App在后台久置后,再次从桌面或最近的任务列表唤醒时经常会发生崩溃,这往往是App在后台被系统杀死,再次恢复的时候遇到了问题,而在使用FragmentActivity+Fragment的时候,经常会遇到:比如Fragment没有提供默认构造方法,就会重建的时候因为反射创建Fragment失败而崩溃,再比如,在onCreate里面new 一个FragmentDialog,并且show,在被后台杀死,再次唤醒的时候,就会show两个对话框,这是为什么?其实这就涉及了后台杀死及恢复的机制。
FragmentActivity被后台杀死后恢复逻辑
当App被后台异常杀死后,再次点击icon,或者从最近任务列表进入的时候,系统会帮助恢复当时的场景,重新创建Activity,对于FragmentActivity,由于其中有Framgent,逻辑会相对再复杂一些,系统会首先重建被销毁的Fragment。看FragmentActivity的onCreat代码:
我们创建一个Activity,并且在onCreate函数中新建并show一个DialogFragment,之后通过某种方式将APP异常杀死(RogueKiller模拟后台杀死工具),再次从最近的任务唤起App的时候,会发现显示了两个DialogFragment,代码如下:
public class DialogFragmentActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
DialogFragment dialogFragment = new FragmentDlg();
dialogFragment.show(getSupportFragmentManager(), "");
}
虽然被杀死了,但是onCreate函数在执行的时候还是只执行了一次啊,为什么会出现两个DialogFragment,这里其实就有一个DialogFragment是通过Android自身的恢复重建机制重建出来,在异常杀死的情况下onCreate(Bundle savedInstanceState)函数的savedInstanceState参数也不是null,而是包含了被杀死时所保存的场景信息。再来看个崩溃的例子,新建一个CrashFragment,并且丢弃默认无参构造方法:
public class CrashFragment extends Fragment {
public CrashFragment(String tag) {
super();
}
}
之后再Activity中Add或replace添加这个CrashFragment,在CrashFragment显示后,通过RogueKiller模拟后台杀死工具模拟后台杀死,再次从最近任务列表里唤起App的时候,就会遇到崩溃,
Caused by: android.support.v4.app.Fragment$InstantiationException:
Unable to instantiate fragment xxx.CrashFragment:
make sure class name exists, is public, and has an empty constructor that is public
at android.support.v4.app.Fragment.instantiate(Fragment.java:431)
at android.support.v4.app.FragmentState.instantiate(Fragment.java:102)
at android.support.v4.app.FragmentManagerImpl.restoreAllState(FragmentManager.java:1952)
at android.support.v4.app.FragmentController.restoreAllState(FragmentController.java:144)
at android.support.v4.app.FragmentActivity.onCreate(FragmentActivity.java:307)
at android.support.v7.app.AppCompatActivity.onCreate(AppCompatActivity.java:81)
上面的这两个问题主要涉及后台杀死后FragmentActivity自身的恢复机制,其实super.onCreate(savedInstanceState)在恢复时做了很多我们没有看到的事情,先看一下崩溃:
为什么Fragment没有无参构造方法会引发崩溃
看一下support-V4中FragmentActivity中onCreate代码如下:
protected void onCreate(@Nullable Bundle savedInstanceState) {
mFragments.attachHost(null /*parent*/);
super.onCreate(savedInstanceState);
...
if (savedInstanceState != null) {
Parcelable p = savedInstanceState.getParcelable(FRAGMENTS_TAG);
mFragments.restoreAllState(p, nc != null ? nc.fragments : null);
}
mFragments.dispatchCreate();
}
可以看到如果savedInstanceState != null,就会执行mFragments.restoreAllState逻辑,其实这里就牵扯到恢复时重建逻辑,再被后台异常杀死前,或者说在Activity的onStop执行前,Activity的现场以及Fragment的现场都是已经被保存过的,其实是被保存早ActivityManagerService中,保存的格式FragmentState,重建的时候,会采用反射机制重新创Fragment
void restoreAllState(Parcelable state, List<Fragment> nonConfig) {
...
for (int i=0; i<fms.mActive.length; i++) {
FragmentState fs = fms.mActive[i];
if (fs != null) {
Fragment f = fs.instantiate(mHost, mParent);
mActive.add(f);
...
其实就是调用FragmentState的instantiate,进而调用Fragment的instantiate,最后通过反射,构建Fragment,也就是,被加到FragmentActivity的Fragment在恢复的时候,会被自动创建,并且采用Fragment的默认无参构造方法,如果没哟这个方法,就会抛出InstantiationException异常,这也是为什么第二个例子中会出现崩溃的原因。
*/
public static Fragment instantiate(Context context, String fname, @Nullable Bundle args) {
try {
Class<?> clazz = sClassMap.get(fname);
if (clazz == null) {
// Class not found in the cache, see if it's real, and try to add it
clazz = context.getClassLoader().loadClass(fname);
sClassMap.put(fname, clazz);
}
Fragment f = (Fragment)clazz.newInstance();
if (args != null) {
args.setClassLoader(f.getClass().getClassLoader());
f.mArguments = args;
}
return f;
} catch (ClassNotFoundException e) {
throw new InstantiationException("Unable to instantiate fragment " + fname
+ ": make sure class name exists, is public, and has an"
+ " empty constructor that is public", e);
} catch (java.lang.InstantiationException e) {
throw new InstantiationException("Unable to instantiate fragment " + fname
+ ": make sure class name exists, is public, and has an"
+ " empty constructor that is public", e);
} catch (IllegalAccessException e) {
throw new InstantiationException("Unable to instantiate fragment " + fname
+ ": make sure class name exists, is public, and has an"
+ " empty constructor that is public", e);
}
}
q 可以看到场景二提示的errormsg跟抛出的异常是可以对应上的,其实Fragment源码里面也说得很清楚:
/**
* Default constructor. <strong>Every</strong> fragment must have an
* empty constructor, so it can be instantiated when restoring its
* activity's state. It is strongly recommended that subclasses do not
* have other constructors with parameters, since these constructors
* will not be called when the fragment is re-instantiated; instead,
* arguments can be supplied by the caller with {@link #setArguments}
* and later retrieved by the Fragment with {@link #getArguments}.
*
* <p>Applications should generally not implement a constructor. The
* first place application code an run where the fragment is ready to
* be used is in {@link #onAttach(Activity)}, the point where the fragment
* is actually associated with its activity. Some applications may also
* want to implement {@link #onInflate} to retrieve attributes from a
* layout resource, though should take care here because this happens for
* the fragment is attached to its activity.
*/
public Fragment() {
}
大意就是,Fragment必须有一个空构造方法,这样才能保证重建流程,并且,Fragment的子类也不推荐有带参数的构造方法,最好采用setArguments来保存参数。下面再来看下为什么会出现两个DialogFragment。
为什么出现两个DialogFragment
Fragment在被创建之后,如果不通过add或者replace添加到Activity的布局中是不会显示的,在保存现场的时候,也是保存了add的这个状态的,来看一下Fragment的add逻辑:此时被后台杀死,或旋转屏幕,被恢复的DialogFragmentActivity时会出现两个FragmentDialog,一个被系统恢复的,一个新建的。
Add一个Fragment,并显示的原理–所谓Fragment生命周期
通常我们FragmentActivity使用Fragment的方法如下:假设是在oncreate函数中:
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
Fragment fr = Fragment.instance("")
getSupportFragmentManager().beginTransaction()
.add(R.id.container,fr).commit();
其中getSupportFragmentManager返回的是FragmentManager的子类FragmentManagerImpl,FragmentManagerImpl是FragmentActivity的一个内部类,其Fragment的管理逻辑都是由FragmentManagerImpl来处理的,本文是基于4.3,后面的高版本引入了FragmentController其实也只是多了一层封装,原理差别不是太大,有兴趣可以自己分析:
public class FragmentActivity extends Activity{
...
final FragmentManagerImpl mFragments = new FragmentManagerImpl();
...
final FragmentContainer mContainer = new FragmentContainer() {
@Override
@Nullable
public View findViewById(int id) {
return FragmentActivity.this.findViewById(id);
}
@Override
public boolean hasView() {
Window window = FragmentActivity.this.getWindow();
return (window != null && window.peekDecorView() != null);
}
};
FragmentManagerImpl的beginTransaction()函数返回的是一个BackStackRecord()
@Override
public FragmentTransaction beginTransaction() {
return new (this);
}
从名字就可以看出,beginTransaction是为FragmentActivity生成一条Transaction(事务),可以执行,也可以反向,作为退栈的一个依据,FragmentTransaction的add函数实现如下,
public FragmentTransaction add(Fragment fragment, String tag) {
doAddOp(0, fragment, tag, OP_ADD);//异步操作的,跟Hander类似
return this;
}
private void doAddOp(int containerViewId, Fragment fragment, String tag, int opcmd) {
fragment.mFragmentManager = mManager;
...
Op op = new Op();
op.cmd = opcmd;
op.fragment = fragment;
addOp(op);
}
之后commit这个Transaction, 将Transaction插入到Transaction队列中去,最终会回调FragmentManager的addFragment方法,将Fragment添加FragmentManagerImpl到维护Fragment列表中去,并且根据当前的Activity状态,将Fragment调整到合适的状态,代码如下:
public void addFragment(Fragment fragment, boolean moveToStateNow) {
if (mAdded == null) {
mAdded = new ArrayList<Fragment>();
}
makeActive(fragment);
if (!fragment.mDetached) {
if (mAdded.contains(fragment)) {
throw new IllegalStateException("Fragment already added: " + fragment);
}
mAdded.add(fragment);
fragment.mAdded = true;
fragment.mRemoving = false;
if (fragment.mHasMenu && fragment.mMenuVisible) {
mNeedMenuInvalidate = true;
}
if (moveToStateNow) {
moveToState(fragment);
}
}
}
为什么说FragmentManager是FragmentActivity管理Fragment的核心呢,请看下面:
final class FragmentManagerImpl extends FragmentManager implements LayoutInflaterFactory {
...
ArrayList<Runnable> mPendingActions;
Runnable[] mTmpActions;
boolean mExecutingActions;
ArrayList<Fragment> mActive;
ArrayList<Fragment> mAdded;
ArrayList<Integer> mAvailIndices;
ArrayList<BackStackRecord> mBackStack;
可以看出FragmentManagerImpl帮FragmentActivity维护着所有管理Fragment的列表,FragmentManagerImpl的State是和Activity的State一致的,这是管理Fragment的关键。其实Fragment自身是没有什么生命周期的,它只是一个View的封装,完全依靠FragmentManagerImpl来进行同步模拟生命周期,比如在onCreate函数中创建Fragment,add后,在执行的到Activity自身的onCreateView之前,Fragment的onCreateView是不会执行的,也就是Fragment是被动式的跟FragmentActivity保持一致。既然Fragment只是个View的封装,那么它是如何转换成View,并添加到Container中去的呢?关键是moveToState函数,这个函数强制将新add的Fragment的生命周期与Activity同步:
void moveToState(Fragment f, int newState, int transit, int transitionStyle,
boolean keepActive) {
...
if (f.mState < newState) { //低于当前Activity的状态
switch (f.mState) {
case Fragment.INITIALIZING:
...
f.mActivity = mActivity;
f.mParentFragment = mParent;
f.mFragmentManager = mParent != null
? mParent.mChildFragmentManager : mActivity.mFragments;
f.mCalled = false;
f.onAttach(mActivity);
...
if (!f.mRetaining) {
f.performCreate(f.mSavedFragmentState);
}
case Fragment.CREATED:
if (newState > Fragment.CREATED) {
f.mView = f.performCreateView(f.getLayoutInflater(
f.mSavedFragmentState), container, f.mSavedFragmentState);
f.onViewCreated(f.mView, f.mSavedFragmentState);
f.performActivityCreated(f.mSavedFragmentState);
if (f.mView != null) {
f.restoreViewState(f.mSavedFragmentState);
}
f.mSavedFragmentState = null;
}
case Fragment.ACTIVITY_CREATED:
case Fragment.STOPPED:
if (newState > Fragment.STOPPED) {
f.performStart();
}
case Fragment.STARTED:
if (newState > Fragment.STARTED) {
f.mResumed = true;
f.performResume();
可以看出,add Fragment之后,需要让Fragment跟当前Activity的State保持一致。现在回归正题,对于后台杀死状态下,为什么会show两个DialogFragment呢,我们需要接着看就要Fragment的异常处理的流程,在Fragment没有无参构造方法会引发崩溃里面,分析只是走到了Fragment的构建,现在接着往下走。提供无参构造函数后,Fragment可以正确的新建出来,之后呢?之后就是一些恢复逻辑,接着看restoreAllState:
void restoreAllState(Parcelable state, ArrayList<Fragment> nonConfig) {
if (state == null) return;
FragmentManagerState fms = (FragmentManagerState)state;
mActive = new ArrayList<Fragment>(fms.mActive.length);
for (int i=0; i<fms.mActive.length; i++) {
FragmentState fs = fms.mActive[i];
if (fs != null) {
Fragment f = fs.instantiate(mActivity, mParent);
mActive.add(f);
fs.mInstance = null;
// Build the list of currently added fragments.
if (fms.mAdded != null) {
mAdded = new ArrayList<Fragment>(fms.mAdded.length);
for (int i=0; i<fms.mAdded.length; i++) {
Fragment f = mActive.get(fms.mAdded[i]);
if (f == null) {
throwException(new IllegalStateException(
"No instantiated fragment for index #" + fms.mAdded[i]));
}
f.mAdded = true;
if (DEBUG) Log.v(TAG, "restoreAllState: added #" + i + ": " + f);
if (mAdded.contains(f)) {
throw new IllegalStateException("Already added!");
}
mAdded.add(f);
}
// Build the back stack.
if (fms.mBackStack != null) {
mBackStack = new ArrayList<BackStackRecord>(fms.mBackStack.length);
for (int i=0; i<fms.mBackStack.length; i++) {
BackStackRecord bse = fms.mBackStack[i].instantiate(this);
mBackStack.add(bse);
if (bse.mIndex >= 0) {
setBackStackIndex(bse.mIndex, bse);
}
其实到现在现在Fragment相关的信息已经恢复成功了,之后随着FragmentActivity周期显示或者更新了,这些都是被杀死后,在FragmentActiivyt的onCreate函数处理的,也就是默认已经将之前的Fragment添加到mAdded列表中去了,但是,在场景一,我们有手动新建了一个Fragment,并添加进去,所以,mAdded函数中就有连个两个Fragment。这样,在FragmentActivity调用onStart函数之后,会新建mAdded列表中Fragment的视图,将其添加到相应的container中去,并在Activity调用onReusume的时候,显示出来做的,这个时候,就会显示两份,其实如果,在这个时候,你再杀死一次,恢复,就会显示三分,在杀死,重启,就是四份。。。。
@Override
protected void onStart() {
super.onStart();
mStopped = false;
mReallyStopped = false;
mHandler.removeMessages(MSG_REALLY_STOPPED);
if (!mCreated) {
mCreated = true;
mFragments.dispatchActivityCreated();
}
mFragments.noteStateNotSaved();
mFragments.execPendingActions();
mFragments.doLoaderStart();
// NOTE: HC onStart goes here.
mFragments.dispatchStart();
mFragments.reportLoaderStart();
}
以上就是针对两个场景,对FramgentActivity的一些分析,主要是回复时候,对于Framgent的一些处理。
onSaveInstanceState与OnRestoreInstance的调用时机
在在点击home键,或者跳转其他界面的时候,都会回调用onSaveInstanceState,但是再次唤醒却不一定调用OnRestoreInstance,这是为什么呢?onSaveInstanceState与OnRestoreInstance难道不是配对使用的?在Android中,onSaveInstanceState是为了预防Activity被后台杀死的情况做的预处理,如果Activity没有被后台杀死,那么自然也就不需要进行现场的恢复,也就不会调用OnRestoreInstance,而大多数情况下,Activity不会那么快被杀死。
onSaveInstanceState的调用时机
onSaveInstanceState函数是Android针对可能被后台杀死的Activity做的一种预防,它的执行时机在2.3之前是在onPause之前,2.3之后,放在了onStop函数之前,也就说Activity失去焦点后,可能会由于内存不足,被回收的情况下,都会去执行onSaveInstanceState。
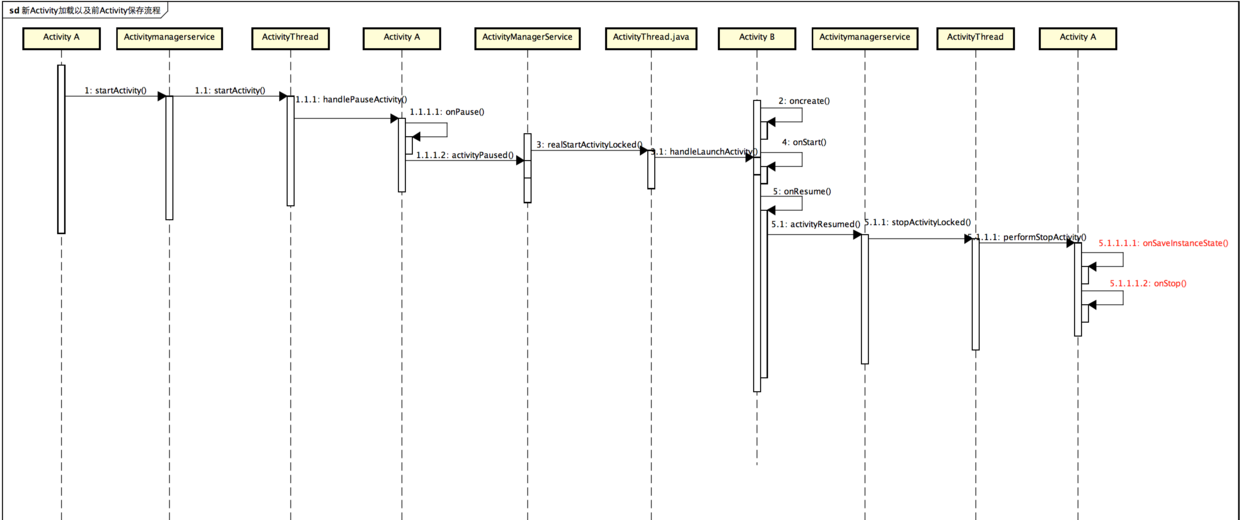
比如在Activity A 调用startActivity启动Activity B的时候,会首先通过AMS pause Activity A,之后唤起B,在B显示,再stop A,在stop A的时候,需要保存A的现场,因为不可见的Activity都是可能被后台杀死的,比如,在开发者选项中打开不保留活动,就会达到这种效果,在启动另一个Activity时,上一个Activity的保存流程大概如下
在2.3之后,onSaveInstanceState的时机都放在了onStop之前,看一下FragmentActivity的onSaveInstanceState源码:
@Override
protected void onSaveInstanceState(Bundle outState) {
super.onSaveInstanceState(outState);
Parcelable p = mFragments.saveAllState();
if (p != null) {
outState.putParcelable(FRAGMENTS_TAG, p);
}
}
可以看出,首先就是父类的onSaveInstanceState,主要是保存一些窗口及View的信息,比如ViewPager当前显示的是第几个View等。之后,就是就是通过FragmentManager的saveAllState,来保存FragmentActivity自身的现场-Fragment的一些状态,这些数据是FragmentActivity恢复Framgent所必须的数据,处理不好就会出现上面的那种异常。
OnRestoreInstanceState的调用时机
OnRestoreInstanceState虽然与onSaveInstanceState是配对实现的,但是其调用却并非完全成对的,在Activity跳转或者返回主界面时,onSaveInstanceState是一定会调用的,但是OnRestoreInstanceState却不会,它只有Activity或者App被异常杀死,走恢复流程的时候才会被调用。如果没有被异常杀死,不走Activity的恢复新建流程,也就不会回调OnRestoreInstanceState,简单看一下Activity的加载流程图:
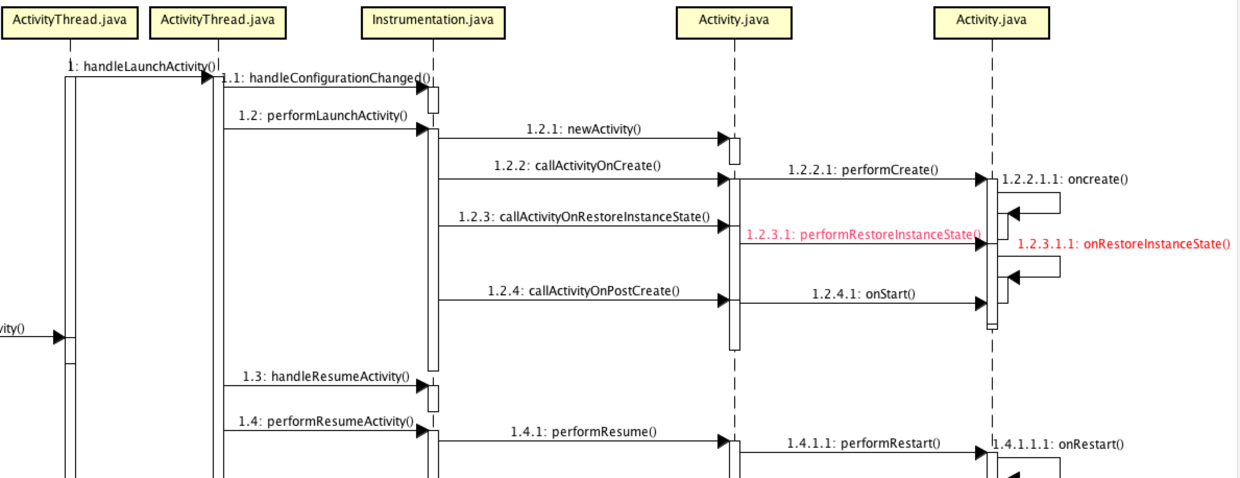
可以看出,OnRestoreInstanceState的调用时机是在onStart之后,在onPostCreate之前。那么正常的创建为什么没调用呢?看一下ActivityThread中启动Activity的源码:
private Activity performLaunchActivity(Activi
...
mInstrumentation.callActivityOnCreate(activity, r.state);
r.activity = activity;
r.stopped = true;
if (!r.activity.mFinished) {
activity.performStart();
r.stopped = false;
}
if (!r.activity.mFinished) {
if (r.state != null) {
mInstrumentation.callActivityOnRestoreInstanceState(activity, r.state);
}
}
if (!r.activity.mFinished) {
activity.mCalled = false;
mInstrumentation.callActivityOnPostCreate(activity, r.state);
}
}
可以看出,只有r.state != null的时候,才通过mInstrumentation.callActivityOnRestoreInstanceState回调OnRestoreInstanceState,r.state就是ActivityManagerService通过Binder传给ActivityThread数据,主要用来做场景恢复。以上就是onSaveInstanceState与OnRestoreInstance执行时机的一些分析。下面结合具体的系统View控件来分析一下这两个函数的具体应用:比如ViewPager与FragmentTabHost,这两个空间是主界面最常用的控件,内部对后台杀死做了兼容,这也是为什么被杀死后,Viewpager在恢复后,能自动定位到上次浏览的位置。
ViewPager应对后台杀死做的兼容
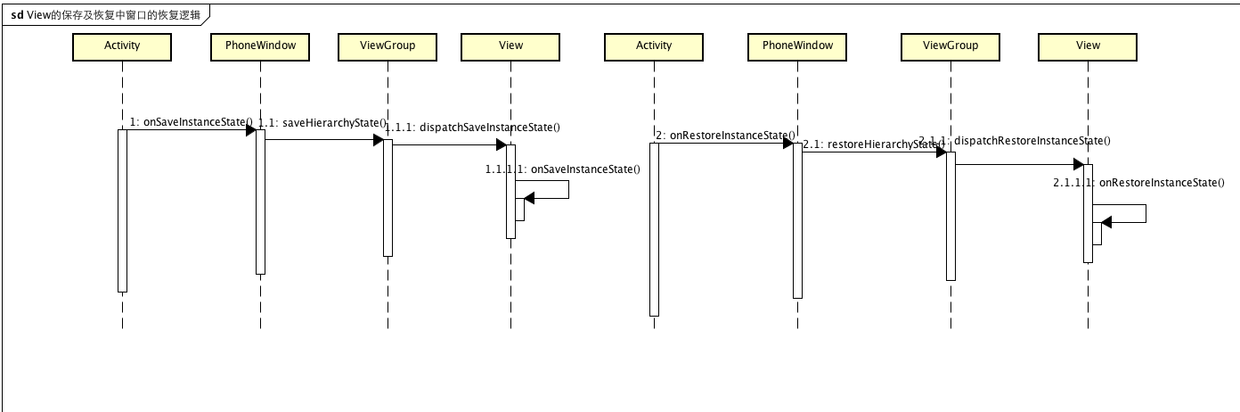
首先看一下ViewPager做的兼容,ViewPager在后台杀死的情况下,仍然能恢复到上次关闭的位置,这也是对体验的一种优化,这其中的原理是什么?之前分析onSaveInstanceState与onRestoreInstanceState的时候,只关注了Fragment的处理,其实还有一些针对Window窗口及View的处理,先看一下onSaveInstanceState针对窗口保存了什么:
protected void onSaveInstanceState(Bundle outState) {
outState.putBundle(WINDOW_HIERARCHY_TAG, mWindow.saveHierarchyState());
}
PhonwWinow.java
@Override
public Bundle saveHierarchyState() {
Bundle outState = new Bundle();
if (mContentParent == null) {
return outState;
}
SparseArray<Parcelable> states = new SparseArray<Parcelable>();
mContentParent.saveHierarchyState(states);
outState.putSparseParcelableArray(VIEWS_TAG, states);
// save the focused view id
View focusedView = mContentParent.findFocus();
...
outState.putInt(FOCUSED_ID_TAG, focusedView.getId());
// save the panels
if (panelStates.size() > 0) {
outState.putSparseParcelableArray(PANELS_TAG, panelStates);
}
if (mActionBar != null) {
outState.putSparseParcelableArray(ACTION_BAR_TAG, actionBarStates);
}
return outState;
}
Window其实就是PhonwWinow,saveHierarchyState其实就是针对当前窗口中的View保存一些场景信息 ,比如:当前获取焦点的View的id、ActionBar、View的一些状态,当然saveHierarchyState递归遍历所有子View,保存所有需要保存的状态:
ViewGroup.java
@Override
protected void dispatchSaveInstanceState(SparseArray<Parcelable> container) {
super.dispatchSaveInstanceState(container);
final int count = mChildrenCount;
final View[] children = mChildren;
for (int i = 0; i < count; i++) {
View c = children[i];
if ((c.mViewFlags & PARENT_SAVE_DISABLED_MASK) != PARENT_SAVE_DISABLED) {
c.dispatchSaveInstanceState(container);
}
}
}
可见,该函数首先通过super.dispatchSaveInstanceState保存自身的状态,再递归传递给子View。onSaveInstanceState主要用于获取View需要保存的State,并将自身的ID作为Key,存储到SparseArray states列表中,其实就PhoneWindow的一个列表,这些数据最后会通过Binder保存到ActivityManagerService中去
View.java
protected void dispatchSaveInstanceState(SparseArray<Parcelable> container) {
if (mID != NO_ID && (mViewFlags & SAVE_DISABLED_MASK) == 0) {
mPrivateFlags &= ~PFLAG_SAVE_STATE_CALLED;
Parcelable state = onSaveInstanceState();
if ((mPrivateFlags & PFLAG_SAVE_STATE_CALLED) == 0) {
throw new IllegalStateException(
"Derived class did not call super.onSaveInstanceState()");
}
if (state != null) {
container.put(mID, state);
}
}
}
那么针对ViewPager到底存储了什么信息?通过下面的代码很容易看出,其实就是新建个了一个SavedState场景数据,并且将当前的位置mCurItem存进去。
@Override
public Parcelable onSaveInstanceState() {
Parcelable superState = super.onSaveInstanceState();
SavedState ss = new SavedState(superState);
ss.position = mCurItem;
if (mAdapter != null) {
ss.adapterState = mAdapter.saveState();
}
return ss;
} 到这里存储的事情基本就完成了。接下来看一下ViewPager的恢复以及onRestoreInstanceState到底做了什么,
protected void onRestoreInstanceState(Bundle savedInstanceState) {
if (mWindow != null) {
Bundle windowState = savedInstanceState.getBundle(WINDOW_HIERARCHY_TAG);
if (windowState != null) {
mWindow.restoreHierarchyState(windowState);
}
}
}
从代码可以看出,其实就是获取当时保存的窗口信息,之后通过mWindow.restoreHierarchyState做数据恢复,
@Override
public void restoreHierarchyState(Bundle savedInstanceState) {
if (mContentParent == null) {
return;
}
SparseArray<Parcelable> savedStates
= savedInstanceState.getSparseParcelableArray(VIEWS_TAG);
if (savedStates != null) {
mContentParent.restoreHierarchyState(savedStates);
}
...
if (mActionBar != null) {
...
mActionBar.restoreHierarchyState(actionBarStates);
}
}
对于ViewPager会发生什么?从源码很容易看出,其实就是取出SavedState,并获取到异常杀死的时候的位置,以便后续的恢复,
ViewPager.java
@Override
public void onRestoreInstanceState(Parcelable state) {
if (!(state instanceof SavedState)) {
super.onRestoreInstanceState(state);
return;
}
SavedState ss = (SavedState)state;
super.onRestoreInstanceState(ss.getSuperState());
if (mAdapter != null) {
mAdapter.restoreState(ss.adapterState, ss.loader);
setCurrentItemInternal(ss.position, false, true);
} else {
mRestoredCurItem = ss.position;
mRestoredAdapterState = ss.adapterState;
mRestoredClassLoader = ss.loader;
}
}
以上就解释了ViewPager是如何通过onSaveInstanceState与onRestoreInstanceState保存、恢复现场的。如果是ViewPager+FragmentAdapter的使用方式,就同时涉及FragmentActivity的恢复、也牵扯到Viewpager的恢复,其实FragmentAdapter也同样针对后台杀死做了一些兼容,防止重复新建Fragment,看一下FragmentAdapter的源码:
FragmentPagerAdapter.java
@Override
public Object instantiateItem(ViewGroup container, int position) {
if (mCurTransaction == null) {
mCurTransaction = mFragmentManager.beginTransaction();
}
final long itemId = getItemId(position);
// Do we already have this fragment?
<!--是否已经新建了Fragment??-->
String name = makeFragmentName(container.getId(), itemId);
Fragment fragment = mFragmentManager.findFragmentByTag(name);
1 如果Activity中存在相应Tag的Fragment,就不要通过getItem新建
if (fragment != null) {
mCurTransaction.attach(fragment);
} else {
2 如果Activity中不存在相应Tag的Fragment,就需要通过getItem新建
fragment = getItem(position);
mCurTransaction.add(container.getId(), fragment,
makeFragmentName(container.getId(), itemId));
}
if (fragment != mCurrentPrimaryItem) {
FragmentCompat.setMenuVisibility(fragment, false);
FragmentCompat.setUserVisibleHint(fragment, false);
}
return fragment;
}
从1与2 可以看出,通过后台恢复,在FragmentActivity的onCreate函数中,会重建Fragment列表,那些被重建的Fragment不会再次通过getItem再次创建,再来看一下相似的控件FragmentTabHost,FragmentTabHost也是主页常用的控件,FragmentTabHost也有相应的后台杀死处理机制,从名字就能看出,这个是专门针对Fragment才创建出来的控件。
FragmentTabHost应对后台杀死做的兼容
FragmentTabHost其实跟ViewPager很相似,在onSaveInstanceState执行的时候保存当前位置,并在onRestoreInstanceState恢复postion,并重新赋值给Tabhost,之后FragmentTabHost在onAttachedToWindow时,就可以根据恢复的postion设置当前位置,代码如下:
FragmentTabHost.java
@Override
protected Parcelable onSaveInstanceState() {
Parcelable superState = super.onSaveInstanceState();
SavedState ss = new SavedState(superState);
ss.curTab = getCurrentTabTag();
return ss;
}
@Override
protected void onRestoreInstanceState(Parcelable state) {
if (!(state instanceof SavedState)) {
super.onRestoreInstanceState(state);
return;
}
SavedState ss = (SavedState) state;
super.onRestoreInstanceState(ss.getSuperState());
setCurrentTabByTag(ss.curTab);
}
在FragmentTabHost执行onAttachedToWindow时候,会首先getCurrentTabTag ,如果是经历了后台杀死,这里得到的值其实是恢复的SavedState里的值,之后通过doTabChanged切换到响应的Tab,注意这里切换的时候,Fragment由于已经重建了,是不会再次新建的。
@Override
protected void onAttachedToWindow() {
super.onAttachedToWindow();
String currentTab = getCurrentTabTag();
...
ft = doTabChanged(currentTab, ft);
if (ft != null) {
ft.commit();
mFragmentManager.executePendingTransactions();
}
}
App开发时针对后台杀死处理方式
最简单的方式,但是效果一般:取消系统恢复
比如:针对FragmentActivity ,不重建:
protected void onCreate(Bundle savedInstanceState) {
if (savedInstanceState != null) {
savedInstanceState.putParcelable(“android:support:fragments”, null);
}
super.onCreate(savedInstanceState);
}
如果是系统的Actvity改成是“android:fragments”,不过这里需要注意:对于ViewPager跟FragmentTabHost不需要额外处理,处理了可能反而有反作用。
针对Window,如果不想让View使用恢复逻辑,在基类的FragmentActivity中覆盖onRestoreInstanceState函数即可。
protected void onRestoreInstanceState(Bundle savedInstanceState) {
}
当然以上的做法都是比较粗暴的做法,最好还是顺着Android的设计,在需要保存现场的地方保存,在需要恢复的地方,去除相应的数据进行恢复。
ActivityManagerService恢复App现场机制
假设,一个应用被后台杀死,再次从最近的任务列表唤起App时候,系统是如何处理的呢?
Android框架层(AMS)如何知道App被杀死了
首先来看第一个问题,系统如何知道Application被杀死了,Android使用了Linux的oomKiller机制,只是简单的做了个变种,采用分等级的LowmemoryKiller,但这个其实是内核层面,LowmemoryKiller杀死进程后,如何向用户空间发送通知,并告诉框架层的ActivityMangerService呢?只有AMS在知道App或者Activity是否被杀死后,AMS(ActivityMangerService)才能正确的走重建或者唤起流程,比如,APP死了,但是由于存在需要复活的Service,那么这个时候,进程需要重新启动,这个时候怎么处理的,那么AMS究竟是在什么时候知道App或者Activity被后台杀死了呢?我们先看一下从最近的任务列表进行唤起的时候,究竟发生了什么。
从最近的任务列表或者Icon再次唤起App流程
在系统源码systemUi的包里,有个RecentActivity,这个其实就是最近的任务列表的入口,而其呈现界面是通过RecentsPanelView来展现的,点击最近的App其执行代码如下:
public void handleOnClick(View view) {
ViewHolder holder = (ViewHolder)view.getTag();
TaskDescription ad = holder.taskDescription;
final Context context = view.getContext();
final ActivityManager am = (ActivityManager)
context.getSystemService(Context.ACTIVITY_SERVICE);
Bitmap bm = holder.thumbnailViewImageBitmap;
...
// 关键点 1 如果TaskDescription没有被主动关闭,正常关闭,ad.taskId就是>=0
if (ad.taskId >= 0) {
// This is an active task; it should just go to the foreground.
am.moveTaskToFront(ad.taskId, ActivityManager.MOVE_TASK_WITH_HOME,
opts);
} else {
Intent intent = ad.intent;
intent.addFlags(Intent.FLAG_ACTIVITY_LAUNCHED_FROM_HISTORY
| Intent.FLAG_ACTIVITY_TASK_ON_HOME
| Intent.FLAG_ACTIVITY_NEW_TASK);
try {
context.startActivityAsUser(intent, opts,
new UserHandle(UserHandle.USER_CURRENT));
}...
}
在上面的代码里面,有个判断ad.taskId >= 0,如果满足这个条件,就通过moveTaskToFront唤起APP,那么ad.taskId是如何获取的?recent包里面有各类RecentTasksLoader,这个类就是用来加载最近任务列表的一个Loader,看一下它的源码,主要看一下加载:
@Override
protected Void doInBackground(Void... params) {
// We load in two stages: first, we update progress with just the first screenful
// of items. Then, we update with the rest of the items
final int origPri = Process.getThreadPriority(Process.myTid());
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
final PackageManager pm = mContext.getPackageManager();
final ActivityManager am = (ActivityManager)
mContext.getSystemService(Context.ACTIVITY_SERVICE);
final List<ActivityManager.RecentTaskInfo> recentTasks =
am.getRecentTasks(MAX_TASKS, ActivityManager.RECENT_IGNORE_UNAVAILABLE);
....
TaskDescription item = createTaskDescription(recentInfo.id,
recentInfo.persistentId, recentInfo.baseIntent,
recentInfo.origActivity, recentInfo.description);
....
}
可以看到,其实就是通过ActivityManger的getRecentTasks向AMS请求最近的任务信息,然后通过createTaskDescription创建TaskDescription,这里传递的recentInfo.id其实就是TaskDescription的taskId,来看一下它的意义:
public List<ActivityManager.RecentTaskInfo> getRecentTasks(int maxNum,
int flags, int userId) {
...
IPackageManager pm = AppGlobals.getPackageManager();
final int N = mRecentTasks.size();
...
for (int i=0; i<N && maxNum > 0; i++) {
TaskRecord tr = mRecentTasks.get(i);
if (i == 0
|| ((flags&ActivityManager.RECENT_WITH_EXCLUDED) != 0)
|| (tr.intent == null)
|| ((tr.intent.getFlags()
&Intent.FLAG_ACTIVITY_EXCLUDE_FROM_RECENTS) == 0)) {
ActivityManager.RecentTaskInfo rti
= new ActivityManager.RecentTaskInfo();
rti.id = tr.numActivities > 0 ? tr.taskId : -1;
rti.persistentId = tr.taskId;
rti.baseIntent = new Intent(
tr.intent != null ? tr.intent : tr.affinityIntent);
if (!detailed) {
rti.baseIntent.replaceExtras((Bundle)null);
}
可以看出RecentTaskInfo的id是由TaskRecord决定的,如果TaskRecord中numActivities > 0就去TaskRecord的Id,否则就取-1,这里的numActivities其实就是TaskRecode中记录的ActivityRecord的数目,更具体的细节可以自行查看ActivityManagerService及ActivityStack,那么这里就容易解释了,只要是存活的APP,或者被LowmemoryKiller杀死的APP,其AMS的ActivityRecord是完整保存的,这也是恢复的依据。对于RecentActivity获取的数据其实就是AMS中的翻版,它也是不知道将要唤起的APP是否是存活的,只要TaskRecord告诉RecentActivity是存货的,那么久直接走唤起流程。也就是通过ActivityManager的moveTaskToFront唤起App,至于后续的工作,就完全交给AMS来处理。现看一下到这里的流程图:
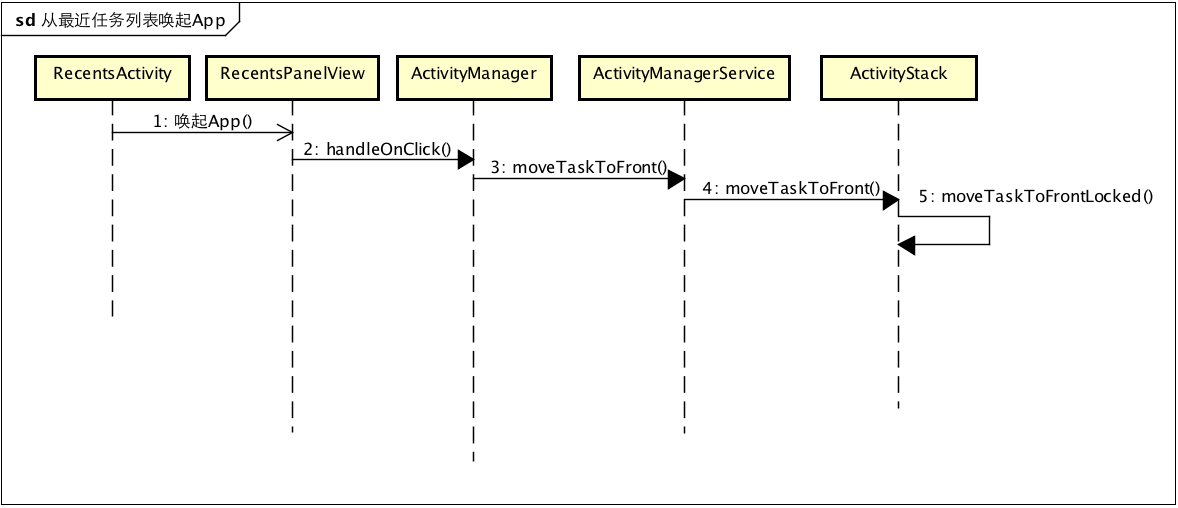
整个APP被后台杀死的情况下AMS是如何恢复现场的
AMS与客户端的通信是通过Binder来进行的,并且通信是”全双工“的,且互为客户端跟服务器,也就说AMS向客户端发命令的时候,AMS是客户端,反之亦然。注意 Binder有个讣告的功能的:如果基于Binder通信的服务端(S)如果挂掉了,客户端(C)能够收到Binder驱动发送的一份讣告,告知客户端Binder服务挂了,可以把Binder驱动看作是第三方不死邮政机构,专门向客户端发偶像死亡通知。对于APP被异常杀死的情况下,这份讣告是发送给AMS的,AMS在收到通知后,就会针对APP被异常杀死的情况作出整理,这里牵扯到Binder驱动的代码有兴趣可以自己翻一下。之类直接冲讣告接受后端处理逻辑来分析,在AMS源码中,入口其实就是appDiedLocked.
final void appDiedLocked(ProcessRecord app, int pid,
IApplicationThread thread) {
...
if (app.pid == pid && app.thread != null &&
app.thread.asBinder() == thread.asBinder()) {
boolean doLowMem = app.instrumentationClass == null;
关键点1
handleAppDiedLocked(app, false, true);
// 如果是被后台杀了,怎么处理
关键点2
if (doLowMem) {
boolean haveBg = false;
for (int i=mLruProcesses.size()-1; i>=0; i--) {
ProcessRecord rec = mLruProcesses.get(i);
if (rec.thread != null && rec.setAdj >= ProcessList.HIDDEN_APP_MIN_ADJ) {
haveBg = true;
break;
}
}
if (!haveBg) {
<!--如果被LowmemoryKiller杀了,就说明内存紧张,这个时候就会通知其他后台APP,小心了,赶紧释放资源-->
EventLog.writeEvent(EventLogTags.AM_LOW_MEMORY, mLruProcesses.size());
long now = SystemClock.uptimeMillis();
for (int i=mLruProcesses.size()-1; i>=0; i--) {
ProcessRecord rec = mLruProcesses.get(i);
if (rec != app && rec.thread != null &&
(rec.lastLowMemory+GC_MIN_INTERVAL) <= now) {
if (rec.setAdj <= ProcessList.HEAVY_WEIGHT_APP_ADJ) {
rec.lastRequestedGc = 0;
} else {
rec.lastRequestedGc = rec.lastLowMemory;
}
rec.reportLowMemory = true;
rec.lastLowMemory = now;
mProcessesToGc.remove(rec);
addProcessToGcListLocked(rec);
}
}
mHandler.sendEmptyMessage(REPORT_MEM_USAGE);
<!--缩减资源-->
scheduleAppGcsLocked();
}
}
}
...
}
先看关键点1:在进程被杀死后,AMS端要选择性清理进程相关信息,清理后,再根据是不是内存低引起的后台杀死,决定是不是需要清理其他后台进程。接着看handleAppDiedLocked如何清理的,这里有重建时的依据:ActivityRecord不清理,但是为它设置个APP未绑定的标识
private final void handleAppDiedLocked(ProcessRecord app,
boolean restarting, boolean allowRestart) {
关键点1
cleanUpApplicationRecordLocked(app, restarting, allowRestart, -1);
...
关键点2
// Remove this application's activities from active lists.
boolean hasVisibleActivities = mMainStack.removeHistoryRecordsForAppLocked(app);
app.activities.clear();
...
关键点3
if (!restarting) {
if (!mMainStack.resumeTopActivityLocked(null)) {
// If there was nothing to resume, and we are not already
// restarting this process, but there is a visible activity that
// is hosted by the process... then make sure all visible
// activities are running, taking care of restarting this
// process.
if (hasVisibleActivities) {
mMainStack.ensureActivitiesVisibleLocked(null, 0);
}
}
}
}
看关键点1,cleanUpApplicationRecordLocked,主要负责清理一些Providers,receivers,service之类的信息,并且在清理过程中根据配置的一些信息决定是否需要重建进程并启动,关键点2 就是关系到唤起流程的判断,关键点3,主要是被杀的进程是否是当前前台进程,如果是,需要重建,并立即显示:先简单看cleanUpApplicationRecordLocked的清理流程
private final void cleanUpApplicationRecordLocked(ProcessRecord app,
boolean restarting, boolean allowRestart, int index) {
<!--清理service-->
mServices.killServicesLocked(app, allowRestart);
...
boolean restart = false;
<!--清理Providers.-->
if (!app.pubProviders.isEmpty()) {
Iterator<ContentProviderRecord> it = app.pubProviders.values().iterator();
while (it.hasNext()) {
ContentProviderRecord cpr = it.next();
。。。
app.pubProviders.clear();
} ...
<!--清理receivers.-->
// Unregister any receivers.
if (app.receivers.size() > 0) {
Iterator<ReceiverList> it = app.receivers.iterator();
while (it.hasNext()) {
removeReceiverLocked(it.next());
}
app.receivers.clear();
}
... 关键点1,进程是够需要重启,
if (restart && !app.isolated) {
// We have components that still need to be running in the
// process, so re-launch it.
mProcessNames.put(app.processName, app.uid, app);
startProcessLocked(app, "restart", app.processName);
}
...
}
从关键点1就能知道,这里是隐藏了进程是否需要重启的逻辑,比如一个Service设置了START_STICKY,被杀后,就需要重新唤起,这里也是流氓软件肆虐的原因。再接着看mMainStack.removeHistoryRecordsForAppLocked(app),对于直观理解APP重建 ,这句代码处于核心的地位,
boolean removeHistoryRecordsForAppLocked(ProcessRecord app) {
...
while (i > 0) {
i--;
ActivityRecord r = (ActivityRecord)mHistory.get(i);
if (r.app == app) {
boolean remove;
<!--关键点1-->
if ((!r.haveState && !r.stateNotNeeded) || r.finishing) {
remove = true;
} else if (r.launchCount > 2 &&
remove = true;
} else {
//一般来讲,走false
remove = false;
}
<!--关键点2-->
if (remove) {
...
removeActivityFromHistoryLocked(r);
} else {
...
r.app = null;
...
}
return hasVisibleActivities;
}
在Activity跳转的时候,准确的说,在stopActivity之前,会保存Activity的现场,这样在AMS端r.haveState==true,也就是说,其ActivityRecord不会被从ActivityStack中移除,同时ActivityRecord的app字段被置空,这里在恢复的时候,是决定resume还是重建的关键。接着往下看moveTaskToFrontLocked,这个函数在ActivityStack中,主要管理ActivityRecord栈的,所有start的Activity都在ActivityStack中保留一个ActivityRecord,这个也是AMS管理Activiyt的一个依据,最终moveTaskToFrontLocked会调用resumeTopActivityLocked来唤起Activity,AMS获取即将resume的Activity信息的方式主要是通过ActivityRecord,它并不知道Activity本身是否存活,获取之后,AMS在唤醒Activity的环节才知道App或者Activity被杀死,具体看一下resumeTopActivityLocked源码:
final boolean resumeTopActivityLocked(ActivityRecord prev, Bundle options) {
...
关键点1
if (next.app != null && next.app.thread != null) {
...
} else {
// Whoops, need to restart this activity!
...
startSpecificActivityLocked(next, true, true);
}
return true;
}
看关键点1的判断条件,由于已经将ActivityRecord的app字段置空,AMS就知道了这个APP或者Activity被异常杀死过,因此,就会走startSpecificActivityLocked进行重建。 其实仔细想想很简单,对于主动调用finish的,AMS并不会清理掉ActivitRecord,在唤起APP的时候,如果AMS检测到APP还存活,就走scheduleResumeActivity进行唤起上一个Activity,但是如果APP或者Activity被异常杀死过,那么AMS就通过startSpecificActivityLocked再次将APP重建,并且将最后的Activity重建。
APP存活,但是Activity被后台杀死的情况下AMS是如何恢复现场的
还有一种可能,APP没有被kill,但是Activity被Kill掉了,这个时候会怎么样。首先,Activity的管理是一定通过AMS的,Activity的kill一定是是AMS操刀的,是有记录的,严格来说,这种情况并不属于后台杀死,因为这属于AMS正常的管理,在可控范围,比如打开了开发者模式中的“不保留活动”,这个时候,虽然会杀死Activity,但是仍然保留了ActivitRecord,所以再唤醒,或者回退的的时候仍然有迹可循,看一下ActivityStack的Destroy回调代码,
final boolean destroyActivityLocked(ActivityRecord r,
boolean removeFromApp, boolean oomAdj, String reason) {
...
if (hadApp) {
...
boolean skipDestroy = false;
try {
关键代码 1
r.app.thread.scheduleDestroyActivity(r.appToken, r.finishing,
r.configChangeFlags);
...
if (r.finishing && !skipDestroy) {
if (DEBUG_STATES) Slog.v(TAG, "Moving to DESTROYING: " + r
+ " (destroy requested)");
r.state = ActivityState.DESTROYING;
Message msg = mHandler.obtainMessage(DESTROY_TIMEOUT_MSG);
msg.obj = r;
mHandler.sendMessageDelayed(msg, DESTROY_TIMEOUT);
} else {
关键代码 2
r.state = ActivityState.DESTROYED;
if (DEBUG_APP) Slog.v(TAG, "Clearing app during destroy for activity " + r);
r.app = null;
}
}
return removedFromHistory;
}
这里有两个关键啊你单,1是告诉客户端的AcvitityThread清除Activity,2是标记如果AMS自己非正常关闭的Activity,就将ActivityRecord的state设置为ActivityState.DESTROYED,并且清空它的ProcessRecord引用:r.app = null。这里是唤醒时候的一个重要标志,通过这里AMS就能知道Activity被自己异常关闭了,设置ActivityState.DESTROYED是为了让避免后面的清空逻辑。
final void activityDestroyed(IBinder token) {
synchronized (mService) {
final long origId = Binder.clearCallingIdentity();
try {
ActivityRecord r = ActivityRecord.forToken(token);
if (r != null) {
mHandler.removeMessages(DESTROY_TIMEOUT_MSG, r);
}
int index = indexOfActivityLocked(r);
if (index >= 0) {
1 <!--这里会是否从history列表移除ActivityRecord-->
if (r.state == ActivityState.DESTROYING) {
cleanUpActivityLocked(r, true, false);
removeActivityFromHistoryLocked(r);
}
}
resumeTopActivityLocked(null);
} finally {
Binder.restoreCallingIdentity(origId);
}
}
}
看代码关键点1,只有r.state == ActivityState.DESTROYING的时候,才会移除ActivityRecord,但是对于不非正常finish的Activity,其状态是不会被设置成ActivityState.DESTROYING,是直接跳过了ActivityState.DESTROYING,被设置成了ActivityState.DESTROYED,所以不会removeActivityFromHistoryLocked,也就是保留了ActivityRecord现场,好像也是依靠异常来区分是否是正常的结束掉Activity。这种情况下是如何启动Activity的呢? 通过上面两点分析,就知道了两个关键点
- ActivityRecord没有动HistoryRecord列表中移除
- ActivityRecord 的ProcessRecord字段被置空,r.app = null
这样就保证了在resumeTopActivityLocked的时候,走startSpecificActivityLocked分支
final boolean resumeTopActivityLocked(ActivityRecord prev, Bundle options) {
...
if (next.app != null && next.app.thread != null) {
...
} else {
// Whoops, need to restart this activity!
...
startSpecificActivityLocked(next, true, true);
}
return true;
}
到这里,AMS就知道了这个APP或者Activity是不是被异常杀死过,从而,决定是走resume流程还是restore流程。
App被杀前的场景是如何保存:新Activity启动跟旧Activity的保存
App现场的保存流程相对是比较简单的,入口基本就是startActivity的时候,只要是界面的跳转基本都牵扯到Activity的切换跟当前Activity场景的保存:先画个简单的图形,开偏里面讲FragmentActivity的时候,简单说了一些onSaveInstance的执行时机,这里详细看一下AMS是如何管理这些跳转以及场景保存的,模拟场景:Activity A 启动Activity B的时候,这个时候A不可见,可能会被销毁,需要保存A的现场,这个流程是什么样的:简述如下
- ActivityA startActivity ActivityB
- ActivityA pause
- ActivityB create
- ActivityB start
- ActivityB resume
- ActivityA onSaveInstance
- ActivityA stop
流程大概是如下样子:
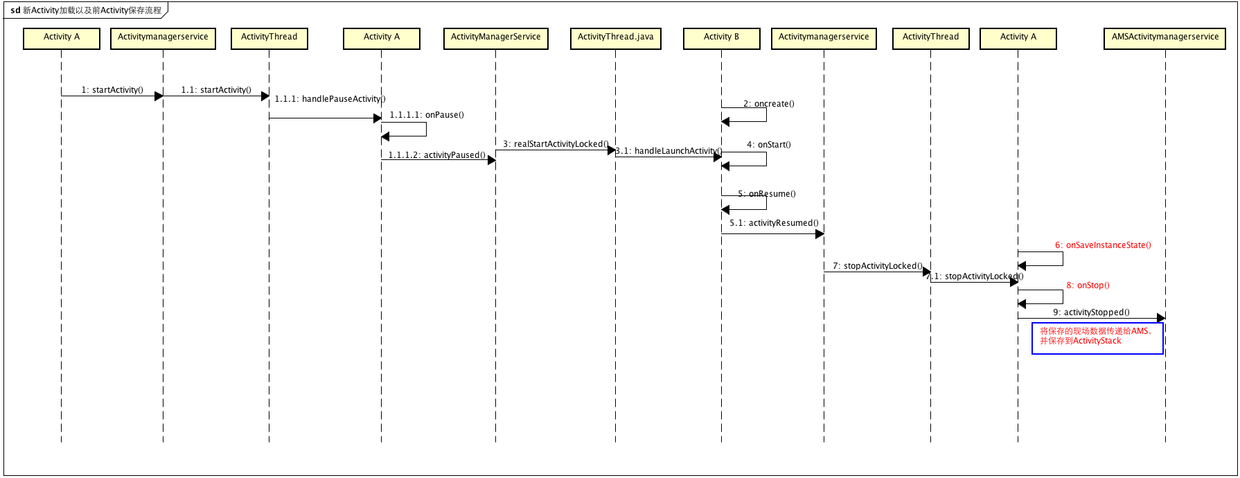
现在我们通过源码一步一步跟一下,看看AMS在新Activity启动跟旧Activity的保存的时候,到底做了什么:跳过简单的startActivity,直接去AMS中去看
ActivityManagerService
public final int startActivityAsUser(IApplicationThread caller, String callingPackage,
Intent intent, String resolvedType, IBinder resultTo,
String resultWho, int requestCode, int startFlags,
String profileFile, ParcelFileDescriptor profileFd, Bundle options, int userId) {
enforceNotIsolatedCaller("startActivity");
...
return mMainStack.startActivityMayWait(caller, -1, callingPackage, intent, resolvedType,
resultTo, resultWho, requestCode, startFlags, profileFile, profileFd,
null, null, options, userId);
}
ActivityStack
final int startActivityMayWait(IApplicationThread caller, int callingUid,
int res = startActivityLocked(caller, intent, resolvedType,
aInfo, resultTo, resultWho, requestCode, callingPid, callingUid,
callingPackage, startFlags, options, componentSpecified, null);
。。。
}
这里通过startActivityMayWait启动新的APP,或者新Activity,这里只看简单的,至于从桌面启动App的流程,可以去参考更详细的文章,比如老罗的startActivity流程,大概就是新建ActivityRecord,ProcessRecord之类,并加入AMS中相应的堆栈等,resumeTopActivityLocked是界面切换的统一入口,第一次进来的时候,由于ActivityA还在没有pause,因此需要先暂停ActivityA,这些完成后,
ActivityStack
final boolean resumeTopActivityLocked(ActivityRecord prev, Bundle options) {
...
<!--必须将当前Resume的Activity设置为pause 然后stop才能继续-->
// We need to start pausing the current activity so the top one
// can be resumed...
if (mResumedActivity != null) {
if (next.app != null && next.app.thread != null) {
mService.updateLruProcessLocked(next.app, false);
}
startPausingLocked(userLeaving, false);
return true;
}
....
}
其实这里就是暂停ActivityA,AMS通过Binder告诉ActivityThread需要暂停的ActivityA,ActivityThread完成后再通过Binder通知AMS,AMS会开始resume ActivityB,
private final void startPausingLocked(boolean userLeaving, boolean uiSleeping) {
if (prev.app != null && prev.app.thread != null) {
...
try {
prev.app.thread.schedulePauseActivity(prev.appToken, prev.finishing,
userLeaving, prev.configChangeFlags);
ActivityThread
private void handlePauseActivity(IBinder token, boolean finished,
boolean userLeaving, int configChanges) {
ActivityClientRecord r = mActivities.get(token);
if (r != null) {
...
performPauseActivity(token, finished, r.isPreHoneycomb());
...
// Tell the activity manager we have paused.
try {
ActivityManagerNative.getDefault().activityPaused(token);
} catch (RemoteException ex) {
}
}
}
AMS收到ActivityA发送过来的pause消息之后,就会唤起ActivityB,入口还是resumeTopActivityLocked,唤醒B,之后还会A给进一步stop掉,这个时候就牵扯到现场的保存,
ActivityStack
private final void completePauseLocked() {
if (!mService.isSleeping()) {
resumeTopActivityLocked(prev);
} else {
...
} ActivityB如何启动的,本文不关心,只看ActivityA如何保存现场的,ActivityB起来后,会通过ActivityStack的stopActivityLocked去stop ActivityA,
private final void stopActivityLocked(ActivityRecord r) {
...
if (mMainStack) {
r.app.thread.scheduleStopActivity(r.appToken, r.visible, r.configChangeFlags);
...
}
回看APP端,看一下ActivityThread中的调用:首先通过callActivityOnSaveInstanceState,将现场保存到Bundle中去,
private void performStopActivityInner(ActivityClientRecord r,
StopInfo info, boolean keepShown, boolean saveState) {
...
// Next have the activity save its current state and managed dialogs...
if (!r.activity.mFinished && saveState) {
if (r.state == null) {
state = new Bundle();
state.setAllowFds(false);
mInstrumentation.callActivityOnSaveInstanceState(r.activity, state);
r.state = state;
。。。
}
之后,通过ActivityManagerNative.getDefault().activityStopped,通知AMS Stop动作完成,在通知的时候,还会将保存的现场数据带过去。
private static class StopInfo implements Runnable {
ActivityClientRecord activity;
Bundle state;
Bitmap thumbnail;
CharSequence description;
@Override public void run() {
// Tell activity manager we have been stopped.
try {
ActivityManagerNative.getDefault().activityStopped(
activity.token, state, thumbnail, description);
} catch (RemoteException ex) {
}
}
}
通过上面流程,AMS不仅启动了新的Activity,同时也将上一个Activity的现场进行了保存,及时由于种种原因上一个Actiivity被杀死,在回退,或者重新唤醒的过程中AMS也能知道如何唤起Activiyt,并恢复。
现在解决两个问题,1、如何保存现场,2、AMS怎么判断知道APP或者Activity是否被异常杀死,那么就剩下最后一个问题了,AMS如何恢复被异常杀死的APP或者Activity呢。
Activity或者Application恢复流程
Application被后台杀死
其实在讲解AMS怎么判断知道APP或者Activity是否被异常杀死的时候,就已经涉及了恢复的逻辑,也知道了一旦AMS知道了APP被后台杀死了,那就不是正常的resuem流程了,而是要重新laucher,先来看一下整个APP被干掉的会怎么处理,看resumeTopActivityLocked部分,从上面的分析已知,这种场景下,会因为Binder通信抛异常走异常分支,如下:
final boolean resumeTopActivityLocked(ActivityRecord prev, Bundle options) {
....
if (next.app != null && next.app.thread != null) {
if (DEBUG_SWITCH) Slog.v(TAG, "Resume running: " + next);
...
try {
...
} catch (Exception e) {
// Whoops, need to restart this activity!
这里是知道整个app被杀死的
Slog.i(TAG, "Restarting because process died: " + next);
next.state = lastState;
mResumedActivity = lastResumedActivity;
Slog.i(TAG, "Restarting because process died: " + next);
startSpecificActivityLocked(next, true, false);
return true;
}
从上面的代码可以知道,其实就是走startSpecificActivityLocked,这根第一次从桌面唤起APP没多大区别,只是有一点需要注意,那就是这种时候启动的Activity是有上一次的现场数据传递过得去的,因为上次在退到后台的时候,所有Activity界面的现场都是被保存了,并且传递到AMS中去的,那么这次的恢复启动就会将这些数据返回给ActivityThread,再来仔细看一下performLaunchActivity里面关于恢复的特殊处理代码:
private Activity performLaunchActivity(ActivityClientRecord r, Intent customIntent) {
ActivityInfo aInfo = r.activityInfo;
Activity activity = null;
try {
java.lang.ClassLoader cl = r.packageInfo.getClassLoader();
activity = mInstrumentation.newActivity(
cl, component.getClassName(), r.intent);
StrictMode.incrementExpectedActivityCount(activity.getClass());
r.intent.setExtrasClassLoader(cl);
if (r.state != null) {
r.state.setClassLoader(cl);
}
} catch (Exception e) {
...
}
try {
Application app = r.packageInfo.makeApplication(false, mInstrumentation);
...
关键点 1
mInstrumentation.callActivityOnCreate(activity, r.state);
...
r.activity = activity;
r.stopped = true;
if (!r.activity.mFinished) {
activity.performStart();
r.stopped = false;
}
关键点 1
if (!r.activity.mFinished) {
if (r.state != null) {
mInstrumentation.callActivityOnRestoreInstanceState(activity, r.state);
}
}
if (!r.activity.mFinished) {
activity.mCalled = false;
mInstrumentation.callActivityOnPostCreate(activity, r.state);
...
}
看一下关键点1跟2,先看关键点1,mInstrumentation.callActivityOnCreate会回调Actiivyt的onCreate,这个函数里面其实主要针对FragmentActivity做一些Fragment恢复的工作,ActivityClientRecord中的r.state是AMS传给APP用来恢复现场的,正常启动的时候,这些都是null。再来看关键点2 ,在r.state != null非空的时候执行mInstrumentation.callActivityOnRestoreInstanceState,这个函数默认主要就是针对Window做一些恢复工作,比如ViewPager恢复之前的显示位置等,也可以用来恢复用户保存数据。
Application没有被后台杀死
打开开发者模式”不保留活动“,就是这种场景,在上面的分析中,知道,AMS主动异常杀死Activity的时候,将AcitivityRecord的app字段置空,因此resumeTopActivityLocked同整个APP被杀死不同,会走下面的分支
final boolean resumeTopActivityLocked(ActivityRecord prev, Bundle options) {
...
if (next.app != null && next.app.thread != null) {
...
} else {
关键点 1 只是重启Activity,可见这里其实是知道的,进程并没死,
// Whoops, need to restart this activity!
startSpecificActivityLocked(next, true, true);
}
return true;
}
虽然不太一样,但是同样走startSpecificActivityLocked流程,只是不新建APP进程,其余的都是一样的,不再讲解。
主动清除最近任务跟异常杀死的区别:ActivityStack是否正常清除
恢复的时候,为什么是倒序恢复:因为这是ActivityStack中的HistoryRecord中栈的顺序,严格按照AMS端来
一句话概括Android后台杀死恢复原理:Application进程被Kill,但现场被AMS 保存,AMS能根据保存恢复Application现场
LowMemoryKiller原理
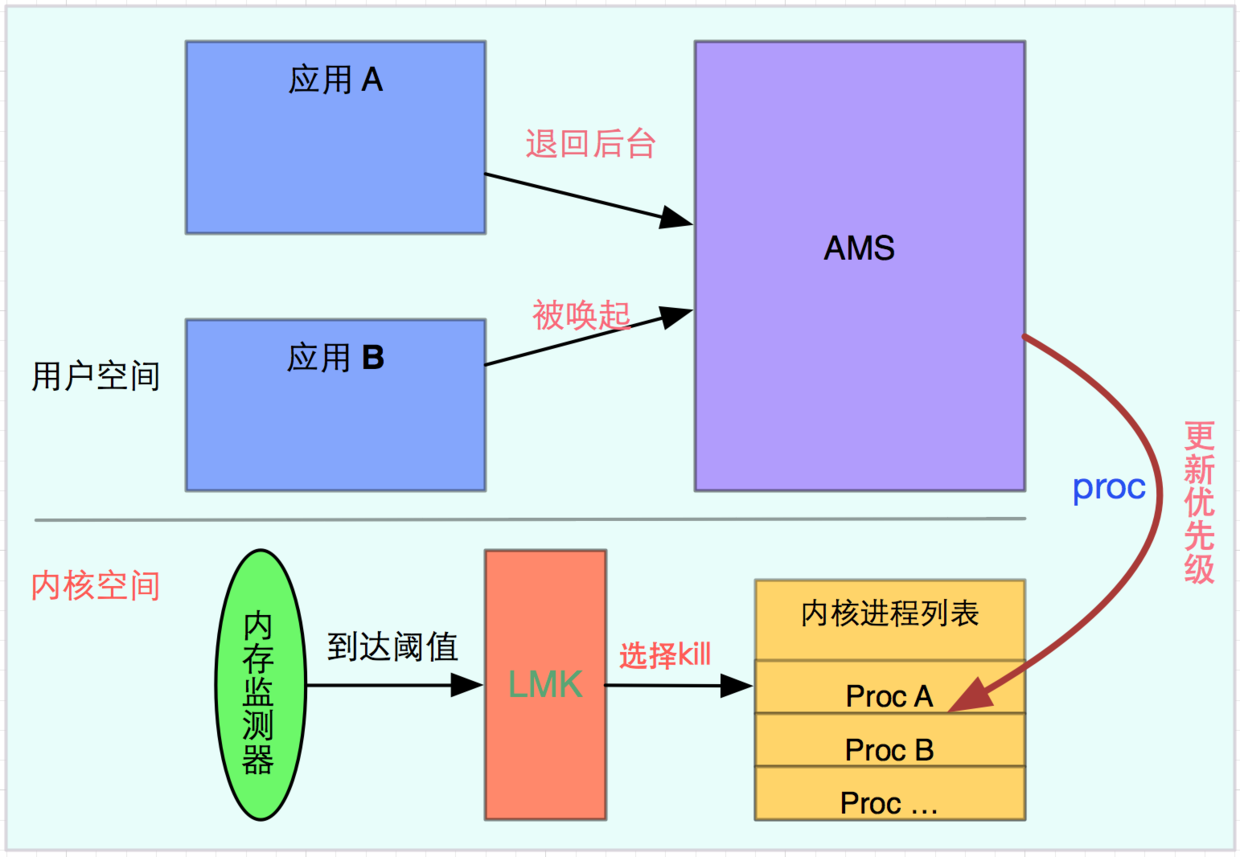
LowMemoryKiller(低内存杀手)是Andorid基于oomKiller原理所扩展的一个多层次oomKiller,OOMkiller(Out Of Memory Killer)是在Linux系统无法分配新内存的时候,选择性杀掉进程,到oom的时候,系统可能已经不太稳定,而LowMemoryKiller是一种根据内存阈值级别触发的内存回收的机制,在系统可用内存较低时,就会选择性杀死进程的策略,相对OOMKiller,更加灵活。
- 进程优先级定义:只有有了优先级,才能决定先杀谁,后杀谁
- 进程优先级的动态管理:一个进程的优先级不应该是固定不变的,需要根据其变动而动态变化,比如前台进程切换到后台优先级肯定要降低
- 进程杀死的时机,什么时候需要挑一个,或者挑多个进程杀死
- 如何杀死
Android底层采用的是Linux内核,其进程管理都是基于Linux内核,LowMemoryKiller也相应的放在内核模块,这也意味着用户空间对于后台杀死不可见,就像AMS完全不知道一个APP是否被后台杀死,只有在AMS唤醒APP的时候,才知道APP是否被LowMemoryKiller杀死过。其实LowmemoryKiller的原理是很清晰的,先看一下整体流程图,再分步分析:
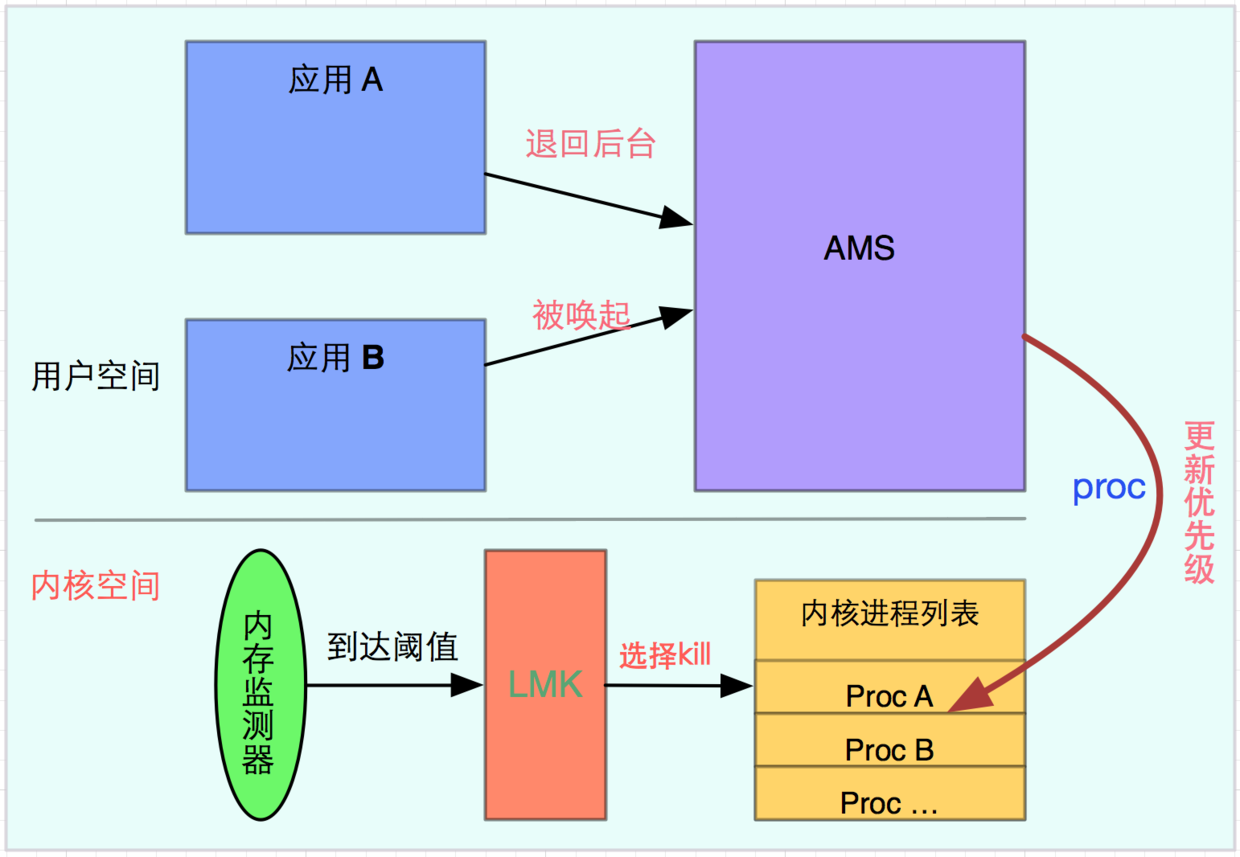
先记住两点 :
- LowMemoryKiller是被动杀死进程
- Android应用通过AMS,利用proc文件系统更新进程信息
Android应用进程优先级及oomAdj
Android会尽可能长时间地保持应用存活,但为了新建或运行更重要的进程,可能需要移除旧进程来回收内存,在选择要Kill的进程的时候,系统会根据进程的运行状态作出评估,权衡进程的“重要性“,其权衡的依据主要是四大组件。如果需要缩减内存,系统会首先消除重要性最低的进程,然后是重要性略逊的进程,依此类推,以回收系统资源。在Android中,应用进程划分5级(摘自Google文档):Android中APP的重要性层次一共5级:
- 前台进程(Foreground process)
- 可见进程(Visible process)
- 服务进程(Service process)
- 后台进程(Background process)
- 空进程(Empty process)
前台进程
用户当前操作所必需的进程。如果一个进程满足以下任一条件,即视为前台进程:
- 包含正在交互的Activity(resumed
- 包含绑定到正在交互的Activity的Service
- 包含正在“前台”运行的Service(服务已调用startForeground())
- 包含正执行一个生命周期回调的Service(onCreate()、onStart() 或 onDestroy())
- 包含一个正执行其onReceive()方法的BroadcastReceiver
通常,在任意给定时间前台进程都为数不多。只有在内存不足以支持它们同时继续运行这一万不得已的情况下,系统才会终止它们。 此时,设备往往已达到内存分页状态,因此需要终止一些前台进程来确保用户界面正常响应。
可见进程
没有任何前台组件、但仍会影响用户在屏幕上所见内容的进程。 如果一个进程满足以下任一条件,即视为可见进程:
- 包含不在前台、但仍对用户可见的 Activity(已调用其 onPause() 方法)。例如,如果前台 Activity 启动了一个对话框,允许在其后显示上一Activity,则有可能会发生这种情况。
- 包含绑定到可见(或前台)Activity 的 Service。
可见进程被视为是极其重要的进程,除非为了维持所有前台进程同时运行而必须终止,否则系统不会终止这些进程。
服务进程
正在运行已使用 startService() 方法启动的服务且不属于上述两个更高类别进程的进程。尽管服务进程与用户所见内容没有直接关联,但是它们通常在执行一些用户关心的操作(例如,在后台播放音乐或从网络下载数据)。因此,除非内存不足以维持所有前台进程和可见进程同时运行,否则系统会让服务进程保持运行状态。
后台进程
包含目前对用户不可见的 Activity 的进程(已调用 Activity 的 onStop() 方法)。这些进程对用户体验没有直接影响,系统可能随时终止它们,以回收内存供前台进程、可见进程或服务进程使用。 通常会有很多后台进程在运行,因此它们会保存在 LRU (最近最少使用)列表中,以确保包含用户最近查看的 Activity 的进程最后一个被终止。如果某个 Activity 正确实现了生命周期方法,并保存了其当前状态,则终止其进程不会对用户体验产生明显影响,因为当用户导航回该 Activity 时,Activity会恢复其所有可见状态。
空进程
不含任何活动应用组件的进程。保留这种进程的的唯一目的是用作缓存,以缩短下次在其中运行组件所需的启动时间,这就是所谓**热启动 **。为了使系统资源在进程缓存和底层内核缓存之间保持平衡,系统往往会终止这些进程。
根据进程中当前活动组件的重要程度,Android会将进程评定为它可能达到的最高级别。例如,如果某进程托管着服务和可见 Activity,则会将此进程评定为可见进程,而不是服务进程。此外,一个进程的级别可能会因其他进程对它的依赖而有所提高,即服务于另一进程的进程其级别永远不会低于其所服务的进程。 例如,如果进程 A 中的内容提供程序为进程 B 中的客户端提供服务,或者如果进程 A 中的服务绑定到进程 B 中的组件,则进程 A 始终被视为至少与进程B同样重要。
通过Google文档,对不同进程的重要程度有了一个直观的认识,下面看一下量化到内存是什么样的呈现形式,这里针对不同的重要程度,做了进一步的细分,定义了重要级别ADJ,并将优先级存储到内核空间的进程结构体中去,供LowmemoryKiller参考:
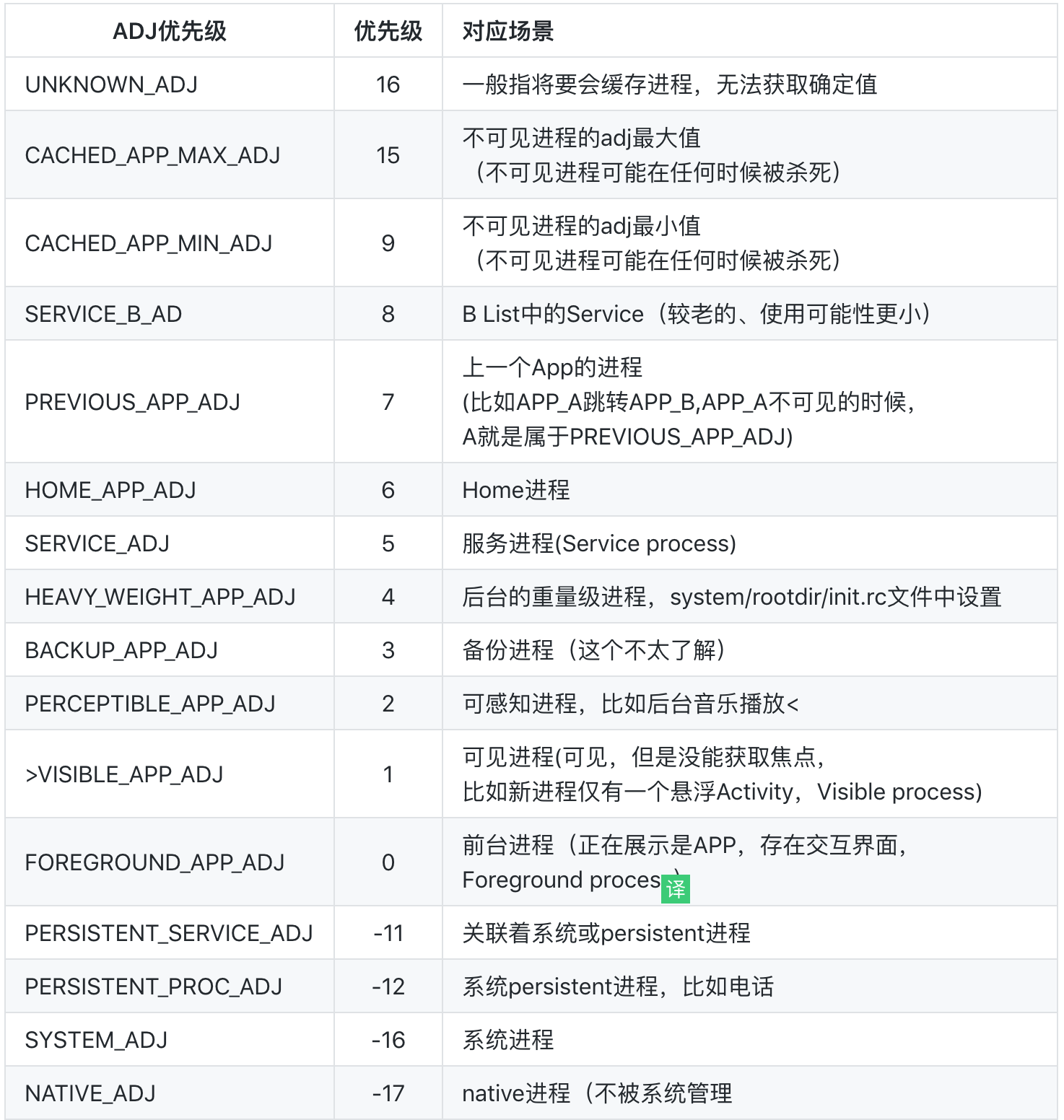
以上介绍的目的只有一点:Android的应用进程是有优先级的,它的优先级跟当前是否存在展示界面,以及是否能被用户感知有关,越是被用户感知的的应用优先级越高(系统进程不考虑)。
Android应用的优先级是如何更新的
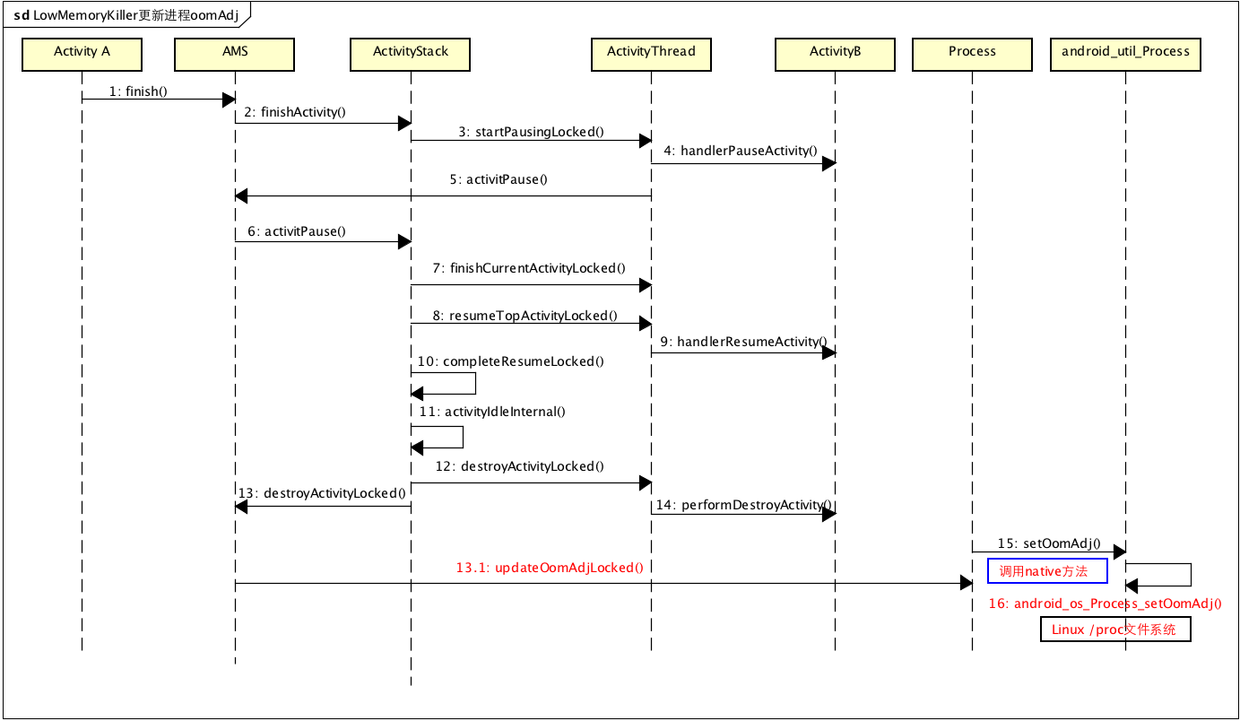
APP中很多操作都可能会影响进程列表的优先级,比如退到后台、移到前台等,都会潜在的影响进程的优先级,我们知道Lowmemorykiller是通过遍历内核的进程结构体队列,选择优先级低的杀死,那么APP操作是如何写入到内核空间的呢?Linxu有用户间跟内核空间的区分,无论是APP还是系统服务,都是运行在用户空间,严格说用户控件的操作是无法直接影响内核空间的,更不用说更改进程的优先级。其实这里是通过了Linux中的一个proc文件体统,proc文件系统可以简单的看多是内核空间映射成用户可以操作的文件系统,当然不是所有进程都有权利操作,通过proc文件系统,用户空间的进程就能够修改内核空间的数据,比如修改进程的优先级,在Android家族,5.0之前的系统是AMS进程直接修改的,5.0之后,是修改优先级的操作被封装成了一个独立的服务-lmkd,lmkd服务位于用户空间,其作用层次同AMS、WMS类似,就是一个普通的系统服务。我们先看一下5.0之前的代码,这里仍然用4.3的源码看一下,模拟一个场景,APP只有一个Activity,我们主动finish掉这个Activity,APP就回到了后台,这里要记住,虽然没有可用的Activity,但是APP本身是没哟死掉的,这就是所谓的热启动,先看下大体的流程:
ActivityManagerService
public final boolean finishActivity(IBinder token, int resultCode, Intent resultData) {
...
synchronized(this) {
final long origId = Binder.clearCallingIdentity();
boolean res = mMainStack.requestFinishActivityLocked(token, resultCode,
resultData, "app-request", true);
...
}
}
一开始的流程跟startActivity类似,首先是先暂停当前resume的Activity,其实也就是自己,
final boolean finishActivityLocked(ActivityRecord r, int index, int resultCode,
Intent resultData, String reason, boolean immediate, boolean oomAdj) {
...
if (mPausingActivity == null) {
if (DEBUG_PAUSE) Slog.v(TAG, "Finish needs to pause: " + r);
if (DEBUG_USER_LEAVING) Slog.v(TAG, "finish() => pause with userLeaving=false");
startPausingLocked(false, false);
}
...
}
pause掉当前Activity之后,还需要唤醒上一个Activity,如果当前APP的Activity栈里应经空了,就回退到上一个应用或者桌面程序,唤醒流程就不在讲解了,因为在AMS恢复异常杀死APP的那篇已经说过,这里要说的是唤醒之后对这个即将退回后台的APP的操作,这里注意与startActivity不同的地方,看下面代码:
ActivityStack
private final void completePauseLocked() {
ActivityRecord prev = mPausingActivity;
if (prev != null) {
if (prev.finishing) {
1、 不同点
<!--主动finish的时候,走的是这个分支,状态变换的细节请自己查询代码-->
prev = finishCurrentActivityLocked(prev, FINISH_AFTER_VISIBLE, false);
}
...
2、相同点
if (!mService.isSleeping()) {
resumeTopActivityLocked(prev);
}
看一下上面的两个关键点1跟2,1是同startActivity的completePauseLocked不同的地方,主动finish的prev.finishing是为true的,因此会执行finishCurrentActivityLocked分支,将当前pause的Activity加到mStoppingActivities队列中去,并且唤醒下一个需要走到到前台的Activity,唤醒后,会继续执行stop:
private final ActivityRecord finishCurrentActivityLocked(ActivityRecord r,
int index, int mode, boolean oomAdj) {
if (mode == FINISH_AFTER_VISIBLE && r.nowVisible) {
if (!mStoppingActivities.contains(r)) {
mStoppingActivities.add(r);
...
}
....
return r;
}
...
}
让我们再回到resumeTopActivityLocked继续看,resume之后会回调completeResumeLocked函数,继续执行stop,这个函数通过向Handler发送IDLE_TIMEOUT_MSG消息来回调activityIdleInternal函数,最终执行destroyActivityLocked销毁ActivityRecord,
final boolean resumeTopActivityLocked(ActivityRecord prev, Bundle options) {
...
if (next.app != null && next.app.thread != null) { ...
try {
。。。
next.app.thread.scheduleResumeActivity(next.appToken,
mService.isNextTransitionForward());
..。
try {
next.visible = true;
completeResumeLocked(next);
}
....
}
在销毁Activity的时候,如果当前APP的Activity堆栈为空了,就说明当前Activity没有可见界面了,这个时候就需要动态更新这个APP的优先级,详细代码如下:
final boolean destroyActivityLocked(ActivityRecord r,
boolean removeFromApp, boolean oomAdj, String reason) {
...
if (hadApp) {
if (removeFromApp) {
// 这里动ProcessRecord里面删除,但是没从history删除
int idx = r.app.activities.indexOf(r);
if (idx >= 0) {
r.app.activities.remove(idx);
}
...
if (r.app.activities.size() == 0) {
// No longer have activities, so update oom adj.
mService.updateOomAdjLocked();
...
}
最终会调用AMS的updateOomAdjLocked函数去更新进程优先级,在4.3的源码里面,主要是通过Process类的setOomAdj函数来设置优先级:
ActivityManagerService
private final boolean updateOomAdjLocked(ProcessRecord app, int hiddenAdj,
int clientHiddenAdj, int emptyAdj, ProcessRecord TOP_APP, boolean doingAll) {
...
计算优先级
computeOomAdjLocked(app, hiddenAdj, clientHiddenAdj, emptyAdj, TOP_APP, false, doingAll);
。。。
<!--如果不相同,设置新的OomAdj-->
if (app.curAdj != app.setAdj) {
if (Process.setOomAdj(app.pid, app.curAdj)) {
...
}
Process中setOomAdj是一个native方法,原型在android_util_Process.cpp中
android_util_Process.cpp
jboolean android_os_Process_setOomAdj(JNIEnv* env, jobject clazz,
jint pid, jint adj)
{
#ifdef HAVE_OOM_ADJ
char text[64];
sprintf(text, "/proc/%d/oom_adj", pid);
int fd = open(text, O_WRONLY);
if (fd >= 0) {
sprintf(text, "%d", adj);
write(fd, text, strlen(text));
close(fd);
}
return true;
#endif
return false;
}
可以看到,在native代码里,就是通过proc文件系统修改内核信息,这里就是动态更新进程的优先级oomAdj,以上是针对Android4.3系统的分析,之后会看一下5.0之后的系统是如何实现的。下面是4.3更新oomAdj的流程图,注意红色的执行点:
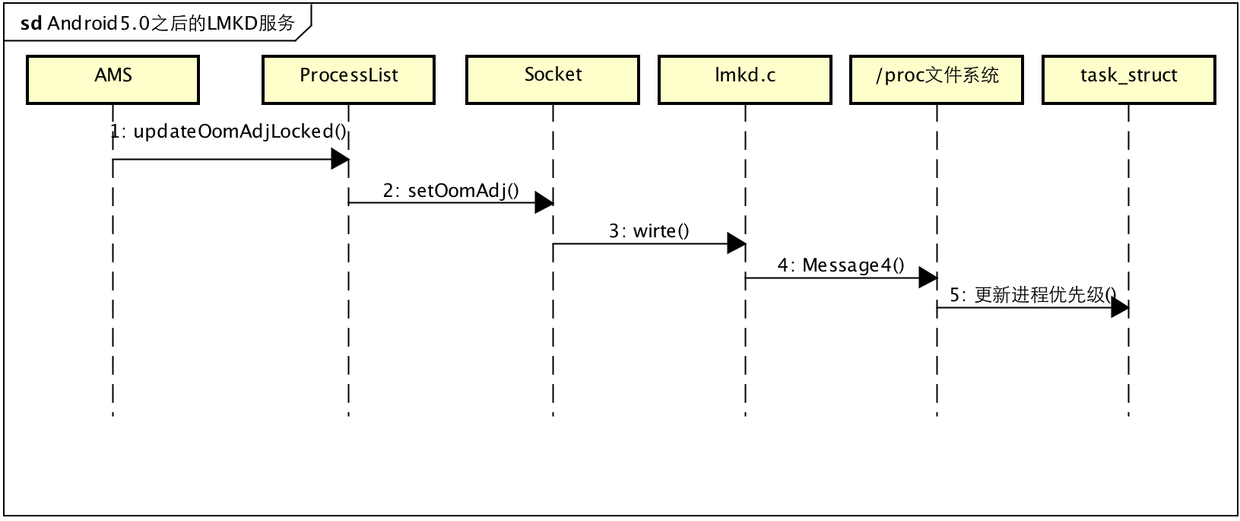
Android5.0之后框架层的实现:LMKD服务
Android5.0将设置进程优先级的入口封装成了一个独立的服务lmkd服务,AMS不再直接访问proc文件系统,而是通过lmkd服务来进行设置,从init.rc文件中看到服务的配置。
service lmkd /system/bin/lmkd
class core
critical
socket lmkd seqpacket 0660 system system
从配置中可以看出,该服务是通过socket与其他进行进程进行通信,其实就是AMS通过socket向lmkd服务发送请求,让lmkd去更新进程的优先级,lmkd收到请求后,会通过/proc文件系统去更新内核中的进程优先级。首先看一下5.0中这一块AMS有什么改变,其实大部分流程跟之前4.3源码类似,我们只看一下不同地方
ActivityManagerService
private final boolean updateOomAdjLocked(ProcessRecord app, int cachedAdj,
ProcessRecord TOP_APP, boolean doingAll, long now) {
...
computeOomAdjLocked(app, cachedAdj, TOP_APP, doingAll, now);
...
applyOomAdjLocked(app, doingAll, now, SystemClock.elapsedRealtime());
}
private final boolean applyOomAdjLocked(ProcessRecord app, boolean doingAll, long now,
long nowElapsed) {
boolean success = true;
if (app.curRawAdj != app.setRawAdj) {
app.setRawAdj = app.curRawAdj;
}
int changes = 0;
不同点1
if (app.curAdj != app.setAdj) {
ProcessList.setOomAdj(app.pid, app.info.uid, app.curAdj);
if (DEBUG_SWITCH || DEBUG_OOM_ADJ) Slog.v(TAG_OOM_ADJ,
"Set " + app.pid + " " + app.processName + " adj " + app.curAdj + ": "
+ app.adjType);
app.setAdj = app.curAdj;
app.verifiedAdj = ProcessList.INVALID_ADJ;
}
从上面的不同点1可以看出,5.0之后是通过ProcessList类去设置oomAdj,其实这里就是通过socket与LMKD服务进行通信,向lmkd服务传递给LMK_PROCPRIO命令去更新进程优先级:
public static final void setOomAdj(int pid, int uid, int amt) {
if (amt == UNKNOWN_ADJ)
return;
long start = SystemClock.elapsedRealtime();
ByteBuffer buf = ByteBuffer.allocate(4 * 4);
buf.putInt(LMK_PROCPRIO);
buf.putInt(pid);
buf.putInt(uid);
buf.putInt(amt);
writeLmkd(buf);
long now = SystemClock.elapsedRealtime();
}
private static void writeLmkd(ByteBuffer buf) {
for (int i = 0; i < 3; i++) {
if (sLmkdSocket == null) {
if (openLmkdSocket() == false) {
...
try {
sLmkdOutputStream.write(buf.array(), 0, buf.position());
return;
...
}
其实就是openLmkdSocket打开本地socket端口,并将优先级信息发送过去,那么lmkd服务端如何处理的呢,init.rc里配置的服务是在开机时启动的,来看看lmkd服务的入口:main函数
lmkd.c函数
int main(int argc __unused, char **argv __unused) {
struct sched_param param = {
.sched_priority = 1,
};
mlockall(MCL_FUTURE);
sched_setscheduler(0, SCHED_FIFO, ¶m);
if (!init())
mainloop();
ALOGI("exiting");
return 0;
}
很简单,打开一个端口,并通过mainloop监听socket,如果有请求到来,就解析命令并执行,刚才传入的LMK_PROCPRIO命令对应的操作就是cmd_procprio,用来更新oomAdj,其更新新机制还是通过proc文件系统,不信?看下面代码:
static void cmd_procprio(int pid, int uid, int oomadj) {
struct proc *procp;
。。。
还是利用/proc文件系统进行更新
snprintf(path, sizeof(path), "/proc/%d/oom_score_adj", pid);
snprintf(val, sizeof(val), "%d", lowmem_oom_adj_to_oom_score_adj(oomadj));
writefilestring(path, val);
。。。
}
简单的流程图如下,同4.3不同的地方
LomemoryKiller内核部分:如何杀死
LomemoryKiller属于一个内核驱动模块,主要功能是:在系统内存不足的时候扫描进程队列,找到低优先级(也许说性价比低更合适)的进程并杀死,以达到释放内存的目的。对于驱动程序,入口是__init函数,先看一下这个驱动模块的入口:
static int __init lowmem_init(void)
{
register_shrinker(&lowmem_shrinker);
return 0;
}
可以看到在init的时候,LomemoryKiller将自己的lowmem_shrinker入口注册到系统的内存检测模块去,作用就是在内存不足的时候可以被回调,register_shrinker函数是一属于另一个内存管理模块的函数,如果一定要根下去的话,可以看一下它的定义,其实就是加到一个回调函数队列中去:
void register_shrinker(struct shrinker *shrinker)
{
shrinker->nr = 0;
down_write(&shrinker_rwsem);
list_add_tail(&shrinker->list, &shrinker_list);
up_write(&shrinker_rwsem);
}
最后,看一下,当内存不足触发回调的时候,LomemoryKiller是如何找到低优先级进程,并杀死的:入口函数就是init时候注册的lowmem_shrink函数(4.3源码,后面的都有微调但原理大概类似):
static int lowmem_shrink(int nr_to_scan, gfp_t gfp_mask)
{
struct task_struct *p;
。。。
关键点1 找到当前的内存对应的阈值
for(i = 0; i < array_size; i++) {
if (other_free < lowmem_minfree[i] &&
other_file < lowmem_minfree[i]) {
min_adj = lowmem_adj[i];
break;
}
}
。。。
关键点2 找到优先级低于这个阈值的进程,并杀死
read_lock(&tasklist_lock);
for_each_process(p) {
if (p->oomkilladj < min_adj || !p->mm)
continue;
tasksize = get_mm_rss(p->mm);
if (tasksize <= 0)
continue;
if (selected) {
if (p->oomkilladj < selected->oomkilladj)
continue;
if (p->oomkilladj == selected->oomkilladj &&
tasksize <= selected_tasksize)
continue;
}
selected = p;
selected_tasksize = tasksize;
}
if(selected != NULL) {
force_sig(SIGKILL, selected);
rem -= selected_tasksize;
}
lowmem_print(4, "lowmem_shrink %d, %x, return %d\n", nr_to_scan, gfp_mask, rem);
read_unlock(&tasklist_lock);
return rem;
}
先看关键点1:其实就是确定当前低内存对应的阈值;关键点2 :找到比该阈值优先级低或者相等,并且内存占用较多的进程(tasksize = get_mm_rss(p->mm)其实就是获取内存占用)),将其杀死。如何杀死的呢?很直接,通过Linux的中的信号量,发送SIGKILL信号直接将进程杀死。到这就分析完了LomemoryKiller内核部分如何工作的。其实很简单,一句话:被动扫描,找到低优先级的进程,杀死。
- Android APP进程是有优先级的的,与进程是否被用户感知有直接关系
- APP切换等活动都可能造成进程优先级的变化,都是利用AMS,并通过proc文件设置到内核的
- LowmemoryKiller运行在内核,在内存需要缩减的时候,会选择低优先级的进程杀死
Binder讣告原理
Binder是一个类似于C/S架构的通信框架,有时候客户端可能想知道服务端的状态,比如服务端如果挂了,客户端希望能及时的被通知到,而不是等到再起请求服务端的时候才知道,这种场景其实在互为C/S的时候最常用,比如AMS与APP,当APP端进程异常退出的时候,AMS希望能及时知道,不仅仅是清理APP端在AMS中的一些信息,比如ActivityRecord,ServiceRecord等,有时候可能还需要及时恢复一些自启动的Service。Binder实现了一套”死亡讣告”的功能,即:服务端挂了,或者正常退出,Binder驱动会向客户端发送一份讣告,告诉客户端Binder服务挂了。
Binder“讣告”有点采用了类似观察者模式,因此,首先需要将Observer注册到目标对象中,其实就是将Client注册到Binder驱动,将来Binder服务挂掉时候,就能通过驱动去发送。Binder“讣告”发送的入口只有一个:在释放binder设备的时候,在在操作系统中,无论进程是正常退出还是异常退出,进程所申请的所有资源都会被回收,包括打开的一些设备文件,如Binder字符设备等。在释放的时候,就会调用相应的release函数,“讣告”也就是在这个时候去发送的。因此Binder讣告其实就仅仅包括两部分:注册与通知。
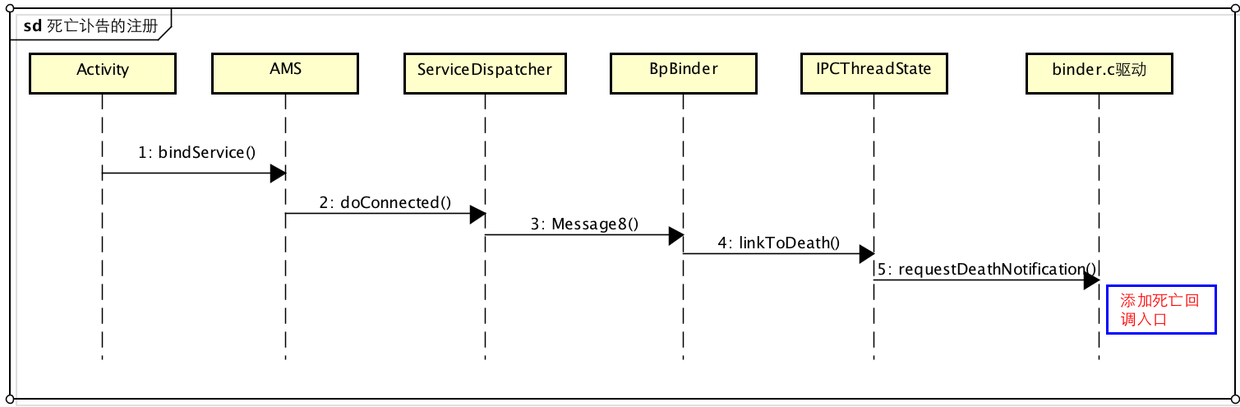
Binder”讣告”的注册入口
这里拿bindService为例子进行分析,其他场景类似,bindService会首先请求AMS去启动Service,Server端进程在启动时,会调用函数open来打开设备文件/dev/binder,同时将Binder服务实体回传给AMS,AMS再将Binder实体的引用句柄通过Binder通信传递给Client,也就是在AMS回传给Client的时候,会向Binder驱动注册。其实这也比较好理解,获得了服务端的代理,就应该关心服务端的死活 。当AMS利用IServiceConnection这条binder通信线路为Client回传Binder服务实体的时候,InnerConnection就会间接的将死亡回调注册到内核:
private static class InnerConnection extends IServiceConnection.Stub {
final WeakReference<LoadedApk.ServiceDispatcher> mDispatcher;
public void connected(ComponentName name, IBinder service) throws RemoteException {
LoadedApk.ServiceDispatcher sd = mDispatcher.get();
if (sd != null) {
sd.connected(name, service);
}
}
}
ServiceDispatcher函数进一步调用 doConnected
public void doConnected(ComponentName name, IBinder service) {
ServiceDispatcher.ConnectionInfo old;
ServiceDispatcher.ConnectionInfo info;
synchronized (this) {
if (service != null) {
mDied = false;
info = new ConnectionInfo();
info.binder = service;
info.deathMonitor = new DeathMonitor(name, service);
try {
<!-- 关键点点1-->
service.linkToDeath(info.deathMonitor, 0);
}
}
看关键点点1 ,这里的IBinder service其实是AMS回传的服务代理BinderProxy,linkToDeath是一个Native函数,会进一步调用BpBinde的linkToDeath:
status_t BpBinder::linkToDeath(
const sp<DeathRecipient>& recipient, void* cookie, uint32_t flags){
<!--关键点1-->
IPCThreadState* self = IPCThreadState::self();
self->requestDeathNotification(mHandle, this);
self->flushCommands();
}
最终调用IPCThreadState的requestDeathNotification(mHandle, this)向内核发送BC_REQUEST_DEATH_NOTIFICATION请求:
status_t IPCThreadState::requestDeathNotification(int32_t handle, BpBinder* proxy)
{
mOut.writeInt32(BC_REQUEST_DEATH_NOTIFICATION);
mOut.writeInt32((int32_t)handle);
mOut.writeInt32((int32_t)proxy);
return NO_ERROR;
}
最后来看一下在内核中,是怎么登记注册的:
int
binder_thread_write(struct binder_proc *proc, struct binder_thread *thread,
void __user *buffer, int size, signed long *consumed)
{
...
case BC_REQUEST_DEATH_NOTIFICATION:
case BC_CLEAR_DEATH_NOTIFICATION: {
...
ref = binder_get_ref(proc, target);
if (cmd == BC_REQUEST_DEATH_NOTIFICATION) {
...关键点1
death = kzalloc(sizeof(*death), GFP_KERNEL);
binder_stats.obj_created[BINDER_STAT_DEATH]++;
INIT_LIST_HEAD(&death->work.entry);
death->cookie = cookie;
ref->death = death;
if (ref->node->proc == NULL) {
ref->death->work.type = BINDER_WORK_DEAD_BINDER;
if (thread->looper & (BINDER_LOOPER_STATE_REGISTERED | BINDER_LOOPER_STATE_ENTERED)) {
list_add_tail(&ref->death->work.entry, &thread->todo);
} else {
list_add_tail(&ref->death->work.entry, &proc->todo);
wake_up_interruptible(&proc->wait);
}
}
}
}
看关键点1 ,其实就是为Client新建binder_ref_death对象,并赋值给binder_ref。在binder驱动中,binder_node节点会记录所有binder_ref,当binder_node所在的进程挂掉后,驱动就能根据这个全局binder_ref列表找到所有Client的binder_ref,并对于设置了死亡回调的Client发送“讣告”,这是因为在binder_get_ref_for_node向Client插入binder_ref的时候,也会插入binder_node的binder_ref列表。
static struct binder_ref *
binder_get_ref_for_node(struct binder_proc *proc, struct binder_node *node)
{
struct rb_node *n;
struct rb_node **p = &proc->refs_by_node.rb_node;
struct rb_node *parent = NULL;
struct binder_ref *ref, *new_ref;
if (node) {
hlist_add_head(&new_ref->node_entry, &node->refs);
}
return new_ref;
}
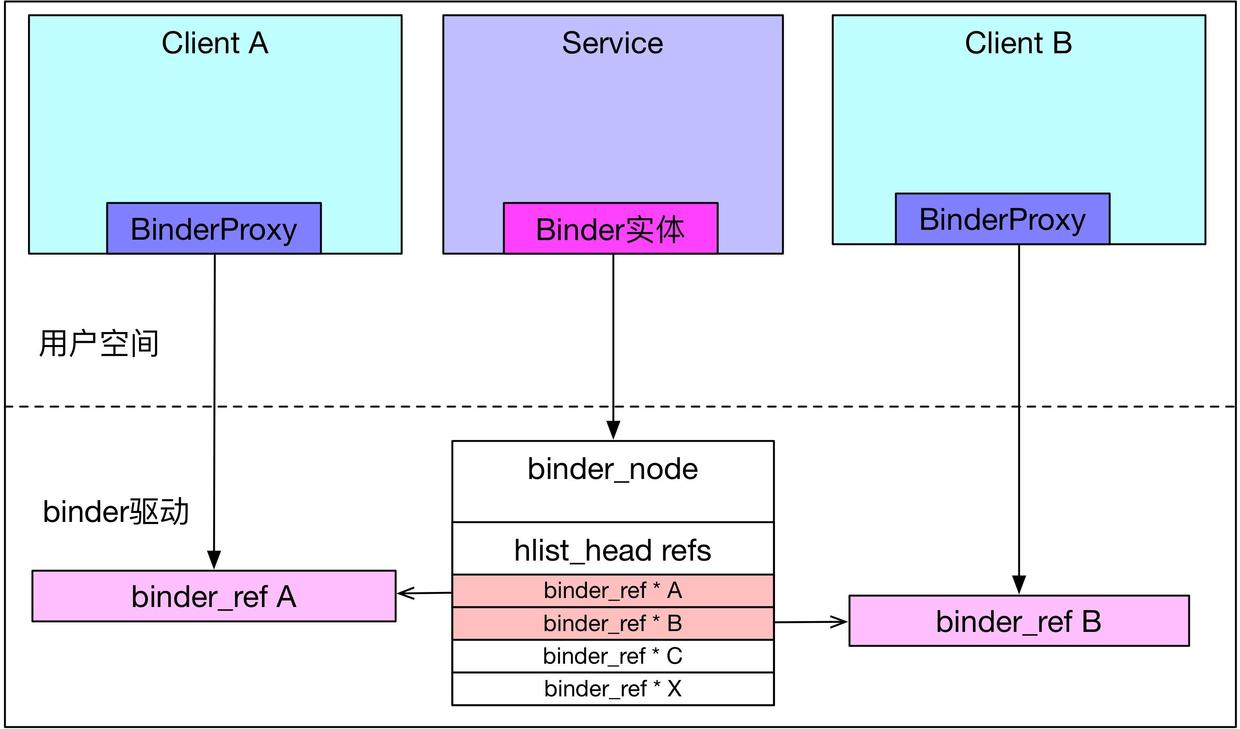
如此,死亡回调入口就被注册到binder内核驱动,之后,等到进程结束要释放binder的时候,就会触发死亡回调。
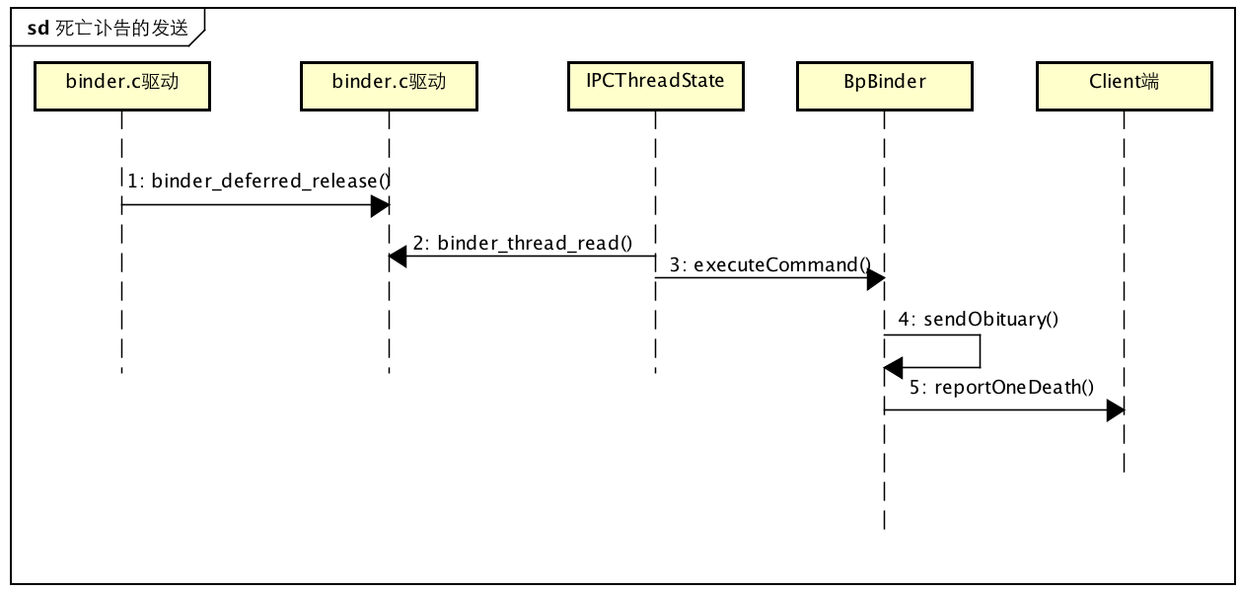
死亡通知的发送
在调用binder_realease函数来释放相应资源的时候,最终会调用binder_deferred_release函数。该函数会遍历该binder_proc内所有的binder_node节点,并向注册了死亡回调的Client发送讣告,
static void binder_deferred_release(struct binder_proc *proc)
{ ....
if (ref->death) {
death++;
if (list_empty(&ref->death->work.entry)) {
ref->death->work.type = BINDER_WORK_DEAD_BINDER;
list_add_tail(&ref->death->work.entry, &ref->proc->todo);
// 插入到binder_ref请求进程的binder线程等待队列????? 天然支持binder通信吗?
// 什么时候,需要死亡回调,自己也是binder服务?
wake_up_interruptible(&ref->proc->wait);
}
...
}
死亡讣告被直接发送到Client端的binder进程todo队列上,这里似乎也只对于互为C/S通信的场景有用,当Client的binder线程被唤醒后,就会针对“讣告”做一些清理及善后工作:
static int
binder_thread_read(struct binder_proc *proc, struct binder_thread *thread,
void __user *buffer, int size, signed long *consumed, int non_block)
{
case BINDER_WORK_DEAD_BINDER:
case BINDER_WORK_DEAD_BINDER_AND_CLEAR:
case BINDER_WORK_CLEAR_DEATH_NOTIFICATION: {
struct binder_ref_death *death = container_of(w, struct binder_ref_death, work);
uint32_t cmd;
if (w->type == BINDER_WORK_CLEAR_DEATH_NOTIFICATION)
cmd = BR_CLEAR_DEATH_NOTIFICATION_DONE;
else
cmd = BR_DEAD_BINDER;
...
}
这里会向用户空间写入一个BR_DEAD_BINDER命令,并返回talkWithDriver函数,返回后,IPCThreadState会继续执行executeCommand,
status_t IPCThreadState::executeCommand(int32_t cmd)
{
// 死亡讣告
case BR_DEAD_BINDER:
{
BpBinder *proxy = (BpBinder*)mIn.readInt32();
<!--关键点1 -->
proxy->sendObituary();
mOut.writeInt32(BC_DEAD_BINDER_DONE);
mOut.writeInt32((int32_t)proxy);
} break; }
看关键点1,Obituary直译过来就是讣告,其实就是利用BpBinder发送讣告,待讣告处理结束后,再向Binder驱动发送确认通知。
void BpBinder::sendObituary()
{
ALOGV("Sending obituary for proxy %p handle %d, mObitsSent=%s\n",
this, mHandle, mObitsSent ? "true" : "false");
mAlive = 0;
if (mObitsSent) return;
mLock.lock();
Vector<Obituary>* obits = mObituaries;
if(obits != NULL) {
<!--关键点1-->
IPCThreadState* self = IPCThreadState::self();
self->clearDeathNotification(mHandle, this);
self->flushCommands();
mObituaries = NULL;
}
mObitsSent = 1;
mLock.unlock();
if (obits != NULL) {
const size_t N = obits->size();
for (size_t i=0; i<N; i++) {
reportOneDeath(obits->itemAt(i));
}
delete obits;
}
}
看关键点1,这里跟注册相对应,将自己从观察者列表中清除,之后再上报
void BpBinder::reportOneDeath(const Obituary& obit)
{
sp<DeathRecipient> recipient = obit.recipient.promote();
ALOGV("Reporting death to recipient: %p\n", recipient.get());
if (recipient == NULL) return;
recipient->binderDied(this);
}
进而调用上层DeathRecipient的回调,做一些清理之类的逻辑。以AMS为例,其binderDied函数就挺复杂,包括了一些数据的清理,甚至还有进程的重建等,不做讨论。