

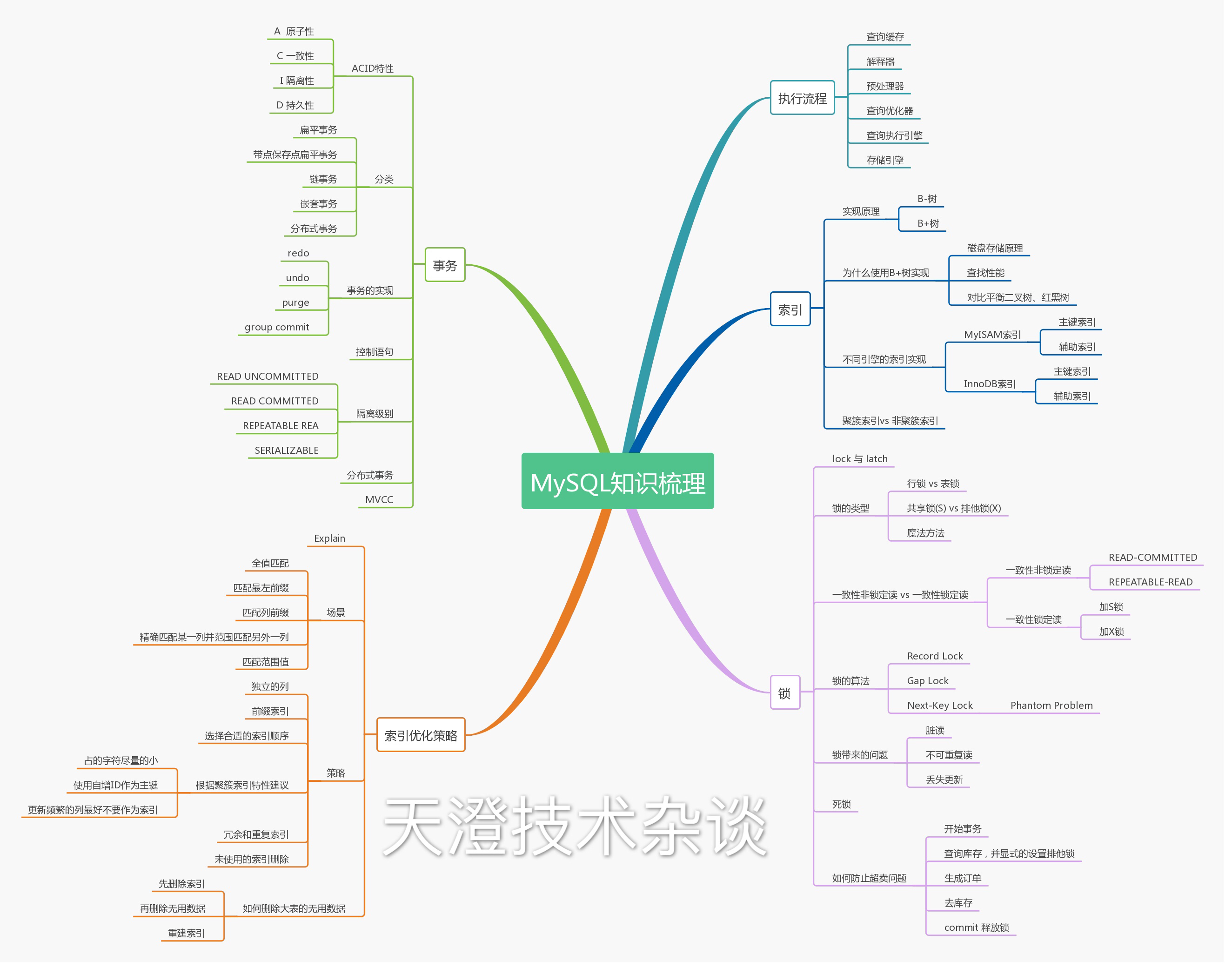
MySQL知识梳理图,一图看完整篇文章:
MySQL优化一直是老生常谈的问题,尤其在面试环节中,但在做MySQL的优化之前,得先了解MySQL的执行流程是怎样,这样才更好的去优化。
面试过程中也通常会问如果高并发或者用户反映系统太卡,我们该怎么去优化?
- 如果高并发,请求书过多,优先增加web服务器机器,做好负载均衡。
- 如果请求静态页面不卡,但是动态数据卡,则说明MySQL处理的请求过多,需要再MySQL的上游封装一层缓存层,减轻MySQL的压力。
- 数据库层其实是非常脆弱的一层,一般在应用架构设计时,通常需要将一些用户非实时的数据或变化不频繁的数据缓存起来,让这些请求穿透不到DB,同时还可以引入队列做数据的异步更新。如果请求数激增,还是有非常大的查询压力到MySQL,这时候则想办法解决MySQL的瓶颈。
1. 执行流程图
简易的流程图如下:
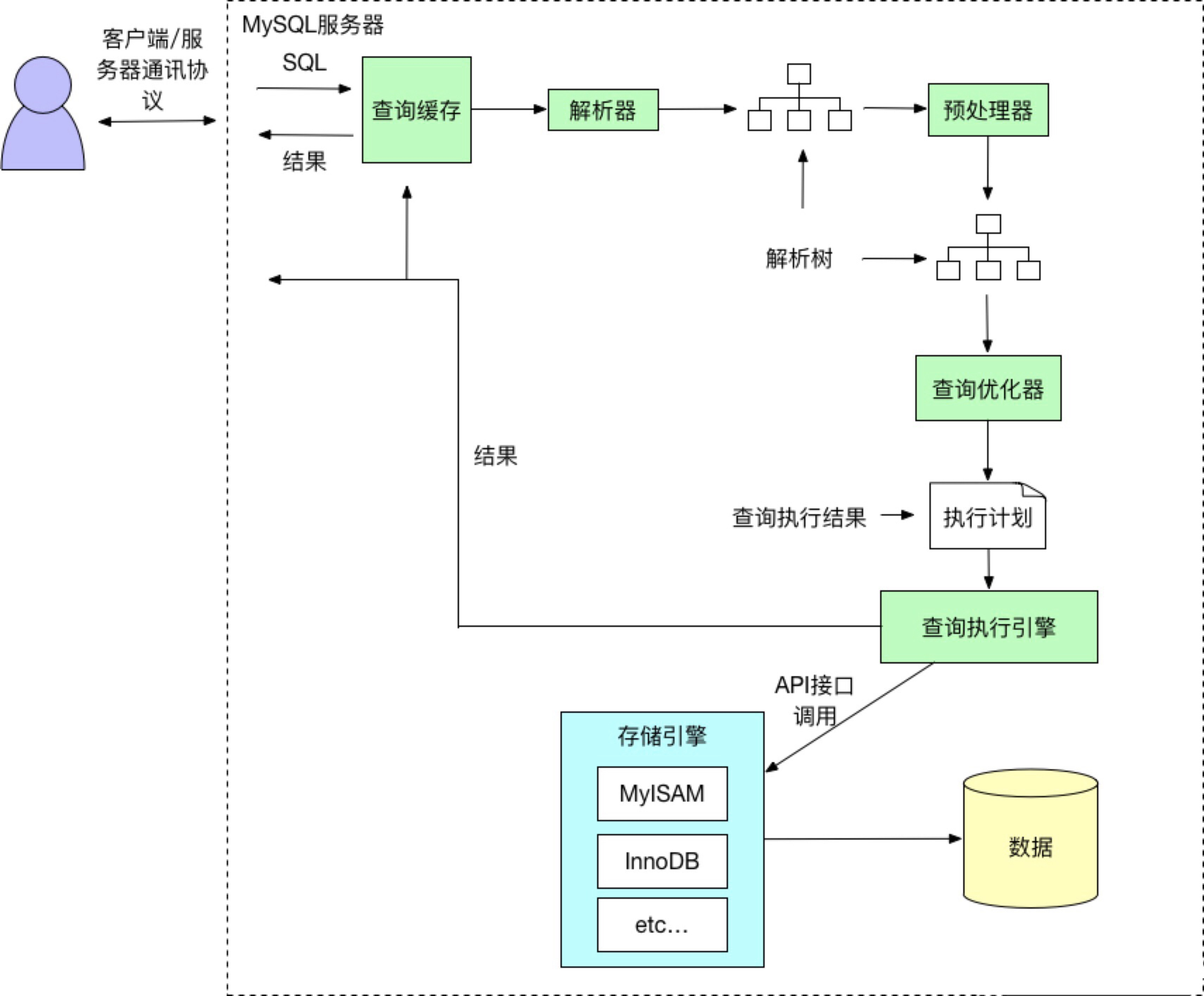
大致流程描述:
- MySQL客户端通过协议将SQL语句发送给MySQL服务器。
- 服务器会先检查查询缓存中是否有执行过这条SQL,如果命中缓存,则将结果返回,否则进入下一个环节(查询缓存默认不开启)。
- 服务器端进行SQL解析,预处理,然后由查询优化器生成对应的执行计划。
- 服务器根据查询优化器给出的执行计划,再调用存储引擎的API执行查询。
- 将结果返回给客户端,如果开启查询缓存,则会备份一份到查询缓存中。
2. 流程图详解
2.1 查询缓存
MySQL查询缓存会保存查询返回的完整结构。当查询命中该缓存时,MySQL会立刻返回结果,跳过了解析、优化和执行阶段。 但查询缓存是默认不开启的,且要求SQL和参数都是一样,同时查询缓存系统会跟踪查询中涉及的每一个表,如果这些表发生变化,则该表相关的所有缓存数据均会失效。所以命中率一般较低,生产环境中也很少用到,具体流程就不描述了。如果感兴趣的可以查阅详细资料。
2.2 解析和预处理
如果查询缓存未命中,则到解析器。解析器主要是对SQL语句进行解析,使用MySQLy语法规则进行验证和解析查询,并生成对应的解析树。 得到解析数之后,还需要做预处理,预处理则进一步检查解释树是否合法,以及进行一些优化,比如检查数据表和列是否存在,如果有计算,会将计算的结果算出来等等。
2.3 查询优化器
查询优化器是整个流程中重要的一环。查询优化器会将预处理之后的解析树转化成执行计划。一条查询可以有多种执行方法,最后均会返回相同结果。查询优化器的作用就是找到这其中最好的执行计划。 生成执行计划的过程会消耗较多的时间,特别是存在许多可选的执行计划时。如果在一条SQL语句执行的过程中将该语句对应的最终执行计划进行缓存,当相似的语句再次被输入服务器时,就可以直接使用已缓存的执行计划,从而跳过SQL语句生成执行计划的整个过程,进而可以提高语句的执行速度。 通常所讲的优化SQL,其实就是想让查询优化器,按照我们的思路,帮我们选择最优的执行方案。
2.4 查询执行计划
查询执行计划,就是MySQL查询中的执行计划,比如是执行where语句还是from语句,下面有一张执行顺序的图。

最先执行的总是FROM操作,最后执行的是LIMIT操作。其中每一个操作都会产生一张虚拟的表,这个虚拟的表作为一个处理的输入,只是这些虚拟的表对用户来说是透明的,但是只有最后一个虚拟的表才会被作为结果返回。如果没有在语句中指定某一个子句,那么将会跳过相应的步骤。
- FORM: 对FROM的左边的表和右边的表计算笛卡尔积。产生虚表VT1
- ON: 对虚表VT1进行ON筛选,只有那些符合的行才会被记录在虚表VT2中。
- JOIN: 如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3, 如果 from子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3这三个步骤,一直到处理完所有的表为止。
- WHERE: 对虚拟表VT3进行WHERE条件过滤。只有符合的记录才会被插入到虚拟表VT4中。
- GROUP BY: 根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5.
- CUBE | ROLLUP: 对表VT5进行cube或者rollup操作,产生表VT6.
- HAVING: 对虚拟表VT6应用having过滤,只有符合的记录才会被 插入到虚拟表VT7中。
- SELECT: 执行select操作,选择指定的列,插入到虚拟表VT8中。
- DISTINCT: 对VT8中的记录进行去重。产生虚拟表VT9.
- ORDER BY: 将虚拟表VT9中的记录按照<order_by_list>进行排序操作,产生虚拟表VT10.
- LIMIT:取出指定行的记录,产生虚拟表VT11, 并将结果返回。
2.5 查询执行引擎
执行计划会传给查询执行引擎,执行引擎选择存储引擎来执行计划,到磁盘中的文件中去查询。 影响这个查询性能最根本的原因是什么? 其实是硬盘的机械运动,也就是我们平时熟悉的IO,所以一条查询语句是快还是慢,就是根据这个时间的IO来确定的。那怎么执行IO又是什么来确定的?就是传过来的这一份执行计划.
更多文章请关注公众号 『天澄技术杂谈』

参考文章:
https://juejin.cn/post/6844903655439597582
https://blog.csdn.net/I980663737/article/details/78421523
https://www.cnblogs.com/rollenholt/p/3776923.html
