问题定义
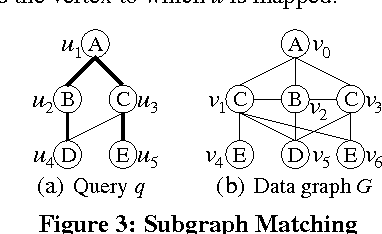
子图匹配:假设有两个图 和图
子图 同构即从
到
存在这样一个函数
并且
使得
同样成立
叫做子图同构的一个映射。在这篇论文中,两个图的顶点都是带
属性的,这样还需要满足
.
论文的核心想法
主要讨论如何通过推迟笛卡尔积操作来减少子图匹配运算的中间结果数量
- 在一个个查询点进行匹配的过程中,实时构建一个叫压缩路径索引(compact path-index,CPI)的数据结构来存储所有查询点的候选以及候选之间的连接关系。
算法的大体流程
- 基于查询图
和数据图
构建CPI
- 将查询图
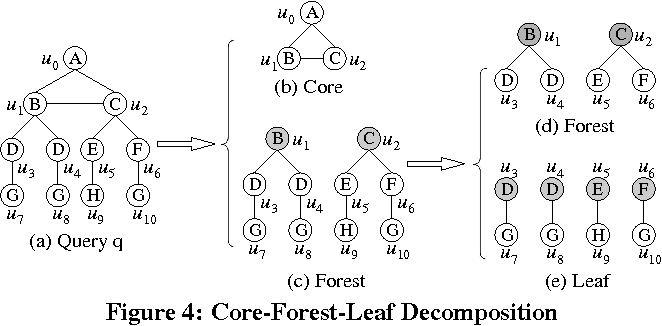
- 将查询图上的点分成三种:核心点(Core)、森林点(Forest)和叶子点(Leaf)
- 核心点就是查询图中满足如下要求的点:任意一个生成树中这个点都不会包含生成树以外的相邻边;
- 叶子点就是查询图中度数为1的点;
- 森林点就是其它点
- 步骤
- 拿出一个查询图中所有度数为1的点,这些点作为叶子点;
- 然后,去掉叶子点之后,度数为1的点就是森林点;
- 这些森林点再被去掉,剩下的结构中度数为1的点还是森林点,如此迭代,直到图中没有剩下度数为1点;
- 剩下的点就是核心点。
- 直接使用CPI,查询点匹配顺序一定按照核心点,森林点和叶子点计算
算法的具体过程
CPI 简介
本文根据查询图构建一个所谓的压缩路径索引(compact path-index,CPI)来实现查询匹配。
-
压缩路径索引就是一个基于查询图宽度优先搜索树的数据图组织方式。
-
在这个查询图宽度优先搜索树之上,每个查询点
都对应一个候选集合
来存储
算法流程
- 挑选候选匹配少且相邻边多的点作为CPI的根,进而得到CPI背后的宽度优先搜索树(CPI构建的具体过程参考下面)
- 根据这个CPI来确定查询点匹配,查询点匹配顺序列表为seq。
- 核心部分
- 首先,对于核心点部分,本文可以根据CPI得到从根到叶子的k条路径p1, p2, …, pk。
- 然后,本文定义一个代价模型确定各个路径的匹配代价,假设k条路径代价从大到小仍然是p1, p2, …, pk
- 最后,依次将p1, p2, …, pk中各个查询点放到seq中,seq中出现过的点不重复出现。
- 森林点和核心部分类似,也是先得到若干条路径,再依次放进seq中。
- 叶子点匹配顺序按照叶子点匹配数量来定
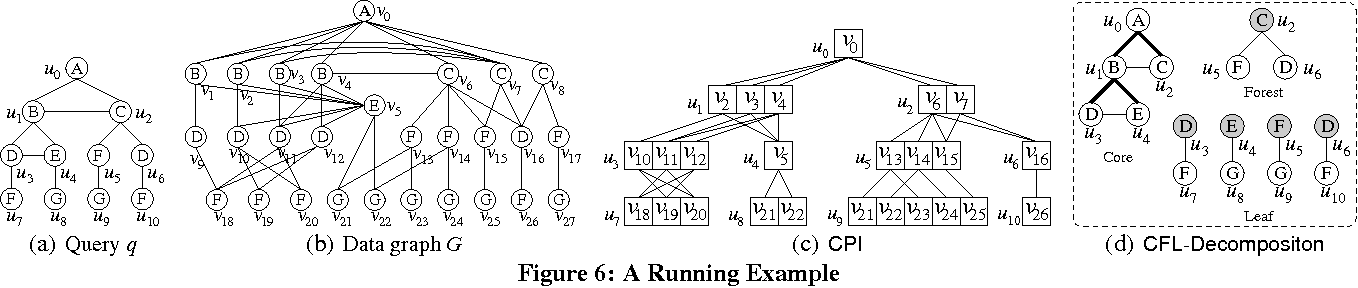
CPI的构建

构建过程
- 按宽度优先搜索树的层次从顶向下依次得到每个查询点的匹配。
- 对于每一层,都尽可能多地利用每个点的父亲节点的匹配候选以及这层中其他兄弟节点的匹配候选来剪枝掉其的匹配候选。
- 利用每个匹配候选的邻接表来得到CPI。
- 在这个CPI上进行自底向上地剪枝,即利用每个点的孩子节点的匹配候选来剪枝掉其的匹配候选。
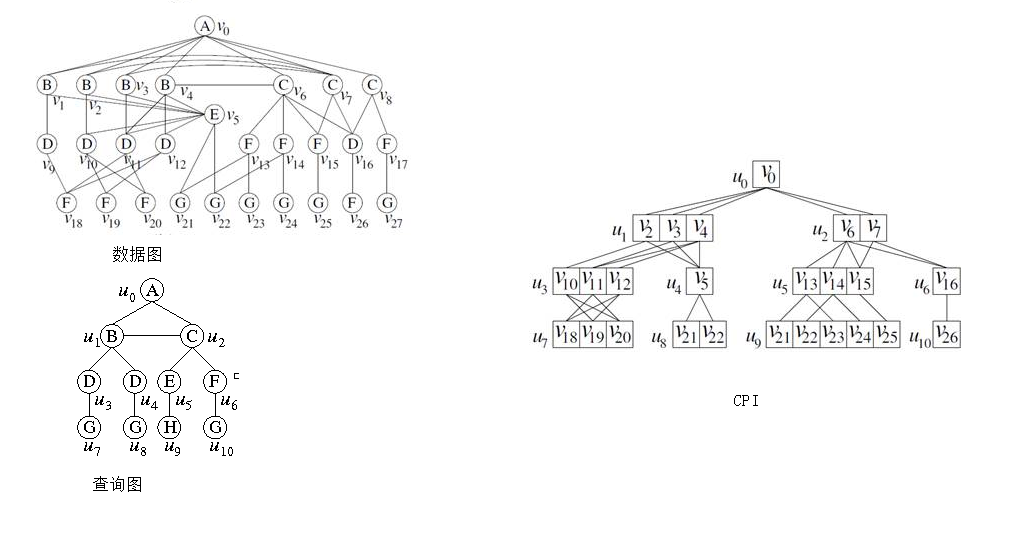
例子
自上向下的构建
考虑图中的查询
和图
中的BFS树,其中
是根顶点。然后q的顶点被划分为三个级别,
级别为1,
级别为2,
级别为3级。
- 处理级别1的顶点(即
)。
- 考虑级别2的顶点(即
和
)。
- 正向处理,我们首先处理
和
;
被指定为具有相同标签
的顶点集合,并且与顶点
相邻,并且
。其次处理
和
;
被指定为具有相同标签
的顶点集合,并且与顶点
相邻,并且
,但由于需要
。
- 后向处理,
由于在
- 邻接列表构造,邻接列表构造如图
所示。
- 正向处理,我们首先处理
- 依次类推第三层
自下向上的改进
- 继续上面例子我们以
的自下而上的方式细化
的顺序处理。
- 首先,
没有较低级别的邻居,我们什么都不做。在处理
来细化
从
- 接下来,在处理
,并且还删除
所示。
- 最后,我们处理
- 首先,
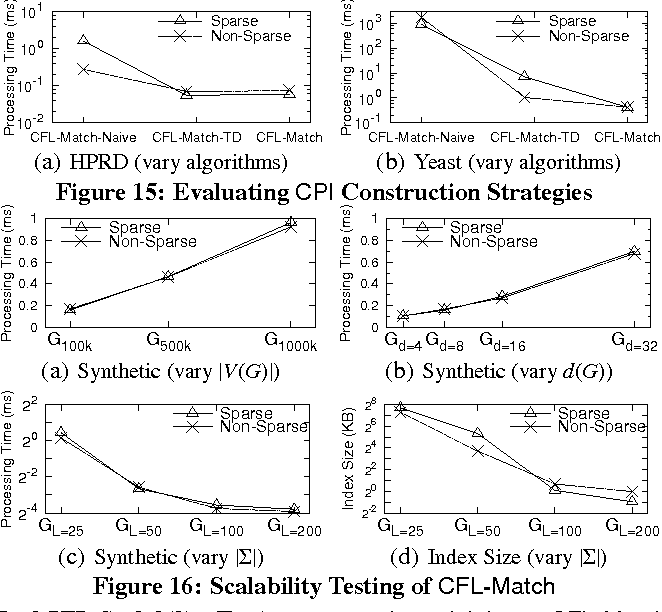
实验
和现有方法方法比

新框架的有效性