


一. 前言
NetDiscovery 是本人开发的一款基于 Vert.x、RxJava 2 等框架实现的通用爬虫框架。它包含了丰富的特性。
二. 多线程的使用
NetDiscovery 虽然借助了 RxJava 2 来实现线程的切换,仍然有大量使用多线程的场景。本文列举一些爬虫框架常见的多线程使用场景。
2.1 爬虫的暂停、恢复
暂停和恢复是最常见的爬虫使用场景,这里借助 CountDownLatch 类实现。
CountDownLatch是一个同步工具类,它允许一个或多个线程一直等待,直到其他线程的操作执行完后再执行。
暂停方法会初始化一个 CountDownLatch 类 pauseCountDown,并设置它的计数值为1。
恢复方法会执行 pauseCountDown 的 countDown() ,正好它的计数到达零。
/**
* 爬虫暂停,当前正在抓取的请求会继续抓取完成,之后的请求会等到resume的调用才继续抓取
*/
public void pause() {
this.pauseCountDown = new CountDownLatch(1);
this.pause = true;
stat.compareAndSet(SPIDER_STATUS_RUNNING, SPIDER_STATUS_PAUSE);
}
/**
* 爬虫重新开始
*/
public void resume() {
if (stat.get() == SPIDER_STATUS_PAUSE
&& this.pauseCountDown!=null) {
this.pauseCountDown.countDown();
this.pause = false;
stat.compareAndSet(SPIDER_STATUS_PAUSE, SPIDER_STATUS_RUNNING);
}
}
从消息队列中取出爬虫的 Request 时,会先判断是否需要暂停爬虫的行为,如果需要暂停则执行 pauseCountDown 的 await()。await() 会使线程一直受阻塞,也就是暂停爬虫的行为,直到 CountDownLatch 的计数为0,此时正好能够恢复爬虫运行的状态。
while (getSpiderStatus() != SPIDER_STATUS_STOPPED) {
//暂停抓取
if (pause && pauseCountDown!=null) {
try {
this.pauseCountDown.await();
} catch (InterruptedException e) {
log.error("can't pause : ", e);
}
initialDelay();
}
// 从消息队列中取出request
final Request request = queue.poll(name);
......
}
2.2 多纬度控制爬取速度
下图反映了单个爬虫的流程。
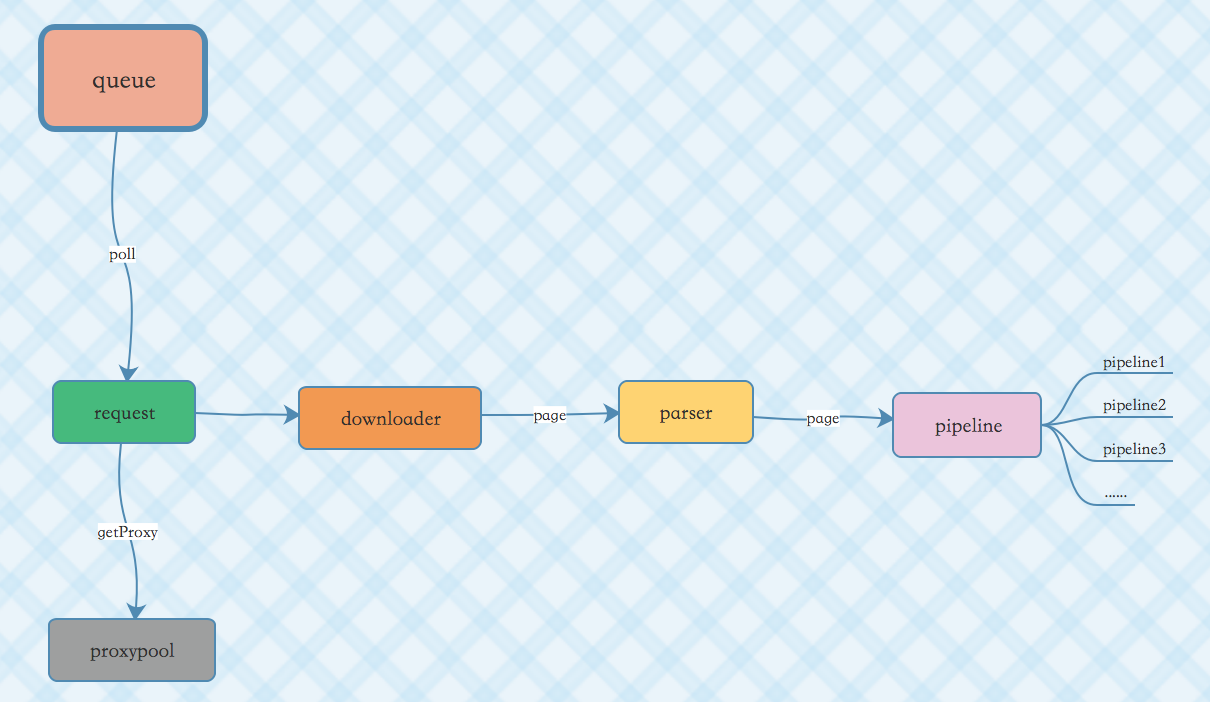
如果爬虫爬取速度太快一定会被对方系统识别,NetDiscovery 可以通过限速来实现基本的反反爬虫。
在 NetDiscovery 内部支持多个纬度实现爬虫限速。这些纬度也基本上对应了单个爬虫的流程。
2.2.1 Request
首先,爬虫封装的请求 Request 支持暂停。从消息队列取出 Request 之后,会校验该 Request 是否需要暂停。
while (getSpiderStatus() != SPIDER_STATUS_STOPPED) {
//暂停抓取
......
// 从消息队列中取出request
final Request request = queue.poll(name);
if (request == null) {
waitNewRequest();
} else {
if (request.getSleepTime() > 0) {
try {
Thread.sleep(request.getSleepTime());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
......
}
}
2.2.2 Download
爬虫下载时,下载器会创建 RxJava 的 Maybe 对象。Download 的限速借助于 RxJava 的 compose、Transformer 来实现。
下面的代码展示了 DownloaderDelayTransformer:
import cn.netdiscovery.core.domain.Request;
import io.reactivex.Maybe;
import io.reactivex.MaybeSource;
import io.reactivex.MaybeTransformer;
import java.util.concurrent.TimeUnit;
/**
* Created by tony on 2019-04-26.
*/
public class DownloaderDelayTransformer implements MaybeTransformer {
private Request request;
public DownloaderDelayTransformer(Request request) {
this.request = request;
}
@Override
public MaybeSource apply(Maybe upstream) {
return request.getDownloadDelay() > 0 ? upstream.delay(request.getDownloadDelay(), TimeUnit.MILLISECONDS) : upstream;
}
}
下载器只要借助 compose 、DownloaderDelayTransformer,就可以实现 Download 的限速。
以 UrlConnectionDownloader 为例:
Maybe.create(new MaybeOnSubscribe<InputStream>() {
@Override
public void subscribe(MaybeEmitter<InputStream> emitter) throws Exception {
emitter.onSuccess(httpUrlConnection.getInputStream());
}
})
.compose(new DownloaderDelayTransformer(request))
.map(new Function<InputStream, Response>() {
@Override
public Response apply(InputStream inputStream) throws Exception {
......
return response;
}
});
2.2.3 Domain
Domain 的限速参考了 Scrapy 框架的实现,将每个域名以及它对应的最近访问时间存到 ConcurrentHashMap 中。每次请求时,可以设置 Request 的 domainDelay 属性,从而实现单个 Request 对某个 Domain 的限速。
import cn.netdiscovery.core.domain.Request;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* Created by tony on 2019-05-06.
*/
public class Throttle {
private Map<String,Long> domains = new ConcurrentHashMap<String,Long>();
private static class Holder {
private static final Throttle instance = new Throttle();
}
private Throttle() {
}
public static final Throttle getInsatance() {
return Throttle.Holder.instance;
}
public void wait(Request request) {
String domain = request.getUrlParser().getHost();
Long lastAccessed = domains.get(domain);
if (lastAccessed!=null && lastAccessed>0) {
long sleepSecs = request.getDomainDelay() - (System.currentTimeMillis() - lastAccessed);
if (sleepSecs > 0) {
try {
Thread.sleep(sleepSecs);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
domains.put(domain,System.currentTimeMillis());
}
}
待 Request 从消息队列中取出时,会先判断 Request 是否需要暂停之后,然后再判断一下 Domain 的访问是否需要暂停。
while (getSpiderStatus() != SPIDER_STATUS_STOPPED) {
//暂停抓取
......
// 从消息队列中取出request
final Request request = queue.poll(name);
if (request == null) {
waitNewRequest();
} else {
if (request.getSleepTime() > 0) {
try {
Thread.sleep(request.getSleepTime());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
Throttle.getInsatance().wait(request);
......
}
}
2.2.4 Pipeline
爬虫处理 Request 的流程大体是这样的:调用网络请求 (包括重试机制) -> 将 response 存放到 page -> 解析 page -> 顺序执行 pipelines -> 完成一次 Request 请求。
// request正在处理
downloader.download(request)
.retryWhen(new RetryWithDelay(maxRetries, retryDelayMillis, request)) // 对网络请求的重试机制
.map(new Function<Response, Page>() {
@Override
public Page apply(Response response) throws Exception {
// 将 response 存放到 page
......
return page;
}
})
.map(new Function<Page, Page>() {
@Override
public Page apply(Page page) throws Exception {
if (parser != null) {
parser.process(page);
}
return page;
}
})
.map(new Function<Page, Page>() {
@Override
public Page apply(Page page) throws Exception {
if (!page.getResultItems().isSkip() && Preconditions.isNotBlank(pipelines)) {
pipelines.stream()
.forEach(pipeline -> {
pipeline.process(page.getResultItems());
});
}
return page;
}
})
.observeOn(Schedulers.io())
.subscribe(new Consumer<Page>() {
@Override
public void accept(Page page) throws Exception {
log.info(page.getUrl());
if (request.getAfterRequest() != null) {
request.getAfterRequest().process(page);
}
signalNewRequest();
}
}, new Consumer<Throwable>() {
@Override
public void accept(Throwable throwable) throws Exception {
log.error(throwable.getMessage(), throwable);
}
});
Pipeline 的限速实质借助了 RxJava 的 delay 和 block 操作符实现。
map(new Function<Page, Page>() {
@Override
public Page apply(Page page) throws Exception {
if (!page.getResultItems().isSkip() && Preconditions.isNotBlank(pipelines)) {
pipelines.stream()
.forEach(pipeline -> {
if (pipeline.getPipelineDelay()>0) {
// Pipeline Delay
Observable.just("pipeline delay").delay(pipeline.getPipelineDelay(),TimeUnit.MILLISECONDS).blockingFirst();
}
pipeline.process(page.getResultItems());
});
}
return page;
}
})
另外,NetDiscovery 支持通过配置 application.yaml 或 application.properties 文件,来配置爬虫。当然也支持配置限速的参数,同时支持使用随机的数值来配置相应的限速参数。
2.3 非阻塞的爬虫运行
早期的版本,爬虫运行之后无法再添加新的 Request。因为爬虫消费完队列中的 Request 之后,默认退出程序了。
新版本借助于 Condition,即使某个爬虫正在运行仍然可以添加 Request 到它到消息队列中。
Condition 的作用是对锁进行更精确的控制。它用来替代传统的 Object 的wait()、notify() 实现线程间的协作,相比使用 Object 的 wait()、notify(),使用Condition 的 await()、signal() 这种方式实现线程间协作更加安全和高效。
在 Spider 中需要定义好 ReentrantLock 以及 Condition。
然后再定义 waitNewRequest() 、signalNewRequest() 方法,它们的作用分别是挂起当前的爬虫线程等待新的 Request 、唤醒爬虫线程消费消息队列中的 Request。
private ReentrantLock newRequestLock = new ReentrantLock();
private Condition newRequestCondition = newRequestLock.newCondition();
......
private void waitNewRequest() {
newRequestLock.lock();
try {
newRequestCondition.await(sleepTime, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
log.error("waitNewRequest - interrupted, error {}", e);
} finally {
newRequestLock.unlock();
}
}
public void signalNewRequest() {
newRequestLock.lock();
try {
newRequestCondition.signalAll();
} finally {
newRequestLock.unlock();
}
}
可以看到,如果从消息队列中取不出 Request,则会运行 waitNewRequest()。
while (getSpiderStatus() != SPIDER_STATUS_STOPPED) {
//暂停抓取
if (pause && pauseCountDown!=null) {
try {
this.pauseCountDown.await();
} catch (InterruptedException e) {
log.error("can't pause : ", e);
}
initialDelay();
}
// 从消息队列中取出request
final Request request = queue.poll(name);
if (request == null) {
waitNewRequest();
} else {
......
}
}
然后,在 Queue 接口中包含了一个 default 方法 pushToRunninSpider() ,它内部除了将 request push 到 queue 中,还有调用了 spider.signalNewRequest()。
/**
* 把Request请求添加到正在运行爬虫的Queue中,无需阻塞爬虫的运行
*
* @param request request
*/
default void pushToRunninSpider(Request request, Spider spider) {
push(request);
spider.signalNewRequest();
}
最后,即使爬虫已经运行,也可以在任意时刻将 Request 添加到该爬虫对应到Queue 中。
Spider spider = Spider.create(new DisruptorQueue())
.name("tony")
.url("http://www.163.com");
CompletableFuture.runAsync(()->{
spider.run();
});
try {
Thread.sleep(2000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
spider.getQueue().pushToRunninSpider(new Request("https://www.baidu.com", "tony"),spider);
try {
Thread.sleep(2000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
spider.getQueue().pushToRunninSpider(new Request("https://www.jianshu.com", "tony"),spider);
System.out.println("end....");
总结
爬虫框架 github 地址:github.com/fengzhizi71…
本文总结了通用爬虫框架在某些特定场景中如何使用多线程。未来,NetDiscovery 还会增加更为通用的功能。
Java与Android技术栈:每周更新推送原创技术文章,欢迎扫描下方的公众号二维码并关注,期待与您的共同成长和进步。

