

前言
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路,一般来讲,计算机中的集合是用哈希表(Hash table)来存储的。
但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为 O(n),O(logn),O(1)。其中时间复杂度最低的hash table的空间复杂度是O(N),在面对数以亿记的数据时,这种实现方式的存储成本会比较大。
比如说,一个像 Yahoo,Hotmail 和 Gmai 那样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。一个办法就是记录下那些发垃圾邮件的 email 地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。如果用哈希表,每存储一亿 个 email 地址, 就需要 1.6GB 的内存(用哈希表实现的具体办法是将每一个 email 地址对应成一个八字节的信息指纹(详见:china.googleblog.com/2006/08/blo… ), 然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email 地址需要占用十六个字节。一亿个地址大约要 1.6GB, 即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB 的内存。除非是超级计算机,一般服务器是无法存储的 -- Google黑板报 china.googleblog.com/2007/07/blo…
那么有没有其他的方式来实现同样的事呢?本文介绍一下布隆过滤器及其原理和应用。
如果面试官问你,一个网站有 100 亿 url 存在一个黑名单中,每条 url 平均 64 字节。问这个黑名单要怎么存?若此时随便输入一个 url,如何判断该 url 是否在这个黑名单中?
正文
布隆过滤器(bloom filter)可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除元素困难。
一般的布隆过滤器会提供两个方法:Test 和 Add
Test用来确认某个元素是否在集合内。如果它返回:
- false,那么这个元素一定不在集合内。
- true,那么这个元素只是有可能在集合里面,部分不在集合内的元素会被误判在集合内,布隆过滤器的假正率(False positive rate)用来描述这一概率,其随着数据的增大而增大,同时也和所使用的hash函数有关。
假正率就是实际数据为false,预测数据(布隆过滤器的判断)为true,的概率。
Add用来添加元素到集合内。
这里没有删除,在讲到原理部分时会比较清楚的讲解为什么布隆过滤器删除元素困难。
布隆过滤器原理
布隆过滤器的原理是,当一个元素被加入集合时,通过K个hash函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
数据结构
布隆过滤器是一个 bit 向量,长这样:
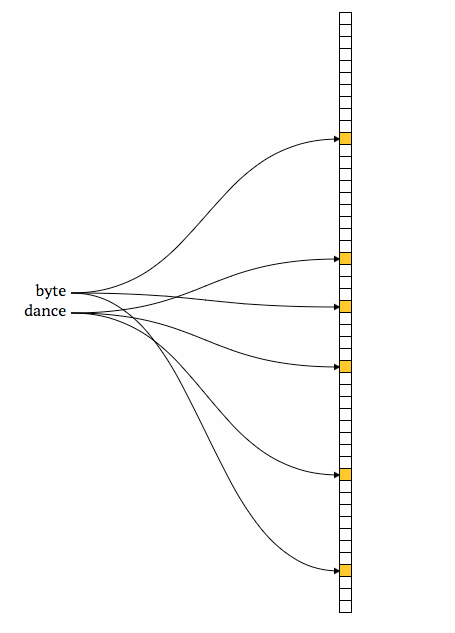
往布隆过滤器中添加一个元素时,我们将这个值传入 k 个hash函数,然后将结果位置bit置为1,在图中例子向量或者说数组的长度为50,使用3个hash函数。
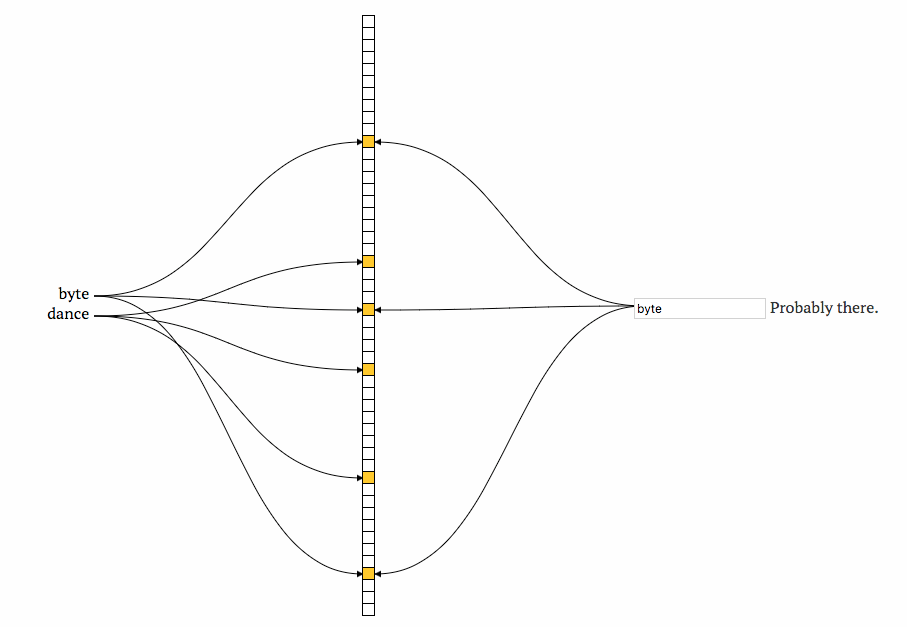
当我们要判断一个元素是否在布隆过滤器中时,我们把这个值传入k个hash函数中获得映射的k个点。这一次我们确认下是否所有的点都被置为1了,如果有某一位没有置为1则这个元素肯定不在集合中。如果都在那这个元素就有可能在集合中。
看完原理后我们就知道了为什么布隆过滤器中有可能误判以及元素越多假正率(误判几率)越大,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值即使没有被存储过,但是有可能元素的hash函数返回的k个 bit 位都被其他值置位了 1 ,那么程序还是会判断这个值存在。
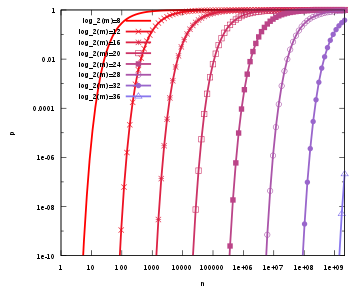
同时hash函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
关于如何选择合适的hash函数个数k和布隆过滤器长度m,有人推导出了公式如下
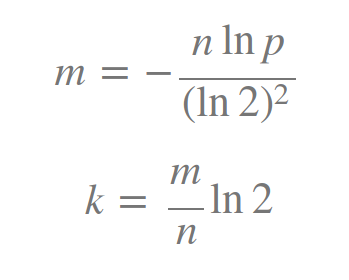
删除困难
了解了布隆过滤器的原理后我们就知道在布隆过滤器中删除元素几乎是不可能的了,不过其实有一种叫做counting bloom filters的数据结构
使用场景
利用布隆过滤器减少磁盘IO或者网络请求
比较常见的例子是用布隆过滤器减少磁盘IO或者网络请求(都是代价很高的操作)查找不存在的key的时候。
布隆过滤器返回false那么这个值肯定不在
因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。如果它在,那么我们就去做查找,由于误判率不会太高所以这种代价一般也能承受。
- Google 著名的分布式数据库 Bigtable 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数
- 在很多Key-Value系统中也使用了布隆过滤器来加快查询过程,如 Hbase,Accumulo,Leveldb,一般而言,Value 保存在磁盘中,访问磁盘需要花费大量时间,然而使用布隆过滤器可以快速判断某个Key对应的Value是否存在,因此可以避免很多不必要的磁盘IO操作,
- 比如高并发秒杀系统中抢红包系统中判断用户是否今天已领取红包
- 在爬虫系统中,我们需要对URL进行去重,已经爬过的网页就可以不用爬了。但是URL太多了,几千万几个亿,如果用一个集合装下这些URL地址那是非常浪费空间的。这时候就可以考虑使用布隆过滤器。它可以大幅降低去重存储消耗,只不过也会使得爬虫系统错过少量的页面。
- 邮箱系统的垃圾邮件过滤功能也普遍用到了布隆过滤器,因为用了这个过滤器,所以平时也会遇到某些正常的邮件被放进了垃圾邮件目录中,这个就是误判所致,概率很低。
- Redis防雪崩(缓存穿透)
