

我们知道,在正则表达式中,可以使用[0-9]或\d来匹配单个数字字符,但是,如果需要验证一个更复杂的字符串呢,比如大陆地区的邮政编码。 不过邮政编码并没有特别规定,只有由6个数字组成的字符串而已, 如246512,根据[0-9]或\d,我们可以很快的实现匹配的正则表达式,\d\d\d\d\d\d。 从上可以看出,我们重复用了6个单个字符来实现匹配,由于目前数字较少,看着还可以接受,那如果不是6个数字组成的,10个?20个?甚至是更多呢,显然这种方式是不行的,正则表达式提供了量词,用来限定出现的次数,可以很好解决这个问题。
首先,看下量词的表示形式:
量词的一般形式
表:一般形式
| 量词 | 说明 |
|---|---|
| {n} | 量词前面的元素必须出现n次 |
| {n,m} | 量词前面的元素至少出现n次,最多出现m次 |
| {n,} | 量词前面的元素至少出现n次,无上限 |
| {,m} | 量词前面的元素可以不出现,也可以出现,最多出现m次(javascript不支持这种写法) |
```bash
/^[0-9]{2}$/.test('12') // => true
/^[0-9]{2}$/.test('123') // => false
/^[0-9]{2,5}$/.test('123') // => true
/^[0-9]{2,5}$/.test('123456') // => false
/^[0-9]{2,}$/.test('123456') // => true
/^[0-9]{0,5}$/.test('123456') // => false
/^[0-9]{0,5}$/.test('12') // => true
/^[0-9]{0,5}$/.test('') // => true
```
注意:
1、{n,m}之间的逗号后面不能出现空格,否则无法正确匹配。
| /^[0-9]{0, 5}$/.test('12') // => false |
2、量词限定的出现次数一般都有明确下限,如果没有,则默认为0,所以推荐{,m}写成{0,m},这是通用的写法。
| /^[0-9]{,5}$/.test('12') // => false |
常用量词
{n,m}是通用形式的量词,正则表达式还有3个常用的量词,分别是+、?、*,虽然形式不同于{n,m},但功能确实相同的,可以当作是“量词的简介法”。
表:常用量词
| 常用量词 | {n,m}等价形式 | 说明 |
|---|---|---|
| * | {0,} | 可能出现,也可能不出现,出现次数没有上限 |
| + | {1,} | 至少出现次数为1,出现次数没有上线 |
| ? | {0,1} | 最多出现1次,有可能不出现(出现0次或1次) |
```bash
/^\d+(\.\d+)*$/.test('123') // => true
/^\d+(\.\d+)*$/.test('123.123') // => true
/^\d+(\.\d+)*$/.test('123.123.111') // => true
/^\d+(\.\d+)*$/.test('123.') // => false
/^travell?er$/.test('traveller') // => true
/^<[^>]+>$/.test('<div>') // => true
/^<[^>]+>$/.test('<b>') // => true
/^<[^>]+>$/.test('<>') // => false
/^travell?er$/.test('traveler') // => true
/^travell?er$/.test('traveller') // => true
```
在实际开发中,很多情况用这三种表示形式几乎可以满足,因此使用频率要高于{n,m}。
点号
正则中,有一个特殊的特殊的元字符,点号.,它可以匹配任意字符,除了换行符(\n)。 如果需要用点号匹配任意字符,则必须在单行内匹配,或者使用其他的方式来替代,如[\s\S]、[\w\W]或[\d\D]。 但在实际开发中,许多人为了图省事,很多情况下会这样使用,这样滥用点号将会带来一些问题。
如:
bash new RegExp("^.*$").exec("quoted 'string '") new RegExp("^(([a-z]+)\\s')+$").exec("quoted 'string '")
如上,匹配的结果将会是整个字符串:"quoted 'string '",这就是我们常说的贪婪模式。
要弄清楚为什么会是这个结果,则必须了解表达式的匹配原理,以".*"为例。
在正则表达式中,点号.可以用来匹配除了换行符之外的所有字符,而*表示匹配的字符串长度没有限制,所以在".*"匹配过程中,每遇到一个字符, ".*"都可以匹配,到底是匹配它,还是忽略它,将其留给最后的"来匹配呢?
答案是由量词来决定的,在正则表达式中量词分为几类,匹配优先量词(贪婪量词)和忽略优先量词(惰性量词)(还有一种支配量词,这里就不介绍了,请自行百度)
匹配优先量词
匹配优先量词,顾名思义,在拿不准是否匹配某个字符时,优先尝试匹配,并且记下这个状态,以备将来“反悔”。 具体过程: 一开始,"匹配",然后到字符q,.*可以匹配q,也可以不匹配,但使用了匹配优先量词*,所有.*会尝试先匹配q,并且记录下这个状态。 接下来是字符字符u,.*可以匹配u,也可以不匹配,但使用了匹配优先量词*,所有.*会尝试先匹配u,并且记录下这个状态。 ... 轮到字符',.*可以匹配',也可以不匹配,但使用了匹配优先量词*,所有.*会尝试先匹配',并且记录下这个状态。 最后是字符串末尾的",.*可以匹配",也可以不匹配,但使用了匹配优先量词*,所有.*会尝试先匹配",并且记录下这个状态。 这个时候,字符串后面已经没有字符了,但是正则表达式中还是有"没有匹配,所以只能查看之前保存的备用状态,看看能不能回退几步,以便匹配",于是让.*后退几步,以便让"可以匹配",发现正好可以匹配,所以整个匹配宣告结束,这个“反悔”的过程,专业术语叫回溯。
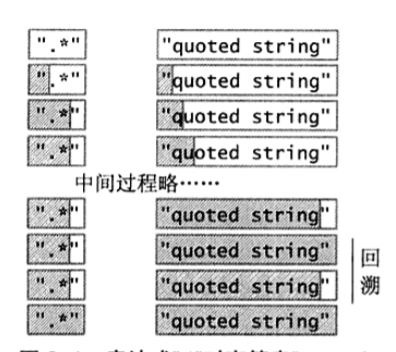
忽略优先量词
忽略优先量词,与匹配优先量词相反,在不确定是否匹配某个字符时,会优先选择“不匹配”的状态,在尝试匹配表达式之后的字符,如果匹配失败,则再回溯,选择之前保存的“匹配的”状态,这样保证了匹配的正确性。 只需要把.*改为.*?即可变成忽略优先量词。 具体过程: 类似于匹配优先量词 这种匹配可以用于完成很多功能,比如匹配注释,标签等。
表:匹配优先量词与忽略优先量词
| 匹配优先量词 | 忽略优先量词 |
|---|---|
| * | *? |
| + | +? |
| ? | ?? |
| {n} | {n}? |
| {n,m} | {n,m}? |
| {n,} | {n,}? |
| {,m} | {,m}? |
转义
在正则表达式中,+、?、*等量词是特殊字符,具有特殊含义,但是有些情况下,只想表达字符自身,则需要转义,即在字符前加反斜线\。对于一般形式的量词{n,m},虽然含有特殊含义的字符不止一个,但转义时只需要给{添加反斜线\即可,如需要匹配{n,m},则是{n,m}。 注意:忽略优先字符不像一般形式字符{n,m}一样,只需要添加一个反斜线\,如*?,必须都要添加反斜线\,即正则表达式必须写作:*?,而不是*?,后者的意思是“*这个字符有可能出现,有可能不出现”。
表:各种量词的转义
| 量词 | 转义形式 |
|---|---|
| * | * |
| + | + |
| ? | ? |
| *? | *? |
| +? | +? |
| ?? | ?? |
| {n} | {n} |
| {n,m} | {n,m} |
| {n,} | {n,} |
| {,m} | {,m} |
除此之外,元字符点.也需要加反斜线\来进行转义。 由于点.表示除了换行符之外的字符,也包括点号(.),所以很多人忽略了对其转义,但如果忽略了对其转义,则在严格匹配点号时会出错。比如匹配小数(3.14)、IP地址(192.168.1.1)、Email地址(some@host.com)等,所以若是要匹配的文本包含点号,一定不要忘了对其进行转义,否则会出现如下的出错:
```bash
/^\d+.\d+$/.test("3.14") // => true
/^\d+.\d+$/.test("3@14") // => true
/^\d+\.\d+$/.test("3.14") // => true
/^\d+\.\d+$/.test("3@14") // => false
```
正则分析
1、密码长度在6-12个字符之间 2、只能由小写字母,数字和横线组成 3、开头和结尾不能为横线 4、不能全部为数字 5、不允许有连续(2个及以上)的横线/^(?!-)(?!\d+/.test('bdad-ss-e3')
