

基础知识
数据类型
NULL 值为NULL的值。
INTEGER 带符号的整数。
REAL 浮点值。
TEXT 文本字符串。
BLOB 为blob数据,完全根据它的输入存储。
uniqueidentifier 用于存储GUID的值。
运算符
-
算数运算符
- 加+、 减-、乘*、除/、取模%
-
比较运算符
- ==、=、!=、<>、>、<、>=、<=、!<、!>
-
逻辑运算符
- AND 和
- BETWEEN 用于在给定最小值和最大值范围内一系列值中搜索
- EXISTS 存在
- IN 用于判断某个值是否在一系列指定列表的值中
- NOT IN 同上
- LIKE 用于把某个值与使用通配符运算符的相似值比较
- GLOB 同上,区别在于它对大小写敏感
- NOT 否定运算符
- OR 用于结合一个SQL语句的where之居中的多个条件
- IS NULL 与NULL值相比较
- IS 与=相似
- IS NOT 与!=相似
- || 连接两个不容的字符串,得到一个新的字符串
- UNIQUE 搜索指定表中的每一行,确保唯一性。
-
位运算符
假设变量A=60,变量B=13:
A = 0011 1100
B = 0000 1101
A&B = 0000 1100 A|B = 0011 1101 ~A = 1100 0011- & (A&B)得到12,即0000 1100
- | (A|B)得到61,即0011 1101
- ~ (~A)得到-61,即1100 0011 一个有符号二进制数的补码形式。
- << 二进制左移 A<<2 得到240,即为1111 0000
- .>> 二进制右移 A>>2 得到15,即为0000 1111
创建表
创建一个TABLE_NAME表,PKKEY为主键
CREATE TABLE TABLE_NAME(PKKEY INT PRIMARY KEY NOT NULL, PKUSER UNIQUEIDENTIFIER NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL);
CREATE TABLE IF NOT EXISTS TABLE_NAME(PKKEY UNIQUEIDENTIFIER NOT NULL, PKUSER UNIQUEIDENTIFIER NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL);
删除表
DROP TABLE TABLE_NAME;
insert语句
INSERT INTO TABLE_NAME (PKKEY, PKUSER, NAME, AGE, ADDRESS, SALARY) VLAUES (VALUE1, VALUE2, VALUE3, VALUE4, VALUE5, VALUE6);
INSERT INTO TABLE_NAME VALUES (VALUE1, VALUE2, VALUE3, VALUE4, VALUE5, VALUE6);
INSERT INTO TABLE_NAME (PKKEY, PJUSER, ... SALARY) SELECT colum1, colum2, ... columN FROM TABLE_NAME2 WHERE CONDITION;
select语句
SELECT PKKEY, PKUSER, ... SALARY FROM TABLE_NAME;
SELECT * FROM TABLE_NAME;
update语句
UPDATE TABLE_NAME SET PKKEY=value1, PKUSER=value2, ... WHERE condition;
delete语句
DELETE FROM TABLE_NAME WHERE condition;
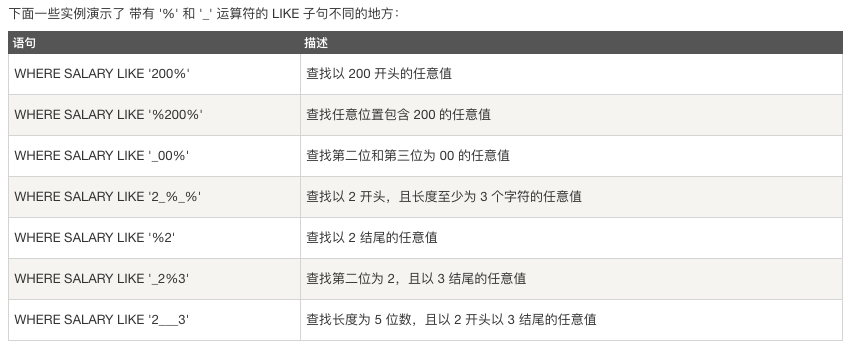
like子句
like运算符是用来匹配通配符指定模式的文本值。如果搜索表达式与模式表达式匹配,like运算符将返回真true,也就是1。
与like运算符一起使用的两个通配符 百分号(%) 与下划线(_)
百分号(%) 代表零个、一个或多个数字或字符。
下划线(_) 代表一个单一的数字或字符。可以组合使用。
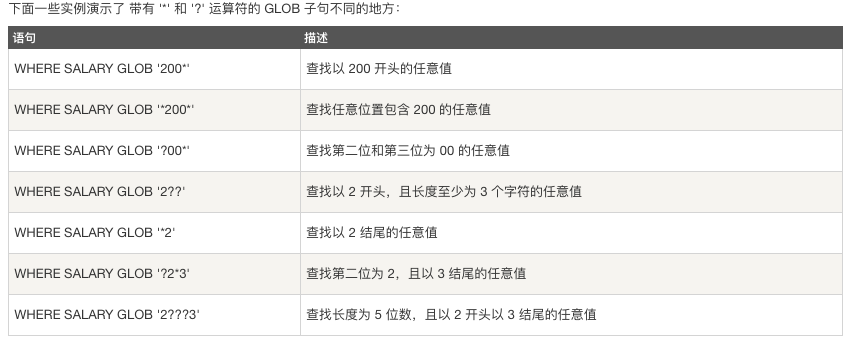
Glob子句
GLOB 运算符是用来匹配通配符指定模式的文本值。如果搜索表达式与模式表达式匹配,GLOB运算符将返回真true,也就是1。
与like不同的是,GLOB大小写敏感。 与GLOB一起使用的两个通配符是星号(*)、问号(?)
星号(*) 代表零个、一个或者多个数字或字符。
问号(?) 代表一个单一的数字或字符。
Limit子句
limit子句用于限制由SELECT语句返回的数据数量。
SELECT * FROM TABLE_NAME LIMIT [rows];
SELECT * FROM TABLE_NAME LIMIT [rows] OFFSET [row num];
Order By子句
Order by子句是用来基于一个或多个列按升序或降序顺序排列的数据。
SELECT * FROM TABLE_NAME WHERE condition ORDER BY NAME [ASC | DESC];
Group By子句
Group By子句用于与SELECT语句一起使用,来对该列下的相同的数据进行分组。
在SELECT语句中,GROUP BY子句放在WHERE子句之后,放在ORDER BY子句之前。
SELECT NAME, SUM(SALARY) FROM TABLE_NAME WHERE condition GROUP BY NAME ORDER BY SUM(SALARY) DESC;
Having 子句
HAVING 子句允许指定条件来过滤将出现在最终结果中的分组结果。
WHERE子句在所选列上设置条件,而HAVING子句则在有GROUP BY子句创建的分组上设置条件。
SELECT NAME, SUM(SALARY) FROM TABLE_NAME WHERE condition GROUP BY NAME HAVING count(NAME) < 2 ORDER BY SUM(SALARY);
Distinct关键字
distinct关键字与SELECT语句一起使用,来消除所有重复的记录,并只获取唯一一次记录。
SELECT DISTINCT NAME FROM TABLE_NAME WHERE condition;
高级知识
约束
约束是在表的数据列上强制执行的规则。这些是用来限制可以插入到表中的数据类型。约束可以是列级或者表级。列级约束仅适用于列,表级约束被应用到整个表。
- NOT NULL 约束:确保某列不能有
NULL值 - DEFAULT 约束:当某列没有指定值时,为该列提供默认值
- UNIQUE 约束:确保某列中的所有值是不同的
- PRIMARY KEY 约束: 唯一标识数据库表中的各行/记录
- CHECK 约束:确保某列中的所有值满足一定条件
默认情况下,列可以保存NULL值,但如果不想某列有NUll值,只要在该列上定义NOT NULL约束。DEFAULT约束在INSERT INTO 语句没有提供一个特定的值时,为列提供一个默认值。UNIQUE约束防止在一个特定列存在两个记录具有相同的值。PRIMARY KEY约束唯一标识数据库表中的每个记录。在一个表中可以有多个UNIQUE列,但只能有一个主键。
CREATE TABLE TABLE_NAME(ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL UNIQUE, SALARY REAL DEFAULT 50000.00);
Join子句
Join子句用于结合两个或多个数据库表的记录。JOIN是一种通过共同值来结合两个表中字段的手段。
- 交叉连接 CROSS JOIN
- 内连接 INNER JOIN
- 外连接 OUTER JOIN
交叉连接: 把第一个表的每一行与第二个表的每一行进行匹配。如果两个输入表分别有x和y行,则结果表有x * y行。由于交叉连接可能产生非常大的表,使用须谨慎。
SELECT Acolum1, Acolum2, Bcolum2 FROM TABLEA CROSS JOIN TABLEB;
内连接: 根据连接谓词结合两个表的列值来创建一个新的结果表。查询会把表1中的每一行与表2中的每一行进行比较,找到所有满足连接谓词的行的匹配对。当满足连接谓词时,A和B行的每个匹配对的列值会合并成一个结果行。内连接是默认的连接类型。INNER关键字是可选的。
SELECT Acolum1, Acolum2, Bcolum2 FROM TABLEA [INNER] JOIN TABLEB ON condition;
为了避免冗余,可以使用USING表达式声明内连接。这个表达式指定一个或多个列的列表:
SELECT ... FROM TABLEA JOIN TABLEB USING (colum1, ...) ...
自然连接(NATURAL JOIN)类似于JOIN...USING,只是它会自动测试存在两个表中的每一列的值之间相等值:
SELECT ... FROM TABLEA NATURAL JOIN TABLEB ...
外连接: 是内连接的扩展,虽然SQL标准定义了三种类型的外连接: LEFT, RIGHT, FULL, 但SQLite只支持左外连接(LEFT OUTER JOIN)。
外连接(OUTER JOIN)声明条件的方法与内连接是相同的,使用ON, USING或NATURAL关键字来表达。最初的结果表以相同的方式进行计算。一旦主连接计算完成,外连接将一个或两个表中任何未连接的行,合并进来,外连接的列使用NULL值,将他们附加到结果表中。
SELECT Acolum1, Acolum2, Bcolum1 FROM TABLEA LEFT OUTER JOIN TABLEB ON condition...
SELECT ... FROM TABLEA LEFT OUTER JOIN TABLEB USING (colum1, ...) ...
SELECT ... FROM TABLEA NATURAL LEFT OUTER JOIN TABLEB ...
Unions子句
UNION 子句用于合并两个或者多个SELECT语句的结果,不返回任何重复的行。
为了使用UNION,每个SELECT被选择的列数必须是相同的,相同数目的列表达式,相同的数据类型,并确保他们有相同的顺序,但它们不必具有相同的长度。
SELECT colum1, colum2 FROM TABLEA WHERE condition UNION SELECT colum1, colum2 FROM TABLEA WHERE condition;
UNION ALL 子句,用于结合两个SELECT语句的结果,包括重复行。
SELECT colum1, colum2 FROM TABLEA WHERE condition UNION ALL SELECT colum1, colum2 FROM TABLEA WHERE condition;
别名
暂时把表或列重命名为另一个名字,被称为别名。使用表别名是指在一个特定的SQLite语句中,重命名表,重命名是临时的改变,在数据库中实际的表的名称是不会改变的。关键字AS可以被省略。
表的别名:
SELECT colum1, colum2... FROM TABLE_NAME AS TABLEA WHERE condition;
列的别名:
SELECT colum1 AS columA FROM TABLE_NAME WHERE condition;
触发器
触发器(Trigger) 是数据库的回调函数,它会在指定的数据库事件发生时自动执行/调用。
- SQLite的触发器可以指定在特定的数据库表发生
DELETE、INSERT或UPDATE时触发,或在一个或多个指定表的列发生更新时触发。 - SQLite只支持
FOR EACH ROW触发器,没有FOR EACH STATEMENT触发器。因此,明确指定FOR EACH ROW是可选的。 - 如果提供
WHEN子句,则只针对WHEN子句为真的指定行执行SQL语句。如果没有提供WHEN子句,则针对所有行执行SQL语句。 BEFORE或AFTER关键字决定何时执行触发器动作,决定是在关联行的插入、修改或删除之前或者之后执行触发器动作。- 当触发器相关联的表删除时,自动删除触发器。
CREATE TRIGGER trigger_name [BEFORE|AFTER] event_name ON table_name BEGIN -- Trigger logic goes here ... END;
在这里,event_name可以是在所提到的表table_name上的INSERT、DELETE和UPDATE数据库操作。亦可在表名后选择指定 FOR EACH ROW。
下面是在UPDATE操作上在表的一个或多个指定列上创建触发器的语法:
CREATE TRIGGER trigger_name [BEFORE|AFTER] UPDATE OF column_name ON table_name BEGIN --Trigger logic goes here ... END;

可以从sqlite_master表中列出所有的触发器。
SELECT name FROM sqlite_master WHERE type='trigger';

删除触发器:
DROP TRIGGER trigger_name;
补充:
FOR EACH ROW 是操作语句每影响到一行的时候就出发一次,也就是说删除/更新了10行,就触发了10次。
FOR EACH STATE 一条操作语句就触发一次,有时没有被影响的行也执行。
SQLite只实现了FOR EACH ROW的触发。
when的用法:
CREATE TRIGGER trigger_name AFTER UPDATE OF id ON table1 FOR EACH ROW WHEN new_id>30 BEGIN update table_2 set id = new_id WHERE table_2 id = OLD_ID END;
索引Index
索引(Index) 是一种特殊的查找表,数据库搜索引擎用来加快数据检索。简单的说就是,索引是一个指向表中数据的指针。
CREATE INDEX index_name ON table_name;
单列索引是一个只基于表的一个列上创建的索引。
CREATE INDEX index_name ON table_name (column_name);
唯一索引不仅为了性能,同时也为了数据的完整性。唯一索引不允许任何重复的值插入到表中。
CREATE UNIQUE INDEX index_name ON table_name (column_name);

组合索引 是基于一个表的两个或多个列上创建的索引。
CREATE INDEX index_name ON table_name (column1, column2);
创建一个单列索引还是组合索引,要考虑到在作为查询过滤的条件的WHERE子句中使用非常频繁的列。
列出所有索引:
SELECT * FROM sqlite_master WHERE type='index';
删除索引:
DROP INDEX index_name;
下面情况下避免使用索引:
- 索引不应该使用在较小的表上。
- 索引不应该使用在哟频繁的大批量的更新或插入操作的表上。
- 索引不应该使用在含有大量的NULL值的列上。
- 索引不应该使用在频繁操作的列上。
Alter命令
ALTER TABLE 命令不通过执行一个完整的转储和数据的重载来修改已有的表。可以重命名,还可以再已有的表中添加额外的列。
在SQLite中,出来重命名表和在已有的表中添加列,ALTER TABLE命令不支持其他操作。
重命名表名:
ALTER TABLE table_name RENAME new_table_name;
添加额外的列:
ALTER TABLE table_name ADD COLUMN column char(50);
测试发现,不支持直接添加带有unique约束的列:

可以先直接添加一列数据,然后添加unique索引(唯一索引)。
