 (a+|b)c,然后用它来匹配字符串 aacde、abcde,这是怎样的一个过程呢?
前段时间,我试着去查找、学习相关的资料,然后知道了以下的内容:
- 目前正则表达式引擎主要有两种:NFA 和 DFA
- JavaScript 采用的是 NFA 引擎
那么 NFA 又是啥,跟 DFA 有什么不同?NFA 又是怎么实现正则表达式匹配的呢?
接下来,我试着用我自己的方式来介绍,希望也能帮助对此感兴趣的你。
NFA
NFA 是指 Nondeterministic Finite Automaton,非确定有限状态自动机。
有点深奥,我刚看到的时候也很懵,咱们慢慢来。
先说有限状态机(Automation),来个示例图看下:
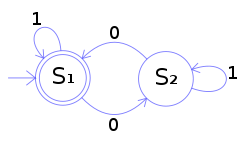
状态机中有这样一些要素,对照上图分别说下:
- 开始状态:圆圈表示状态,被一个“没有起点的箭头”指向的状态,是开始状态,上例中是 S1
- 最终状态:也叫接受状态,图中用双圆圈表示,这个例子中也是 S1
- 输入:在一个状态下,向状态机输入的符号/信号,不同输入导致状态机产生不同的状态改变
- 转换:在一个状态下,根据特定输入,改变到特定状态的过程,就是转换
所以有限状态机的工作过程,就是从开始状态,根据不同的输入,自动进行状态转换的过程。
上图中的状态机的功能,是检测二进制数是否含有偶数个 0。从图上可以看出,输入只有 1 和 0 两种。从 S1 状态开始,只有输入 0 才会转换到 S2 状态,同样 S2 状态下只有输入 0 才会转换到 S1。所以,二进制数输入完毕,如果满足最终状态,也就是最后停在 S1 状态,那么输入的二进制数就含有偶数个 0。
还是有点晕,这个和正则表达式有什么关系呢?
正则表达式,可以认为是对一组字符串集合的描述。例如 (a+|b)c 对应的字符串集合是:
ac
bc
aac
aaac
aaaac
...
有限状态机也可以用来描述字符串集合,同样是正则表达式所描述的集合,用有限状态机来表示,可以是这样的:
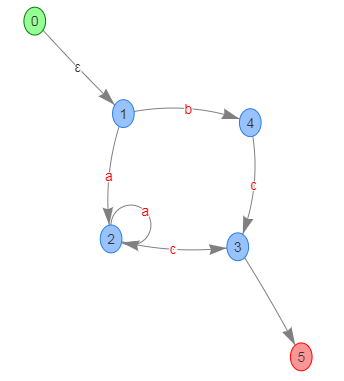
这里的 NFA 状态图是我用自己写的页面绘制出来的,比较简陋,不过我相信你可以看懂。 你可以在这里(luobotang/nfa)自己试试看,只支持简单的正则表达式。
并且,有限状态机是可以“执行”的,给出如上的状态机之后,就可以用来对输入的字符串进行检测。如果最终匹配,也就意味着输入的字符串和正则表达式 (a+|b)c 匹配。
所以,编程语言中的正则表达式,一般是通过有限状态机来实现。正则表达式匹配字符串的过程,可以分解为:
- 正则表达式转换为等价的有限状态机
- 有限状态机输入字符串执行
到这里,我想你大概知道有限状态机在正则表达式中的作用了,当然,只是具体实现还不清楚。
这里再讲一下 NFA 和 DFA 的区别。DFA 是 Deterministic Finite Automaton,确定有限状态机。DFA 可以认为是一种特殊的 NFA,它最大的特点,就是确定性。它的确定性在于,在一个状态下,输入一个符号,一定是转换到确定的状态,没有其他的可能性。
举个例子,对于正则表达式 ab|ac,对应 NFA 可以是这样的:
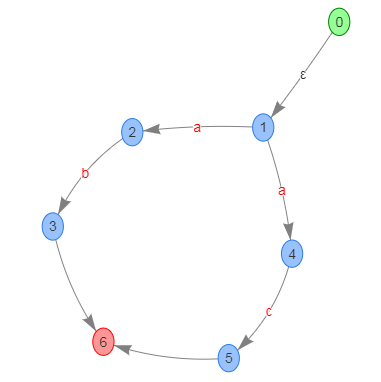
可以看到,在状态 1 这里,如果输入 a,其实有两种可能,如果后面的符号是 b,那么可以匹配成功,后面符号是 c 也能匹配成功。所以状态机在执行过程中,可能要尝试所有的可能性。在尝试一种可能路径匹配失败后,还要回到之前的状态再尝试其他的路径,这就是“回溯”。
但是 DFA 消除了这种不确定性,所以可以想见,其执行性能应该要比 NFA 更好,因为不需要回溯。
NFA 是可以转换为等价的 DFA 的,也就是说,理论上讲,正则表达式可以用 DFA 来实现,从而获得优于 NFA 的执行性能。但是 NFA 转换 DFA 的过程,会消耗更多资源,甚至最终得到的 DFA 要占用大量存储空间(据有的资料的说法,可能会产生指数级增长)。而且,DFA 相比 NFA,在实现一些正则表达式的特性时会更复杂,成本更高。所以当前的许多编程语言,其正则表达式引擎为 NFA 模式。
可以用如下的正则表达式测试当前编程语言采用的引擎是否 NFA:
nfa|nfa not
用上面的正则表达式来测试字符串 nfa not,NFA 引擎在检测满足 nfa 就返回匹配成功的结果了,而 DFA 则会尝试继续查找,也就是说会得到“最长的匹配结果”。
从正则表达式到 NFA
了解了 NFA 在正则表达式中的应用,接下来要介绍的是如何将正则表达式转换得到对应的 NFA。这一部分会稍微有些枯燥,不过对于深入理解正则表达式和 NFA 还是挺有帮助的。
Thompson 算法
Thompson 算法用于转换正则表达式为NFA,它并非最高效的算法,但是实用,易于理解。
Thompson 算法中使用最基本的两种转换:
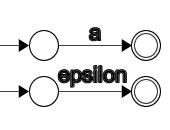
普通转换就是在一个状态下,输入字符a后转换至另一个状态;epsilon转换则不需要有输入,就从一个状态转换至另一个状态。
正则表达式中的各种运算,可以通过组合上述两种转换实现:
- 组合运算
RS:

-
替换运算
R|S: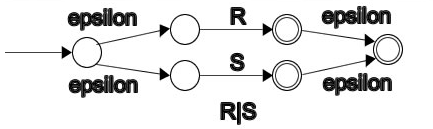
-
重复运算
R*: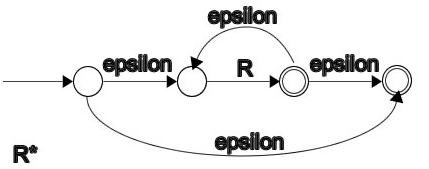
上面图中的 R、S 是有开始状态和结束状态的 NFA。
以正则表达式 ab|c 为例,包括两个运算:
ab组合ab的结果,与c替换
这样我们把正则表达式视为一系列输入和运算,进行分解、组合,就可以得到最终的 NFA。
首先,我们要把正则表达式转换为方便记录输入、运算的方式。
正则表达式 -> 后缀表达式
后缀表达式是一种方便记录输入、运算的表达式,本身已包含了运算符的优先级,也称为 逆波兰表示法(Reverse Polish Notation,简写为 RPN)。
为方便记录运算,我们为正则表达式中的组合运算也创建一个运算符“.”(本文只涉及最简单的正则表达式形式,这里的“.”不是用于匹配任意字符的特殊符号)。
正则表达式ab|c对应的后缀表达式为 ab.c|。
这样,通过逐个扫描后缀表达式,并识别其中的运算符来执行,就可以对后缀表达式进行求解。对于正则表达式来说,则是在将其变为后缀表达式后,通过“求值”的过程来进一步构建并得到最终的 NFA。
用于创建后缀表达式的是 调度场算法。
对于这里的正则表达式处理的场景,算法的大致描述如下:
代码在:regex2post() | nfa.js#L14 - luobotang/nfa
- 创建输出队列 output 和运算符栈 ops
- 依次读取输入字符串中每一个字符 ch
- 如果 ch 是普通字符,追加到 output
- 如果 ch 是运算符,只要 ops 栈顶的运算符优先级不低于 ch,依次出栈并追加到 output,最后将 ch 入栈 ops
- 如果 ch 是“(”,入栈 ops
- 如果 ch 是“)”,只要 ops 栈顶不是“(”,依次出栈并追加到 output
- 将 ops 中运算符依次出栈追加到 output
- 返回 output
具体处理过程中,由于原始正则表达式中并没有组合运算符,所以需要自行判断合理的插入位置。
运算符优先级如下(由高到低):
- * ? +
- .
- |
- (
后缀表达式 -> NFA
基于后缀表达式创建 NFA,是一个由简单的 NFA 进行不断组合得到复杂 NFA 的过程。
用于表示状态 State 的数据结构为:
// State
{
id: String,
type: String, // 'n' - normal, 'e' - epsilon, 'end'
symbol: String, // 普通状态对应的输入字符
out: State, // 允许的下一个状态
out1: State // 允许的下一个状态
}
每个状态可以对应最多两个 out 状态,像 a|b|c 的表达式,会被分解为 (a|b)|c,每次运算符“|”都只处理两个(子)表达式。
在构造最终 NFA 过程中,每次会创建 NFA 的片段 Fragment:
// Fragment
{
start: State,
out: State
}
不管 NFA 片段内部是怎样复杂,它都只有一个入口(开始状态),一个出口(最终状态)。
这一部分代码在:post2nfa() | nfa.js#L90 - luobotang/nfa
处理的过程大致为:
- 创建用于记录 NFA 片段的栈 stack
- 依次读取输入的后缀表达式的每个字符 ch
- 如果 ch 是运算符,从 stack 出栈所需数目的 NFA 片段,构建新的 NFA 片段后入栈 stack
- 如果 ch 是普通字符,创建新的状态,并构建只包含此状态的 NFA 片段入栈 stack
- 返回 stack 栈顶的 NFA 片段,即最终结果
以对组合运算的处理为例:
const e2 = stack.pop()
const e1 = stack.pop()
e1.out.out = e2.start
stack.push(new Fragment(e1.start, e2.out))
从 stack 出栈两个 NFA 片段,然后将其首尾相连后构建新的 NFA 片段再入栈。
其他处理过程就不详细介绍了,感兴趣可以看下代码。
NFA 的执行
NFA 的执行过程就是用当前状态来比对字符串的当前字符,如果匹配就继续比对下一个状态和下一个字符,否则匹配失败。
不过由于 NFA 的不确定性,所以可能会同时有多个匹配的状态。
我这里就简单粗暴了,直接让当前所有的状态都进行比对,仍然满足条件的下一个状态再继续参与下一轮比对。一次只跟踪一条路径,匹配失败后再回溯肯定也是可以的,不过就要复杂很多了。
代码在:simulator.js - luobotang/nfa
总结
综上,正则表达式的执行,可以通过构建等价的 NFA,然后执行 NFA 来匹配输入的字符串。真实的 JavaScript 中的正则表达式拥有更多的特性,其正则表达式引擎也更加复杂。
希望通过我的介绍,能够让你对正则表达式有了更多的了解。当然,水平有限,讲得不当的地方在所难免,欢迎指正。
最后,感谢阅读!
