

其他更多java基础文章:
java基础学习(目录)
HDFS概述
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统。
分布式文件系统(DistributedFileSystem) 是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。分布式文件系统的设计基于客户机/服务器模式。一个典型的网络可能包括多个供多用户访问的服务器。
HDFS重要概念
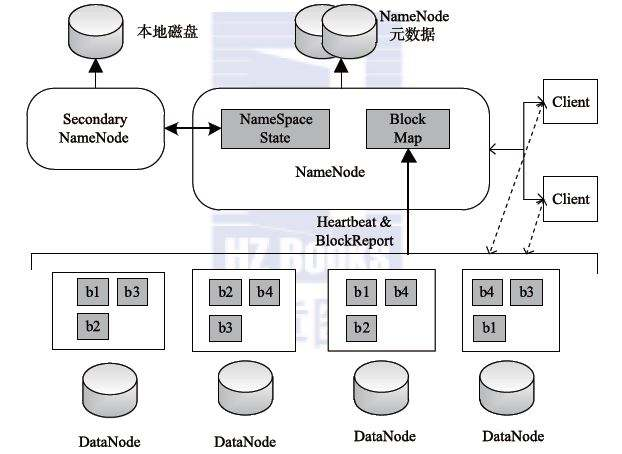
Block数据块
在HDFS系统中,为了便于文件的管理和备份,引入分块概念(block)。这里的块是HDFS存储系统当中的最小单位,HDFS默认定义一个块的大小在Hadoop1.0中为64MB,Hadoop2.0中为128MB。当有文件上传到HDFS上时,若文件大小大于设置的块大小,则该文件会被切分存储为多个块,多个块可以存放在不同的DataNode上。但值得注意的是如果某文件大小没有到达64/128MB,该文件并不会占据整个块空间 。(例如当一个1MB的文件存储在128MB的块中,文件只使用1MB的硬盘空间,而不是128MB)。默认副本数为3。
namenode
namenode是管理文件系统的命名空间。它维护者文件系统树及整颗树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:fsimage命名空间镜像文件和edits编辑日志文件。namenode也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息会在系统启动时根据数据节点信息重建。
datanode
datanode是文件系统的工作节点。它们根据需要存储并检索数据块,并定期向namenode发送它们所存储的块的列表。
secondnamenode
secondnamenode又称为辅助namenode。secondnamenode不能被用作namenode,它的重要作用是定期合并namenode编辑日志与命名空间镜像,以防编辑日志过大。但是,secondnamenode保存的状态总是滞后于主节点namenode。
Client
客户端,系统使用者,调用HDFS API操作文件;与NN交互获取文件元数据;与DN交互进行数据读写。
hdfs细节
datatnode副本存储逻辑
hadoop的默认布局策略是在运行客户端的节点上放第1个复本(如果客户端运行在集群之外,就随机的选择一个节点,但是系统会避免挑选那些存储太满或太忙的节点)。第2个复本放在与第1个不同且是随机选择的另外的机架中的节点上。第3个复本与第2个复本放在同一个机架上面,且是随机选择的一个节点,其他的复本放在集群中随机选择的节点上面,但是系统会尽量避免在相同的机架上面放太多的复本。
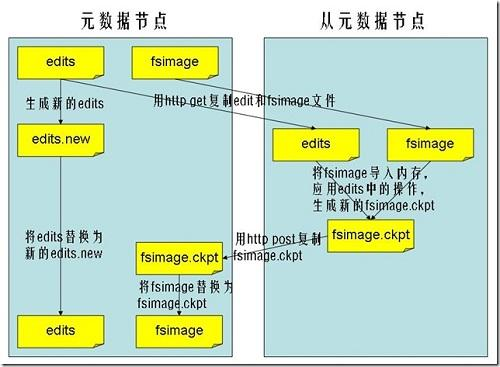
secondnamenode合并namenode日志过程
- 初始化检查点
- secondnamenode通知Namenode启用新的edits文件
- 从Namenode下载fsimage和edits文件
- 调用loadFSImage装载fsimage
- 调用loadFSEdits应用edits日志
- 保存合并后的目录树信息到新的image文件中
- 将新产生的image上传到Namenode中,替换原来的image文件
- 结束检查点
hdfs写入写出过程
在学习过程中,发现这篇文章写得很全面,这个部分非常重要,希望大家好好阅读这篇文章。
hdfs的容错机制
hadoop HA高可用
对于分布式文件系统HDFS ,NN是系统的核心节点,存储了各类元数据信息,并负责管理文件系统的命名空间和客户端对文件的访问。但是,在HDFS1.0中,只存在一个NN,一旦发生“单点故障”,就会导致整个系统失效。
HDFS2.0采用了HA(High Availability)架构。在HA集群中,一般设置两个NN,其中一个处于“活跃(Active)”状态,另一个处于“待命(Standby)”状态。处于Active状态的NN负责对外处理所有客户端的请求,处于Standby状态的NN作为热备份节点,保存了足够多的元数据,在Active节点发生故障时,立即切换到活跃状态对外提供服务。
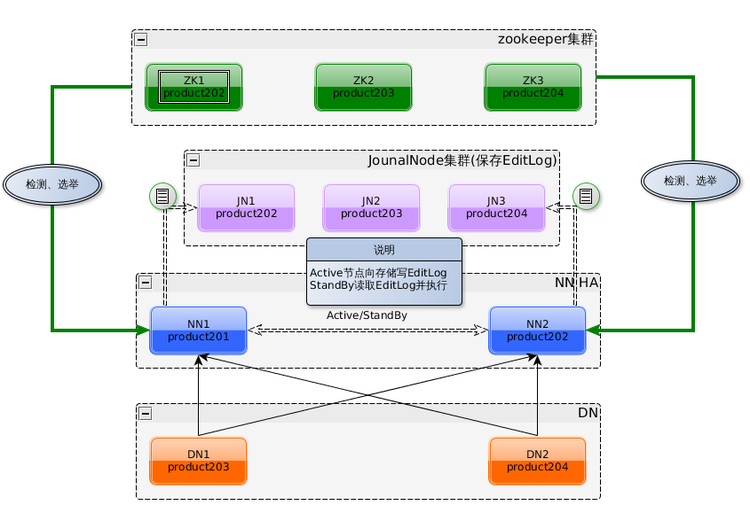
由于Standby NN是Active NN的“热备份”,因此Active NN的状态信息必须实时同步到StandbyNN。针对状态同步,可以借助一个共享存储系统来实现,如NFS(NetworkFile System)、QJM(Quorum Journal Manager)或者Zookeeper。Active NN将更新数据写入到共享存储系统,Standby NN会一直监听该系统,一旦发现有新的写入,就立即从公共存储系统中读取这些数据并加载到自己内存中,从而保证与Active NN状态一致。
此外,NN保存了数据块到实际存储位置的映射信息,即每个数据块是由哪个DN存储的。当一个DN加入到集群中时,它会把自己所包含的数据块列表给NN,定期通过心跳方式,以确保NN中的块映射是最新的。因此,为了实现故障时的快速切换,必须保证StandbyNN中也包含最新的块映射信息,为此需要给DN配置Active和Standby两个NN的地址,把块的位置和心跳信息同时发送到两个NN上。为了防止出现“两个管家”现象,还要保证在任何时刻都只有一个NN处于Active状态,需要Zookeeper实现。
hadoop Federation联邦机制
虽然HDFS HA解决了“单点故障”问题,但是在系统扩展性、整体性能和隔离性方面仍然存在问题。
- 系统扩展性方面,元数据存储在NN内存中,受内存上限的制约。
- 整体性能方面,吞吐量受单个NN的影响。
- 隔离性方面,一个程序可能会影响其他运行的程序,如一个程序消耗过多资源导致其他程序无法顺利运行。HDFS HA本质上还是单名称节点。
HDFS联邦可以解决以上三个方面问题。
