

前言
人工智能是一个最广泛的概念,人工智能的目的就是让计算机这台机器能够象人一样思考,而机器学习是人工智能的分支,专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,使之不断改善自身的性能。
深度学习是一种机器学习的方法,它试图使用包含复杂结构或由多重非线性变换构成的多个处理层(神经网络)对数据进行高层抽象的算法。
深度学习的目的是建立并模拟人脑进行分析学习的神经网络,它模仿大脑的机制来解释数据。
这是学习知识点:
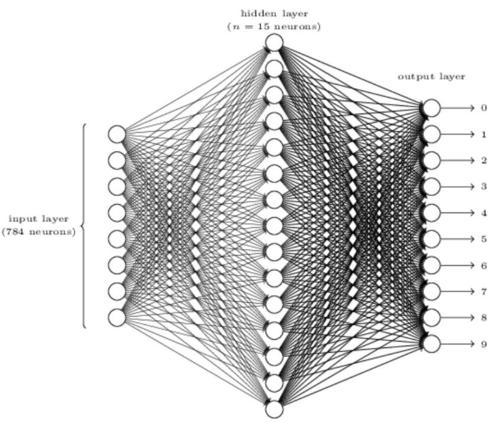
在深度学习网络中,每一个节点层在前一层输出的基础上学习识别一组特定的特征。随着神经网络深度增加,节点所能识别的特征也就越来越复杂,因为每一层会整合并重组前一层的特征。
深度学习的过程同样是分为训练和推理(既“评估”)两个过程,通过训练过程来获得数据模型,然后用于评估新的数据。
数据模型分为两种,一种是所谓判别模型(Discriminative Model),也就是说模型可以直接用来判别事物的。这里所说的判别事物,最典型的就是做分类。既然直接可以用来分类,也就是说我们可以在已知属性的条件下,对该记录进行判断。所以,判别模型是对条件概率进行的建模,也就是p(Y|X)。这里X就是属性集合,实际上就是一个向量;而Y则可能是一个值(此时对应分类问题), 可能是一个向量(此时对应序列标注问题)。判别模型常用于处理分类问题(比如鉴定垃圾邮件)、图像识别等等。
再说一说生成模型(Generative
Model)。生成模型可以描述数据的生成过程。换句话说,已知了这个模型,我们就可以产生该模型描述的数据。而数据由两部分组成,也就是(X,Y),前者是特征,后者则是类别(Y是标量)或者序列类别(Y是向量)。要描述整个数据,也就是要对p(X,Y)进行建模,所以是对联合概率进行建模。生成模型本身不是做分类或者序列标注的,但是可以用来解决这些问题,也可以用于生成式问题,比如聊天机器人、比如AI谱曲等问题。
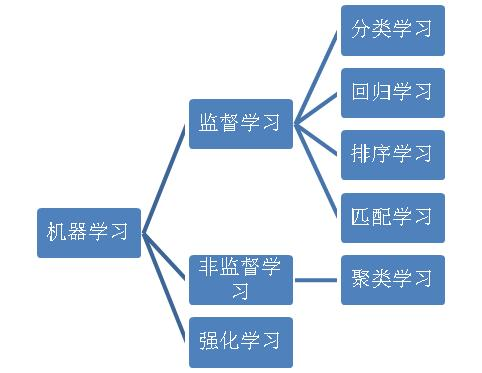
而机器学习可以分成下面几种类别:
监督学习从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。训练数据中的目标是由人标注的。常见的监督学习算法包括回归分析和统计分类。
无监督学习与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有聚类。
半监督学习介于监督学习与无监督学习之间。它主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。。
增强学习通过观察来学习做成如何的动作。每个动作都会对环境有所影响,学习对象根据观察到的周围环境的反馈来做出判断。
在传统的机器学习领域,监督学习最大的问题是训练数据标注成本比较高,而无监督学习应用范围有限。利用少量的训练样本和大量无标注数据的半监督学习一直是机器学习的研究重点。
当前非常流行的深度学习GAN模型和半监督学习的思路有相通之处,GAN是“生成对抗网络”(Generative Adversarial Networks)的简称,包括了一个生成模型G和一个判别模型D,GAN的目标函数是关于D与G的一个零和游戏,也是一个最小-最大化问题。
GAN实际上就是生成模型和判别模型之间的一个模仿游戏。生成模型的目的,就是要尽量去模仿、建模和学习真实数据的分布规律;而判别模型则是要判别自己所得到的一个输入数据,究竟是来自于真实的数据分布还是来自于一个生成模型。通过这两个内部模型之间不断的竞争,从而提高两个模型的生成能力和判别能力。
目前主流的深度学习框架:
Caffe 由Berkeley提出
TensorFlow 由Google提出(Apache 2.0)
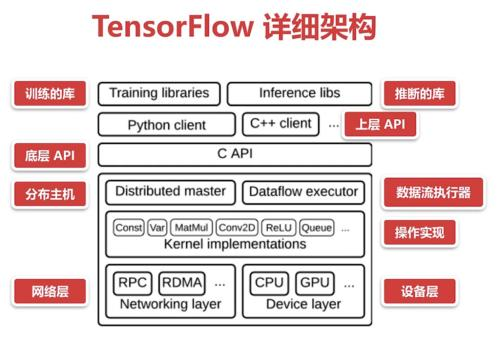
Torch (BSD License), facebook是主要使用者
MXNet 一个相对中立的机器学习框架(Apache 2.0), 被Amazon AWS使用
CNTK2 由Microsoft提出(MIT License)
