

前言
现代web应用的飞速发展,特别是数据驱动思想指导下的React、vue等框架的出现,让我们越来越需要关注数据的组织管理。随着应用复杂度的提升,如果不对数据进行有效合理的设计拆分,那么从性能、可维护性等方面来看会逐渐成为一种阻碍。所以我们需要关注前端数据设计。
其实没有一种很明确的规范告诉我们具体到前端的数据结构应该如何去设计。关系数据库设计有很多范式,借鉴而不照搬结合前端自身特点,才是好的前端数据范式化的实践。
范式化
在深入了解数据范式化之前,我们可以先看个例子
举个栗子:
实际业务中,迭代比较多的业务,我们一般会配置化,即除了业务数据之外将页面布局展示相关的内容也由接口控制。 那么后端返回的数据可能如下:
{
info: [
{
key:'a',
txt:'展示1',
value:0
},
{
key:'b',
txt:'展示2',
value:1
}
]
}
这样响应操作的时候,需要更新每一项的值如果直接修改info这个数组,存在着很大的不便。
如果你说还好,但这样将就操作之后,提交的时候发现这一大串冗余数据后端也不需要呀,还是要处理value。
此时的数据还不是那么的复杂,不过层层嵌套的对象见过吧,让人心头一惊的数据格式,如果还在上面操作,可能下个迭代你自己都不知道到底该操作哪个字段了。
这时候如果将展示和逻辑相分离,抽出来一个专门的属性用来存放与后端交互的数据,看起来是简洁了一些,后期可维护性也增强了不少。
{
info: [
{
key:'a',
txt:'展示1'
},
{
key:'b',
txt:'展示2'
}
],
values:{
a:0,
b:1
}
}
这样其实就可以认为是我们提到范式化或者说是扁平化了。具体到前端数据范式化之前 我们来看看数据库的范式吧
具体到前端数据范式化之前 我们来看看数据库的范式吧
什么是范式:
顾名思义,一个规范模式(虽然有点粗暴,但好像就是这么回事)。
本来想找段定义贴在下面,不过看了看太生硬了,写下个人见解好了。
第一范式 1NF 表的列具有原子性,不可再分解。 只要是关系型数据库就满足1NF
第二范式 2NF 前提是满足1NF,在1NF的基础上。每一行或者实例必须唯一可以被区分,即需要我们说的主键(key)。
第三范式 3NF
满足1NF和2NF,且一个数据库表中不包含已在其他表中包含的非主键字段。
也就是说表中不冗余,可以通过关系从其他表中获取就不要单独存放了,也就是相关信息可以通过外键相关联。 有个图表达的很不错,借来一用:
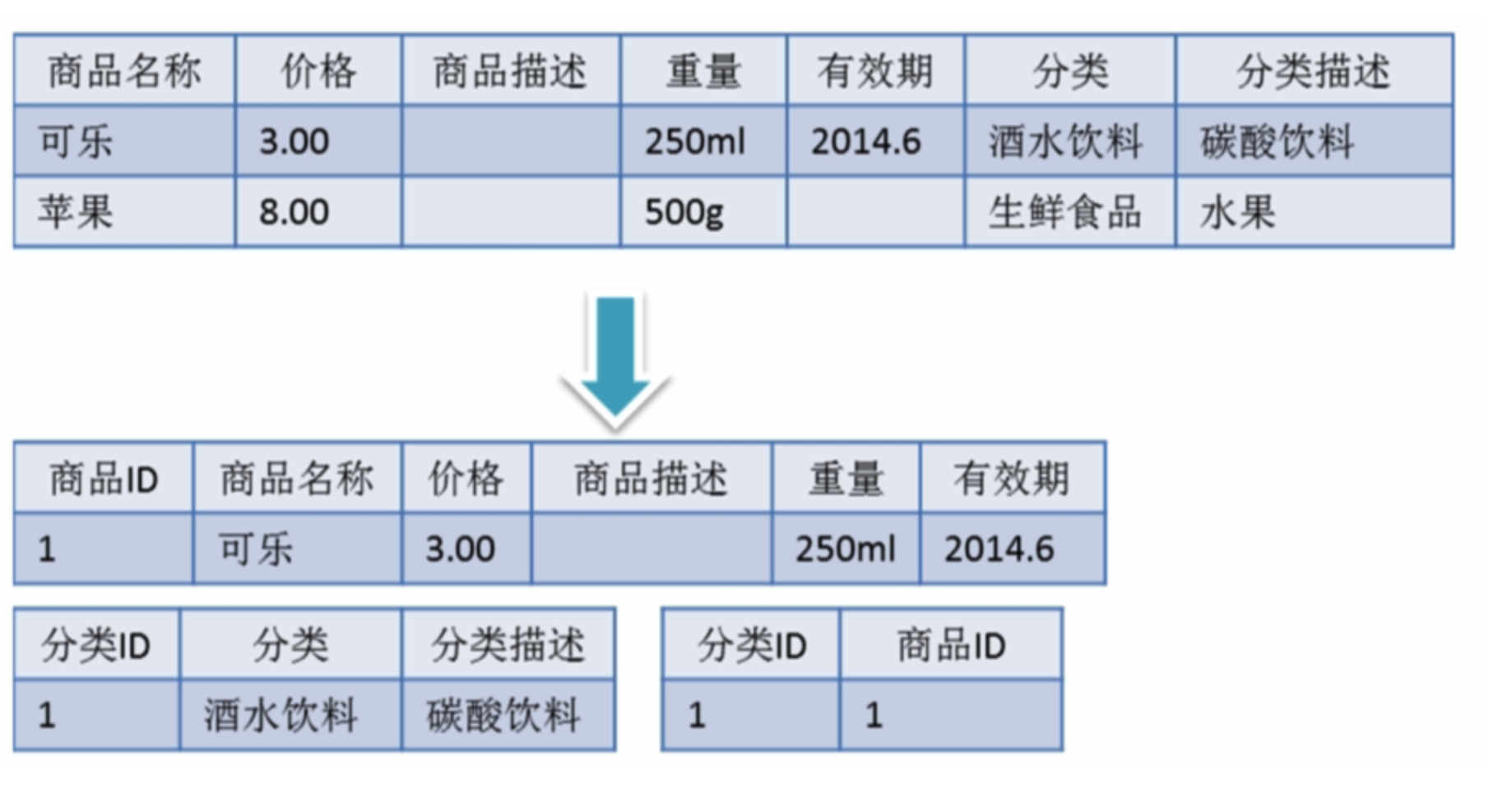
当然后面还有其他范式这里就先不提了。
总结一下,范式就是为了减少冗余,提高效率 遵循的范式越高,冗余越小,但也要具体分析,不可一味追求符合范式。 有些时候一昧的追求范式减少冗余,反而会降低数据读写的效率,这个时候就要反范式,利用空间来换时间。
redux中的state设计要求
redux针对state的设计也提出了范式化的要求,对于复杂的数据结构,除了数据重复之外,还可能有下面这些问题:
- 当数据在多处冗余后,需要更新时,很难保证所有的数据都进行更新。
- 嵌套的数据意味着 reducer 逻辑嵌套更多、复杂度更高。尤其是在打算更新深层嵌套数据时。
- 不可变的数据在更新时需要状态树的祖先数据进行复制和更新,并且新的对象引用会导致与之 connect 的所有 UI 组件都重复 render。尽管要显示的数据没有发生任何改变,对深层嵌套的数据对象进行更新也会强制完全无关的 UI 组件重复 render
所以,在 Redux Store 中管理关系数据或嵌套数据的推荐做法是将这一部分视为数据库,并且将数据按范式化存储。 有这么几点概念:
- 任何类型的数据在 state 中都有自己的 “表”。
- 任何 “数据表” 应将各个项目存储在对象中,其中每个项目的 ID 作为 key,项目本身作为 value。
- 任何对单个项目的引用都应该根据存储项目的 ID 来完成。
- ID 数组应该用于排序。
具体实践-Normalizr
这里就需要提到Normalizr了,对于复杂数据管理,基本都会提到它。其作用很直白的通过其简介体现出来:Normalizes nested JSON according to a schema。依据模式规范化的处理json。
其用法这里就不介绍了,只提供下转换前后的数据做个对比。有兴趣的大家去官网一看便知。
原始数据:
{
"id": "123",
"author": {
"id": "1",
"name": "Paul"
},
"title": "My awesome blog post",
"comments": [
{
"id": "324",
"commenter": {
"id": "2",
"name": "Nicole"
}
}
]
}
转换后
{
result: "123",
entities: {
"articles": {
"123": {
id: "123",
author: "1",
title: "My awesome blog post",
comments: [ "324" ]
}
},
"users": {
"1": { "id": "1", "name": "Paul" },
"2": { "id": "2", "name": "Nicole" }
},
"comments": {
"324": { id: "324", "commenter": "2" }
}
}
}
这样的数据就比较符合我们前面redux设计要求了。
结束语
到这里前端数据的范式化也就介绍的差不多了,一个感悟是js中的数据结构设计何尝不是数据库设计,去遵循相应的范式会让我们的数据结构更加清晰明了。
就算开始没考虑到,随着业务量级的上升原本结构遇到的问题,开发的时候自然也会去往更优雅的方向去靠,这就是进步的过程。
不过还是那句话,要基于实际情况来看待,不要盲目引入,化简为繁不是一种值得称赞的做法。
通篇文章为个人见解,抛砖引玉有不对的地方欢迎指出
参考文章:
blog.csdn.net/qq_35401191…
zhuanlan.zhihu.com/p/36487766
cn.redux.js.org/docs/recipe…
