

前言
长文预警。该文主要介绍因线上OOM而引发的问题定位、分析问题的原因、以及如何解决问题。在分析问题原因时候为了能更详细的呈现出引发问题的原因,去翻了hdfs 提供的Java Api主要的类FileSystem的部分代码。由于这部分源代码的分析实在是太太太长了,可以直接跳过看最后的结论,当然有兴趣的可以看下。
风起
一日,突然收到若干线上告警。于是赶紧查看日志,在日志中大量线程报出OOM错误:
Exception in thread "http-nio-8182-exec-29" java.lang.OutOfMemoryError: Java heap space
于是使用jstat命令查看该进程内存使用情况:jstat -gcutil 12492 1000 100
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 100.00 99.89 96.78 94.41 200 1.272 2925 328.850 330.122
0.00 0.00 99.89 99.89 96.78 94.41 200 1.272 2935 329.908 331.180
0.00 0.00 100.00 99.89 96.78 94.41 200 1.272 2944 330.853 332.125
0.00 0.00 99.89 99.89 96.78 94.41 200 1.272 2955 332.002 333.274
0.00 0.00 100.00 99.89 96.78 94.41 200 1.272 2964 332.940 334.212
0.00 0.00 100.00 99.89 96.78 94.41 200 1.272 2973 333.924 335.196
可以看出,该进程老年代内存耗尽,导致OOM,且引发了频繁的FGC。而在对堆参数配置中是完全能满足项目运行的,于是查看了其他几个节点的内存使用情况,老年代使用率都高达98以上且FGC次数也在增加。
由于线上环境影响业务,便dump出内存快照,然后临时重启了节点,重启之后查看内存使用情况: jstat -gcutil 18190 1000 10
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
1.04 0.00 50.39 22.87 95.96 93.41 1680 20.542 4 0.136 20.679
1.04 0.00 50.39 22.87 95.96 93.41 1680 20.542 4 0.136 20.679
1.04 0.00 50.39 22.87 95.96 93.41 1680 20.542 4 0.136 20.679
虽然暂时业务恢复,但该问题还是需要解决的。从上能初步分析出问题是由于内存泄漏,导致在运行一段时间之后OOM。
定位
在将dump出的快照导入MAT中查看,并没有找到特别大的对象,但是看见很多个org.apache.hadoop.conf.Configuration实例。在代码中使用了hdfs的API操作hdfs,该类为连接hdfs的配置类。如下:
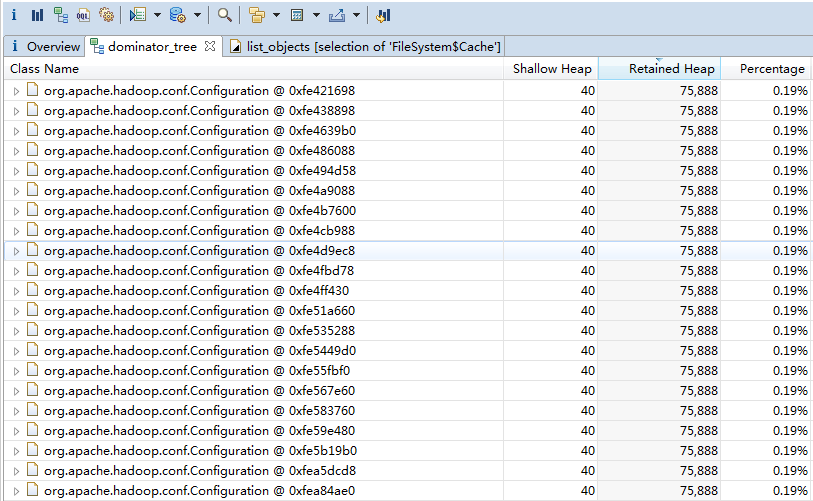
于是在本地debug启动一个与线上相同代码的进程,并dump出该内存快照。在MAT中查看该Configuration类的实例,仅一个实例。到此,差不多能定位是通过Java Api与hdfs交互时,导致某些对象不能回收出现的问题。
然后在本地编写测试接口,通过测试接口访问hdfs,发现该Configuration类实例在增加,且在执行GC的时候并不能回收。
至此,内存泄漏的源头可以说找到了,至于为什么会出现问题则需要查看这段代码了。
原因
大致能确认,导致内存泄漏的原因是与hdfs交互时某段代码bug。于是翻开了项目中与hdfs交互的类,发现了等价于下面的代码的访问hdfs代码:
public Path createDir(String name) throws IOException, InterruptedException {
Path path = new Path(name);
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(URI.create("hdfs://***:8020"), configuration, "hdfs");;
if (fileSystem.mkdirs(path)) {
return path;
}
return null;
}
也就是说,在每次与hdfs交互时,都会与hdfs建立一次连接,并创建一个FileSystem对象。但在使用完之后并未调用close()方法释放连接。
此处可能会有疑问,此处的Configuration实例和FileSystem实例都是局部变量,在该方法执行完成之后,这两个对象都应该是会被回收的,怎么会导致内存泄漏呢?
FileSystem是怎样获取的
在此,如果想知道该问题,就需要去翻FileSystem类的代码了。FileSystem的get方法如下:
public static FileSystem get(URI uri, Configuration conf) throws IOException {
String scheme = uri.getScheme();
String authority = uri.getAuthority();
if (scheme == null && authority == null) { // use default FS
return get(conf);
}
if (scheme != null && authority == null) { // no authority
URI defaultUri = getDefaultUri(conf);
if (scheme.equals(defaultUri.getScheme()) // if scheme matches default
&& defaultUri.getAuthority() != null) { // & default has authority
return get(defaultUri, conf); // return default
}
}
String disableCacheName = String.format("fs.%s.impl.disable.cache", scheme);
if (conf.getBoolean(disableCacheName, false)) {
return createFileSystem(uri, conf);
}
return CACHE.get(uri, conf);
}
重点看一下最后的6行代码,其中String.format("fs.%s.impl.disable.cache", scheme)在连接hdfs时候该参数名为fs.hdfs.impl.disable.cache,可以从倒数第5行代码看出该参数默认值为false。也就是默认情况下会通过CACHE对象返回FileSystem。
那接下来看一下CACHE.get方法:
FileSystem get(URI uri, Configuration conf) throws IOException{
Key key = new Key(uri, conf);
return getInternal(uri, conf, key);
}
private FileSystem getInternal(URI uri, Configuration conf, Key key) throws IOException{
FileSystem fs;
synchronized (this) {
fs = map.get(key);
}
if (fs != null) {
return fs;
}
fs = createFileSystem(uri, conf);
synchronized (this) { // refetch the lock again
FileSystem oldfs = map.get(key);
if (oldfs != null) { // a file system is created while lock is releasing
fs.close(); // close the new file system
return oldfs; // return the old file system
}
// now insert the new file system into the map
if (map.isEmpty()
&& !ShutdownHookManager.get().isShutdownInProgress()) {
ShutdownHookManager.get().addShutdownHook(clientFinalizer, SHUTDOWN_HOOK_PRIORITY);
}
fs.key = key;
map.put(key, fs);
if (conf.getBoolean("fs.automatic.close", true)) {
toAutoClose.add(key);
}
return fs;
}
}
从这段代码中可以看出:
- 在Cache类内部维护了一个Map,该Map用于缓存已经连接好的FileSystem对象,Map的Kep为Cache.Key对象。每次都会通过Cache.Key获取FileSystem,如果未获取到,才会继续创建的流程。
- 在Cache类内部维护了一个Set(toAutoClose),该Set用于存放需自动关闭的连接。在客户端关闭时会自动关闭该集合中的连接。
在看完了上面的代码之后,在看一下CACHE这个变量在FileSystem中是怎样引用的:
/** FileSystem cache */
static final Cache CACHE = new Cache();
也就是说,该CACHE对象会一直存在不会被回收。而每次创建的FileSystem都会以Cache.Key为key,FileSystem为Value存储在Cache类中的Map中。那至于在缓存时候是否对于相同hdfs URI是否会存在多次缓存,就需要查看一下Cache.Key的hashCode方法了,如下:
@Override
public int hashCode() {
return (scheme + authority).hashCode() + ugi.hashCode() + (int)unique;
}
可见,schema和authority变量为String类型,如果在相同的URI情况下,其hashCode是一致。unique在FilSystem.getApi下也不用关心,因为每次该参数的值都是0。那么此处需要重点关注一下ugi.hashCode()。
至此,来小结一下:
- 在获取FileSystem时,FileSystem内置了一个static的Cache,该Cache内部有一个Map,用于缓存已经获取的FileSystem连接。
- 参数fs.hdfs.impl.disable.cache,用于控制FileSystem是否需要缓存,默认情况下是false,即缓存。
- Cache中的Map,Key为Cache.Key类,该类通过schem,authority,UserGroupInformation,unique 4个参数来确定一个Key,如上Cache.Key的hashCode方法。
但还有一个问题,既然FileSystem提供了Cache来缓存,那么在本例中对于相同的hdfs连接是不会出现每次获取FileSystem都往Cache的Map中添加一个新的FileSystem。唯一的解释是Cache.key的hashCode每次计算出来了不一样的值,在Cache.Key的hashCode方法中决定相同的hdfs URI计算hashCode是否一致是由UserGroupInformation的hashCode方法决定的,接下来看一下该方法。
UserGroupInformation.hashCode
其方法定义如下:
@Override
public int hashCode() {
return System.identityHashCode(subject);
}
该方法调用了本地方法identityHashCode,identityHashCod方法对不同的对象返回的hashCode将会不一样,即使是实现了hashCode()的类。那么此处问题关键就转化为UserGroupInformation类的subject是否在每次计算hashCode的时候是同一个对象。
由于该hashCode是计算Cache.key的hashCode时调用的,因此需要看Cache.Key初始化时候,是如何初始化UserGroupInformation该对象的,如下:
Key(URI uri, Configuration conf, long unique) throws IOException {
scheme = uri.getScheme()==null ?
"" : StringUtils.toLowerCase(uri.getScheme());
authority = uri.getAuthority()==null ?
"" : StringUtils.toLowerCase(uri.getAuthority());
this.unique = unique;
this.ugi = UserGroupInformation.getCurrentUser();
}
继续看UserGroupInformation的getCurrentUser()方法,如下:
public synchronized
static UserGroupInformation getCurrentUser() throws IOException {
AccessControlContext context = AccessController.getContext();
Subject subject = Subject.getSubject(context);
if (subject == null || subject.getPrincipals(User.class).isEmpty()) {
return getLoginUser();
} else {
return new UserGroupInformation(subject);
}
}
其中比较关键的就是是否能通过AccessControlContext获取到Subject对象。在本例中通过get(final URI uri, final Configuration conf,final String user)获取时候,在debug调试时,发现此处每次都能获取到一个新的Subject对象(后面会解释为何每次都能获取到一个新的Subject对象)。此处,先看一下获取AccessControlContext的代码,如下:
public static AccessControlContext getContext()
{
AccessControlContext acc = getStackAccessControlContext();
if (acc == null) {
// all we had was privileged system code. We don't want
// to return null though, so we construct a real ACC.
return new AccessControlContext(null, true);
} else {
return acc.optimize();
}
}
其中比较关键的是getStackAccessControlContext方法,该方法调用了Native方法,如下:
private static native AccessControlContext getStackAccessControlContext();
该方法会返回当前堆栈的保护域权限的AccessControlContext对象。(关于该方法更多细节未深究,懂的大佬可指出来一下)
那么此处为什么会返回不同的Subject对象呢?由于在本例中是通过get(final URI uri, final Configuration conf,final String user) Api获取的,因此折回去看一下这个方法,如下:
public static FileSystem get(final URI uri, final Configuration conf,
final String user) throws IOException, InterruptedException {
String ticketCachePath =
conf.get(CommonConfigurationKeys.KERBEROS_TICKET_CACHE_PATH);
UserGroupInformation ugi =
UserGroupInformation.getBestUGI(ticketCachePath, user);
return ugi.doAs(new PrivilegedExceptionAction<FileSystem>() {
@Override
public FileSystem run() throws IOException {
return get(uri, conf);
}
});
}
在该方法中,先通过UserGroupInformation.getBestUGI方法获取了一个UserGroupInformation对象,然后在通过UserGroupInformation的doAs方法去调用了get(URI uri, Configuration conf)方法。
先看一下UserGroupInformation.getBestUGI方法的实现,此处关注一下传入的两个参数ticketCachePath,user。ticketCachePath是获取配置hadoop.security.kerberos.ticket.cache.path的值,在本例中该参数未配置,因此ticketCachePath为空。user参数由于是本例中传入的用户名,因此该参数不会为空。实现如下:
public static UserGroupInformation getBestUGI(
String ticketCachePath, String user) throws IOException {
if (ticketCachePath != null) {
return getUGIFromTicketCache(ticketCachePath, user);
} else if (user == null) {
return getCurrentUser();
} else {
return createRemoteUser(user);
}
}
getBestUGI参数的两个参数,如上所分析ticketCachePath为空,user不为空,因此最终会执行createRemoteUser方法。实现如下:
public static UserGroupInformation createRemoteUser(String user) {
return createRemoteUser(user, AuthMethod.SIMPLE);
}
public static UserGroupInformation createRemoteUser(String user, AuthMethod authMethod) {
if (user == null || user.isEmpty()) {
throw new IllegalArgumentException("Null user");
}
Subject subject = new Subject();
subject.getPrincipals().add(new User(user));
UserGroupInformation result = new UserGroupInformation(subject);
result.setAuthenticationMethod(authMethod);
return result;
}
从代码中,可以看出会通过createRemoteUser方法,来创建一个UserGroupInformation对象。在createRemoteUser方法中,创建了一个新的Subject对象,并通过该对象创建了UserGroupInformation对象。至此,UserGroupInformation.getBestUGI方法执行完成。
接下来看一下UserGroupInformation.doAs方法(FileSystem.get(final URI uri, final Configuration conf, final String user)执行的最后一个方法),如下:
public <T> T doAs(PrivilegedExceptionAction<T> action
) throws IOException, InterruptedException {
try {
logPrivilegedAction(subject, action);
return Subject.doAs(subject, action);
………… 省略多余的
然后在调用Subject.doAs方法,如下:
public static <T> T doAs(final Subject subject,
final java.security.PrivilegedExceptionAction<T> action)
throws java.security.PrivilegedActionException {
java.lang.SecurityManager sm = System.getSecurityManager();
if (sm != null) {
sm.checkPermission(AuthPermissionHolder.DO_AS_PERMISSION);
}
if (action == null)
throw new NullPointerException
(ResourcesMgr.getString("invalid.null.action.provided"));
// set up the new Subject-based AccessControlContext for doPrivileged
final AccessControlContext currentAcc = AccessController.getContext();
// call doPrivileged and push this new context on the stack
return java.security.AccessController.doPrivileged
(action,
createContext(subject, currentAcc));
}
最后在调用AccessController.doPrivileged方法,如下:
public static native <T> T
doPrivileged(PrivilegedExceptionAction<T> action,
AccessControlContext context)
throws PrivilegedActionException;
该方法为Native方法,该方法会使用指定的AccessControlContext来执行PrivilegedExceptionAction,也就是调用该实现的run方法。即FileSystem.get(uri, conf)方法。
至此,就能够解释在本例中,通过get(final URI uri, final Configuration conf,final String user) 方法创建FileSystem时,每次存入FileSystem的Cache中的Cache.key的hashCode都不一致的情况了,小结一下:
- 在通过get(final URI uri, final Configuration conf,final String user)方法创建FileSystem时,由于每次都会创建新的UserGroupInformation和Subject对象。
- 在Cache.Key对象计算hashCode时,影响计算结果的是调用了UserGroupInformation.hashCode方法。
- UserGroupInformation.hashCode方法,计算为:System.identityHashCode(subject)。即如果Subject是同一个对象则返回相同的hashCode,由于在本例中每次都不一样,因此计算的hashCode不一致。
- 综上,就导致每次计算Cache.key的hashCode不一致,便会重复写入FileSystem的Cache。
FileSystem的两个get方法
在FileSystem中,有两个重载的get方法,如下:
public static FileSystem get(final URI uri, final Configuration conf,
final String user)
public static FileSystem get(URI uri, Configuration conf)
在前面已经详细的解读了第一个方法,从代码中可以看第一个最终还是会调用第二个方法。唯一不同的地方就是在初始化Cache.key获取UserGroupInformation对象的时候,如下:
Key(URI uri, Configuration conf, long unique) throws IOException {
scheme = uri.getScheme()==null ?
"" : StringUtils.toLowerCase(uri.getScheme());
authority = uri.getAuthority()==null ?
"" : StringUtils.toLowerCase(uri.getAuthority());
this.unique = unique;
this.ugi = UserGroupInformation.getCurrentUser();
}
该方法会调用UserGroupInformation.getCurrentUser方法,如下:
public synchronized
static UserGroupInformation getCurrentUser() throws IOException {
AccessControlContext context = AccessController.getContext();
Subject subject = Subject.getSubject(context);
if (subject == null || subject.getPrincipals(User.class).isEmpty()) {
return getLoginUser();
} else {
return new UserGroupInformation(subject);
}
}
在直接调用get(URI uri, Configuration conf)方法时,由于未像get(final URI uri, final Configuration conf, final String user)方法创建Subject对象,因此此处Subject会返回空,会继续执行getLoginUser方法。如下:
public synchronized
static UserGroupInformation getLoginUser() throws IOException {
if (loginUser == null) {
loginUserFromSubject(null);
}
return loginUser;
}
由代码可见,loginUser成员变量是关键,查看一下该成员定义,如下:
/**
* Information about the logged in user.
*/
private static UserGroupInformation loginUser = null;
也就是说,一旦该loginUser对象初始化成功,那么后续会一直使用该对象。如上一节所示,UserGroupInformation.hashCode方法将会返回一样的hashCode值。也就是能成功的使用到缓存在FileSystem的Cache。
解决
- 使用public static FileSystem get(URI uri, Configuration conf):
- 该方法是能够使用到FileSystem的Cache的,也就是说对于同一个hdfs URI是只会有一个FileSystem连接对象的。
- 使用此Api可通过System.setProperty("HADOOP_USER_NAME", "hive")方式设置访问用户。(如果有更优雅方式,望大佬指出)
- 默认情况下fs.automatic.close=true,即所有的连接都会通过ShutdownHook关闭。
- 使用public static FileSystem get(final URI uri, final Configuration conf, final String user):
- 该方法如上分析,会导致FileSystem的Cache失效,且每次都会添加至Cache的Map中,导致不能被回收。
- 在使用时,一种方案是:保证对于同一个hdfs URI只会存在一个FileSystem连接对象。
- 另一种方案是:在每次使用完FileSystem之后,调用close方法,该方法会将Cache中的FileSystem删除。
在FileSystem中,还提供了了newInstance等Api。该系列Api每次都会返回一个新的FileSystem,具体实现参见FileSystem代码。
反思
- 在使用开源包时,需详细了解其实现,否则可能因为一时疏忽出现问题。
- code review 是很有必要的。
- 完善线上的监控机制。
~~以上为个人理解,由于水平有限,如有疏漏,望多多指教 ~~
