

在前端的富交互编辑中,稳定的撤销 / 重做功能是用户安全感的一大保障。设计实现这样的特性时有哪些痛点,又该如何解决呢?StateShot 凝聚了我们在这个场景下的一些思考。
背景
如果产品经理拍脑袋决定要求给你的表单加上个支持撤销的功能,怎样一把梭把需求撸出来呢?最简单直接的实现不外乎是个这样的 class:
class History {
push () {}
redo () {}
undo () {}
}
每次 push 的时候塞进去一个页面状态的全量深拷贝,然后在 undo / redo 的时候把相应的状态拿出来就可以了。是不是很简单呢?把所有的状态依次存储在一个线性的数组里,维护一个指向当前状态的数组索引足矣,就像这样:
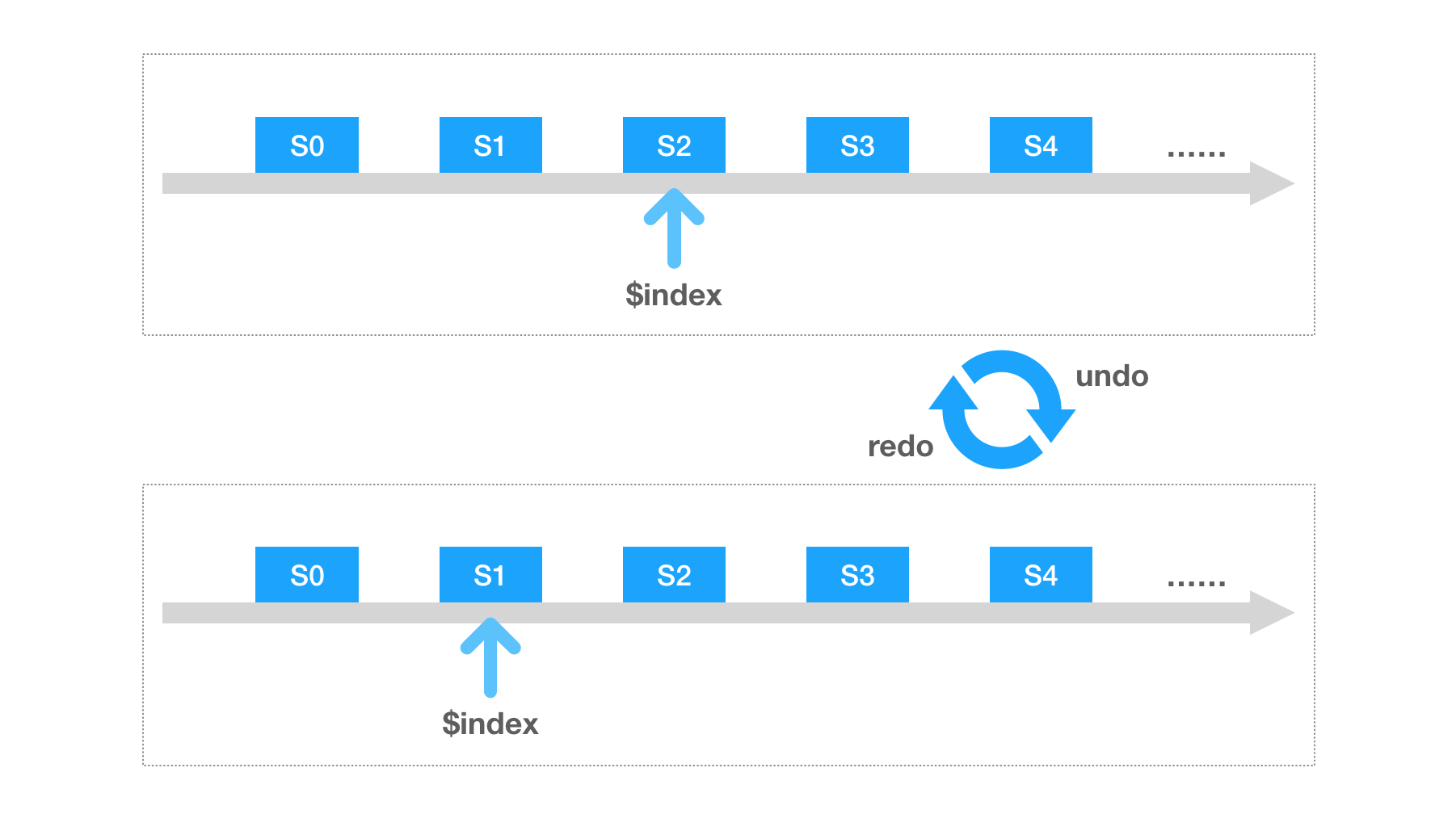
不过,在真实世界的场景里,下面这些地方都是潜在的挑战:
- 增量存储 - 多条记录里不变的数据,没必要重复吧?
- 按需记录 - 编辑集中在同一页,没必要记录其他页面的状态吧?
- 异步记录 - 别管用户事件多琐碎,只管 push 就行吧?
- 可定制性 - 别的地方也要用,耦合具体的数据结构不太好吧?
- 存取速度 - 尽量不能卡吧?
这些关注点中,存储空间和存取速度是与实际体验联系最紧密的指标。而对于这两点,有一个堪称银弹的方案能够给出理论上最优雅的实现:Immutable 数据结构。基于这样的数据结构,每次状态变更都能在常数时间内生成对新状态的引用,这些引用之间天生地共享未改变的内容:这就是所谓的结构共享了。
但是,Immutable 对架构的侵入性是很高的。只有在整个项目自底向上全盘采用它封装的 API 来更新状态时,你才有可能实现理想中的 undo / redo 能力。许多 Vue 甚至原生 JS 场景下司空见惯的形如 state.x = y 的直接赋值操作,都需要重写才能适配——这时还技术债的成本不亚于推倒重来。
所以,我们有没有 Plan B 呢?
设计
在技术面试时,「深拷贝数据」可能已经是道烂大街的题了。这个问题有种让很多人嗤之以鼻的写法:
copy = JSON.parse(JSON.stringify(data))
它比起掘金里各种文章中「优雅的递归」实现的深拷贝,看起来不过是个奇技淫巧而已。但是,这种实现具备一个特别的性质:对于序列化出的字符串,我们很容易计算出它的哈希值。由于相同的状态具备相同的哈希,故而只要我们用哈希值作为 key,就可以很容易地用一个 Map 把每个序列化后的状态「去重」,从而实现「多个相同状态只占用一份存储空间」的特性了。把这一操作的粒度细化到状态树中的每一个节点,我们就能得到一棵结构一致的树,其中每个节点存储的都是原节点的哈希值:
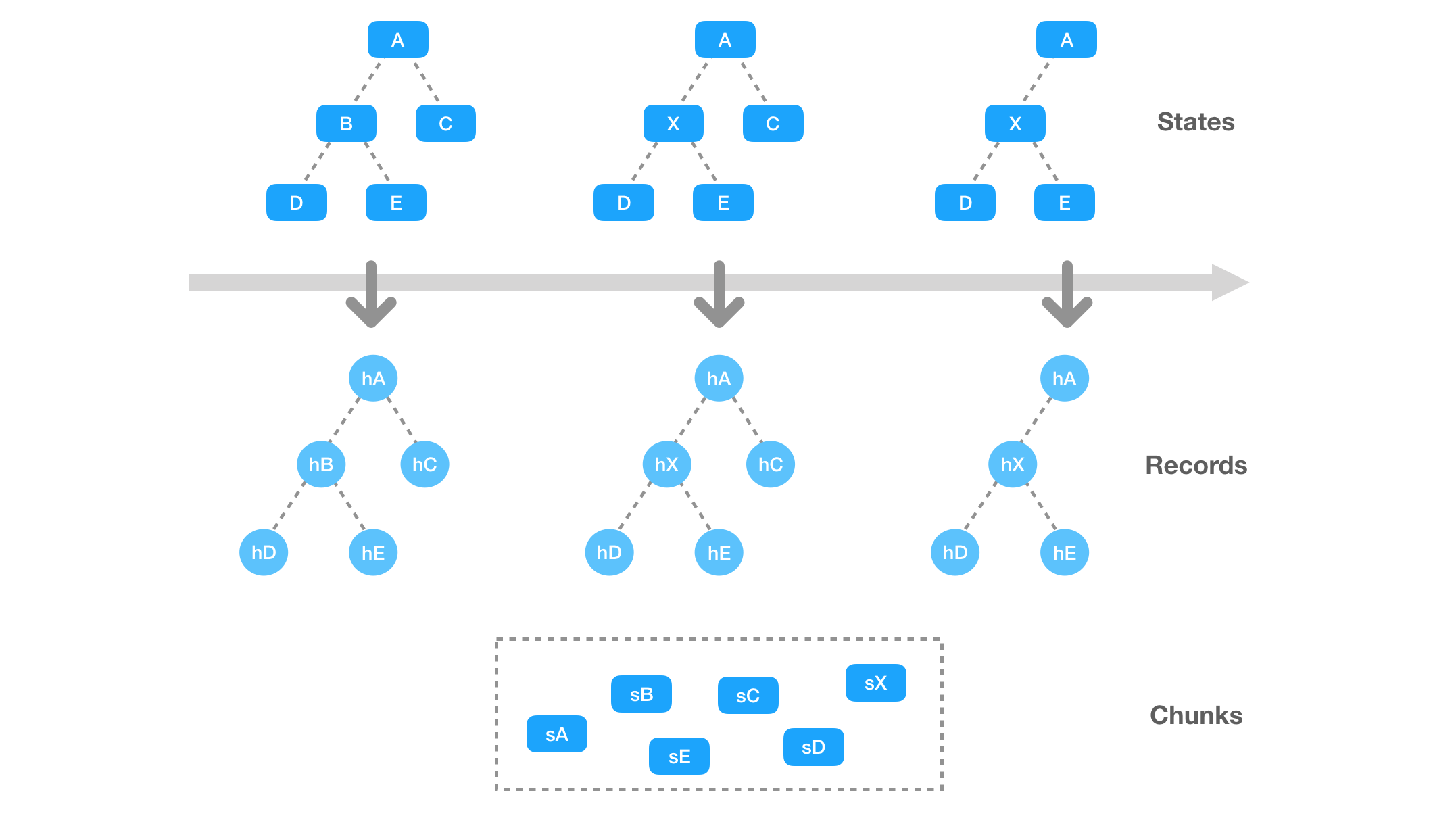
这样,只要将 State 树的结构转换为存储哈希索引的 Record 树,再将每个节点序列化为 Chunk 数据块,就能够实现节点级的结构共享了。
使用
从这个简单的理念出发,我们造出了 StateShot 这个轮子。它的使用方式非常简单:
import { History } from 'stateshot'
const state = { a: 1, b: 2 }
const history = new History()
history.pushSync(state) // 更常用的 push API 是异步的
state.a = 2 // mutation!
history.pushSync(state) // 再记录一次状态
history.get() // { a: 2, b: 2 }
history.undo().get() // { a: 1, b: 2 }
history.redo().get() // { a: 2, b: 2 }
StateShot 会自动帮你处理好数据 → 哈希 → 数据的转换。不过这个示例看起来似乎没什么特别的?确实,从保证易用性的角度出发,我们把它设计成可以不做任何定制地直接使用,但你也可以 Opt-In 地按需进行更细粒度的优化。这就带来了规则驱动的概念。通过指定规则,你可以告诉 StateShot 如何遍历你的状态树。一条规则的结构大致如下:
const rules = [{
match: Function,
toRecord: Function,
fromRecord: Function
}]
const history = new History({ rules })
在规则中,我们可以指定更细粒度的分块优化。例如对于下面的场景:

我们轻微移动这个图片节点的位置,而它的 src 字段保持不变。对于这张 Windows XP 的桌面原图 Bliss,这个节点做了 Base64 后体积达到了 30M 的量级,如果在每次移动时都全量存储一个它的新状态,显然是个很大的负担。这时,你可以通过配置 StateShot 的规则,将单个节点分拆为多个不同的 Chunk,从而将 src 字段与节点的其它字段分离存储,实现单个节点内更细粒度的结构共享:

这对应于形如这样的规则:
const rule = {
match: node => node.type === 'image',
toRecord: node => ({
// 将节点的 src 与其它字段拆分为两个 chunk
chunks: [{ ...node, src: null }, node.src],
})
fromRecord: ({ chunks }) => ({
// 从 chunk 数组中恢复出原状态
...chunks[0], src: chunks[1]
})
}
另外一个很常见的场景出现在状态树存在「多页」的时候:如果用户只在某一个页面上编辑,那么全量对所有的页面状态做哈希计算显然是不合算的。作为优化,StateShot 支持指定一个 pickIndex 来决定要对根节点下的哪个子节点做哈希,这时其它页面(即根节点的直接子节点)状态直接沿用上一条记录相应位置的浅拷贝即可。这时虽然同样存储了全量状态,但记录历史状态的开销即可得到显著的降低:
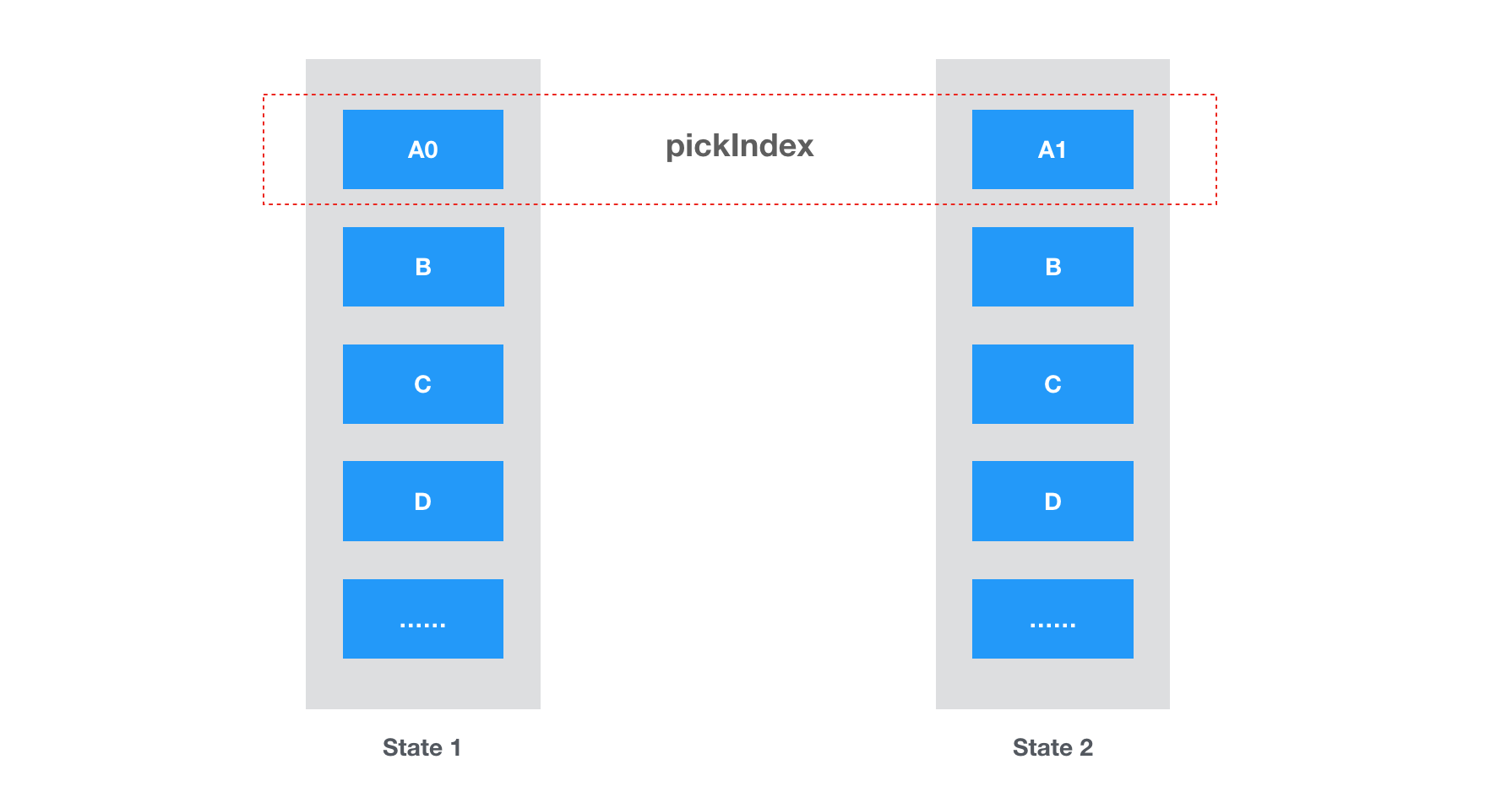
这对应的 API 同样很简单:
history.push(state, 0) // 指定仅对 state 的第一个子节点做哈希
差点忘了,它的 API 还支持链式调用和 Promise,在 8012 年它们可能是「优雅」的标配了吧:
// 最终 get 前的 undo 与 redo 都是 O(1) 的
const state = history.undo().undo().redo().undo().get()
// 异步的节流延时可以通过 delay 参数控制
hisoty.push().then(/* ... */)
总结
在稿定科技自研的编辑器中,我们已经在使用 StateShot 了。在 benchmark 里,它做到了比原有的历史记录模块存取速度约 3 倍的提升(这主要是拜新的 MurmurHash 哈希算法替代了原有的 SHA-1 所赐)。并且,在基于它定制了细粒度的规则后,对单个元素连续做多次拖拽等细微改动的场景下,快照的内存占用也降低了 90% 以上。总的来说,它提供了:
- 开箱即用的无侵入性 API
- 对链式调用与 Promise 的支持
- 规则驱动的定制与优化策略
- < 2KB min + gzipped 的体积
- 100% 的测试覆盖率
StateShot 已经在稿定科技的官方 GitHub 组织下开源,欢迎有历史状态管理需求的同学尝鲜体验 XD
对了,我们长期欢迎有兴趣探索 Web 技术潜力的前端同学加入,有意请邮件 xuebi at gaoding.com 哈
