

哈希表的基本原理
首先回顾一下前面实现的数组和链表,无论是动态数组、链表、还是循环链表,而且如果是从其中查询特定值,都不可避免的要遍历依次遍历所有元素依次去做比较才可以。
做为面向对象开发语言的使用者,一定用过类似于Map的对象,通过 key: value 存储一个键值对。Objective-C中这种对象就是字典:NSDictionary、NSMutableDictionary,Swift中对于Dictionary。而且通过很多介绍的文章都说过,通过key取值的时间复杂度是O(1)。之前我们都只是使用它们,现在我们自己思考,如何利用我们之前已经了解的数据结构,自己实现一个自定义字典。
上面提到,通过数组和链表查询值的时候,时间复杂度都是O(n)级别,那么如何实现仅需要O(1)级别就能够查询到值呢?首先回顾之前的几个数据结构:数组、单向链表、双向链表,哪种数据结构能够做到在任意位置取值都是O(1)?
答案就是数组,数据可以做到通过下标从数组中的任意位置取值都是O(1)的时间复杂度。既然是这样,我们就先决定用静态数组来做为存放数据的底层结构。既然是这样,我们的键值对都是存放在数组中的。但是数组只有通过下标取值才是O(1)的时间复杂度,直接查找值依然需要依次对比元素是否相等。
那么接下来的问题就是,如何将key的遍历查找转换成直接通过index去数组中取值。要做到这一点,我们假设一个函数,这个函数能够做到:将不同的key转换成对应数组长度范围内的一个index,且不同的key转换成的index都不一样。而且这个函数是O(1)级别的数据复杂度,那么当需要将一个键值对存入数组时,只需要通过这个函数计算一下对应在数组中下标,然后将键值对存放在数组中对应位置。当需要通过key从数组中取时,只需要在通过这个函数计算key对应在数组中下标,然后通过下标去数组中直接取出键值对就可以了。存、取、查都是O(1)级别的时间复杂度。
现在就不需要解释什么是哈希表了,上面就是哈希表的原理,静态数组加上一个通过key计算index的函数,就是一个哈希表。下面通过图片看一下我们上面分析的哈希表的存放数据过程:
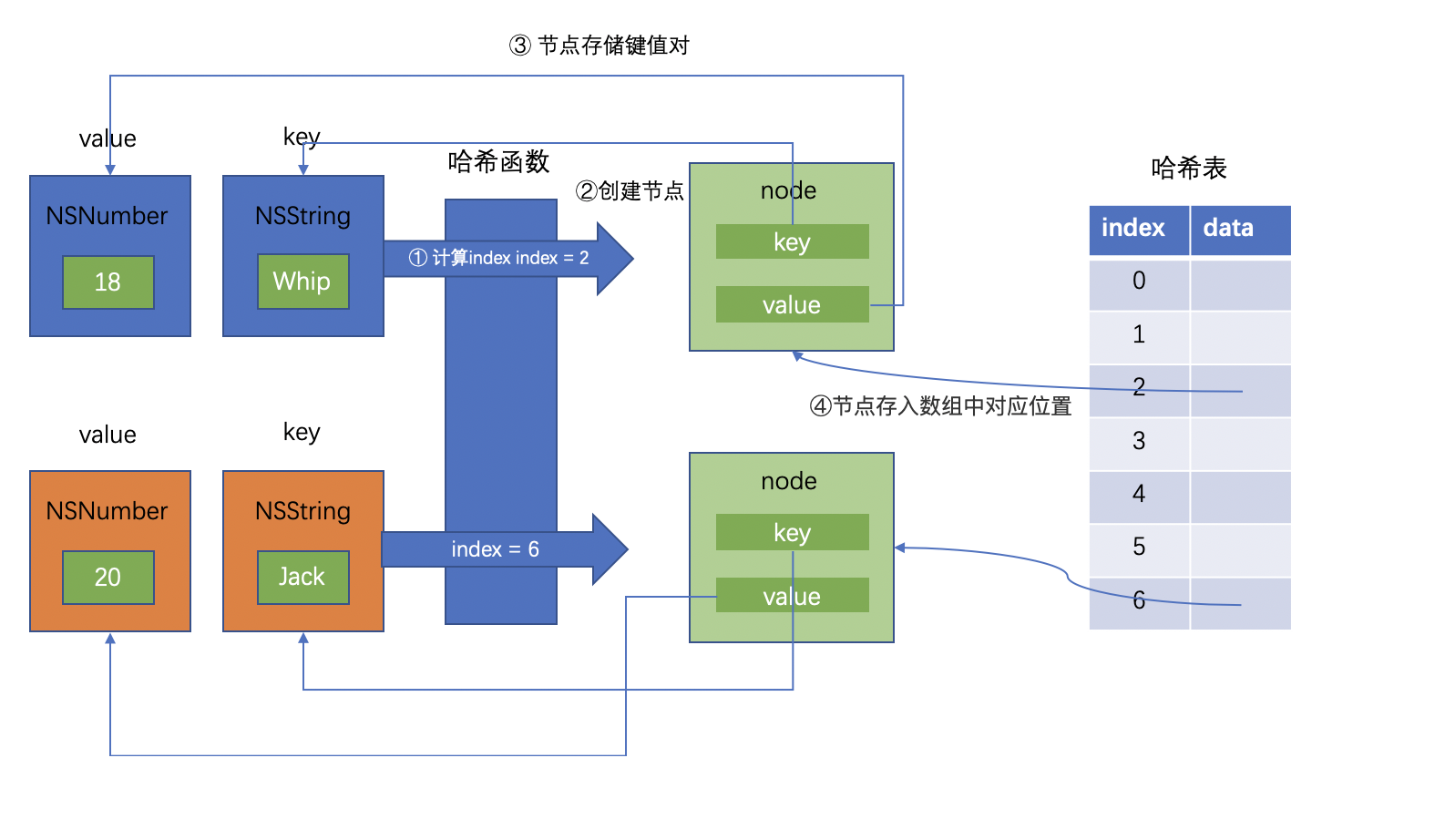
我们有两对键值对需要存放在我们的自定义字典中,key是名字,value是年龄,分别是 Whip:18、Jack:20。
当存储Whip:18时,首先通过哈希函数计算whip对应在哈希表中的index为2,然后创建一个哈希表的节点对象,key指向Whip,value指向18,然后将节点存储在哈希表中index为2的位置。
当存储Jack:20时,首先通过哈希函数计算Jack对应在哈希表中的index为6,然后创建一个哈希表的节点对象,key指向Jack,value指向20,然后将节点存储在哈希表中index为6的位置。
下面看一下哈希表的取值过程:
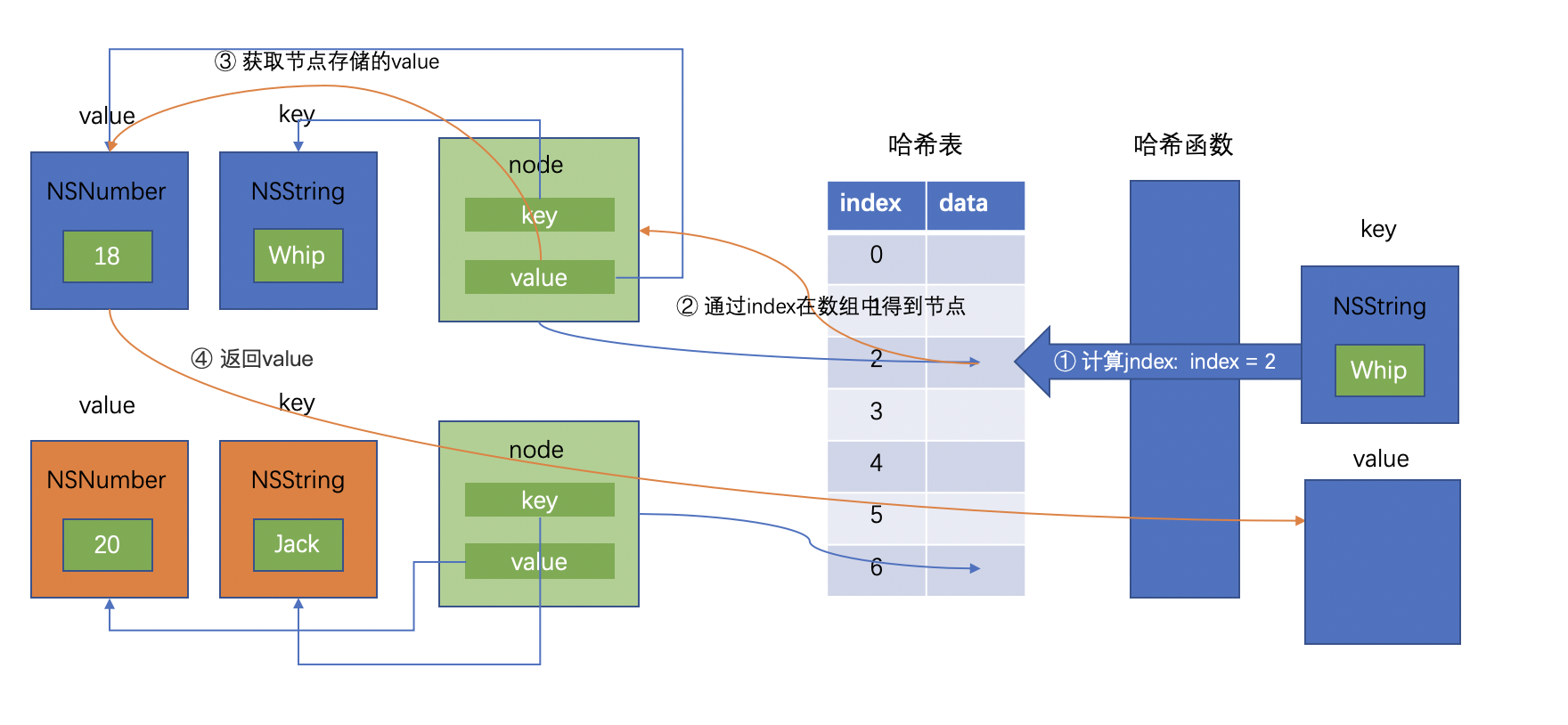
当需要需要得到Whip的年龄时,哈希表先通过哈希函数计算出Whip在哈希表中存放的位置index = 2,然后直接在数组中index为2的位置拿到存储的节点,返回节点的value值18。
哈希函数
既然需要通过哈希函数计算不同key对应在数组中的index,那么我们首先就需要实现一个哈希函数。首先哈希函数需要满足以下条件才是合格的:
- 不同的key生成的索引尽可能不同。
- 生成的索引要在哈希表长度范围内。
在Objective-C中,NSObject对象自带一个hash方法,可以返回一个对象的哈希值:
Person *p1 = [Person personWithAge:1];
Person *p2 = [Person personWithAge:1];
NSLog(@"%zd %zd", p1.hash, p2.hash);
// 打印
4345476000 4345477856
可以看的即使是相同类型的并且属性值相同的对象,返回的哈希值也是不同的。当然也可重写自定义对象的hash方法,返回我们自己希望返回的哈希值,做到让属性值相同的对象,返回相同的hash值:
- (NSUInteger)hash {
NSUInteger hashCode = self.age;
// 奇素数 hashCode * 31 == (hashCode<<5) - hashCode
hashCode = (hashCode<<5) - hashCode;
return hashCode;
}
上面的计算是仿照JDK的方式,将整数乘以31得出哈希值,因为31是一个奇素数,和它相乘可以更容易达到唯一性,减少冲突。
既然重写了hash方法,还需要配套重写对象的 isEqual方法,一个正确的判断逻辑需要满足:
- 两个对象isEqual:判断为true,那么两个对象hash返回值一定相等。
- 哈希值相等的两个对象,isEqual: 不一定相等。
想象一下,如果两个对象isEqual:返回true,意味着两个对象相等,但是它们的哈希值不想等,意味着它们可能存放在哈希表中的不同位置,这样就相当于Map或者NSDictionary中存放了两个key相同的键值对,这明显是不符合逻辑的。
key的哈希值我们已经知道如何使用默认和自定义的方法返回,下面我们通过key的哈希值计算其在数组中的index。首先key的哈希值也是一个整数,并且长度不一定。比如上面,默认返回:4345477856,我们自定义hash方法后返回31。假设我们的数组长度只有8,那么肯定不能将key的哈希值直接当作数组中的index。
这里我们可以通过 & 位运算来得到,前提是数组的长度是2的n次方,假设数组的长度为 2^3 = 8,8 - 1 = 7,其对应的二进制位为:0111。
下面我们和0111做 & 位运算的效果:
// 十进制253
1111 1101
& 0111
---------
0101 = 5
// 十进制31
0001 1111
& 0111
---------
0111 = 7
// 十进制8
0000 1000
& 0111
---------
0000 = 0
可以看到,任何数字和7做&位运算的结果都不会大于8,即key的哈希值通过和数组长度-1的值(数组长度为2的幂)做&位运算就可以得到key哈希值对应在数组中的index:
- (NSUInteger)indexWithKey:(id)key {
if (!key) return 0;
NSUInteger hash = [key hash];
return hash & (self.array.length - 1);
}
现在这个函数还不是很好用,比如下面的情况,假定哈希表长度为2^6,2^6 - 1 = 63,二进制位为:0011 1111
// 6390901416293117903
0101 1000 1011 0001
0000 1010 1111 1010
0100 1000 1011 0001
0010 1111 1100 1111
& 011 1111
----------------------
000 1111 = 15
// 6390901416293511119
0110 1000 1011 0010
0000 1010 1111 1010
0100 1000 1011 0111
0010 1111 1100 1111
& 011 1111
----------------------
000 1111 = 15
6390901416293117903 和 6390901416293511119 由于最后7位2进制位都是 1001111,所以和 011 1111 做位运算之后结果都是 000 1111 = 15,高位都没有参与运算,导致只要末 7 位一样的哈希值的key在数组中index都相同,而我们应该尽量让所有的哈希值位数都参与运算。
下面将哈希值右移16位,然后和原来的哈希值做 ^ 运算,然后在与数组长度 -1 做 & 运算,之后的结果:
(6390901416293117903 ^ (6390901416293117903 >> 16)) & 63); // 62
(6390901416293511119 ^ (6390901416293511119 >> 16)) & 63); // 56
下面是优化后最终哈希表的哈希函数:
- (NSUInteger)indexWithKey:(id)key {
if (!key) return 0;
NSUInteger hash = [key hash];
return (hash ^ (hash >> 16)) & (self.array.length - 1);
}
虽然上面的优化可以一定程度避免不同的哈希值计算出相同的index,但是依然不能完全避免,比如:6390901416293117903 和 6681946542211936207,因为它们的二进制的最后八位一样,而右移后的最后八位仍然一样,最终和63做位运算的最后几位也是一样的值,这样就不可避免的出现的不同key通过哈希函数计算后,在数组中的index是相同的情况。
哈希冲突
对键值对需要存放如哈希表,通过key计算出index后,发现哈希表中该位置已经存放了其它键值对。数组中index位置键值对的key和当前正在添加的键值对的key,通过哈希函数计算出得index是一样的,就会出现这种问题。出现这种问题分为两种情况:
- 当前的key和数组中index位置的key是相等的,这种只需要将新键值覆盖就可以了。
- 当前的key和数组的index位置的key是不相等的,即两个不同的key,通过哈希函数计算得出的index相同。
出现第二种情况就是所谓的哈希冲突,这种冲突是不可避免的,解决哈希冲突的办法有很多种:
- 再次通过其它规则计算index,直到找到一个空的位置。
- 找到index前面或者后面第一个不为空的位置。
- 仍在index位置放置元素,并将两个元素以链表等形式存储。
我们这里采用第三种方式,即发现冲突的时候,以链表的形式将一个index内的所有元素串起来,如下图:
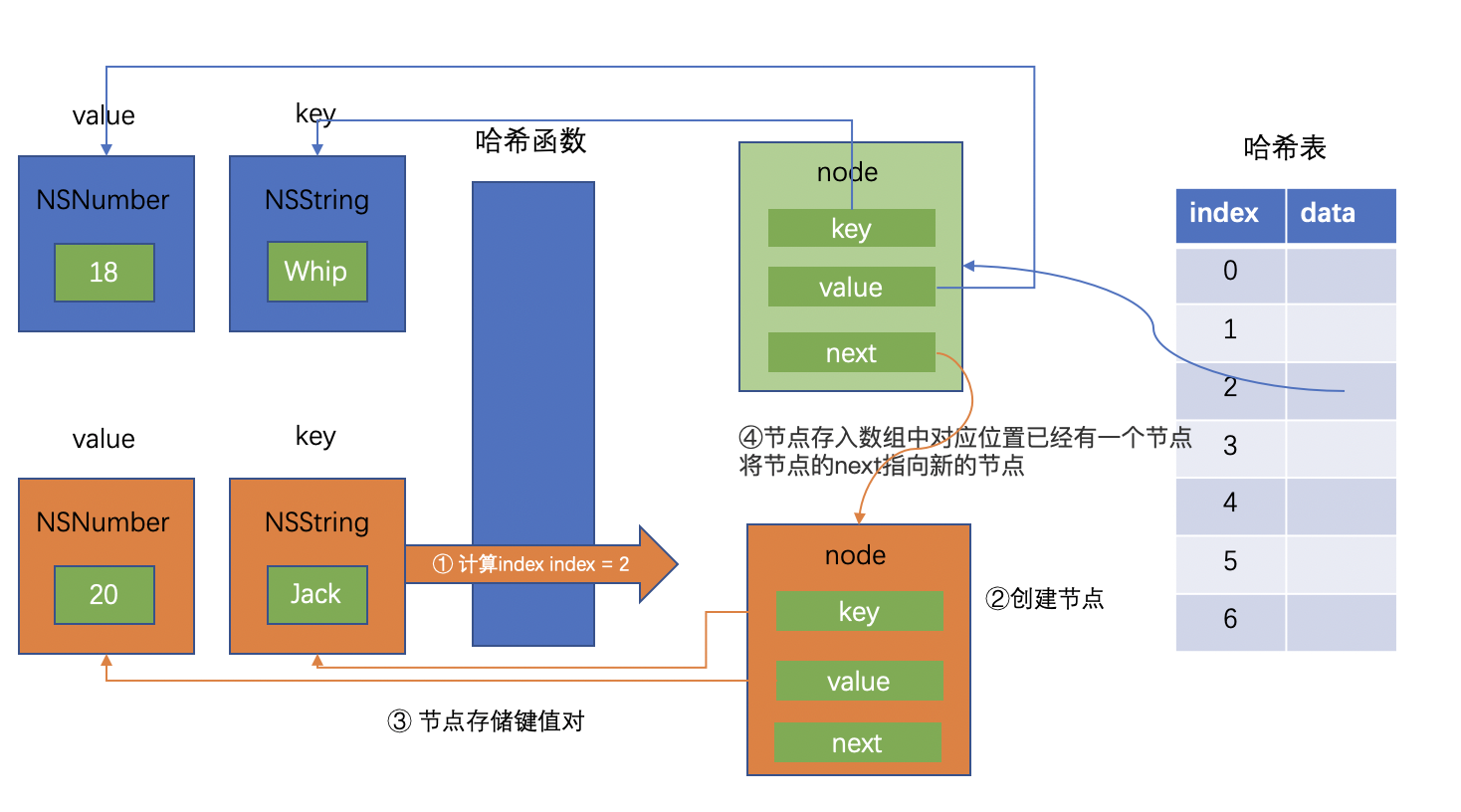
存储Jack:20 的时候,通过哈希函数计算出得index = 2,发现哈希表中index为2的位置已经有了其它节点,这时就将最后一个节点的next指向新的节点。
这种情况下的取值如下图:
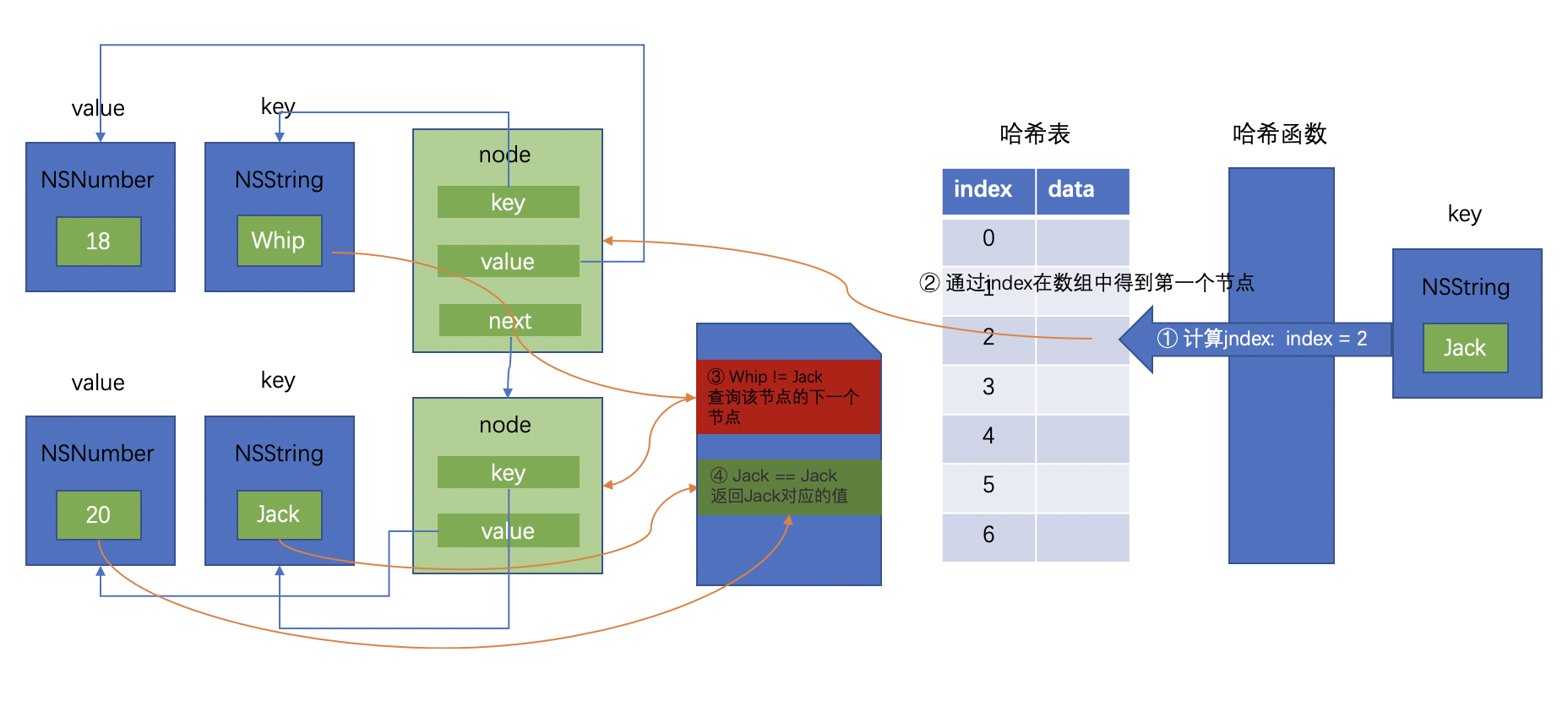
首先通过哈希函数计算key对应的index,然后找到数组中对应位置的第一个节点,比较该节点存储的key和查询的key是否相等,如果不相等则通过该节点next指针找到下一个节点,重复判断过程,直到找到key相等的节点。
哈希表的基本结构
通过上面的分析,哈希表的结构其实已经很清晰了,首先哈希表是一个静态数组,数据中存放哈希表的节点,哈希表的节点是一个单向链表的结构,每一个节点通过next指针指向下一个节点,节点另外需要两个指针指向key和value。我们还需要实现一个哈希函数,可以通过key计算出其对应在哈希表中的位置,这个函数我们前面已经实现了。
我这里将哈希表封装成一个类似字典的类,外部接口完全和系统的NSMutableDictionary一致,实现的功能也是一样的。首先创建一个JKRHashMap_LinkedList类。
_size来保存当前哈希表存放的键值对的数量,注意区分这里的_size是存放键值对的数量,而不是哈希表的长度。
#import <Foundation/Foundation.h>
NS_ASSUME_NONNULL_BEGIN
@interface JKRHashMap_LinkedList<KeyType, ObjectType> : NSObject{
@protected
/// 节点个数
NSUInteger _size;
}
/// 元素个数
- (NSUInteger)count;
/// 清空所有元素
- (void)removeAllObjects;
/// 删除元素
- (void)removeObjectForKey:(KeyType)key;
/// 添加一个元素
- (void)setObject:(nullable ObjectType)object forKey:(nullable KeyType)key;
/// 获取元素
- (nullable ObjectType)objectForKey:(nullable KeyType)key;
/// 是否包含元素
- (BOOL)containsObject:(nullable ObjectType)object;
/// 是否包含key
- (BOOL)containsKey:(nullable KeyType)key;
@end
@interface JKRHashMap_LinkedList<KeyType, ObjectType> (JKRExtendedHashMap)
- (nullable ObjectType)objectForKeyedSubscript:(nullable KeyType)key;
- (void)setObject:(nullable ObjectType)obj forKeyedSubscript:(nullable KeyType)key;
@end
NS_ASSUME_NONNULL_END
然后创建哈希表的节点对象:
@interface JKRHashMap_LinkedList_Node : NSObject
@property (nonatomic, strong) id key;
@property (nonatomic, strong) id value;
@property (nonatomic, strong) JKRHashMap_LinkedList_Node *next;
@end
哈希表的基本功能
初始化
首先哈希表中应该有一个静态数组,由于Objective-C不提供,所以在第一篇文章中已经提前实现了一个静态数组,它需要在哈希表初始化的时候创建,并且长度为2的幂:
@interface JKRHashMap_LinkedList ()
@property (nonatomic, strong) JKRArray *array;
@end
@implementation JKRHashMap_LinkedList
- (instancetype)init {
self = [super init];
self.array = [JKRArray arrayWithLength:1 << 4];
return self;
}
@end
哈希函数
前面已经实现了,这里直接就可以使用:
- (NSUInteger)indexWithKey:(id)key {
if (!key) return 0;
NSUInteger hash = [key hash];
return (hash ^ (hash >> 16)) & (self.array.length - 1);
}
通过key查找节点
正如上面分析的查找过程,
- 1,首先通过哈希函数找到key对应的index。
- 2,通过index获取哈希表中对应位置的节点。
- 3,如果节点为空,则key不在哈希表中,返回null。
- 4,如果节点存在,则比较节点的key的查询key是否相等,相等直接返回该节点,否则进入下一步。
- 5,得到该节点的下一个节点,重复第三步。
- (JKRHashMap_LinkedList_Node *)nodeWithKey:(id)key {
NSUInteger index = [self indexWithKey:key];
JKRHashMap_LinkedList_Node *node= self.array[index];
while (node) {
if (node.key == key || [node.key isEqual:key]) {
return node;
} else if (key && node.key && [key class] == [node.key class] && [key respondsToSelector:@selector(compare:)] && [key compare:node.key] == 0){
return node;
}
node = node.next;
}
return node;
}
通过key获取object
上面已经实现了通过key获取节点,这里只需要将返回的节点的value返回:
- (id)objectForKey:(id)key {
JKRHashMap_LinkedList_Node *node = [self nodeWithKey:key];
return node ? node.value : nil;
}
是否存包含key
上面已经实现了通过key获取节点,这里只需要判断返回的节点是否为空:
- (BOOL)containsKey:(id)key {
return [self nodeWithKey:key] != nil;
}
返回哈希表的键值对数量
只需要返回_size:
- (NSUInteger)count {
return _size;
}
添加键值对
添加键值对的步骤:
- 1,通过key计算出index。
- 2,通过index取出哈希表对应位置的节点。
- 3,如果节点为空,直接创建一个新节点并存储传入的key和value,并将节点指针存入哈希表, _size++。否则进入下一步。
- 4,判断节点的key和传入的key是否相等,如果相等,则需要进行覆盖操作,将传入的key和value覆盖节点的key和value。否则进入下一步。
- 5,保存一下该节点为preNode,然后获取该节点的下一个节点,判断节点是否为空,如果为空,创建一个新节点,将key和value存入新节点的key和value,并将preNode的next指向新节点,_size++。否则返回步骤4。
- (void)setObject:(id)object forKey:(id)key {
NSUInteger index = [self indexWithKey:key];
JKRHashMap_LinkedList_Node *node = self.array[index];
if (!node) {
node = [JKRHashMap_LinkedList_Node new];
node.key = key;
node.value = object;
self.array[index] = node;
_size++;
return;
}
JKRHashMap_LinkedList_Node *preNode = nil;
while (node) {
if (node.key == key || [node.key isEqual:key]) {
break;
} else if (key && node.key && [key class] == [node.key class] && [key respondsToSelector:@selector(compare:)] && [key compare:node.key] == 0) {
break;
}
preNode = node;
node = node.next;
}
if (node) {
node.key = key;
node.value = object;
return;
}
JKRHashMap_LinkedList_Node *newNode = [JKRHashMap_LinkedList_Node new];
newNode.key = key;
newNode.value = object;
preNode.next = newNode;
_size++;
}
删除键值对
- 1,通过key计算出index。
- 2,通过index取出当前哈希表对应的节点。
- 3,判断该节点是否为空,如果节点为空,直接返回。否则进入下一步。
- 4,判断该节点的key是否和传入的key相等,如果相等,删除该节点,_size--。 否则进入下一步。
- 5,拿到该节点的下一个节点,重复第4步。
- (void)removeObjectForKey:(id)key {
NSUInteger index = [self indexWithKey:key];
JKRHashMap_LinkedList_Node *node= self.array[index];
JKRHashMap_LinkedList_Node *preNode = nil;
while (node) {
if (node.key == key || [node.key isEqual:key]) {
if (preNode) {
preNode.next = node.next;
} else {
self.array[index] = node.next;
}
_size--;
return;
} else if (key && node.key && [key class] == [node.key class] && [key respondsToSelector:@selector(compare:)] && [key compare:node.key] == 0){
if (preNode) {
preNode.next = node.next;
} else {
self.array[index] = node.next;
}
_size--;
return;
}
preNode = node;
node = node.next;
}
}
是否包含某元素
因为哈希表的value存放在节点中,并且无法直接找到其位置,只能通过遍历哈希表所有节点实现:
- (BOOL)containsObject:(id)object {
if (_size == 0) {
return NO;
}
for (NSUInteger i = 0; i < self.array.length; i++) {
JKRHashMap_LinkedList_Node *node= self.array[i];
while (node) {
if (node.value == object || [node.value isEqual:object]) {
return YES;
}
node = node.next;
}
}
return NO;
}
让自定义的哈希表支持字典运算符
- (id)objectForKeyedSubscript:(id)key {
return [self objectForKey:key];
}
- (void)setObject:(id)obj forKeyedSubscript:(id)key {
[self setObject:obj forKey:key];
}
重写打印方便查看哈希表结构
- (NSString *)description {
NSMutableString *string = [NSMutableString string];
[string appendString:[NSString stringWithFormat:@"<%@, %p>: \ncount:%zd length:%zd\n{\n", self.className, self, _size, self.array.length]];
for (NSUInteger i = 0; i < self.array.length; i++) {
[string appendString:[NSString stringWithFormat:@"\n\n--- index: %zd ---\n\n", i]];
JKRHashMap_LinkedList_Node *node= self.array[i];
if (node) {
while (node) {
[string appendString:[NSString stringWithFormat:@"[%@:%@ -> %@%@] ", node.key , node.value, node.next ? [NSString stringWithFormat:@"%@:", node.next.key] : @"NULL", node.next ? node.next.value : @""]];
node = node.next;
if (i) {
[string appendString:@", "];
}
}
} else {
[string appendString:@" "];
[string appendString:@"NULL"];;
}
}
[string appendString:@"\n}"];
return string;
}
哈希表的功能测试
JKRHashMap_LinkedList *dic = [JKRHashMap_LinkedList new];
for (NSUInteger i = 0; i < 30; i++) {
NSString *key = getRandomStr();
dic[key] = [NSString stringWithFormat:@"%zd", i];
}
NSLog(@"%@", dic);
// 打印:
<JKRHashMap_LinkedList, 0x102814a10>:
count:30 length:16
{
--- index: 0 ---
[Wlqvuq:2 -> Xecsbw:9] [Xecsbw:9 -> Kvfexi:11] [Kvfexi:11 -> NULL]
--- index: 1 ---
[Ifaeuy:15 -> NULL] ,
--- index: 2 ---
[Bmitqy:3 -> Ynqbcw:12] , [Ynqbcw:12 -> NULL] ,
--- index: 3 ---
[Djwmew:0 -> Epzzlc:4] , [Epzzlc:4 -> Jqjrvq:22] , [Jqjrvq:22 -> NULL] ,
--- index: 4 ---
[Myvwre:28 -> NULL] ,
--- index: 5 ---
[Mrgpfv:8 -> Ltdazq:25] , [Ltdazq:25 -> Tzweni:27] , [Tzweni:27 -> NULL] ,
--- index: 6 ---
NULL
--- index: 7 ---
[Eyvque:5 -> Ltmzik:24] , [Ltmzik:24 -> NULL] ,
--- index: 8 ---
[Rvnupm:7 -> NULL] ,
--- index: 9 ---
[Ryrort:16 -> NULL] ,
--- index: 10 ---
[Rsdkaw:1 -> Hgszuk:20] , [Hgszuk:20 -> Jtrtes:26] , [Jtrtes:26 -> NULL] ,
--- index: 11 ---
[Txonlm:29 -> NULL] ,
--- index: 12 ---
[Bvbdbe:14 -> NULL] ,
--- index: 13 ---
[Pszvix:6 -> Dtizif:19] , [Dtizif:19 -> Czkxyj:21] , [Czkxyj:21 -> Kzatxv:23] , [Kzatxv:23 -> NULL] ,
--- index: 14 ---
[Ustobp:10 -> Erqclk:13] , [Erqclk:13 -> Fbliqs:17] , [Fbliqs:17 -> Jpcvbm:18] , [Jpcvbm:18 -> NULL] ,
--- index: 15 ---
NULL
}
可以看到,哈希表中的值平均分散在数组中,出现哈希冲突时,以单向链表的形式存储。
和NSMutableDictionary对比哈希表的性能测试
既然要做性能的对比测试,首先需要数据,这里使用苹果公布的objc4源代码,官方下载地址:opensource.apple.com/tarballs/ob…,将其中runtime的源码文件夹当作资源文件:
读取其中所有文件的代码,取出其中的所有单词,计算不同单词出现的次数。
这个需求刚好可以利用字典或者我们自定义的哈希表,将单词做为key,将单词出现的次数做为value,计算逻辑如下:
- 首先读取所有文件并截取出所有单词(包括重复的)。
- 遍历所有单词,将单词做为key,依次添加到哈希表中。
- 添加前,先通过key从哈希表中取值,如果取到,则value为取到的值+1,否则为1,将key、value存入哈希表中。
这样当依次遍历添加完所有单词后,哈希表中存放的就是每个单词出现的次数。
首先取出所有单词:
NSMutableArray * allFileStrings() {
NSFileManager *fileManager = [NSFileManager defaultManager];
NSError *fileManagerError;
NSString *fileDirectory = @"/Users/Lucky/Documents/SourceCode/runtime";
NSArray<NSString *> *array = [fileManager subpathsOfDirectoryAtPath:fileDirectory error:&fileManagerError];
if (fileManagerError) {
NSLog(@"读取文件夹失败");
nil;
}
NSLog(@"文件路径: %@", fileDirectory);
NSLog(@"文件个数: %zd", array.count);
NSMutableArray *allStrings = [NSMutableArray array];
[array enumerateObjectsUsingBlock:^(NSString * _Nonnull obj, NSUInteger idx, BOOL * _Nonnull stop) {
NSString *filePath = [fileDirectory stringByAppendingPathComponent:obj];
NSError *fileReadError;
NSString *str = [NSString stringWithContentsOfFile:filePath encoding:NSUTF8StringEncoding error:&fileReadError];
if (fileReadError) {
return;
}
[str enumerateSubstringsInRange:NSMakeRange(0, str.length) options:NSStringEnumerationByWords usingBlock:^(NSString * _Nullable substring, NSRange substringRange, NSRange enclosingRange, BOOL * _Nonnull stop) {
[allStrings addObject:substring];
}];
}];
NSLog(@"所有单词的数量: %zd", allStrings.count);
return allStrings;
}
然后依次遍历并加入哈希表中:
JKRHashMap_LinkedList *map = [JKRHashMap_LinkedList new];
[JKRTimeTool teskCodeWithBlock:^{
NSMutableDictionary *map = [NSMutableDictionary new];
[allStrings enumerateObjectsUsingBlock:^(id _Nonnull obj, NSUInteger idx, BOOL * _Nonnull stop) {
NSNumber *count = map[obj];
if (count) {
count = [NSNumber numberWithInteger:count.integerValue+1];
} else {
count = [NSNumber numberWithInteger:1];
}
map[obj] = count;
}];
NSLog(@"NSMutableDictionary 计算不重复单词数量和出现次数 %zd", map.count);
NSLog(@"NSMutableDictionary 计算单词出现的次数NSObject: %@", map[@"NSObject"]);
NSLog(@"NSMutableDictionary 计算单词出现的次数include: %@", map[@"include"]);
NSLog(@"NSMutableDictionary 计算单词出现的次数return: %@", map[@"return"]);
__block NSUInteger allCount = 0;
[allStrings enumerateObjectsUsingBlock:^(id _Nonnull obj, NSUInteger idx, BOOL * _Nonnull stop) {
allCount += [map[obj] integerValue];
[map removeObjectForKey:obj];
}];
NSLog(@"NSMutableDictionary 累加计算所有单词数量 %zd", allCount);
}];
// 打印:
文件个数: 104
所有单词的数量: 165627
JKRHashMap_LinkedList 计算不重复单词数量和出现次数 10490
JKRHashMap_LinkedList 计算单词出现的次数NSObject: 34
JKRHashMap_LinkedList 计算单词出现的次数include: 379
JKRHashMap_LinkedList 计算单词出现的次数return: 2681
JKRHashMap_LinkedList 累加计算所有单词数量 165627
耗时: 14.768 s
下面使用NSMutableDictionary测试一遍:
[JKRTimeTool teskCodeWithBlock:^{
NSMutableDictionary *map = [NSMutableDictionary new];
[allStrings enumerateObjectsUsingBlock:^(id _Nonnull obj, NSUInteger idx, BOOL * _Nonnull stop) {
NSNumber *count = map[obj];
if (count) {
count = [NSNumber numberWithInteger:count.integerValue+1];
} else {
count = [NSNumber numberWithInteger:1];
}
map[obj] = count;
}];
NSLog(@"NSMutableDictionary 计算不重复单词数量和出现次数 %zd", map.count);
NSLog(@"NSMutableDictionary 计算单词出现的次数NSObject: %@", map[@"NSObject"]);
NSLog(@"NSMutableDictionary 计算单词出现的次数include: %@", map[@"include"]);
NSLog(@"NSMutableDictionary 计算单词出现的次数return: %@", map[@"return"]);
__block NSUInteger allCount = 0;
[allStrings enumerateObjectsUsingBlock:^(id _Nonnull obj, NSUInteger idx, BOOL * _Nonnull stop) {
allCount += [map[obj] integerValue];
[map removeObjectForKey:obj];
}];
NSLog(@"NSMutableDictionary 累加计算所有单词数量 %zd", allCount);
}];
// 打印:
文件个数: 104
所有单词的数量: 165627
NSMutableDictionary 计算不重复单词数量和出现次数 10490
NSMutableDictionary 计算单词出现的次数NSObject: 34
NSMutableDictionary 计算单词出现的次数include: 379
NSMutableDictionary 计算单词出现的次数return: 2681
NSMutableDictionary 累加计算所有单词数量 165627
耗时: 0.058 s
发现所有的计算结果都是一样的,证明我们的哈希表确实可以和系统的NSMutableDictionary完成一样的功能,但是时间上有这非常大差距:14.768s VS 0.058s,好吧,简直慢到不能忍。
哈希表的优化-扩容
首先分析下为什么我们的哈希表这么慢,其实很简单,因为我们的哈希表默认容量是 1 << 4 = 16,长度只有16的数组内,分散存放了10490条数据,平均数组的一个位置存放了655个节点,即每个单向链表平均长度达到了655,而基于我们上面实现的哈希表的存、取、读都是通过单向链表从头节点开始遍历,那么当哈希表元素过多,链表长度越长时,遍历所需时间必然越长。
为了防止每条链表过长,我们需要在哈希表元素达到一定数量就要扩展哈希表数组的长度,这非常类似于动态数组的扩容操作。同时,如果哈希表数组长度发生变化,每个key对应哈希函数计算出的index必然发生变化,那么原来存放在哈希表中的节点还需要重新调整在哈希表中的位置。
那么什么时候去扩充哈希表的容量呢,据科学统计,当哈希表的存储的元素个数大于数组的长度 * 0.75时,扩容最优,我们就采用这个规则。
首先在添加键值对的方法最开始添加一个扩容方法:
- (void)setObject:(id)object forKey:(id)key {
[self resize];
// ...
}
当数组元素个数小于哈希表长度 * 0.75 时,不去扩容,否则就扩容。
- (void)resize {
if (_size <= self.array.length * 0.75) return;
}
扩容需要创建一个新的容量更大的数组,这里我们采用扩容后的数组是原来的数组的两倍:
JKRArray *oldArray = self.array;
self.array = [JKRArray arrayWithLength:oldArray.length << 1];
需要将原来数组中的所有节点重新排列在哈希表中,这里采用复用原来的节点,只将它们的位置重新排列,而不是依次取出值重新添加到哈希表中,因为这样需要重建创建所有节点,我们这里节省不必要的开销:
for (NSUInteger i = 0; i < oldArray.length; i++) {
JKRHashMap_LinkedList_Node *node = oldArray[i];
while (node) {
JKRHashMap_LinkedList_Node *moveNode = node;
node = node.next;
moveNode.next = nil;
// 重新排列节点
[self moveNode:moveNode];
}
}
重新排列节点的逻辑如下:
- 1,取出该节点的key计算index。
- 2,通过index取出节点。
- 3,判断节点是否为空。如果为空进入第4步,否则进入第5步。
- 4,将数组index位置存放该节点。
- 5,依次遍历到最后一个节点,将最后一个节点的next指向该节点。
完整扩容逻辑如下:
- (void)resize {
if (_size <= self.array.length * 0.75) return;
JKRArray *oldArray = self.array;
self.array = [JKRArray arrayWithLength:oldArray.length << 1];
for (NSUInteger i = 0; i < oldArray.length; i++) {
JKRHashMap_LinkedList_Node *node = oldArray[i];
while (node) {
JKRHashMap_LinkedList_Node *moveNode = node;
node = node.next;
moveNode.next = nil;
[self moveNode:moveNode];
}
}
}
- (void)moveNode:(JKRHashMap_LinkedList_Node *)newNode {
NSUInteger index = [self indexWithKey:newNode.key];
JKRHashMap_LinkedList_Node *node = self.array[index];
if (!node) {
self.array[index] = newNode;
return;
}
JKRHashMap_LinkedList_Node *preNode = nil;
while (node) {
preNode = node;
node = node.next;
}
preNode.next = newNode;
}
扩容后性能对比
扩容后重复上面的测试,打印如下:
NSMutableDictionary 计算不重复单词数量和出现次数 10490
耗时: 0.066 s
JKRHashMap_LinkedList 计算不重复单词数量和出现次数 10490
耗时: 0.192 s
时间已经从之前的 14.768s 减少到 0.192s。
接下来
仅仅使用单向链表实现的哈希表并不能够保证所有情况的查找速度,当哈希函数计算出现问题或者数据量特别大的时候,很可能出现某一条单向链表长度非常长。
在JDK开源的哈希表解决方案中,单链表长度超过一定值时,将链表转换成红黑树的方法解决这个问题,后面也会采用红黑树的方式重新实现一遍哈希表。但是在这之前,会先介绍队列和栈的实现,因为它们这是二叉树操作的基础。
