1.hashCode介绍
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个散列码的作用是确定该对象在散列表中的索引位置,如果有看我的上一篇文章 什么是散列表,那么这里的散列码就相当于上文中根据首字母查询散列表例子中 人名关键字k在散列表中的具体地址。hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode() 函数。
2.hashCode 的作用
数组是java中效率最高的数据结构,但是“最高”是有前提的。第一我们需要知道所查询数据的所在位置。第二:如果我们进行迭代查找时,数据量一定要小,对于大数据量而言一般推荐集合。
在 Java 集合中有两类,一类是 List,一类是 Set 他们之间的区别就在于 List 集合中的元素师有序的,且可以重复,而 Set 集合中元素是无序不可重复的。对于 List 好处理,但是对于 Set 而言我们要如何来保证元素不重复呢?通过迭代来 equals() 是否相等。数据量小还可以接受,当我们的数据量大的时候效率可想而知(当然我们可以利用算法进行优化)。比如我们向 HashSet 插入 1000 数据,难道我们真的要迭代 1000 次,调用 1000 次 equals() 方法吗?hashCode 提供了解决方案。怎么实现?我们先看 hashCode 的源码(Object)。
public native int hashCode();
它是一个本地方法,它的实现与本地机器有关。当我们向一个集合中添加某个元素,集合会首先调用 hashCode 方法,这样就可以直接定位它所存储的位置,若该处没有其他元素,则直接保存。若该处已经有元素存在,就调用 equals 方法来匹配这两个元素是否相同,相同则不存,不同则散列到其他位置。这样处理,当我们存入大量元素时就可以大大减少调用 equals() 方法的次数,极大地提高了效率。
所以 hashCode 在上面扮演的角色为寻域(寻找某个对象在集合中区域位置)。hashCode 可以将集合分成若干个区域,每个对象都可以计算出他们的 散列码,可以将 散列码分组,每个分组对应着某个存储区域(散列表),根据一个对象的 散列码就可以确定该对象所存储区域,这样就大大减少查询匹配元素的数量,提高了查询效率。
3.hashCode 对于一个对象的重要性
hashCode 重要么?不重要,对于 List 集合、数组而言,但是对于 HashMap、HashSet、HashTable 而言,它变得异常重要。所以在使用 HashMap、HashSet、HashTable 时一定要注意 hashCode。对于一个对象而言,其 hashCode 过程就是一个简单的 Hash 算法的实现,其实现过程对你实现对象的存取过程起到非常重要的作用。
以 HashTable 为例阐述 hashCode 对于一个对象的重要性。
一个对象势必会存在若干个属性,如何选择属性来进行散列考验着一个人的设计能力。如果我们将所有属性进行散列,这必定会是一个糟糕的设计,因为对象的 hashCode 方法无时无刻不是在被调用,如果太多的属性参与散列,那么需要的操作数时间将会大大增加,这将严重影响程序的性能。但是如果较少属相参与散列,散列的多样性会削弱,会产生大量的散列“冲突”,除了不能够很好的利用空间外,在某种程度也会影响对象的查询效率。其实这两者是一个矛盾体,散列的多样性会带来性能的降低。
那么如何对对象的 hashCode 进行设计,本人 也没有经验。从网上查到了这样一种解决方案:设置一个缓存标识来缓存当前的散列码,只有当参与散列的对象改变时才会重新计算,否则调用缓存的 hashCode,这样就可以从很大程度上提高性能。
在 HashTable 计算某个对象在 table[] 数组中的索引位置,其代码如下:
int index = (hash & 0x7FFFFFFF) % tab.length;
为什么要 &0x7FFFFFFF?因为某些对象的 hashCode 可能会为负值,与 0x7FFFFFFF 进行与运算可以确保 index 为一个正数。通过这步我可以直接定位某个对象的位置,所以从理论上来说我们是完全可以利用 hashCode 直接定位对象的散列表中的位置,但是为什么会存在一个 key-value 的键值对,利用 key 的 hashCode 来存入数据而不是直接存放 value 呢?这就关系 HashTable 性能问题的最重要的问题: Hash 冲突!(详见上篇)
我们知道冲突的产生是由于不同的对象产生了相同的散列码, hashcode 返回的是 int,它的值只可能在 int 范围内。如果我们存放的数据超过了 int 的范围呢?这样就必定会产生两个相同的 散列码,这时在 散列码 位置处会存储两个对象,我们就可以利用 key 本身来进行判断。所以具有相索引的对象,在该 散列码 位置处存在多个对象,我们必须依靠 key 的 hashCode 和key 本身来进行区分。而Key的比较就用到了equals
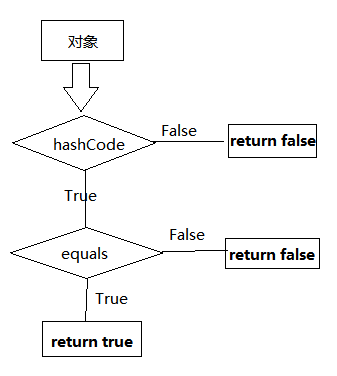
4.hashCode 与 equals
简而言之就是:
- 如果两个对象相等,则hashcode一定也是相同的
- 两个对象相等,对两个对象分别调用equals方法都返回true
- 两个对象有相同的hashcode值,它们也不一定是相等的
- 因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖
- hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
对象的比较过程如下: