

少长咸集,群贤毕至。--《王羲之・兰亭集序》
目标文件
目标文件结构
程序员编写的是源代码,而计算机运行的则是CPU能识别的机器指令,因此必须要有一系列工具或程序来将源代码转化为机器指令,这个转化的过程需要经历编译和链接两个主要阶段。所谓编译就是将源代码文件转化为中间的目标文件(Object file)。目标文件的后缀一般为.o。iOS系统的目标文件也是一种mach-o格式的文件,mach-o文件的头部结构体:struct mach_header中的filetype成员字段用来描述当前文件的类型,目标文件所对应的类型是MH_OBJECT。目标文件中的布局结构和内容和可执行文件中的布局结构和内容非常相似,编译后形成的目标文件中的代码段(__TEXT Segment)中的节(__text Section) 中的内容存放的是已经被编译为机器指令的二进制代码了。下面就是一个目标文件的布局结构:
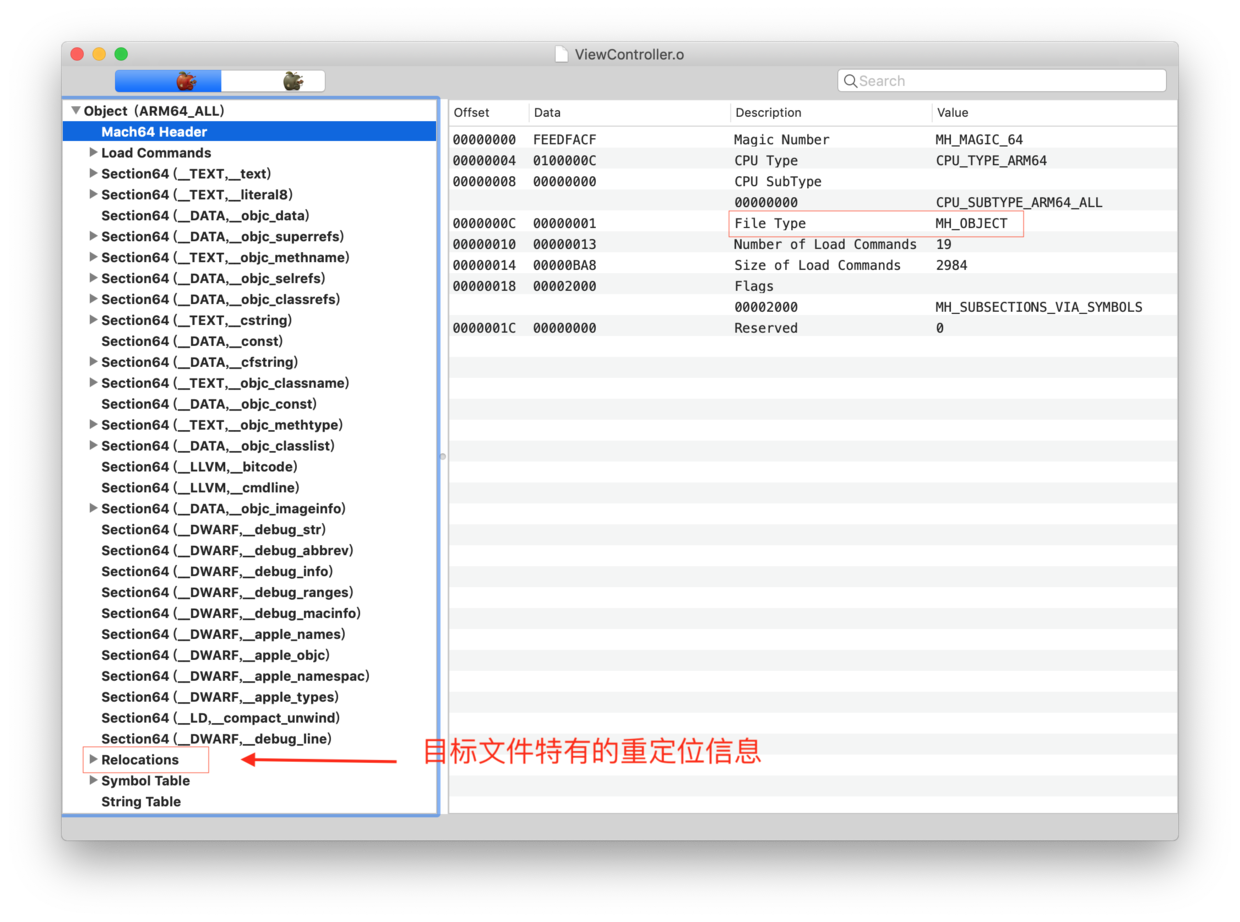
重定位表(Relocation table)
系统的编译操作是针对一个个源文件的独立行为。通常情况下在编写程序时会引用其他源文件或者动态库中定义的函数或者类方法以及全局变量,因此在编译阶段所有的外部引用符号的地址是无法被确定的,此时生成的目标文件中的段(Segment)中的节(Section)中的外部函数调用指令的操作数部分以及外部全局变量符号的地址的值都将是0。在后续的链接过程中需要调整这些指令的操作数的值来进行重定位(Relocation),为此系统在编译的目标文件中的对那些有外部符号引用的节(Section)中都会建立一个重定位表(Relocation table)。这个重定位表中的每个条目会将所有需要进行重定位的指令或者数据访问的位置信息以及引用的外部符号的信息记录起来,以便在链接时进行更新处理。下面的图表展示了这个结构:
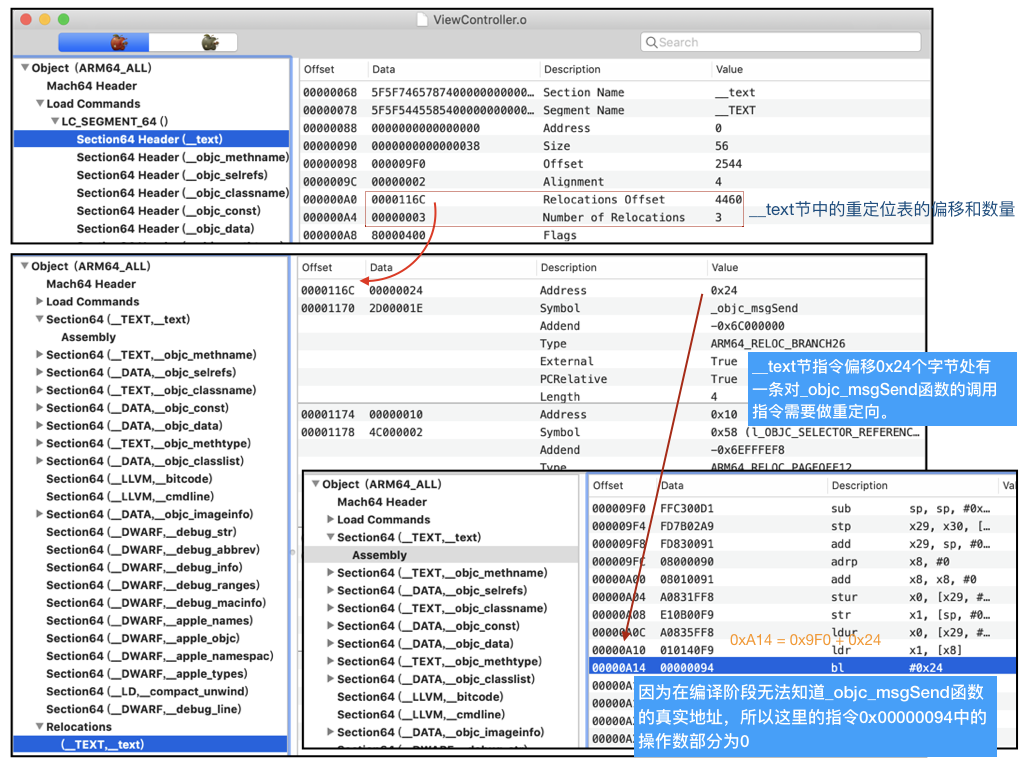
现假设工程中有一个源文件test.m,其内容如下:
int testfn(NSString *str)
{
return [str lenght];
}
这个源文件中有一个OC方法调用[str length],方法在编译时会转化为对objc_msgSend函数的调用,但是因为objc_msgSend函数的定义在动态库libobjc.dylib中,因此对于源文件test.m来说这是一个外部符号,在生成函数调用指令时编译器无法确定objc_msgSend函数相对于当前指令的偏移量,因此指令中的函数调用无法确定操作数的值,就如上图的调用指令0x00000094一样只有操作码而操作数被暂时设置为0。
为了在链接时能够对所有的外部符号引用进行重定位,描述机制代码__text的Section结构:
//如果是64位系统则是section_64
struct section { /* for 32-bit architectures */
char sectname[16]; /* name of this section */
char segname[16]; /* segment this section goes in */
uint32_t addr; /* memory address of this section */
uint32_t size; /* size in bytes of this section */
uint32_t offset; /* file offset of this section */
uint32_t align; /* section alignment (power of 2) */
uint32_t reloff; /* 重定位入口表的偏移 */
uint32_t nreloc; /* 重定位的条目数量 */
uint32_t flags; /* flags (section type and attributes)*/
uint32_t reserved1; /* reserved (for offset or index) */
uint32_t reserved2; /* reserved (for count or sizeof) */
};
中的reloff和nreloc两个字段用来描述这个节中所有需要进行重定位的信息。就如上面的图例中的"Relocations Offset"和"Number of Relocations"中描述的是重定位表在文件的0x116c的偏移处,一共有3个需要进行重定位的信息。重定位表的条目是一个结构体:
struct relocation_info {
int32_t r_address; /* offset in the section to what is being
relocated */
uint32_t r_symbolnum:24, /* symbol index if r_extern == 1 or section
ordinal if r_extern == 0 */
r_pcrel:1, /* was relocated pc relative already */
r_length:2, /* 0=byte, 1=word, 2=long, 3=quad */
r_extern:1, /* does not include value of sym referenced */
r_type:4; /* if not 0, machine specific relocation type */
};
这个结构体在<mach-o/reloc.h>中被定义,它的结构定义我将在后续的文档中会有详细的介绍。这里大家只要了解一下这个结构中主要包括的是需要进行重定向的指令的位置,以及外部引用的符号信息。就如上图中展示的一样。
简要的说一下链接步骤所做的事情
当编译器对所有的源代码文件编译完成后,接下来的步骤就是链接了。链接的主要功能就是将所有目标文件中的各个相同段和节的信息依次连接起来拼装成一个单独的可执行文件。同时还会将所有目标文件中需要Relocation的部分的指令进行调整,因为此时可以知道每个引用符号的位置了。在链接时系统会分析每个目标文件中的依赖信息,也就是说链接成一个可执行文件中各段各节的内容总是无依赖的目标文件放在前面而有依赖的目标文件放置在后面。
基地址重定向(Rebase)
在链接时还有一个重要的信息就是添加基地址重定向(Rebase)信息。原因是进程执行时每个引用的动态库以及可执行文件所加载的基地址是不一样的。而是一个随机的行为。而我们的源代码或者系统实现中有很多地方保存的是一个绝对地址值,就比如runtime中每个OC类的方法列表中的IMP部分的值就是一个函数地址指针。在对程序进行编译链接时会为生成的可执行文件或者动态库指定一个默认的虚拟基地址,后续所有生成的代码中的绝对地址值都是基于这个虚拟基地址来构建的。我们可以在可执行文件的mach-o文件的名字为__TEXT的这个LC_SEGMENT或者LC_SEGMENT_64中的load command定义中找到程序加载的默认的基地址。名字为__TEXT的结构体struct segment_command中的vmaddr数据成员中的值保存的就是程序加载的默认基地址值,一般情况下可执行程序的默认基地址都是0x100000000。
而刚才说了虽然程序生成时的基地址是固定的,但是的每次程序加载到内存的基地址是不一样的,而是一个随机值。因此程序加载的真实基地址和程序生成时的基地址值之间就有一个slide值,也就是地址差值。但是因为程序中很多地方的地址值都是以生成的虚拟基地址为基础的,所以在程序运行加载时需要对这部分函数地址进行基地址重定向(rebase)处理。为了实现rebase的能力,可执行文件的mach-o文件中会构造出一个LC_DYLD_INFO或者LC_DYLD_INFO_ONLY的load command,这个load command的结构描述是一个struct dyld_info_command,详细描述可以在<mach-o/loader.h>中看到。这个结构体中的rebase_off和rebase_size两个字段分别用来描述需要进行rebase的表的偏移以及需要进行rebase的数量。rebase表中记录着所有需要进行rebase的信息,这样当进程在加载时就会根据默认基地址的值和真实加载的基地址值之间的slide值来调整这部分内容的值。下面就是rebase段的内容:
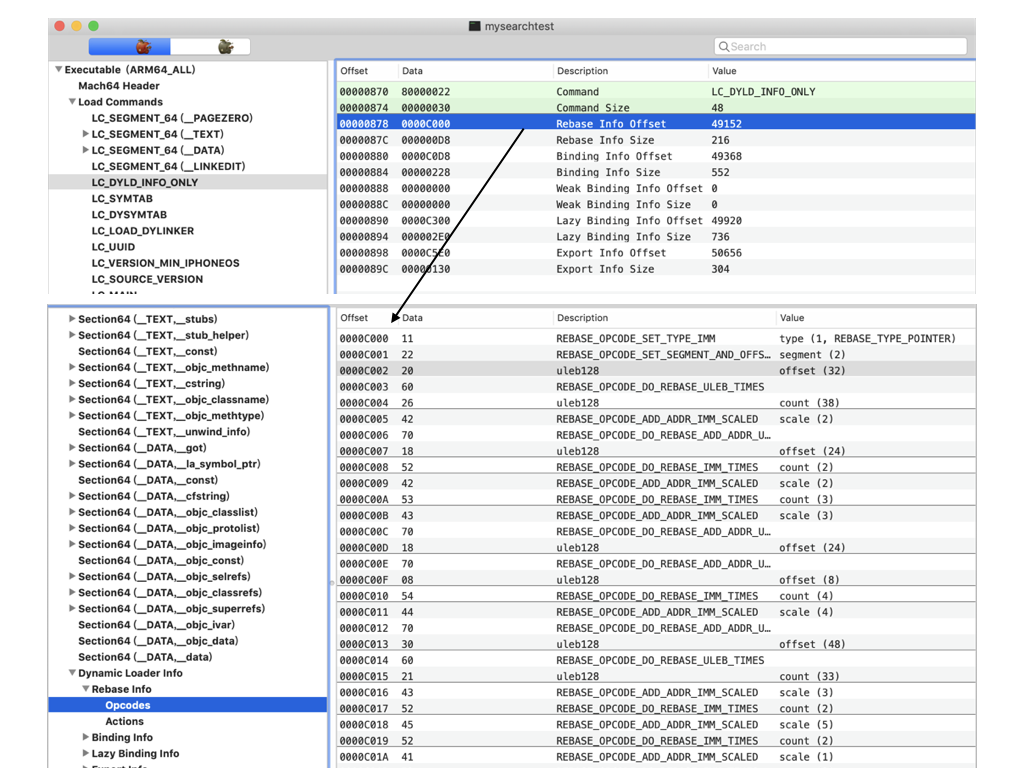
可以看出在LC_DYLD_INFO_ONLY中不仅有需要进行rebase的地址信息,还有弱绑定和懒加载的信息。每个rebase条目中记录着rebase需要进行的操作(opcode)以及需要进行rebase的地址所在的段以及段内偏移值等信息。关于rebase的详细信息我将会在后面的文章中继续介绍。这里就不再赘述了。
静态库代码链接规则
应用程序链接的过程最开始是以主程序工程中的所有目标文件为单位进行的,无论这个工程中的目标文件中的代码是否有被引用或者被调用都会链接进可执行程序中。在链接的过程中,如果发现某个符号没有在主程序工程中被定义,那么就会去导入的动态库文件或者静态库文件中查找。如果符号在动态库中被定义那么就会为动态库的中的符号(这里假设符号就是某个函数) 生成stub代码并且将引用信息放入导入符号表以便在后续程序运行时动态的加载真实的函数地址。而如果发现符号在静态库中被定义那么就会按如下的规则进行处理:
- 默认情况下是以静态库中的目标文件为单位进行链接的,只要某个目标文件中定义的符号被主程序引用,则这个目标文件中的所有代码都会链接到可执行程序中去。如果这个目标文件中又引用了其他目标文件中定义的符号则链接会进行递归处理。如果静态库中某个目标文件中的代码没有被任何其他地方引用则这个目标文件将不会链接到可执行程序中去。
- OC类的方法列表的构建是在编译阶段完成的,但是对其中的方法调用都是在运行时动态确定的,所以在代码中的任何对静态库中定义的OC类的方法调用都不会被认为是对符号的引用,都不会产生链接行为。除非在代码中引用了这个OC类本身才会产生链接行为,此时会把静态库中定义的所有OC类的方法都链接到可执行程序中(因为OC类的方法列表在编译阶段已经构建完成)。也就是说静态库中的OC类定义的方法要么就全部都链接进可执行程序中,要么就一个方法也不会被链接。
假设某个静态库中定义了一个名字为CA的OC类:
//类中定义了2个方法。
@interface CA:NSObject
-(void)fn1
-(void)fn2;
@end
//假如在同一个文件中还定义了CB类
@interface CB:NSObject
@end
假设主程序中有两处会使用到静态库中定义的CA类的地方:
//虽然这里CA作为一个参数,并且里面调用了对应的方法,但是在链接时仍然不会将CA类链接进来,因为这个是一个运行时的间接方法调用过程。
void foo1(CA *p)
{
[p fn1];
}
//假设没有foo2这个函数则CA类中的代码是不会链接进可执行程序中的。
void foo2()
{
//只有明确的使用CA类来创建对象时,才表明是对CA类的引用。这样才会将CA类中的所有方法都链接进可执行程序中,这里虽然没有调用fn2但是fn2的实现也会被链接进去。
CA *p = [CA new];
[p fn1];
}
void main()
{
foo1(nil);
foo2();
}
因为CB和CA类在同一个.m文件中实现,所以即使CB类没有被引用,但是根据上述的按文件为单位的链接规则,CB类仍然会被链接到可执行程序中,除非CB类和CA类不在同一个文件中实现。
-
静态库中的任意OC类所定义的分类方法默认情况下都不会链接到可执行程序中,即使这个方法在主程序中调用了也是如此(这也就是为什么当我们调用静态库中某个类的分类方法时总会报方法找不到的异常,原因上面的OC类方法调用都是运行时被确定而不是编译时就被确定)。 除非是在主程序工程中的
Other Linker Flags中添加 -ObjC 选项。这个选项的意思是会把所有静态库中定义的OC类的方法都链接到可执行程序中去,而不管这个类是否有被引用,也不管方法是否是分类方法。 -
如果静态库中定义的C语言函数没有被任何地方引用则这个函数将不会被链接到可执行程序中去。而如果相同文件中其他符号被引用则根据以文件为单为的链接规则即使这个函数没有被引用也会链接到可执行程序中去。
-
如果静态库中定义的C++类的的某个普通的成员函数没有被任何地方引用则这个成员函数将不会被链接到可执行程序中去。如果这是一个虚函数则只要这个类被引用则即使这个虚函数没有被引用也会链接到可执行程序中去,因为虚函数需要在编译时参与虚表的构建。而如果相同文件中其他符号被引用则根据以文件为单为的链接规则即使这个文件中C++类中定义的成员函数没有被引用也会链接到可执行程序中去。
-
如果静态库中某文件定义的Swift类没有被任何地方引用则不会链接到可执行程序中,如果类本身或者类中的方法被引用则类中定义的所有方法都会链接到可执行程序中去。对于Swift类定义的extension中的扩展方法而言如果扩展方法是和类方法定义在同一个文件,则一旦类被引用则扩展方法也会被链接到可执行程序中。如果扩展方法定义在不同的文件中,则只有扩展方法被调用时才会被链接进可执行程序。
Swift类的方法调用并不是和OC类的方法调用在运行时才决定的,而是采用了类似C++虚函数的机制来实现多态的功能以及和虚函数的调用机制相似,而Swift中对extension的实现则是直接采用函数地址调用,也就是说extension中定义的函数就和普通的C函数非常相似。
- 如果我们在
Other Linker Flags中添加**-all_load选项,则主程序工程会把所有静态库中的所有代码全部链接到可执行程序中去,而不管代码是以何种语言实现的代码,以及不管代码是否被引用和调用。如果我们只想对某个静态库中的所有代码进行全部链接处理,则可以在Other Linker Flags中添加-force_load 静态库路径**来实现。
这也就是为什么当我们调用在静态库中定义的分类方法时如果不使用-Objc或者-all_load选项时,会出现方法不被识别的调用异常了。但是这两个选项的另外一个问题是不管静态库中的类是否被引用都会将代码链接到可执行程序中去,从而增加了可执行程序的尺寸。
- 我们可以在主程序工程的项目中将DEAD_CODE_STRIPPING(Dead Code Stripping) 开关开启,用来优化可执行程序中的代码。需要注意的是这个开关是在代码链接完成后的优化行为。当这个开关被打开时链接器会删除可执行程序中所有没有被调用的C函数以及C++中的普通成员函数。但是不会删除没有被调用到的OC类的成员方法,以及Swift类的成员方法,以及C++类中的虚函数。在XCODE中这个开关默认是开启的。
从上面的规则中可以看出采用静态库的形式进行链接可以减少可执行文件的尺寸。有的时候我们的应用可能会引用一些第三方的静态库,而这些第三方的静态库的尺寸非常的庞大(比如地图类的SDK,可能有好几百兆)。可是当应用最后生成的可执行文件却不是那么的大。现在的应用往往都集成了很多的功能,尤其是一些大型应用的尺寸都已经达到好几百M了,这么大尺寸的应用下载安装的时间往往很长,而且还会消耗用户的网络流量,甚至会影响程序的启动时间。
静态库的作用
每当我们build一个工程项目时,系统总是会先将所有源代码编译为目标文件,再将目标文件链接为可执行程序。即使是我们改变其中某一个文件中的源代码,而其他文件没有改变也是如此。因此为了加快编译速度,有些文件将不再以源代码的形式提供,而是可以将一部分目标文件先集中起来形成一个静态库。这样就可以对这部分文件略过编译而直接进行链接从而加快编译的速度。
对于iOS系统来说因为不支持第三方以动态库的形式集成到我们的工程中以及上传到appstore。而第三方提供的库因为安全和知识产权以及保密的特性不大可能以源代码的形式提供给我们,而是以静态库的形式提供给我们。
可见静态库的作用主要是为了加快编译速度、进行模块划分、以及代码安全的功能。静态库是一个编译产生的结果,而动态库则是编译链接产生的结果。静态库的组成其实是一个个目标文件。下面就是静态库和普通源代码参与编译和连接的流程图,从流程图中可以看出静态库存在的作用和意义:
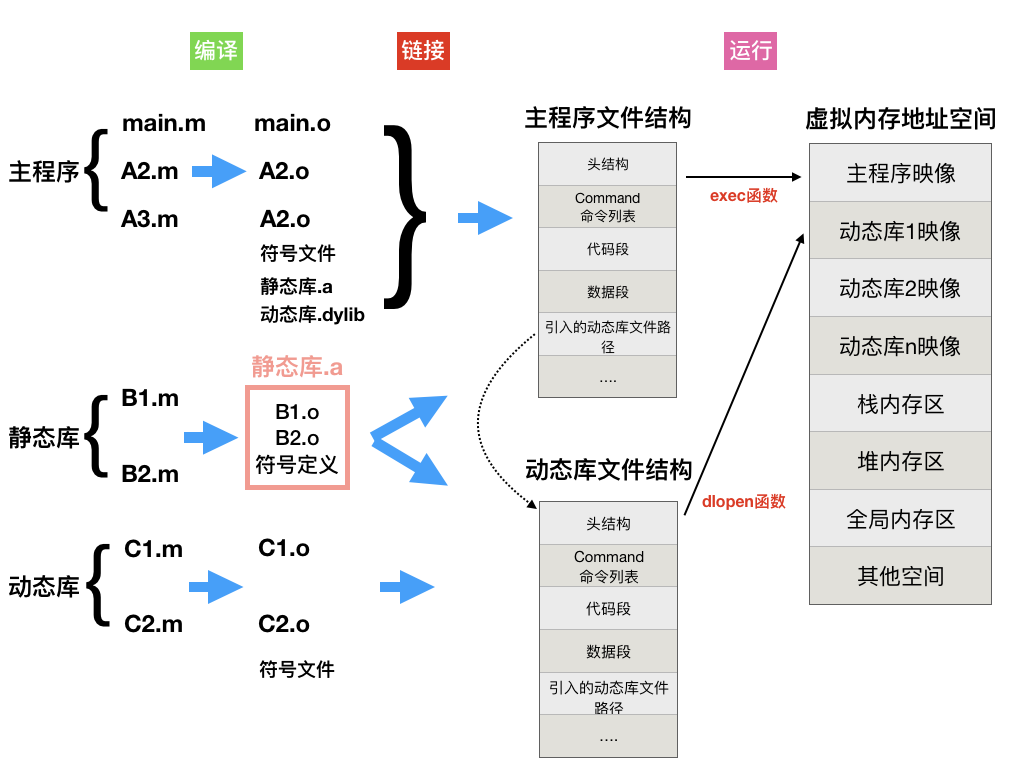
静态库文件结构
静态库是由文件头标志加符号表加目标文件集合组成的一个文件。可见静态库文件是一个文件的集合文件。静态库在unix/linux中一般以.a结尾,而在windows中一般以.lib结尾。静态库文件是一种档案文件(archive file),档案文件的格式并没有形成统一的标准。
静态库的文件格式并不是mach-o文件格式的一部分。但是目前大部分操作系统中静态库的文件格式和生成标准都非常的相似。因为在iOS系统中可以支持x64和arm两种体系结构,因此iOS系统中的静态库文件中还可以同时支持多种体系结构的目标文件的集合,我们称这种静态库文件之为fat格式的静态库文件。下面分别展示的单体系结构下的静态库文件布局结构和多体系结构下的静态库文件布局结构:
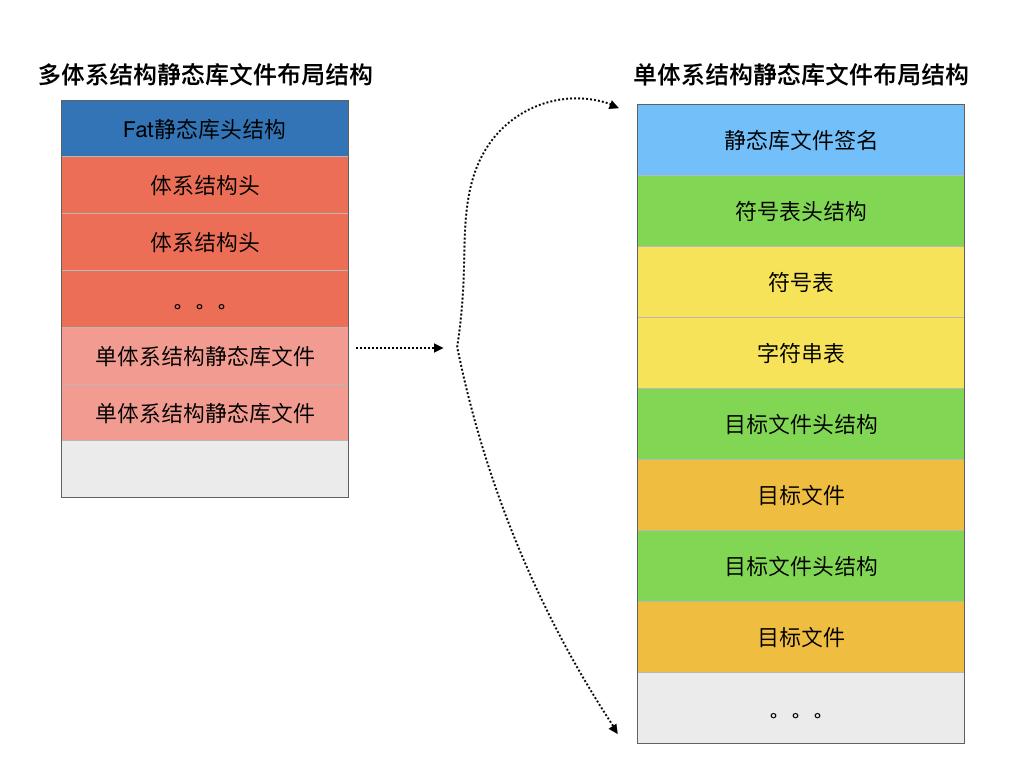
1.静态库文件签名
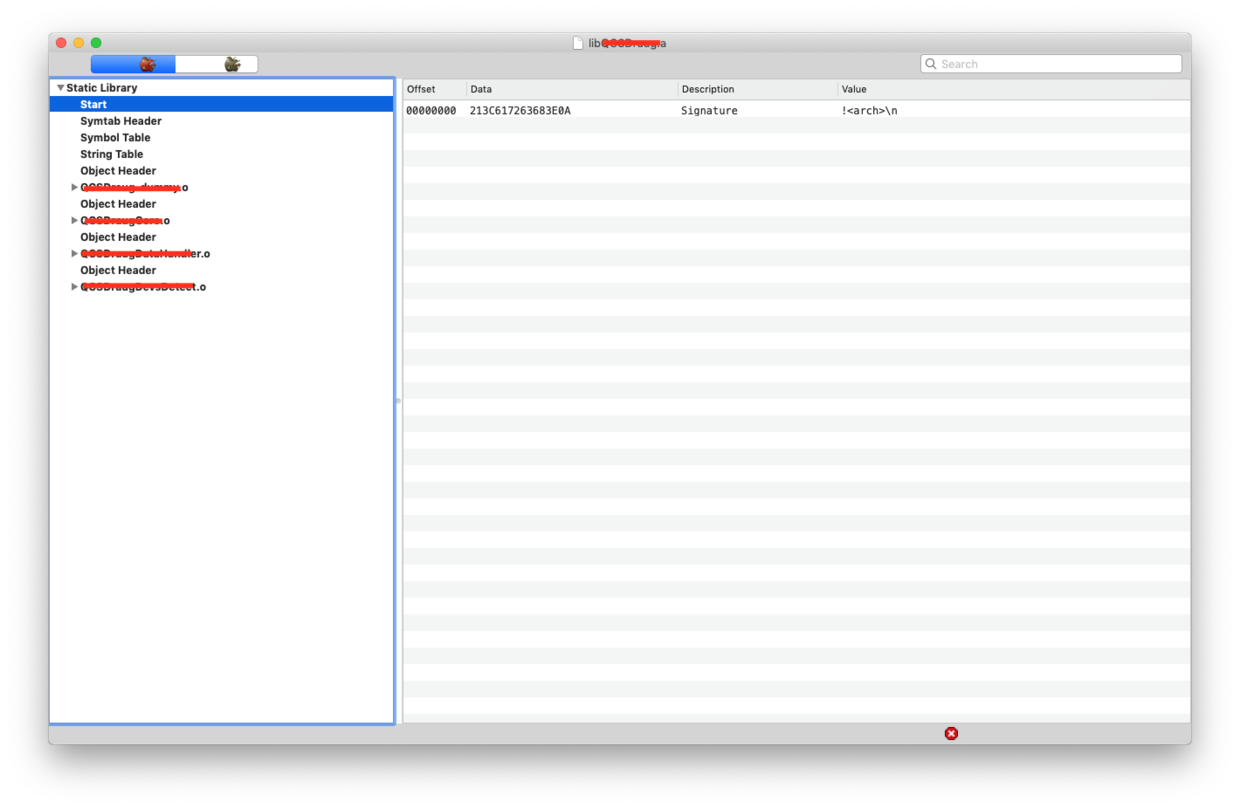
正如大部分文件的开头总是有一个所谓的magic标识一样,单体系结构静态库文件的开头也有一个8字节长度的字符串签名:!\n。这个签名是所有档案文件(archive file)的通用头部签名。因此你可以通过读取文件的前8个字节的内容来和“!\n”进行比较判断来确认是否是一个有效的静态库。需要注意的是这里的\n是一个换行的转义字符。
2.符号表头结构
静态库文件的第二部分就是一个符号表头结构。其实符号表也是可以单独成为一个文件的。因此符号表头结构其实就是用来对符号表进行描述的结构体。这是一个变长的结构体,结构体定义如下:
struct symtab_header
{
char identifier[16]; //符号表的标识
char timestamp[12]; //符号表生成的时间戳, 这里用数字字符串来表示从1970.1.1到现在的毫秒数。
char ownerid[6]; //符号表文件的所有者标识
char groupid[6]; //符号表文件的组标识
char mode[8]; //符号表文件的读写模式
char size[10]; //符号表的尺寸,用字符串形式表示的尺寸。
char end[2]; //头部结束标志。
char name[0]; //可选的符号表文件名称。
};
符号表头结构体中所有的数据成员都是字符串类型,观察结构体的数据成员有很多是和文件属性关联的,比如时间戳、所有者、所属的组、以及读写模式。这样定义的作用是当我们把静态库中的符号表信息单独提取出一个文件时可以设置提取出来文件的默认属性,同时这些信息也用来描述生成这个静态库的符号表文件的信息。 符号表头结构中的identifier和name两个数据成员都可以用来描述符号表的名字。name部分则是可选的。当identifier为正常的字符串时则identifier字段用来描述符号表的名字。而当identifier中的内容为一个特殊值: “#1/长度” 时则表明name部分是用来描述符号表名称的。name的长度则由identifier中指定的长度决定。比如当某个identifier中的内容为:“#1/20”时则表明符号表的名称存放在name字段中,并且名字的长度为20个字符。一般情况符号表的名称都是固定为:“__.SYMDEF”或者为"__.SYMDEF_64",并且保存在name字段中。
3.符号表
静态库中的符号表中保存的是所有目标文件中的符号表信息的集合。我们知道在程序链接时需要读取目标文件中的符号表信息才能决定其他目标文件中引用的符号信息是否真实存在,当其他目标文件引用的符号信息不存在或者找不到时就会报经典的符号信息不存在的错误:
Undefined symbols for architecture arm64:
"_fn", referenced from:
-[ViewController viewDidLoad] in ViewController.o
ld: symbol(s) not found for architecture arm64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
那么既然目标文件中都有符号表信息,为什么还要在静态库的开头来构造一段静态库内所有目标文件导出的符号信息呢?答案就是为了加快链接的速度,因为每次都从目标文件中去读取符号信息肯定会比单独从静态库中一处读取符号信息要慢很多。
符号表的结构体也是一个可变长度的结构体其定义如下:
struct symtab
{
int size; //符号表条目的尺寸。注意这里是整个符号表条目数组的尺寸,而不是条目的数量。
struct ranlib[0]; //符号表条目数组,如果是64位的则是ranlib_64
};
结构体struct ranlib的定义可以在<mach-o/ranlib.h>中找到。这个结构体的定义如下:
struct ranlib {
union {
uint32_t ran_strx; //符号名称在下面的字符串表中的开始偏移位置。
#ifndef __LP64__
char *ran_name; /* symbol defined by */
#endif
} ran_un;
uint32_t ran_off; //符号归属的目标文件头结构的偏移。
};
每个符号条目由两部分组成:一个ran_strx是指定符号在下面字符串表中的开始偏移的位置。一个ran_off则是指定这个符号是在哪个目标文件中被定义,这个值是对应目标文件的目标头结构在静态库中的偏移量值。因此可以通过这个值快速的定义到符号所在的目标文件。
4.字符串表
静态库里面的字符串表是专门用来为符号表服务的。字符串表跟在符号表的后面,最开始的4个字节保存的是字符串表的长度,而后面跟随的就是以\0结尾的字符串数组列表。字符串表的结构定义如下:
struct stringtab
{
int size; //字符串表的尺寸
char strings[0]; //字符串表的内容,每个字符串以\0分隔。
};
5.目标文件头结构
目标文件头结构用来描述后面跟随的目标文件的信息。它的结构的定义和符号表头结构是一模一样的。这里就不再赘述了。
6.目标文件
目标文件是一个mach-o格式的文件,在上面关于目标文件的介绍中有大体介绍目标文件的格式,要想了解更多关于目标文件的格式信息请参考一些相关的mach-o格式介绍的文档,以及后续我也会在相关的文章中进行详细介绍。
因为在静态库中是目标文件的集合,因此每个静态库文件中都会有非常多的目标文件头结构和目标文件。下面就是一个静态库文件结构的例子:
7.Fat静态库头结构
静态库文件中可能只有一个体系结构的库,可能包括多个体系结构的库的集合,就比如第三方提供给我们的静态库可能会有模拟器版本和真机版本。因此静态库也是可以支持多体系结构的,当一个静态库中包含有多种体系结构的内容时,在静态库文件的开头将是一个Fat静态库的头结构,而不是以"!\n"开头了。而是一个如下定义的结构体:
struct fat_header {
uint32_t magic; /* FAT_MAGIC or FAT_MAGIC_64 */
uint32_t nfat_arch; /* number of structs that follow */
};
这个结构体的定义可以在<mach-o/fat.h>中找到,可以看出无论是静态库还是可执行文件,当文件中包含多个体系结构的代码时,文件的开头都是一个fat_header的结构体。结构体后面跟随着多个体系结构的描述信息。
8.体系结构头
体系结构头信息描述具体的体系结构的信息,这个结构体的定义如下:
//如果是64位系统则是fat_arch_64
struct fat_arch {
cpu_type_t cputype; /* cpu specifier (int) */
cpu_subtype_t cpusubtype; /* machine specifier (int) */
uint32_t offset; /* file offset to this object file */
uint32_t size; /* size of this object file */
uint32_t align; /* alignment as a power of 2 */
};
这个结构体的定义也可以在<mach-o/fat.h>中找到,可以很清楚的看到结构体中有描述具体的CPU的类型,以及对于的内容的偏移offset和size。对于静态库来说每个fat_arch的offset位置就是一个单体系结构的静态库的文件的内容,而可执行文件来说offset位置指定的就是可执行文件的image内容。
上面就是我要介绍的关于静态库文件结构的所有内容了。通过上面的介绍我想你应该对静态库的作用和其文件布局结构有了更进一步的了解。我们可以通过XCODE工程来生成一个静态库文件,我们还可以通过lipo命令来构造一个多体系结构的静态库。(其实了解了静态库的文件结构后我们就很容易自己编写出一个lipo命令出来了!)
静态库的一些操作命令。
对于静态库文件通常情况下我们可以借助lipo命令在构建多体系结构的静态库,还可以通过ar命令来构建和显示一个静态库中的文件,以及提取这些文件,或则将某个目标文件从静态库中删除,以及将某个目标文件添加到静态库中。另外你还可以用nm命令来查看一个静态库中的所有符号信息。
lipo命令使用入口:blog.csdn.net/SoaringLee_…
ar命令使用入口: www.cnblogs.com/woxinyijiu/…
nm命令使用入口: www.jianshu.com/p/6d5147347…
静态库中的一个应用场景
静态库的目标文件中的relocation信息是保存的外部符号的引用信息,那么我们可以对目标文件的这部分信息进行修改,使得在不改变源代码的情况下实现原生对函数A的调用改为对函数B的调用!一个非常有意思的应用就是我们可以改动所有对objc_msgSend的调用!来实现对OC方法调用的HOOK处理。至于为什么要对静态库中的目标文件修改的原因是XCODE对源代码的编译和链接是一体的我们无法在编译之后和链接之前插入脚本来修改目标文件中的内容。但是静态库中的内容则是我们可以任意预先去修改的。
参考
1.本文对静态库结构的介绍主要是来自于machOView的源代码。 2.en.wikipedia.org/wiki/Ar_(Un…
👉【返回目录】
欢迎大家访问我的github地址
