作者:小麻姐@毛豆前端
浏览器缓存
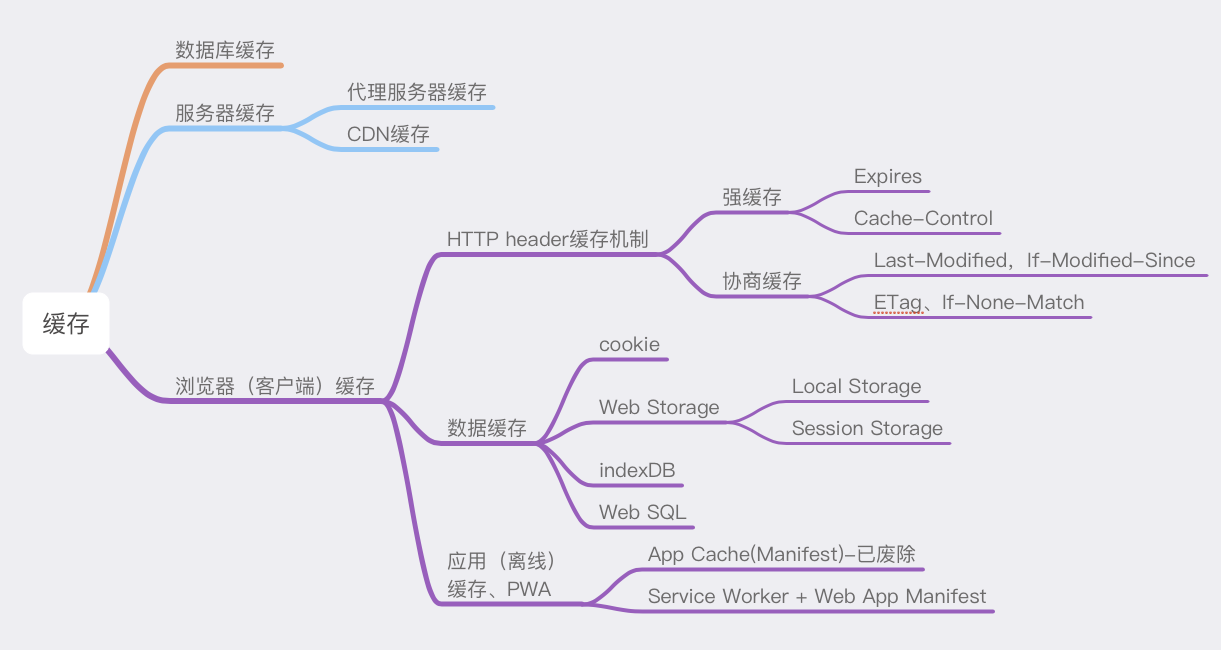
首先用一张图了解下缓存:
为什么要缓存
我们从性能方面分析下为什么要缓存
缓存的作用
缓存能够对已有的资源进行重用,减少延迟和网络阻塞,达到减少某个资源展示的时间。 其实我们对于页面静态资源的要求就两点
1、静态资源加载速度
2、页面渲染速度
页面渲染速度建立在资源加载速度之上,但不同资源类型的加载顺序和时机也会对其产生影响,所以缓存的可操作空间非常大
缓存的应用场景
1、每次都加载某个同样的静态文件 => 浪费带宽,重复请求 => 让浏览器使用本地缓存(协商缓存,返回304)
2、协商缓存还是要和服务器通信 => 依然存在有网络请求 => 强制浏览器使用本地强缓存(返回200)
3、缓存要更新啊,兄弟,网络请求都没了,我咋知道啥时候要更新?=> 让请求(header加上ETag)或者url的修改与文件内容关联(文件名加哈希值)
4、CTO大佬说,我们买了阿里还是腾讯的CDN,几百G呢,用起来啊 => 把静态资源和动态网页分集群部署,静态资源部署到CDN节点上,网页中引用的资源变成对应的部署路径 => html中的资源引用和CDN上的静态资源对应的url地址联系起来了 => 问题来了,更新的时候先上线页面,还是先上线静态资源?(蠢,等到半天三四点啊,用户都睡了,随便你先上哪个)
5、老板说:我们的产品将来是国际化的,不存在所谓的半夜三点 => GG,咋办?=> 用非覆盖式发布啊,用文件的摘要信息来对资源文件进行重命名,把摘要信息放到资源文件发布路径中,这样,内容有修改的资源就变成了一个新的文件发布到线上,不会覆盖已有的资源文件。上线过程中,先全量部署静态资源,再灰度部署页面 (参考网上内容)
各类缓存
数据缓存
1、cookie: 一个用户所请求的操作属于一个会话,而另一个用户所请求的是另一个会话,由于http是无状态的,一旦会话完毕就会关闭,这样无法通过会话保存所请求的内容。 一个用户请求服务器,服务器如需保存用户的信息,则返回的response加cookie信息,浏览器会将cookie保存在浏览器上,下次请求会将请求信息和cookie一起发给浏览器,这样服务器通过cookie信息识别用户信息,甚至修改cookie信息,以此来辨认用户状态。
2、session: 和cookie不同的是,session是保存在服务器上的。服务器通过识别cookie带来的sessin-id,来找到服务器上保存的用户信息,以此来识别用户。
当程序需要为某个浏览器创建session信息的话: 1、程序首先检查该请求是否携带sessionId.
2、携带sessionId的话程序会自己在服务器上查询该sessionId,拿到session信息。如果查询不到,会新建一个一个sessionId
3、请求未携带sessionId,程序会在附服务器上创建一个session,将此session的sessionId返回给浏览器。
缺点:在请求头上,大小4k。
常用的配置属性有以下几个
Expires :cookie最长有效期
Max-Age:在 cookie 失效之前需要经过的秒数。(当Expires和Max-Age同时存在时,文档中给出的是已Max-Age为准,可是我自己用Chrome实验的结果是取二者中最长有效期的值)
Domain:指定 cookie 可以送达的主机名。
Path:指定一个 URL 路径,这个路径必须出现在要请求的资源的路径中才可以发送 Cookie 首部
Secure:一个带有安全属性的 cookie 只有在请求使用SSL和HTTPS协议的时候才会被发送到服务器。
HttpOnly:设置了 HttpOnly 属性的 cookie 不能使用 JavaScript 经由 Document.cookie 属性、XMLHttpRequest 和 Request APIs 进行访问,以防范跨站脚本攻击(XSS)。
storage
1、sessionStorage:
sessionStorage存储在浏览器上,存储内容可以是任何形式(包括:数组、图片、json、样式。。。)等。明文存储,所以一般不会保存较敏感信息。当页面关闭的时候不会保存。
2、localStorage:
同sessionStorage一样,也是存储在浏览器上,存储内容形式多样,明文存储。但是当浏览器关闭的时候,信息仍然会存在。除非人为删除,否则理论上永远存在。
两者存储大小5M左右。
监听storage事件 可以通过监听 window 对象的 storage 事件并指定其事件处理函数,当页面中对 localStorage 或 sessionStorage 进行修改时,则会触发对应的处理函数
window.addEventListener('storage',function(e){
console.log('key='+e.key+',oldValue='+e.oldValue+',newValue='+e.newValue);
})
触发事件的时间对象(e 参数值)有几个属性:
key : 键值。
oldValue : 被修改前的值。
newValue : 被修改后的值。
url : 页面url。
storageArea : 被修改的 storage 对象。
HTTP Header缓存
良好的缓存能降低资源重复加载提升页面加载速度。 缓存分为强缓存和协商缓存
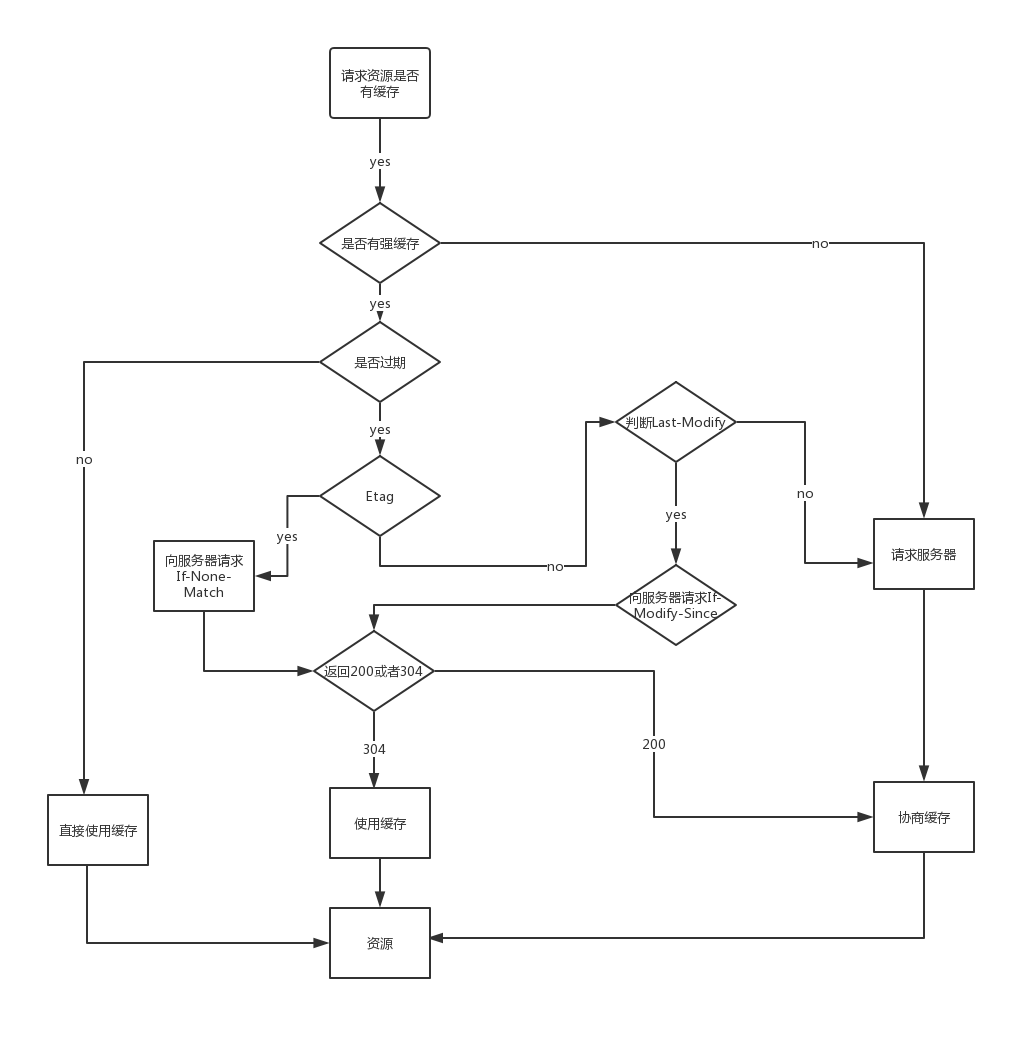
一、基本概述
1、请求原理
1)、浏览器加载资源的时候首先检查请求头的expires和cache-control来判断有没有强缓存,有的话直接使用强缓存。
2)、如果没有命中强缓存,则向服务器发送请求,根据last-modified和etag来检查是否有协商缓存,有的话返回304,直接使用协商缓存。
3)、未命中协商缓存的话则直接从服务器上拉取资源。
2、相同点
命中后都是从浏览器中直接拉取资源。
3、不同点
强缓存不发送请求到服务器,协商缓存则发请求到服务器。
二、强缓存
强缓存主要通过expier和cache-control来表示缓存时间和资源。
1、expire
expire是http1.0 提供的规范。它的值是一个GMT格式的绝对时间值。这代表expire失效的时间,在这个时间之前永远有效。但是这个值是受到浏览器上本地时间影响的,如果浏览器和服务器时间不一致,则会导致缓存混乱。当cache-control: max-age和expire同时存在的时候,max-age优先级高。
2、cache-control
cache-control是http1.1提供的规范。利用max-age来判断缓存时间,是一个相对值。例如cache-control: max-age=1000,则表示缓存在1000秒内有效。
cache-control常用的值:
no-cache:不使用本地缓存。需要使用缓存协商,先与服务器确认返回的响应是否被更改,如果之前的响应中存在ETag,那么请求的时候会与服务端验证,如果资源未被更改,则可以避免重新下载。
no-store:直接禁止游览器缓存数据,每次用户请求该资源,都会向服务器发送一个请求,每次都会下载完整的资源。
public:可以被所有的用户缓存,包括终端用户和CDN等中间代理服务器。
private:只能被终端用户的浏览器缓存,不允许CDN等中继缓存服务器对其缓存。
Cache-Control与Expires可以在服务端配置同时启用,同时启用的时候Cache-Control优先级高。
二、协商缓存
协商缓存就是由服务器来判断缓存是否有效,浏览器和服务器之间协商一个标示,根据该标示来判断是否使用缓存。 这个主要涉及到两组header字段:Etag和If-None-Match、Last-Modified和If-Modified-Since
1、Etag和If-None-Match Etag/If-None-Match返回的是一个校验码。ETag可以保证每一个资源是唯一的,资源变化都会导致ETag变化。服务器根据浏览器上送的If-None-Match值来判断是否命中缓存。
与Last-Modified不一样的是,当服务器返回304 Not Modified的响应时,由于ETag重新生成过,response header中还会把这个ETag返回,即使这个ETag跟之前的没有变化。
2、Last-Modify/If-Modify-Since 浏览器第一次请求一个资源的时候,服务器返回的header中会加上Last-Modify,Last-modify是一个时间标识该资源的最后修改时间。
当浏览器再次请求该资源时,request的请求头中会包含If-Modify-Since,该值为缓存之前返回的Last-Modify。服务器收到If-Modify-Since后,根据资源的最后修改时间判断是否命中缓存。
如果命中缓存,则返回304,并且不会返回资源内容,并且不会返回Last-Modify。
三、缓存流程图