

需求背景
- 业务系统需要预览报告(如产品周报,体检报告等)并生成pdf格式供用户下载,或者定期发送给指定用户
- 报告格式相对固定,由文本,图片和图表组成,基本与前端页面保持一致
解决方案
需求分为两步:报告预览和报告生成。
- 报告预览在前端进行展示,可使用前端技术,如React/Vue等技术栈对其进行还原,数据从服务端获取。
- 报告生成需要对第一步生成的HTML进行PDF的转换生成,HTML2PDF的方式又分为两种:
- 基于canvas的客户端生成方案
- 基于nodejs + puppeteer的服务端生成方案
一个完整的案例
下面以一个体检报告的案例进行这两种方案的说明: 体检报告展示形式如下,格式相对固定,分为四个页面:个人信息页,建议页,原理页,个人信息页与建议页数据来源于服务器。
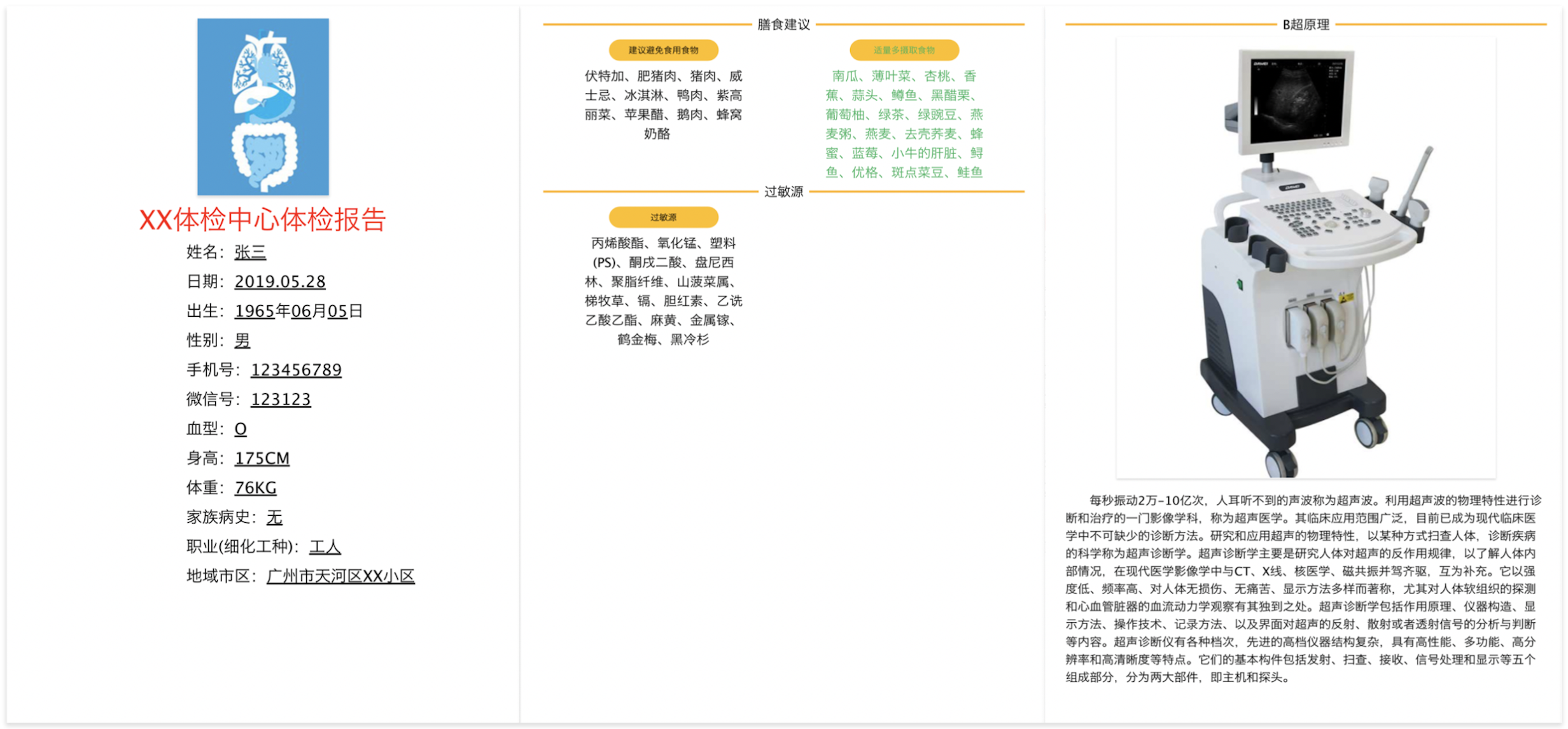
基于canvas的客户端生成方案
canvas是HTML5标准中新增的元素,可用于通过使用JS的脚本来绘制图形。canvas提供了toDataURL/toBlob方法,用于把canvas中的内容转换为图片,API文档如下(来源于MDN):

由于HTML文档再浏览器中是以DOM树的形式存在,所以我们可以通过三步完成HTML到PDF的转换:
- 将DOM树转换为canvas对象,可使用html2canvas完成
- 将canvas转换为图片,可使用canvas.toDataURL完成
- 将图片转换为PDF,可使用jsPDF完成
完整代码实现:github.com/simonwoo/di…
截图如下,点击下载按钮可进行pdf生产:
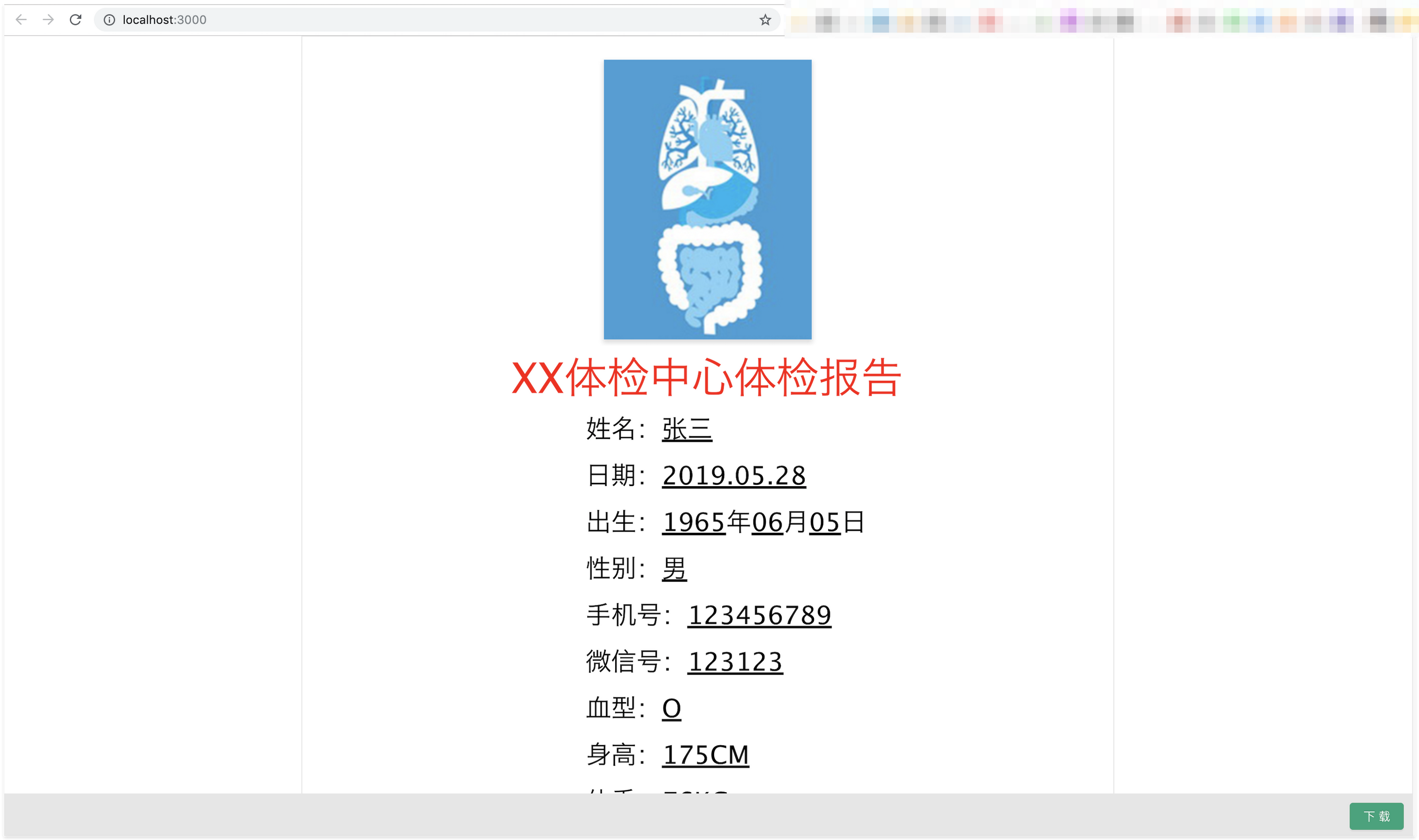
该方案完全基于客户端的方式生成,不需要服务器进行支持。在使用该方案的过程中,发现了一些问题:
- 生产的PDF比较模糊,质量不高
- 如果HTML中有外链图片,无法生成
- 由于第一步是通过DOM去生成canvas,所以针对特别长的报告,DOM尚未加载完便点击下载时,会造成报告生成问题
- 因为是客户端方案,所以需要用户主动触发生成,但对于一些定期发送给用户的报告,该方案无法使用
基于nodejs + puppeteer的服务端生成方案
puppeteer是google推出的headless浏览器,即没有图形界面的浏览器,但又可以实现普通浏览器HTML/JS/CSS的渲染,以及其他基本浏览器功能。你可以理解为一个没有界面的Chrome浏览器。主要有以下几种使用场景:
- 生成页面的截图和PDF
- 抓取SPA并生成预先呈现的内容(即“SSR”)
- 爬虫,从网站抓取你需要的内容
- 自动化测试,自动表单提交,UI测试,键盘输入等
- 创建一个最新的自动化测试环境。使用最新的JavaScript和浏览器功能,直接在最新版本的Chrome中运行测试 通过理解puppeteer的功能,我们可以开启一个实例去渲染HTML报告,然后再利用其提供的转换PDF功能进行PDF的生成。
两个重要的API:
- page.goto(url, [options]) - 打开指定url的文件,可以是本地文件(file://)也可以是网络文件(http://)
- page.pdf([options]) - 转换页面成PDF文件
puppeteer使用一个小例子,将百度网页转换为pdf:
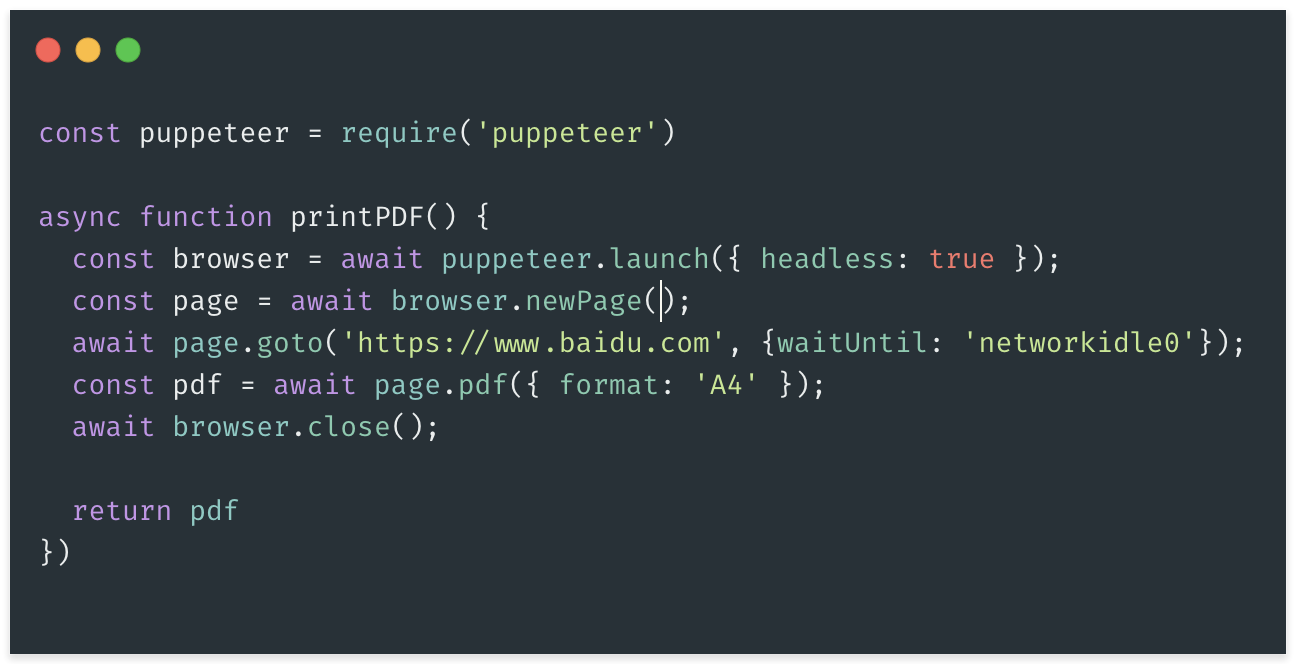
完整代码如下:
项目启动流程如下:
- 进入到webapp目录,使用npm install和npm run start启动前端服务器,地址为:localhost:3000
- 进入到server目录,使用npm install和npm run dev启动node服务器,地址为:localhost:7001
整个服务架构如下:
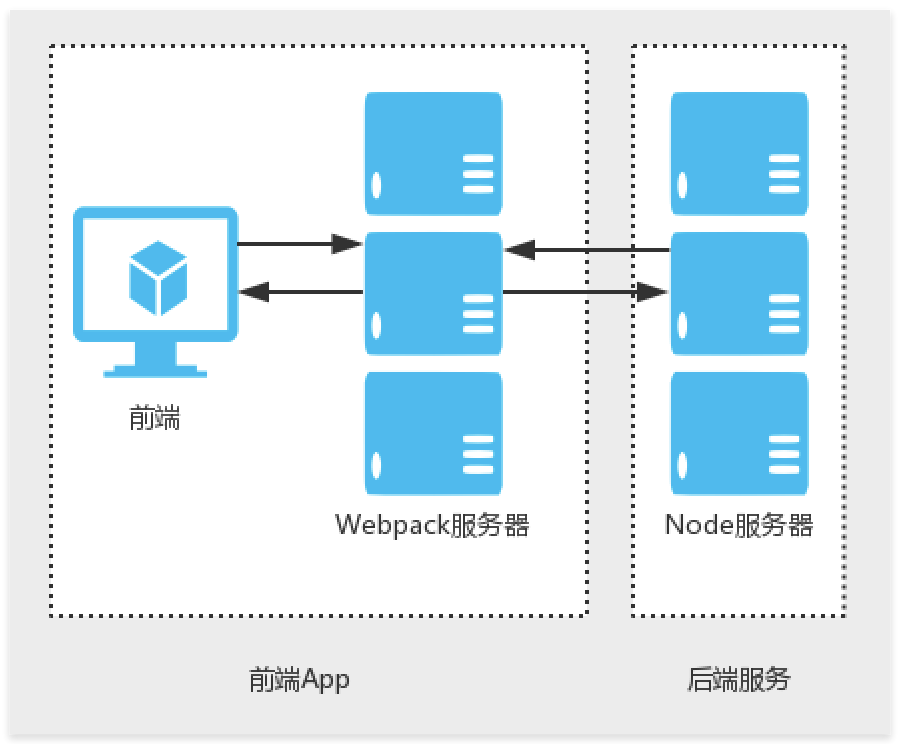
node服务器通过路由增加一个pdf生成的controller,该controller通过启动puppeteer实例去加载localhost:3000的页面并生成pdf。直接在浏览器中通过http://localhost:7001/pdf即可访问到生成的pdf.
在实际环境中,前端页面可部署在nginx服务器上或者直接放在Node服务器上,puppeteer也支持使用cookie的操作,这样可以避免一些需要身份认证的问题。
相比客户端生成方式,使用puppeteer生成的pdf质量比较高,可满足生产要求。
本文中提到的两种方案中,均省去了ajax后端请求数据部分,读者可根据需要自行增加。
Reference
- html2canvas - html2canvas.hertzen.com/documentati…
- jsPDF - github.com/MrRio/jsPDF
- puppeteer - zhaoqize.github.io/puppeteer-a…
- Eggjs - eggjs.org/zh-cn/
