

本文是 《使用 RxJS + Redux 管理应用状态》系列第三篇文章,将介绍我们在使用 Redux 时的困惑,如何重新思考 Redux 定下的范式,以及我们能为此做出的努力。返回第一篇:使用 redux-observable 实现组件自治
本系列的文章地址汇总:
为什么我们需要 Redux?
首先要明确的是,Redux 并不是 React 独有的一个插件,它是顺应前端组件化开发潮流而诞生的一种状态管理模型,你在 Vue 或者 Angular 中也可以使用这个模型。
目前,大家都比较认可的是,某一时刻的应用或者组件状态,将对应此时应用或者组件的 UI:
UI = f(state)
那么,在前端组件化开发的时候,就需要思考两个问题:
- 状态来源
- 状态管理
组件所具有的状态,一搬来源于两个方面:
- 自身具有的状态:例如一个 Button 组件自身含有一个计数状态 count,表示自己被点击的次数。
- 外部注入的状态:例如一个 Modal 组件,就需要由外部注入一个是否显示的状态 visible。React 将外部注入的状态称为 props。
状态源为组件输送了其需要的状态,进而,组件的外观形态也得到了确认。在简单工程和简单组件中,我们思考了状态来源也就行了,如果引入额外的状态管理方案(例如我们为一个使用 Redux 管理一个按钮组件的状态),反而会加重每个组件的负担,造成了多余的抽象和依赖。
而对于大型前端工程和复杂组件来说,其往往具有如下特点:
- 数据复杂
- 组件丰富
在这种场景下,朴素的状态管理就显得捉襟见肘了,主要体现在下面几个方面:
- 当组件层级过深时,如何优雅得呈递组件需要的状态,或者说组件如何更方便取得自己需要的状态
- 如何回溯到某个状态
- 如何更好的测试状态管理
Redux 正是要去解决这些问题,从而让大型前端工程的状态更加可控。Redux 提出了一套约定模型,让状态的更新和派发都集中了:
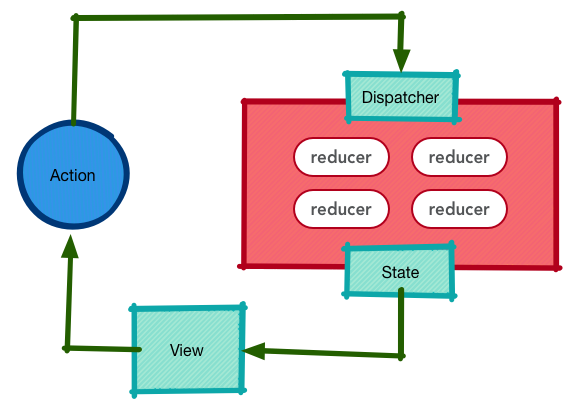
Redux 所使用的模型是受到了 Elm 的启发:
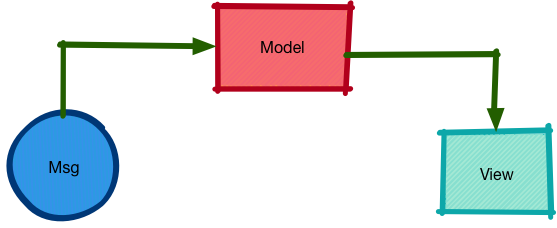
在 Elm 中,流动于应用中的是消息(msg) :一个由**消息类型(type)所标识,并且携带了内容(payload)**的数据结构。消息决定了数据模型(model)怎么更新,而数据又决定了 UI 形态。
而在 Redux 中,消息被称替代为动作(action),并且使用 reducer 来描述状态随行为的变迁。另外,与 Elm 不同的是,Redux 专注于状态管理,而不再处理视图(View),因此 ,Redux 也不是分型的(关于分型架构的介绍,可以看 的博文)。
在了解到 Redux 的利好,或者被 Redux 的流行所吸引后,我们引入 Redux 作为应用的状态管理器,这让整个应用的状态变动都变得无比清晰,状态在一条链路上涌动,我们甚至可以回到或者前进到某个状态。然而,Redux 就真的完美无缺吗?
不完美的 Redux
Redux 当然不完美,它最困扰我们的就是下面两个方面:
- 啰嗦的样板代码
- 低下的异步任务处理能力
假定前端需要从服务端拉取一些数据并进行展示,在 Redux 的模式下,完成从数据拉取到状态更新,就需要经历:
(1)定义若干的 action type:
const FETCH_START = 'FETCH_START'
const FETCH_SUCCESS = 'FETCH_SUCCESSE'
const FETCH_ERROR = 'FETCH_ERROR'
(2)定义若干 action creator,这里假定我们使用 redux-thunk 驱动异步任务:
const fetchSuccess = data => ({
type: FETCH_START,
payload: { data }
})
const fetchError = error => ({
type: FETCH_ERROR,
payload: { error }
})
const fetchData = (params) => {
return (dispatch, getState) => {
return api.fetch(params)
.then(fetchSuccess)
.catch(fetchError)
}
}
(3)在 reducer 中,对不同 action type,通过 switch-case 声明不同的状态更新方式:
function reducer(state = initialState, action) {
const { type, payload } = action
switch(action.type){
case FETCH_START: {
return { ...state, loading: true }
}
case FETCH_SUCCESS: {
return { ...state, loading: false, data: payload.data }
}
case FETCH_ERROR: {
return { ...state, loading: false, data: null, error: payload.error}
}
}
}
这个流程带来的问题是:
- 个人开发不够专注:工程中,我们是分散管理 action type、action 及 reducer 的,走完一套流程,需要在当中不停的跳跃,思路不够集中。
- 多人协作不够高效:同样是因为 action type、action 及 reducer 的分散,多人协作时就会出现名字冲突,相似业务的流程重复等问题。这对我们的应用状态设计提出了比较高的要求。优秀的设计是状态易于定位,变迁流程清晰,无冗余状态,而低下的设计就会让状态膨胀难于定位,变迁流程错综复杂,冗余状态随处可见。
怎么用好 Redux
当我们受困于 Redux 的负面影响时,切到其他的状态管理方案(例如 mobx 或者 mobx-state-stree),也不太现实,一方面是迁移成本大,一方面你也不知道新的状态管理方案是否就是银弹。但是,对 Redux 的负面影响无动于衷或者忍气吞声,也只会让问题越滚越大,直到失控。
在开始讨论如何更好地 Redux 之前,我们需要明确一点,样板代码和异步能力的缺乏,是 Redux 自身设计的结果,而非目的,换句话说,Redux 设计出来,并不是要让开发者去撰写样本代码,或者去纠结怎么处理异步状态更新。
我们需要再定义一个角色,让他来代替我们去写样板代码,让他给予我们最优秀的异步任务处理能力,让他负责一切 Redux 中恶心的事儿。因此,这个角色就是一个让 Redux 变得更加优雅的框架,至于如何创建这个角色,需要我们从单个组件开始,重新梳理下应用形态,并着眼于:
- 如何打掉 Redux 的样板代码
- 如何更优雅地处理异步任务
组件的样子
一个组件的生态大概是这样的:
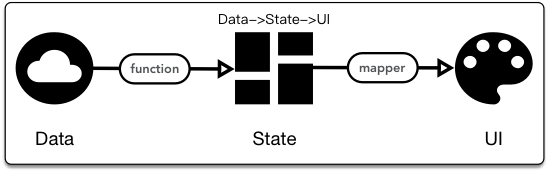
即:数据经处理形成页面状态,页面状态决定 UI 渲染。
应用的样子
而组件生态(UI + 状态 + 状态管理方式)的组合就构成了我们应用:
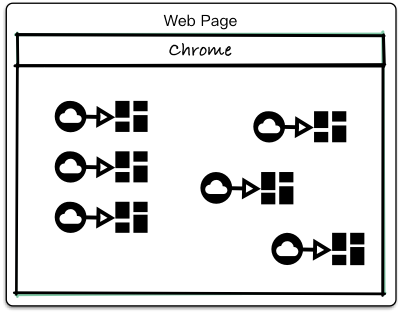
这里组件生态特意只展示了数据到状态这一步,因为 Redux 处理的正是这个部分。我们暂且可以定义数据到状态的过程为 flow,即一个业务流的意思。
应用划分
借鉴于 Elm,我们可以按数据模型对应用进行划分:
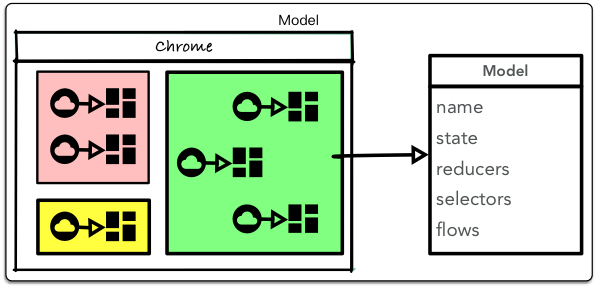
其中,模型具有的属性有:
name: 模型名称state:模型的初始状态reducers:处理当前模型状态的 stateselectors:服务于当前模型的 state selectorsflows:当前模型涉及的业务流(副作用)
这个经典的划分模型正是 Dva 的应用划分手段,只是模型属性略有不同。
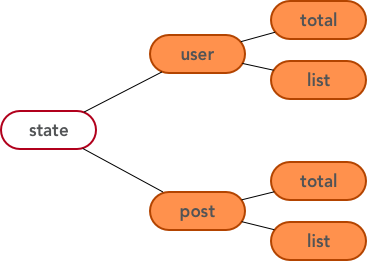
假定我们创建了 user 模型和 post 模型,那么框架将挂载他们的状态到 user 和 post 状态子树下:
约定 —— 打掉样板代码
有了模型这个概念后,框架就能定义一系列的约定去减少样板代码的书写。首先,我们回顾下以前我们是怎么定义的一个 action type 的:
- action 名称
- 指定一个 namespace 防止名字冲突
例如,我们这样定义用户数据拉取相关的 action type:
const FETCH = 'USRE/FETCH'
const FETCH_SUCCESS = 'USER/FETCH_SUCCESSE'
const FETCH_ERROR = 'USER/FETCH_ERROR'
其中, FETCH 对应的是一个异步 拉取数据的 action,FETCH_SUCCESS 和 FETCH_ERROR 则对应两个同步修改状态的 action。
同步 action 约定
对于同步的、不包含副作用的 action,我们直接将其呈递到 reducer,是不会破坏 reducer 纯度的。 因此,我们不妨约定: model 下 reducer 的名字映射一个直接对状态操作的 action type:
SYNC_ACTION_TYPE = MODEL_NAME/REDUCER_NAME
例如下面这个 user model:
const userModel = {
name: 'user',
state: {
list: [],
total: 0,
loading: false
},
reducers: {
fetchStart(state, payload) {
return { ...state, loading:true }
}
}
}
当我们派发了一个类型为 user/fetchStart 的 action 之后,action 就带着其 payload 进入到 user.fetchStart 这个 reducer 下,进行状态变更。
异步 action 约定
对于异步的 action,我们就不能直接在 reducer 进行异步任务处理,而 model 中的 flow 就是异步任务的集装箱:
ASYNC_ACTION_TYPE = MODEL_NAME/FLOW_NAME
例如下面这个 model:
const user = {
name: 'user',
state: {
list: [],
total: 0,
loading: false
},
flows: {
fetch() {
// ... 处理一些异步任务
}
}
}
如果我们在 UI 里面发出了个 user/fetch,由于 user model 中存在一个名为 fetch 的 flow,那么就进入到这个flow 中进行异步任务的处理。
状态的覆盖与更新
如果每个状态的更新都去撰写一个对应的 reducer 就太累了,因此,我们可以考虑为每个模型定义一个 change reducer,用于直接更新状态:
const userModel = {
name: 'user',
state: {
list: [],
pagination: {
page: 1,
total: 0
},
loading: false
},
reducers: {
change(state, action) {
return { ...state, ...action.payload }
}
}
}
此时,当我们派发了下面的一个 action,就将能够将 loading 状态置为 true:
dispatch({
type: 'user/change',
payload: {
loading: true
}
})
但是,这种更新是覆盖式的,假定我们想要更新状态中的当前页面信息:
dispatch({
type: 'user/change',
payload: {
pagination: { page: 1 }
}
})
状态就会变为:
{
list: [],
pagination: {
page: 1
},
loading: false
}
pagination 状态被整个覆盖掉了,其中的总数状态 total 就丢失了。
因此,我们还要定义一个 patch reducer,意为对状态的补丁更新,它只会影响到 action payload 中声明的子状态:
import { merge } from 'lodash.merge'
const userModel = {
name: 'user',
state: {
list: [],
pagination: {
page: 1,
total: 0
},
loading: false
},
reducers: {
change(state, action) {
return {
{ ...state, ...action.payload }
}
},
patch(state, action) {
return deepMerge(state, action.payload)
}
}
}
现在,我们尝试只更新分页:
dispatch({
type: 'user/patch',
payload: {
pagination: { page: 1 }
}
})
新的状态就是:
{
list: [],
pagination: {
page: 1,
total: 0
},
loading: false
}
注意:这里的实现不是生产环境的实现,直接使用 lodash 的 merge 是不够的,实际项目中还要进行一定改造。
异步任务的组织
Dva 使用了 redux-saga 进行副作用(主要是异步任务)的组织,Rematch 则使用了 async/await 进行组织。从长期的实践来看,我更偏向于使用 redux-observable,尤其是在其 1.0 版本的发布之后,更是带来了可观察的 state$,使得我们能更加透彻地实践响应式编程。我们回顾下前文中提到的该模式的好处:
- 统一数据源,observable 之间可组合
- 声明式编程,代码直爽简洁
- 优秀的竞态处理能力
- 测试友好
- 便于实现组件自治
因此,对于模型异步任务的处理,我们选择 redux-observable:
const user:Model<UserState> = {
name: 'user',
state: {
list: [],
// ...
},
reducers: {
// ...
},
flows: {
fetch(flow$, action$, state$) {
// ....
}
}
}
与 epic 的函数签名略有不同的是,每个 flow 多了一个 flow$ 参数,以上例来说,它就相当于:
action$.ofType('user/fetch')
这个参数便于我们更快的取到需要的 action。
处理加载态与错误态
前端工程中经常会有错误展示和加载展示的需求,
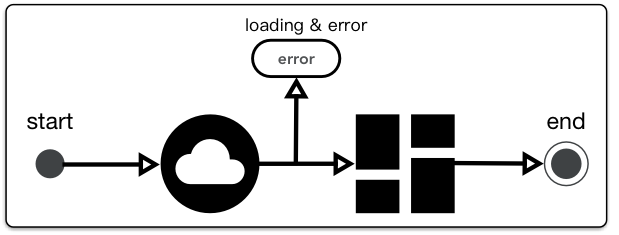
如果我们手动管理每个模型的加载态和错误态就太麻烦了,因此在根状态下,单独划分两棵状态子树用于处理加载态与错误态,这样,便于框架去治理加载与错误,开发者直接在状态树上取用即可:
- loading
- error
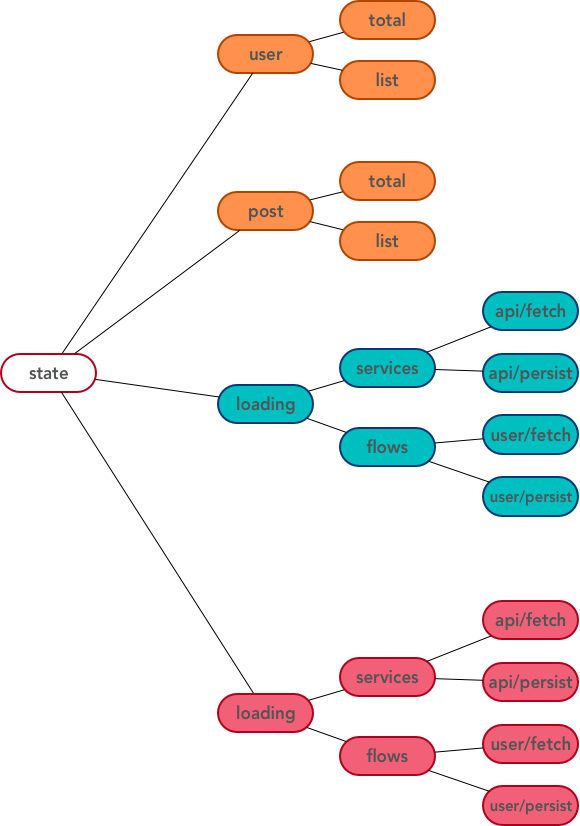
如图,加载态和错误态还需要根据粒度进行划分,有大粒度的 flow 级别,用于标识一个 flow 是否正在进行中;也有小粒度的 service 级别,用于标识某个异步服务是否在进行中。
例如,若:
loading.flows['user/fetch'] === true
即表示 user model 下的 fetch flow 正在进行中。
若:
loading.services['/api/fetchUser'] === true
即表示 /api/fetchUser 这个服务正在进行中。
响应式的服务治理
前端调用后端服务操纵数据是一个广泛的需求,因此,我们还希望所谓的中间角色(框架)能够在我们的业务流中注入服务,完成服务和应用状态的交互:观察调用状况,自动捕获调用异常,适时地修改应用 loading 态和 error 态,方便用户直接在顶层状态取用服务运行状况。
另外,在响应式编程的范式下,框架提供的服务治理,在处理服务的成功和错误时应该也是响应式的,即成功和错误将是预定义的流(observable 对象),从而让开发者能更好的利用到响应式编程的能力:
const user:Model<UserState> = {
name: 'user',
state: {
list: [],
total: 0
},
reducers: {
fetchSuccess(state, payload) {
return { ...state, list: payload.list, total: payload.total }
},
fetchError(state, payload) {
return { ...state, list:[] }
}
},
flows: {
fetch(flow$, action$, state$, dependencies) {
const { service } = dependencies
return flow$.pipe(
withLatestFrom(state$, (action, state) => {
// 拼装请求参数
return params
}),
switchMap(params => {
const [success$, error$] = service(getUsers(params))
return merge(
success$.pipe(
map(resp => ({
type: 'user/fetchSuccess',
payload: {
list: resp.list,
total: resp.total
}
}))
),
error$.pipe(
map(error => ({
type: 'user/fetchError'
}))
)
)
})
)
}
}
}
reobservable
上面的种种思考,概括下来其实就是 Dva architecture + redux-observable,前者能够打掉 Redux 冗长啰嗦的样板代码,后者则负责异步任务治理。
比较遗憾的是,Dva 没有使用 redux-observable 进行副作用管理,也没有相关插件实现使用 redux-observable 或者 RxJS 进行副作用管理,并且,通过 Dva 暴露的 hook 去实现一个 redux-observable 的 Dva 中间件也颇为不畅,因此,笔者尝试撰写了一个 reobservable 来实现上面提到框架,它与 Dva 不同的是:
- 只关注应用状态,不涉及组件路由的其他生态
- 集成 loading 和 error 处理
- 使用 redux-observable 而不是 redux-saga 处理副作用
- 响应式的服务处理,支持应用自定义服务细节
如果你的应用使用了 Redux,你苦于 Redux 种种负面影响,并且你还是一个响应式编程和 RxJS 的爱好者,你可以尝试下 reobservable。但是如果你偏爱 saga,或者 async await,你还是应该选择 Dva 或者 Rematch,术业有专攻。
参考资料
关于本系列
- 本系列将从介绍 redux-observable 1.0 开始,阐述自己在结合 RxJS 到 Redux 中的心得体会。涉及内容会有 redux-observable 实践介绍,redux-observable 实现原理探究,最后会介绍下自己当前基于 redux-observble + dva architecture 的一个 state 管理框架 reobservable。
- 本系列不是 RxJS 或者 Redux 入门,不再讲述他们的基础概念,宣扬他们的核心优势。如果你搜索 RxJS 不小心进到了这个系列,对 RxJS 和 FRP 程序设计产生了兴趣,那么入门我会推荐:
- learnrxjs.io
- Andre Staltz 在 egghead.io 上的一系列课程
- 程墨的 《深入浅出 RxJS》
- 本系列更不是教程,只是介绍自己在 Redux 中应用 RxJS 的一些思路,希望更多人能指出当中存在的误区,或者交流更优雅的实践。
- 由衷的感谢实践路上一些师兄的帮助,尤其感谢腾讯云的 questguo 学长在模式上的指导。reobservable 脱胎于腾讯云 questguo 主导的 React 框架 —— TCFF,期待未来 TCFF 的开源。
- 感谢小雨的设计支援。
