

本套系列博客从真实商业环境抽取案例进行总结和分享,并给出Spark源码解读及商业实战指导,请持续关注本套博客。版权声明:本套Spark源码解读及商业实战归作者(秦凯新)所有,禁止转载,欢迎学习。
- Spark商业环境实战-Spark内置框架rpc通讯机制及RpcEnv基础设施
- Spark商业环境实战-Spark事件监听总线流程分析
- Spark商业环境实战-Spark存储体系底层架构剖析
- Spark商业环境实战-Spark底层多个MessageLoop循环线程执行流程分析
- Spark商业环境实战-Spark二级调度系统Stage划分算法和最佳任务调度细节剖析
- Spark商业环境实战-Spark任务延迟调度及调度池Pool架构剖析
- Spark商业环境实战-Task粒度的缓存聚合排序结构AppendOnlyMap详细剖析
- Spark商业环境实战-ExternalSorter 外部排序器在Spark Shuffle过程中设计思路剖析
- Spark商业环境实战-ShuffleExternalSorter外部排序器在Spark Shuffle过程中的设计思路剖析
- Spark商业环境实战-Spark ShuffleManager内存缓冲器SortShuffleWriter设计思路剖析
- Spark商业环境实战-Spark ShuffleManager内存缓冲器UnsafeShuffleWriter设计思路剖析
- Spark商业环境实战-Spark ShuffleManager内存缓冲器BypassMergeSortShuffleWriter设计思路剖析
- [Spark商业环境实战-Spark Shuffle 聚合拉取读数据(Reduce Task)过程深入剖析]
- Spark商业环境实战-StreamingContext启动流程及Dtream 模板源码剖析
- Spark商业环境实战-ReceiverTracker与BlockGenerator数据流接收过程剖析
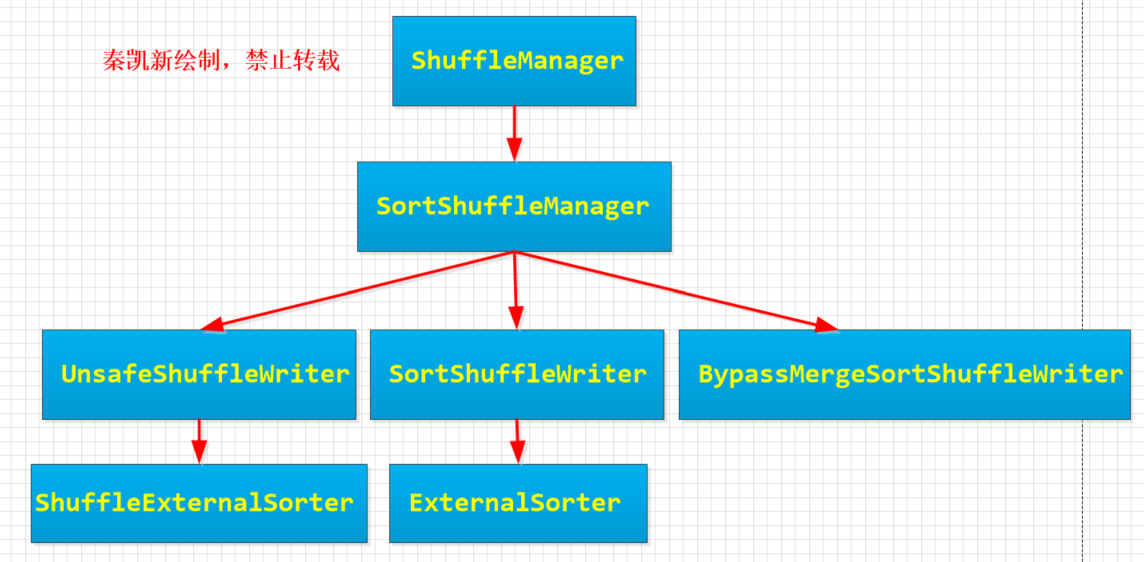
1 从ShuffeManager讲起
一张图我已经用过多次了,不要见怪,因为毕竟都是一个主题,有关shuffle的。英文注释已经很详细了,这里简单介绍一下:
- 目前只有一个实现 SortShuffleManager。
- SortShuffleManager依赖于ShuffleWriter提供服务,通过ShuffleWriter定义的规范,可以将MapTask的任务中间结果按照约束的规范持久化到磁盘。
- SortShuffleManager总共有三个子类, UnsafeShuffleWriter,SortShuffleWriter ,BypassMergeSortShuffleWriter。
官方英文介绍如下:
* Pluggable interface for shuffle systems. A ShuffleManager is created in SparkEnv on the
* driver and on each executor, based on the spark.shuffle.manager setting. The driver
* registers shuffles with it, and executors (or tasks running locally in the driver) can ask * to read and write data.
* NOTE: this will be instantiated by SparkEnv so its constructor can take a SparkConf and
* boolean isDriver as parameters.
ShuffeManager代码欣赏,可以看到,只是定义了标准规范:
/**
* Register a shuffle with the manager and obtain a handle for it to pass to tasks.
*/
def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle
/** Get a writer for a given partition. Called on executors by map tasks. */
def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext): ShuffleWriter[K, V]
/**
* Get a reader for a range of reduce partitions (startPartition to endPartition-1, inclusive).
* Called on executors by reduce tasks.
*/
def getReader[K, C](
handle: ShuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext): ShuffleReader[K, C]
/**
* Remove a shuffle's metadata from the ShuffleManager.
* @return true if the metadata removed successfully, otherwise false.
*/
def unregisterShuffle(shuffleId: Int): Boolean
/**
* Return a resolver capable of retrieving shuffle block data based on block coordinates.
*/
def shuffleBlockResolver: ShuffleBlockResolver
/** Shut down this ShuffleManager. */
def stop(): Unit
}
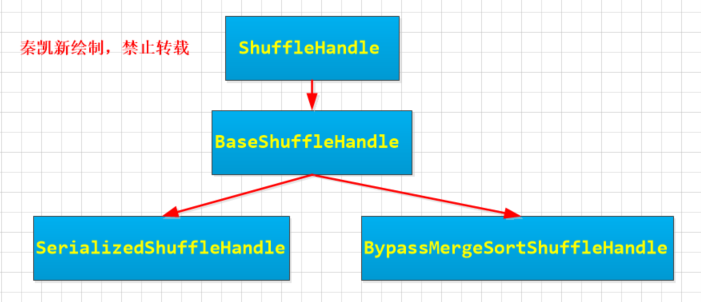
- SortShuffleManager依赖于ShuffleHandle样例类,主要还是负责向Task传递Shuffle信息。一个是序列化,一个是确定何时绕开合并和排序的Shuffle路径。
2 再讲MapStatus
MapStatus的主要作用用于给ShuffleMapTask返回TaskScheduler的执行结果。看看MapStatus的代码:
* Result returned by a ShuffleMapTask to a scheduler. Includes the block manager address that the
* task ran on as well as the sizes of outputs for each reducer, for passing on to the reduce tasks.
-
特质MapStatus,其中location和getSizeForBlock一个表示地址,一个表示大小。
private[spark] sealed trait MapStatus { /** Location where this task was run. */ def location: BlockManagerId /** * Estimated size for the reduce block, in bytes. * * If a block is non-empty, then this method MUST return a non-zero size. This invariant is * necessary for correctness, since block fetchers are allowed to skip zero-size blocks. */ def getSizeForBlock(reduceId: Int): Long } -
伴生对象用于实现压缩
private[spark] object MapStatus { def apply(loc: BlockManagerId, uncompressedSizes: Array[Long]): MapStatus = { if (uncompressedSizes.length > 2000) { HighlyCompressedMapStatus(loc, uncompressedSizes) } else { new CompressedMapStatus(loc, uncompressedSizes) } }
3 三聊SortShuffleWriter(重磅戏)
- 针对MapTask输出提供了数据排序,聚合以及缓存功能
- SortShuffleWriter底层借助于PartionedAppendOnlyMap和PartionPairBuffer功能,实现数据的写入缓存,以及在缓存中排序,聚合等。
3.1 SortShuffleWriter核心成员介绍
-
blockManager: SparkEnv.get.blockManager子组件实现数据存储服务统一对外管理器
-
sorter :御用成员ExternalSorter,实现内存中缓冲,排序,聚合功能。
-
mapStatus :数据输出的规范,方便reducer查找。
-
dep :handle.dependency传入,主要是ShuffleDependency相关属性。
-
shuffleBlockResolver :索引文件生成器
* Create and maintain the shuffle blocks' mapping between logic block and physical file location. * Data of shuffle blocks from the same map task are stored in a single consolidated data file. * The offsets of the data blocks in the data file are stored in a separate index file. * * We use the name of the shuffle data's shuffleBlockId with reduce ID set to 0 and add ".data" * as the filename postfix for data file, and ".index" as the filename postfix for index file.
3.2 SortShuffleWriter的Write方法(神来之笔)
- ShuffleDependency的mapSideCombine属性为True时,则允许使用aggregator和keyOrdering属性进行聚合和排序。 否则则不传递。这也说明一个问题,究竟是使用PartitionedAppendOnlyMap还是使用PartitionedPairBuffer。
- insertAll实现了map任务的输出记录插入到内存。
- ShuffleBlockId:获取Shuffle的数据文件,主要是MapTask的输出文件句柄。
- writePartitionedFile:重要的伙伴,开始迭代Map端的缓存数据到磁盘,该过程可能会合并溢出到磁盘的中间数据,归并排序后迭代写入正式的Block文件到磁盘。
- writeIndexFileAndCommit:为最终的Block正式文件建立对应的索引,此索引会记录不同分区Id对应的偏移值,以便reducer任务前来拉取。
3.3 SortShuffleWriter的精彩代码段欣赏
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records) ======> 神来之笔
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
val tmp = Utils.tempFileWith(output)
try {
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID) ======> 神来之笔
val partitionLengths = sorter.writePartitionedFile(blockId, tmp) ======> 神来之笔
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp) ======> 神来之笔
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
} finally {
if (tmp.exists() && !tmp.delete()) {
logError(s"Error while deleting temp file ${tmp.getAbsolutePath}")
}
}
}
3.4 SortShuffleWriter的Write方法示意图,可谓一图道尽所有
不废话,这张图简直画的太好了,望原图作者看到留言于我。

3.5 SortShuffleWriter伴生对象shouldBypassMergeSort
是不是需要绕过聚合和排序。spark.shuffle.sort.bypassMergeThreshold默认值是200.
* We cannot bypass sorting if we need to do map-side aggregation.
private[spark] object SortShuffleWriter {
def shouldBypassMergeSort(conf: SparkConf, dep: ShuffleDependency[_, _, _]): Boolean = {
// We cannot bypass sorting if we need to do map-side aggregation.
if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
false
} else {
val bypassMergeThreshold: Int = conf.getInt("spark.shuffle.sort.bypassMergeThreshold", 200)
dep.partitioner.numPartitions <= bypassMergeThreshold
}
}
4 SortShuffleManager 如何扛霸子
根据需要选择想要的UnsafeShuffleWriter 还是BypassMergeSortShuffleWriter 还是SortShuffleWriter,然后执行内存缓冲排序集合。
SortShuffleManager因此是组织者,对外暴露的管理者
/** Get a writer for a given partition. Called on executors by map tasks. */
override def getWriter[K, V](
handle: ShuffleHandle,
mapId: Int,
context: TaskContext): ShuffleWriter[K, V] = {
numMapsForShuffle.putIfAbsent(
handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps)
val env = SparkEnv.get
handle match {
case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf)
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
bypassMergeSortHandle,
mapId,
context,
env.conf)
case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
}
}
5 总结
本节内容是作者投入大量时间优化后的内容,采用最平实的语言来剖析 ShuffeManager之统一存储服务SortShuffleWriter设计思路。
秦凯新 于深圳
