

前言
本篇文章将引入Kafka 0.11,实现真正的实时流计算
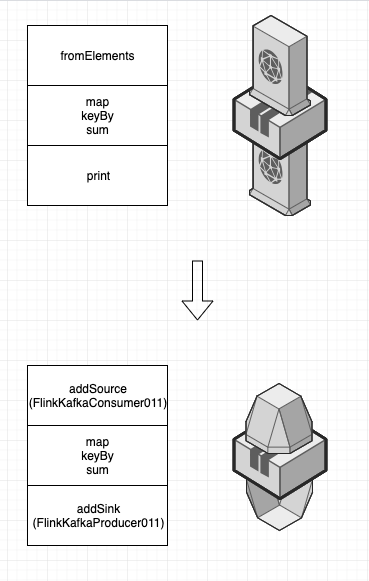
改造
定义消息传递格式
上篇文章我们定义了数据格式,基于此我们来定义kafka的传递数据的格式,即为${timetamp},${word},中间用逗号分隔,好吧我承认看起来是和当时我们定义数据格式是一样的,但是这里要注意的是分隔符的选取
因为我们这里不是复杂的业务场景,不需要用上json,用常用的列分隔符就好,比如csv中用到的逗号,但是这里要注意的是你的${word}里是否会包含有你所选取的分隔符,这点很关键
消息传入改为Kafka
由于引入了Kafka,我们就要传入参数,这里解析参数用的是官方采用的方法
val params = ParameterTool.fromArgs(args)
然后我们用参数来创建一个FlinkKafkaConsumer011对象,通过env.addSource添加到环境中
val dataStream = env.addSource(
new FlinkKafkaConsumer011[(String)](
params.getRequired("input.topic"),new SimpleStringSchema, params.getProperties)).uid("add-source")
这里我们只是用了SimpleStringSchema来解析Kafka中消息为字符串,我们还需要一步map操作进行数据转换
.map{x =>
val arr = x.split(",")
if(arr.length != 2){
println(s"解析${x}失败")
return null
}else {
(arr(0), arr(1))
}
}.filter(_ != null)
这里做了一个容错处理,如果解析失败的话,就会返回一个null,意即把一个null数据传递给下一个operator,然后我们再用一个filter对它进行过滤
这一步我们做完了,就可以开始测试一波了
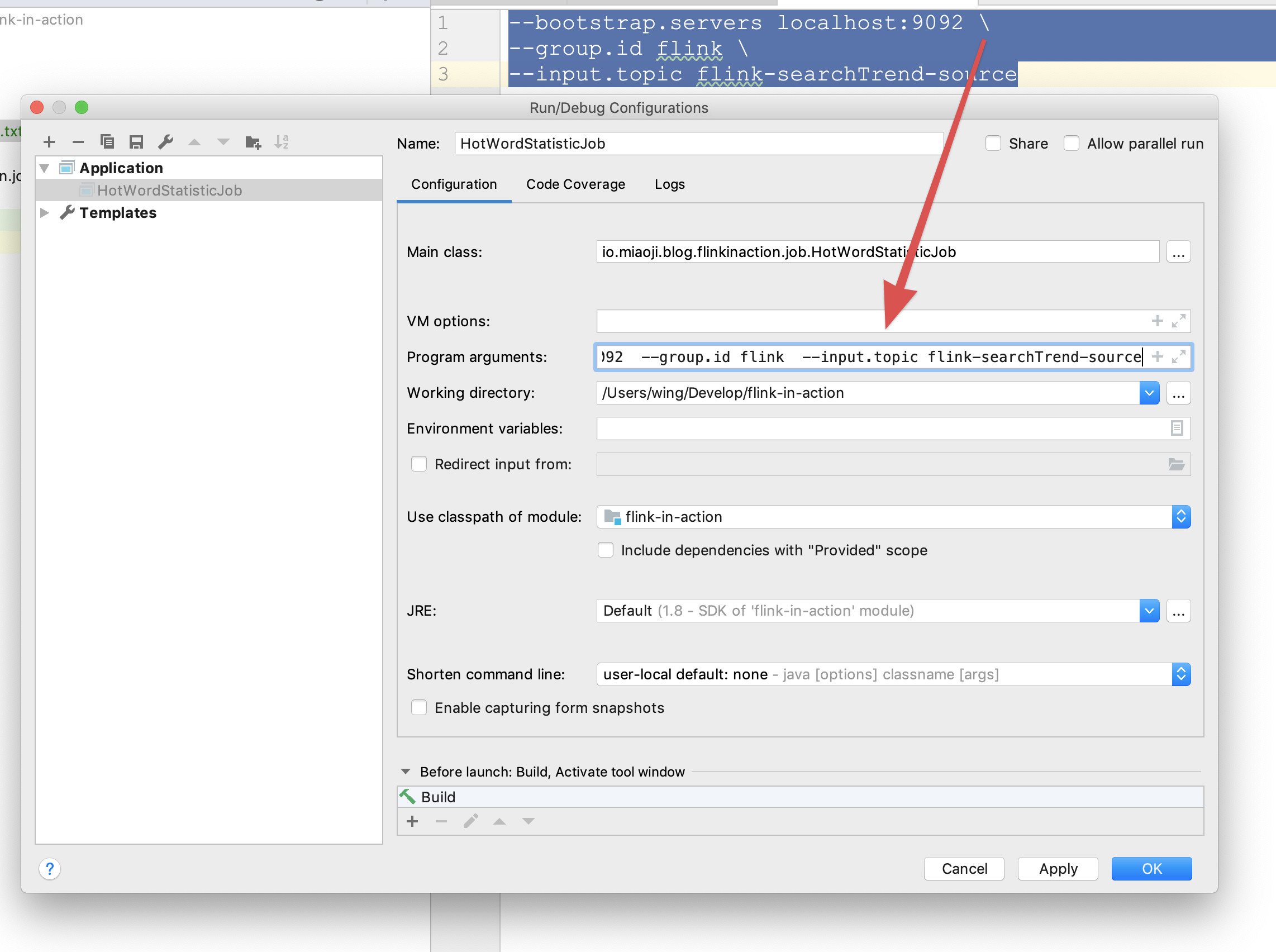
--bootstrap.servers localhost:9092
--group.id flink
--input.topic flink-searchTrend-source
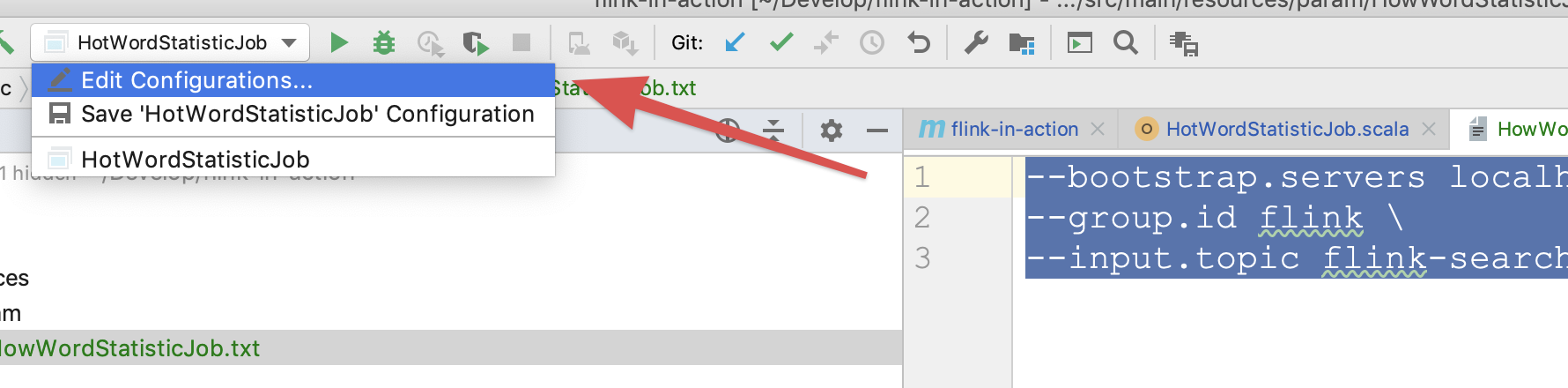
我们将参数存在txt文档里,方便以后复制 在本地调试时可以将参数粘贴进如图所示的输入框中,然后运行main方法
这里调试的时候建议用kafka的命令行命令,如下
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic flink-hotWordStatisticJob-source
这里我们先把对消息传入的这一环节改造的部分调通,再进行下一步骤
消息输出改为Kafka
我们把之前计算后的DataStream赋值给resultDataStream,然后给其设定数据输出口,即Sink,当然事先也得把它变成字符串
resultDataStream.map(x => s"${x._2},${x._3}").addSink(
new FlinkKafkaProducer011[String](
params.getRequired("output.topic"),new SimpleStringSchema,params.getProperties
)
)
参数中增加一个
--output.topic flink-hotWordStatisticJob-sink
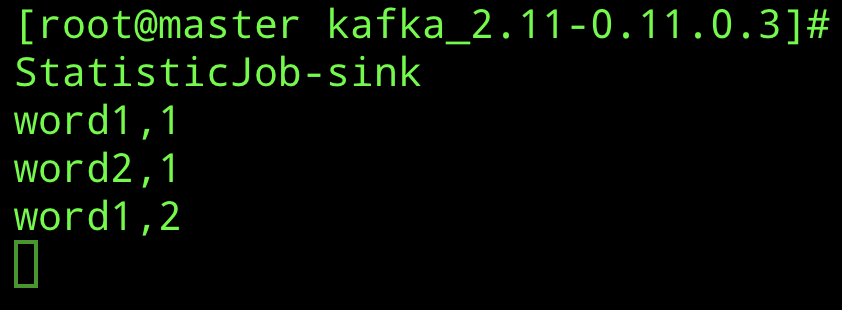
最后的效果
输入消息
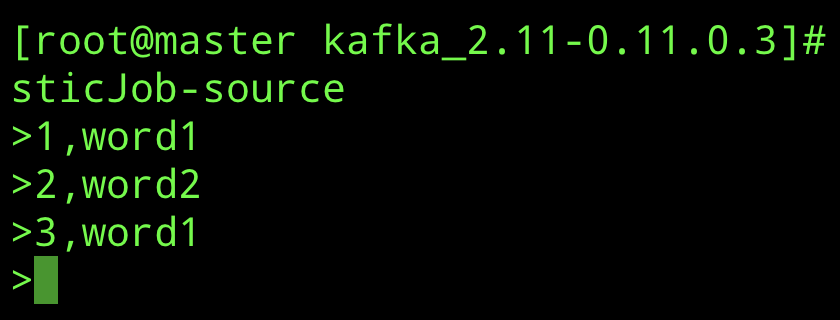
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic flink-hotWordStatisticJob-sink
结尾
如果产品设计的需求就是热词统计一直累加的话,那么写到这,代码就可以部署至生产了,当然他以后肯定是会变的
