

朴素贝叶斯模型是文本分析领域最为常用的模型之一,也是最为经典的模型。文本主要从教学的角度来讲解朴素贝叶斯模型以及数学原理。为了让文档具备完备性,必要的前置知识也包含在文章里。 在这里,我们假设朴素贝叶斯的输入向量是每个单词出现的次数。如果向量的表示为tf-idf等实数型的,我们则需要使用高斯朴素贝叶斯模型(不是本文重点)。
本文章来源于《自然语言处理训练营》,主要以教学为目的,让学员了解最大似然以及如何使用简单的优化技巧来求朴素贝叶斯的最大似然。It is a self-contained draft that everything is included.
作者:李文哲
预备数学知识:
- 求极值问题
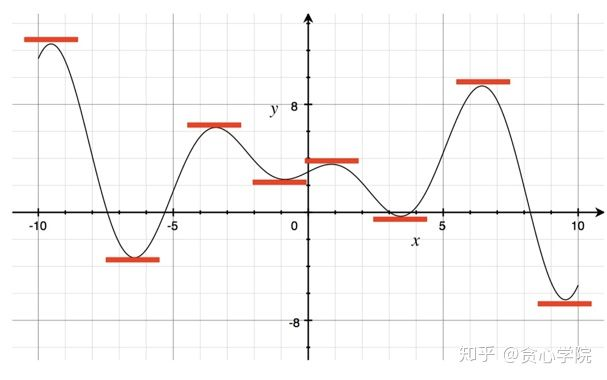
人工智能中最核心的数学环节是求出一个目标函数(object function)的最小值/最大值。求出一个函数最小是/最大值的方法很多,在这里我们介绍一个最经典的方法之一:直接求出极值点。这些极值点的共同特点是在这些点上的梯度为0, 如下图所示。这个图里面,有8个极值点,而且这些极值点中必然会存在最小值或者最大值(除去函数的左右最端点)。所以在这种方式下,我们通常x先求出函数的导数,然后设置成为0。之后从找出的极值点中选择使得结果为最小值/最大值的极值点。
A. 无约束条件的优化
例1:求 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05dc6cbeaaf~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 的最小值
的最小值
对于这样的一个问题,其实我们都知道这个问题的答案是 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05dc67d0b2b~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ,基本上不需要计算就能看出来。接下来我们通过求导的方式来求一下最小值。首先对
,基本上不需要计算就能看出来。接下来我们通过求导的方式来求一下最小值。首先对 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05dda3da34a~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 求导并把导数设置成0。
求导并把导数设置成0。
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05dc690c6a6~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
从而得到 , 求出来的是唯一的极值点,所以最后得出来的函数的最小值是 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05dc642e68c~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05de8c68493~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 的最小值
的最小值
求导之后 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05de9d47d2a~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
即可以得到 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e10060268~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。 把这三个值分别带入到 即可以得到
。 把这三个值分别带入到 即可以得到 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05deb88e0f4~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。所以,
。所以, ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05ded1b4266~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 两个点都可以作为函数的最小值点,这时候函数值为
两个点都可以作为函数的最小值点,这时候函数值为 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05deac4b029~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。
。
*请注意:并不一定所有函数的极值都可以通过设置导数为0的方式求出。也就是说,有些问题中当我们设定导数为0时,未必能直接计算出满足导数为0的点(比如逻辑回归模型),这时候就需要利用数值计算相关的技术(最典型为梯度下降法,牛顿法..)
B. 带约束条件的优化 - 拉格朗日乘法项(Lagrangian Multiplier)
对于某些求极值问题,函数通常带有一些条件。如下面的例子:
例3:求 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e130e3045~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 的最大值,但有个条件是
的最大值,但有个条件是 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e1b608857~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。那这时候怎么求出最大值呢?
。那这时候怎么求出最大值呢?
拉格朗日乘法项就是用来解决这类问题。我们可以把限制条件通过简单的转变加到目标函数中,这时候问题就变成了
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e1b740479~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
剩下的过程就跟上面的类似了。设定导数为0,即可以得到以下三个方程:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e1b70009b~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e31f48d8b~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e1d666be7~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
解完之后即可以得到 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e423999be~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。 针对于每一个$\lambda$我们得到的解为
。 针对于每一个$\lambda$我们得到的解为 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e340c9005~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。把两个解带入到原来函数里并做比较即可以确定最优解。
。把两个解带入到原来函数里并做比较即可以确定最优解。
2. 最大似然估计(Maximum Likelihood Estimation)
最大似然估计是机器学习领域最为常见的用来构建目标函数的方法。它的核心思想是根据观测到的结果来预测其中的未知参数。我们举一个投掷硬币的例子。
假设有一枚硬币,它是不均匀的,也就是说出现正面的反面的概率是不同的。假设我们设定这枚硬币出现正面的概率为 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e4ec8db60~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) , 这里
, 这里 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e3f622f39~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 指的是正面(head), 类似的还会有反面(tail)。假设我们投掷6次之后得到了以下的结果,而且我们假定每次投掷都是相互独立的事件:
指的是正面(head), 类似的还会有反面(tail)。假设我们投掷6次之后得到了以下的结果,而且我们假定每次投掷都是相互独立的事件:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e43b5c853~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
其中D表示所观测到的所有样本。从这个结果其实谁都可以很容易说出 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e3a96ccf0~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ,也就是出现正面的概率为4/6,其实我们在无意识中使用了最大似然估计法。接下来,我们从更严谨的角度来定义最大似然下的目标函数。
,也就是出现正面的概率为4/6,其实我们在无意识中使用了最大似然估计法。接下来,我们从更严谨的角度来定义最大似然下的目标函数。
基于最大似然估计法,我们需要最大化观测到样本的概率,即p(D)。进一步可以写成:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e5cee913f~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
我们的目标是最大化概率值 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e54798f02~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。那这部分的优化即可以采用上面所提到的方法。
。那这部分的优化即可以采用上面所提到的方法。
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e5bf743b3~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
把这个式子整理完之后即可以得到 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e6647f64b~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) , 结果跟一开始我们算出来的是一致的。
, 结果跟一开始我们算出来的是一致的。
朴素贝叶斯的最大似然估计
假设给定了一批训练数据 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e671031cd~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ,其中
,其中 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e67b5c9dd~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 指的是第
指的是第 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e9b9c0919~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 个样本(文章),而且这个样本(文章)包含了
个样本(文章),而且这个样本(文章)包含了 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05eab8d2360~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 个单词,所以可以 表示成
个单词,所以可以 表示成 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05ea8d8fea6~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) . 假设$x^i$的全文内容为"今天 很 高兴 来 参加 自然语言处理 训练营", 那这时候
. 假设$x^i$的全文内容为"今天 很 高兴 来 参加 自然语言处理 训练营", 那这时候 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05ea2f83eb1~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) "今天",
"今天", ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05e6da88018~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ="很",
="很", ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05eaa39d77c~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ="高兴",
="高兴", ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05eb9ffe75d~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ="来"
="来" ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05eab715ef6~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ="参加",
="参加", ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05ec397a4a0~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ="自然语言处理",
="自然语言处理", ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05ec3801f9e~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ="训练营"。所以这里
="训练营"。所以这里 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05ec474895b~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。另外,
。另外, ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05ec5965413~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 代表的是$x^i$的标签。比如在垃圾邮件应用上,它代表"垃圾邮件",”正常邮件“。我们利用K来代表分类的个数。比如在垃圾邮件应用上K=2。但在这里,我们考虑普遍的情况,很有可能K>2,也称之为是多分类问题。最后,我们再定义V为词典库的大小。
代表的是$x^i$的标签。比如在垃圾邮件应用上,它代表"垃圾邮件",”正常邮件“。我们利用K来代表分类的个数。比如在垃圾邮件应用上K=2。但在这里,我们考虑普遍的情况,很有可能K>2,也称之为是多分类问题。最后,我们再定义V为词典库的大小。
朴素贝叶斯是生成模型,它的目标是要最大化概率p(D),也就是p(x,y)。我们把前几步的推导先写一下:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05ed73aae58~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
这里简单说明一下:样本 由很多个单词来构成,这里每一个 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05ece1a0bb7~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 看作是一个单词。最后一个是利用了朴素贝叶斯的假设,也就是每个词都是相互独立的。比如给定一个句子"我们 今天 运动",在给定一个标签y的情况下,概率可以写成
看作是一个单词。最后一个是利用了朴素贝叶斯的假设,也就是每个词都是相互独立的。比如给定一个句子"我们 今天 运动",在给定一个标签y的情况下,概率可以写成 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05ee0c274f4~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。
。
我们看到式子里面都是乘法项,而且多个乘法项很容易引起数据的overflow或则underflow(在这里是underflow)。所以我们一般不直接最大化p(D),而是最大化 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05ee4e7ba86~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) , 其实这两个是等同的。因为
, 其实这两个是等同的。因为 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05ee6fcabee~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 函数是严格递增的函数。加上 ,我们对上面式子做一些变化:
函数是严格递增的函数。加上 ,我们对上面式子做一些变化:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05ee8539211~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
在这里我们用了一些技巧。举例子,假设一个文章的内容为 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05eef1ab88d~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ,按照之前的逻辑这句话的概率为
,按照之前的逻辑这句话的概率为 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05efe103248~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。但另一方面,我们也可以利用词典库的所有的词来代表这个概率。
。但另一方面,我们也可以利用词典库的所有的词来代表这个概率。 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f15aad450~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) .
.
这两者是等同的,只不过我们从词典库的维度把所有的单词都考虑了进来,并数一下每一个单词在文档i里出现了多少次,如果没有出现,相当于0次。所以从这个角度我们可以把 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05fb92e277e~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 写成
写成 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f1c6cf709~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ,其中
,其中 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f19a2ea2f~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 代表单词j出现在文档$i$的次数。这里
代表单词j出现在文档$i$的次数。这里 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f217c03b0~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 代表词典库里的第j个单词。
代表词典库里的第j个单词。
另外,我们也用到了 的性质。比如 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f22520464~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。还有一点是,一开始的时候我们是从文档1到N的顺序来循环,但现在我们先取出类别为1的文档,然后再取出类别为2的文档,以此类推。所以前面的
。还有一点是,一开始的时候我们是从文档1到N的顺序来循环,但现在我们先取出类别为1的文档,然后再取出类别为2的文档,以此类推。所以前面的 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f25765216~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 被拆分成两个sum, 即
被拆分成两个sum, 即 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f348f03b0~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。这里
。这里 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f33d1c0e1~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 代表属于类别k的所有文档。另外,我们引入了两组变量。也就是我们直接设置
代表属于类别k的所有文档。另外,我们引入了两组变量。也就是我们直接设置 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f3a0d8c5d~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 为
为 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f366b08be~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ,意思就是当文章分类为k的时候出现单词 的概率( )。
,意思就是当文章分类为k的时候出现单词 的概率( )。
另外,我们设定 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f3d5b6986~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 为
为![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f47b680b5~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ,也就是文档属于第k类的概率,这个也是朴素贝叶斯模型的先验(prior)。 比如在垃圾识别应用中,假设总共有100个垃圾邮件和1000个正常邮件,这时候一个邮件为垃圾邮件的概率为
,也就是文档属于第k类的概率,这个也是朴素贝叶斯模型的先验(prior)。 比如在垃圾识别应用中,假设总共有100个垃圾邮件和1000个正常邮件,这时候一个邮件为垃圾邮件的概率为 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f4d3e3c97~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) , 正常邮件的概率为10/11,这就是贝叶斯模型的先验,而且所有之和等于1。最后我们引入了一个新的变量叫做
, 正常邮件的概率为10/11,这就是贝叶斯模型的先验,而且所有之和等于1。最后我们引入了一个新的变量叫做 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f52de8550~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ,也就是属类别k的文件个数(训练数据总统计即可,是已知的)。也就是
,也就是属类别k的文件个数(训练数据总统计即可,是已知的)。也就是 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f51bddb55~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。
。
另外,有两个约束条件需要满足,分别是:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f57d1fa02~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
第一个条件表示的是所有类别的概率加在一起等于1. 比如 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f609cffc4~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。第二个条件表示的是对于任意一个分类k, 出现所有词典里的单词的总概率合为1. 所以,这个问题是有约束条件的优化问题。把约束条件和目标函数写在一起即可以得到:
。第二个条件表示的是对于任意一个分类k, 出现所有词典里的单词的总概率合为1. 所以,这个问题是有约束条件的优化问题。把约束条件和目标函数写在一起即可以得到:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f5fa48ece~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f68e9b783~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
利用拉格朗日乘法项,我们可以把目标函数写成:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f6c4be6c5~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
A: 找出最优解
我们需要设置导数为0,进而找出最优解。现在求解的是 ,所以只要跟 无关的项我们都可以不用考虑,因为它们导数为0. ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f7a7e82a1~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 对 的导数为:
对 的导数为:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f6f2a37e6~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
解为 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f744a0468~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。这里有个参数
。这里有个参数 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f824284bb~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ,但同时我们有一个约束条件是
,但同时我们有一个约束条件是 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f8ba1dd3d~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) , 我们把刚才的解带入到这里,可以得到:
, 我们把刚才的解带入到这里,可以得到:
则 的值为 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f8f441729~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。把$\lambda$再次带入到 里面,我们可以得到:
。把$\lambda$再次带入到 里面,我们可以得到:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f8be4e723~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
这里面 为k类文档出现的个数,分母为所有文档的个数。
B. 找出最优解
类似的,我们需要求L对 的导数为:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f936d24f4~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
解为 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05f94a0a04b~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。这里有个参数是
。这里有个参数是 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05fe03fb967~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ,但同时我们有个约束条件是
,但同时我们有个约束条件是 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05fa8d020bc~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) ,把刚才的解带入到这里,可以得到:
,把刚才的解带入到这里,可以得到:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05fac24e24a~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
把 带入到上面的解即可以得到:
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05fb58bdb32~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
这个式子中分子代表的是在所有类别为k的文档里出现了多少次 ![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/5/16bbe05fb67a0515~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 也就是词典库里的j个单词。分母代表的是在类别为k的所有文档里包含了总共多少个单词。
也就是词典库里的j个单词。分母代表的是在类别为k的所有文档里包含了总共多少个单词。
到此为止,模型的参数已经得到。If there is any mistake, pls let me know.
