

对于回归问题,通常有 MSE、MAE、RMSE、R^2 四种方法来评判模型的效果。对于分类问题,最简单的办法是采用准确率来评估模型的效果。比如 sklearn 中对于分类问题默认的 score 都是根据准确率来统计的。
使用准确率来评估理解非常简单,但是对于极度偏斜的数据的预测会有很大问题。比如对于癌症预测问题,健康 vs 患病的比例可能是 10000:1。对于这种极度偏斜的数据,我们可以做一个最简单的模型,直接预测所有样本都属于健康类,这样模型准确率都可以达到 99.99%。
对于这类型数据,分类算法模型的 score 可以借助混淆矩阵来评估。
混淆矩阵
下面为了方便解释混淆矩阵以及准确率和召回率等名词术语,先以二分类问题为例来分析。
| 真实/预测 | 0 | 1 |
|---|---|---|
| 0 | TN | FP |
| 1 | FN | TP |
- 上述表格中,行代表实际值,列代表预测值。
- 0 代表 negative,1 代表 postive。
- TN (True Negative) 表示实际值为 negative,预测值为 negative,预测 negative 正确。
- FP (False Positive) 表示实际值为 negative,预测值为 positive,预测 positive 错误。
- FN (False Negative) 表示实际值为 positive,预测值为 negative,预测 negative 错误。
- TP (True Positive) 表示实际值为 positive,预测值为 positive,预测 positive 错误。
上面说的有些抽象,下面举一个具体的例子。
| 真实/预测 | 0 | 1 |
|---|---|---|
| 0 | 9980 | 10 |
| 1 | 3 | 7 |
- 9980 个人本身没有患癌症,同时算法也预测他们没有患癌症。
- 10 个人没有患癌症,但是算法预测他们患有癌症。
- 3 个人患有癌症,但是算法预测他们没有患癌症。
- 7 个人患有癌症,算法预测他们患有癌症。
精准率
对于精准率的定义是:预测关注事件的结果中(总共 17 次)预测正确的概率,7 次正确,10 次错误。
精准率 = TP / (TP + FP) = 7 / (10+7),也就是说没做 17 次患病预测的时候,平均有 7 次正确的。
召回率
召回率的定义是:对所关注的类型(也就是 10 个患者),将其预测出的概率(预测出 7 个)。
召回率 = TP / (TP + FN) = 7 / (7 + 3) = 70%,也就是说每当有 100 个患者,算法平均能够成功找出 70 个,会漏掉 30 个。
F1-Score
对于有些场景,选择精准率更合适,比如股票预测场景,要预测股票是涨还是降,业务需求是更精准的找到能够上升的股票。而对于疾病预测场景,要预测就诊人员是否患病,这个时候的业务需求是找出所有患病的病人不要漏掉任何一个患者,可以说将健康者诊断为患者可能没太多关系,只要不将患者诊断为健康者。
但是在有些场景,需要同时综合精准率和召回率,这个时候怎么办呢?可以使用 f1-score 来解决,f1 是精准率和召回率的调和平均值:
实例
为了演示上面提到的三个概念,首先我们先构建一个极度偏斜的数据,我们选择 sklearn 提供手写识别数据集,本身在这个数据集中,0-9 十个数字都分布比较均匀,我们将这个十分类数据转换成二分类数据,一类等于 9,另外一类不等于 9 来制造数据偏斜。
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
y[digits.target==9] = 1
y[digits.target!=9] = 0
使用逻辑回归来进行预测:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
log_reg.score(X_test, y_test)
由于数据是极度偏斜的,即使预测所有样本的类型都是 0,准确度都能达到 90% 左右。准确度只能说明模型对每一个样本预测的准确度,并不能真正准确找出类型为 1 的样本,也就是说准确度并不能反映模型是否精准找出了类型为 1 的样本。sklearn metrics 包中直接提供了对于混淆矩阵、精准率、召回率的支持。
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_log_predict)
from sklearn.metrics import precision_score
precision_score(y_test, y_log_predict)
from sklearn.metrics import recall_score
recall_score(y_test, y_log_predict)
from sklearn.metrics import f1_score
f1_score(y_test, y_log_predict)
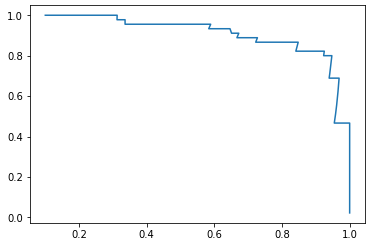
PR 曲线
对于二分类问题,我们可以调节分类边界值来调节精准率和召回率的比重。score > threshold 时分类为 1,score < threshold 时分类为 0。阈值增大,精准率提高,召回率降低;阈值减小,精准率降低,召回率提高。精准率和召回率是相互牵制,互相矛盾的两个变量,不能同时增高。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
y[digits.target==9] = 1
y[digits.target!=9] = 0
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
decision_scores = log_reg.decision_function(X_test)
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
precisions = []
recalls = []
thresholds = np.arange(np.min(decision_scores), np.max(decision_scores), 0.1)
for threshold in thresholds:
y_predict = np.array(decision_scores >= threshold, dtype='int')
precisions.append(precision_score(y_test, y_predict))
recalls.append(recall_score(y_test, y_predict))
plt.plot(precisions, recalls)
plt.show()
ROC 曲线
ROC(Receiver Operation Characteristic Curve)用来描述 TPR 和 FPR 之间的关系,其中:
- TPR(True Positive Rate) 表示真正率,被预测为正的正样本结果数 / 正样本实际数:TPR = TP /(TP + FN)
- TNR(True Negative Rate) 表示真负率;被预测为负的负样本结果数 / 负样本实际数:TNR = TN /(TN + FP)
- FPR(False Positive Rate) 表示假正率;被预测为正的负样本结果数 /负样本实际数:FPR = FP /(TN + FP)
- FNR(False Negative Rate) 表示假负率;被预测为负的正样本结果数 / 正样本实际数:FNR = FN /(TP + FN)
实例
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
y[digits.target==9] = 1
y[digits.target!=9] = 0
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
decision_scores = log_reg.decision_function(X_test)
from sklearn.metrics import roc_curve
fprs, tprs, thresholds = roc_curve(y_test, decision_scores)
import matplotlib.pyplot as plt
plt.plot(fprs, tprs)
plt.show()
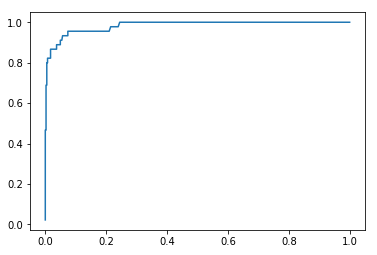
ROC 曲线与图形边界围成的面积,作为衡量模型优劣的标准,面积越大,模型越优。
