

还记得刚学爬虫的时候,选了一个美女网站来练手,效率极高,看到什么都想爬下来。爬得正高兴呢,出现了一连串错误信息,查看后发现因为爬取太过频繁,被网站封了ip,那时起就有了构建代理ip池的念头。
网上搜索一下代理ip就会发现有很多网站提供,但是稳定好用的都要收费,免费倒也有一堆,但大多数都不能用。而且我写的一般都是小爬虫,极少有爬取上白g数据的时候,用收费的代理ip有点浪费。
所以,写了这个代理ip池,从各大代理ip网站爬取收集免费的代理ip,然后一一进行测试,从中筛选出高速可用的ip。得益于Node的异步架构,速度非常快,可以直接在自己的爬虫里调用,每次爬取前获取最新的代理ip,以后妈妈就再也不用担心我的爬虫被封了。
接下来会分为三个部分来讲解,怎么下载,怎么用和怎么写,如果只是想用的话看前两篇就够了。
1.如何下载
有两种途径,一个是通过Github:Card007/Proxy-Pool;
另一种是通过npm添加:npm install ip-proxy-pool;
两种方式都可以,推荐github,有个使用说明,后期我还会进行更新,欢迎start。
2.如何使用
//导入本地模块
var proxy = require('./proxy_pool.js')
//如果通过npm安装
//var proxy = require('ip-proxy-pool')
//主程序,爬取ip+检查ip
var proxys = proxy.run
//不爬取,只检查数据库里现有的ip
var check = proxy.check
//提取数据库里所有的ip
var ips = proxy.ips
//ips接收一个处理函数,然后向这个函数传递两个参数,一个为错误信息,另一个为数据库里的所有ip
ips((err,response)=>{
console.log(response)
})
//如果希望爬取的ip多一点可以修改check函数里的timeout
3.怎么手动写一个代理ip池
现在来说说自己怎么写一个代理ip池,以西刺为例,用到的工具和方法基本上和上一篇爬取豆瓣top250一样,先是爬取西刺网站前5页的所有免费ip,然后保存在sqlite数据库里,然后通过一一使用爬取好的代理ip访问某个网址,返回200的则是可用,返回其它数字的则删除,来看代码:
//导入相应的库
var request = require('request')
var cheerio = require('cheerio')
var sqlite3 = require('sqlite3')
//生成网址,西刺网址以尾号数字作为分页链接
var ipUrl = function(resolve){
var url = 'http://www.xicidaili.com/nn/'
var options = {
url:'http://www.xicidaili.com/nn/',
headers,
}
//用个简单的for循环即可获得所有需要的链接,然后将链接一一放到爬取网络的requestProxy里
for (let i = 1; i <= 5; i++) {
options.url = url + i
requestProxy(options)
}
}
//链接网络
var requestProxy = function(options){
//这里使用了Promise来控制异步
return new Promise((resolve, reject) => {
request(options, function(err, response, body){
if(err === null && response.statusCode === 200){
//返回200说明爬取成功,loadHtml为解析函数,会将我们需要的信息爬取出来存在数据库里
loadHtml(body)
resolve()
} else {
console.log('链接失败')
resolve()
}
})
})
}
接下来要说到Node的大坑,异步,由于异步架构,需要用到Promise来控制,比如在这个代理ip池里,会出现reqeust函数还没有爬完的时候就开始执行验证函数,很容易出错,所以我们需要分为两组,一组为异步爬取网站爬取,另一组为异步验证代理ip,所以我们来改造一下上面的代码:
//生成网址
var ipUrl = function(resolve){
var url = 'http://www.xicidaili.com/nn/'
var options = {
url:'http://www.xicidaili.com/nn/',
headers,
}
var arr = []
for (let i = 1; i <= 5; i++) {
options.url = url + i
arr.push(requestProxy(options))
}
//Promise.all接收一个数组,直到数组里所有的函数执行完毕才执行后面then里的内容
//实际上放这里有点多余,后期会改过来,先将就
Promise.all(arr).then(function(){
resolve()
})
}
//链接网络
var requestProxy = function(options){
return new Promise((resolve, reject) => {
request(options, function(err, response, body){
if(err === null && response.statusCode === 200){
loadHtml(body)
resolve()
} else {
console.log('链接失败')
resolve()
}
})
})
}
接下来分析一下网页内容,这里我们只需要ip,端口,和类型即可:
//分析网页内容
var loadHtml = function(data){
var l = []
var e = cheerio.load(data)
e('tr').each(function(i, elem){
l[i] = e(this).text()
})
for (let i = 1; i < l.length; i ++){
//在提取到想要的内容后发现太乱,需要额外的函数进行处理优化
clearN(l[i].split(' '))
}
}
//提取优化文件数据,
var clearN = function(l){
var index = 0
for (let i = 0; i < l.length; i++) {
if(l[i] === '' || l[i] === '\n'){
}else{
var ips = l[i].replace('\n','')
if (index === 0){
var ip = ips
console.log('爬取ip:' + ip)
} else if(index === 1){
var port = ips
} else if(index === 4){
var type = ips
}
index += 1
}
}
//存入数据库
insertDb(ip, port, type)
}
接着来实现数据库的存储删除功能:
//打开数据库
var db = new sqlite3.Database('Proxy.db', (err) => {
if(!err){
console.log('打开成功')
} else {
console.log(err)
}
})
db.run('CREATE TABLE proxy(ip char(15), port char(15), type char(15))',(err) => {})
//添加数据文件
var insertDb = function(ip, port, type){
db.run("INSERT INTO proxy VALUES(?, ?, ?)",[ip,port,type])
}
//删除数据库文件
var removeIp = function(ip){
db.run(`DELETE FROM proxy WHERE ip = '${ ip }'`, function(err){
if(err){
console.log(err)
}else {
console.log('成功删除:'+ip)
}
})
}
//从数据库提取所有ip
var allIp = function(callback){
return db.all('select * from proxy', callback)
}
接着将数据库里的ip提取出来,进行测速筛选:
//从数据库提取出来的ip会通过这个类创建一个对象
var Proxys = function(ip,port,type){
this.ip = ip
this.port = port
this.type = type
}
//提取所有ip,通过check函数检查
var runIp = function(resolve){
var arr = []
allIp((err,response) => {
for (let i = 0; i < response.length; i++) {
var ip = response[i]
var proxy = new Proxys(ip.ip, ip.port, ip.type)
arr.push(check(proxy, headers))
}
Promise.all(arr).then(function(){
allIp((err, response)=>{
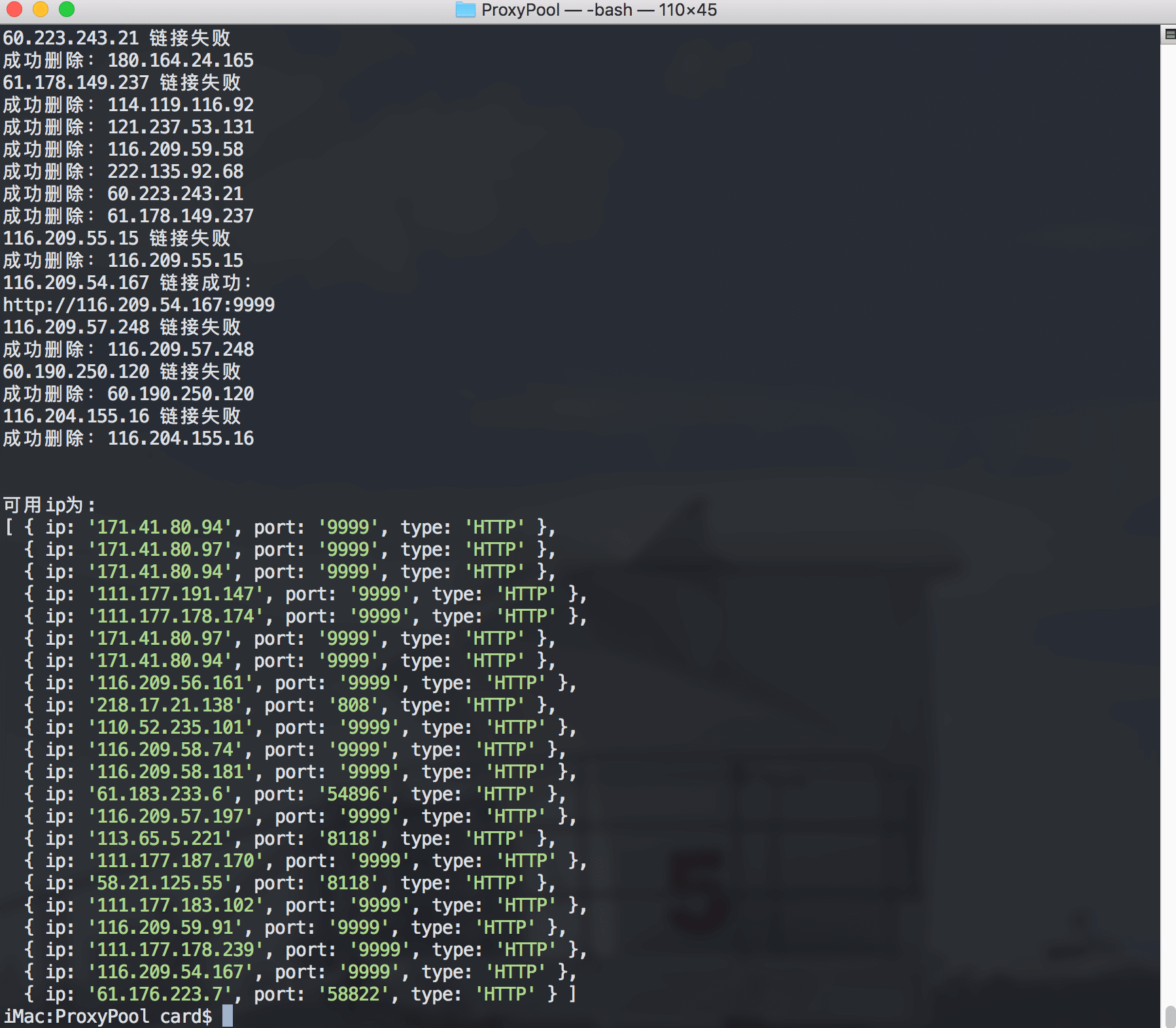
console.log('\n\n可用ip为:')
console.log(response)
})
})
})
}
//检测ip
var check = function(proxy, headers){
return new Promise((resolve, reject) => {
request({
//检测网址为百度的某个js文件,速度快,文件小,非常适合作为检测方式
url:'http://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js',
proxy: `${proxy.type.toLowerCase()}://${proxy.ip}:${proxy.port}`,
method:'GET',
//这里延迟使用了2000,如果希望通过检测的ip多一些,可以适当延长
timeout: 2000,
headers,}
,function(err, response,body){
if(!err && response.statusCode == 200){
console.log(proxy.ip+' 链接成功:')
resolve()
} else {
console.log(proxy.ip+' 链接失败')
removeIp(proxy.ip)
resolve()
}
}
)
})
}
最后,来写几个运行函数:
var run = function(){
new Promise(ipUrl).then(runIp)
}
var rcheck= function(){
runIp()
}
var ips = function(callback){
allIp(callback)
}
大功告成:
完整代码可以通过Github查看:Proxy-Pool
也可以访问我的网站,获取更多文章:Nothlu
