

性能为何至关重要
引自:性能为何至关重要
网站开始加载时,用户需要等待一段时间才能看到要显示的内容。这部分时间是可以通过性能优化控制的。
- 性能关乎用户的去留
当用户等待的时间超过忍耐的程度时,必将抛弃该应用
- 性能关乎转化率的提升
响应速度慢会对网站收入带来不利影响,反之亦然。
- 性能关乎用户体验
等待页面的加载时间就是在考验用户的忍耐力,而用户的忍受时间也是有一个阈值的。
- 性能关乎用户
性能低的网站和应用还会导致用户产生实际成本。
http 缓存
大部分性能优化都是基于缓存用空间换时间,一般使用资源的缓存提高加载的性能。
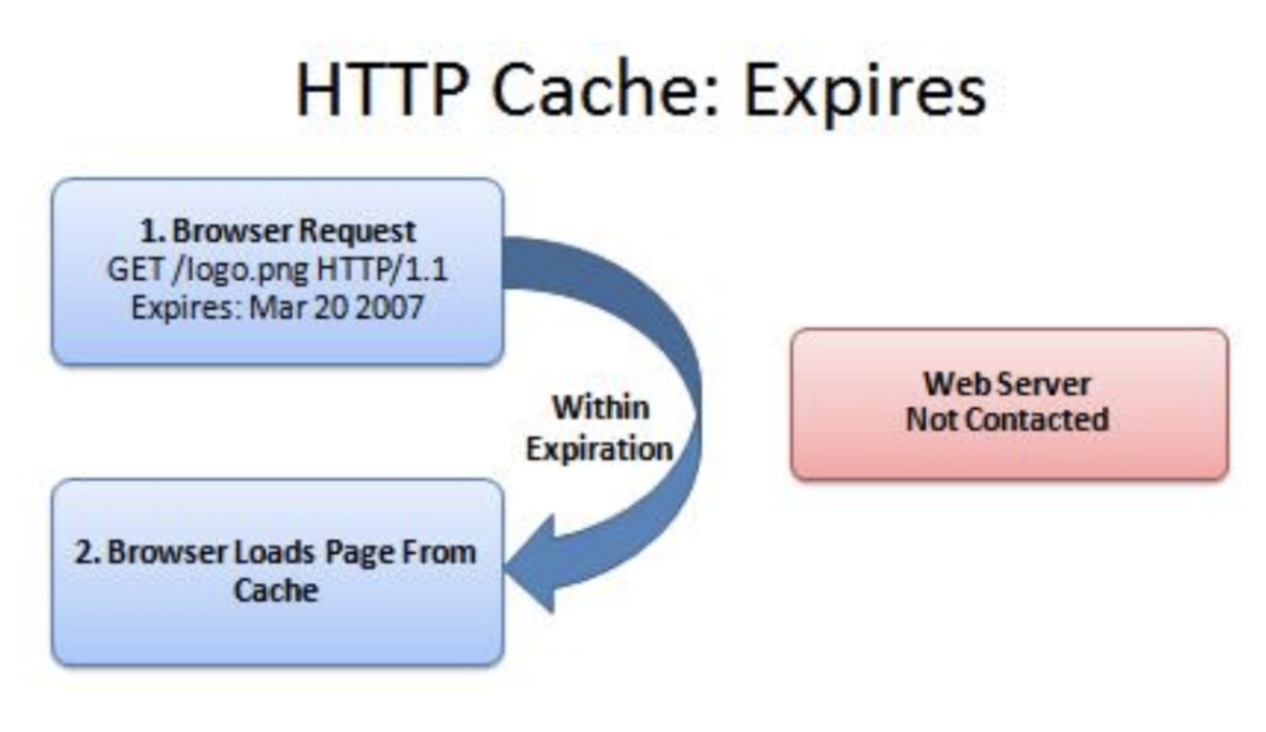
Expires
设置缓存对象的有效期
因为工程化的发展,目前很少有人用这个参数去控制 http 请求的缓存了,用过的人可能知道,这个参数现在最常见的就是在设置 cookie 上
如果有人想用这个参数,一样也可以设置到请求里,设置了 Expires 的请求头大概是这样的
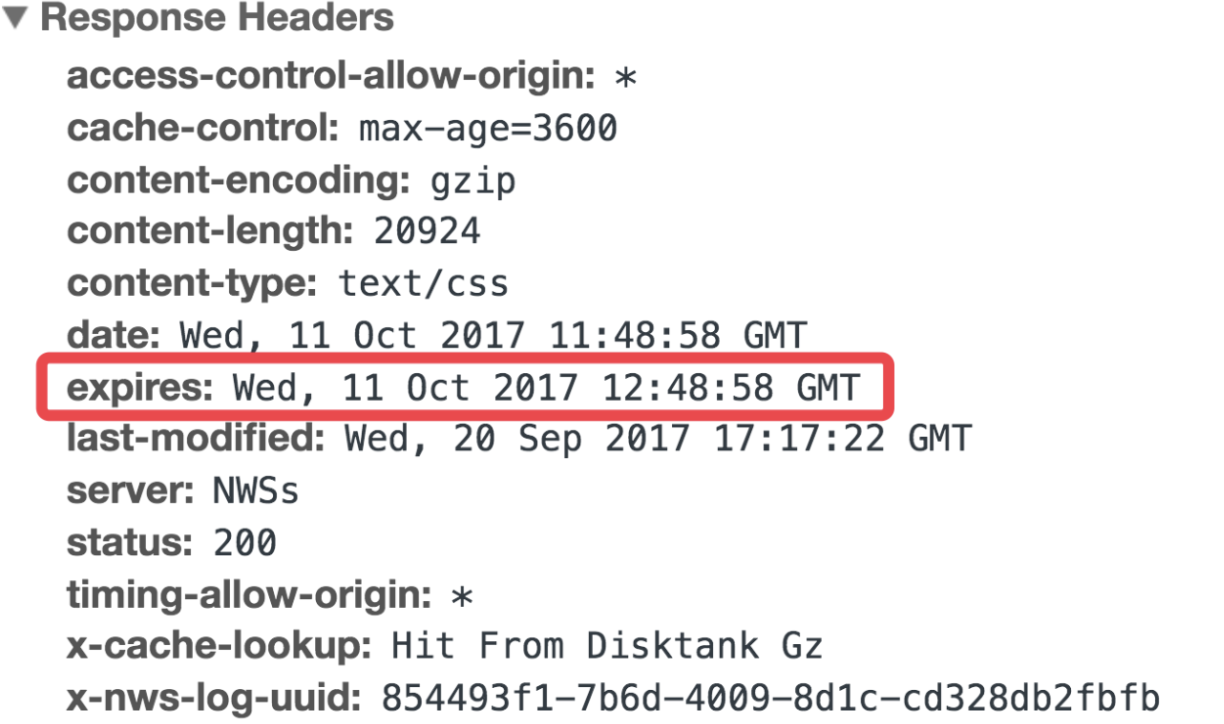
如果请求的时候找到缓存文件了,并且查看缓存的时间未过期,则不会再次给服务发起请求,而是直接使用缓存。
cache-Control
上面的 response header 图中可见,也设置了最大的缓存时间的 cache-control:max-age=3600
- max-age=num 设置最大缓存时间
- public 缓存能被多用户共享
- private 缓存不能在多用户间共享
- no-cache 缓存前必需确认缓存的有效性
- no-store 不能被存储
last-modified
设置对象的最后修改时间
如果我们启用了协商缓存,它会在首次请求的时候被携带在响应头里,之后我们每次请求都会带上一个 if-modified-since 时间戳,服务器接收到这个值后会把前后两次时间戳进行对比,判断文件资源是否变化
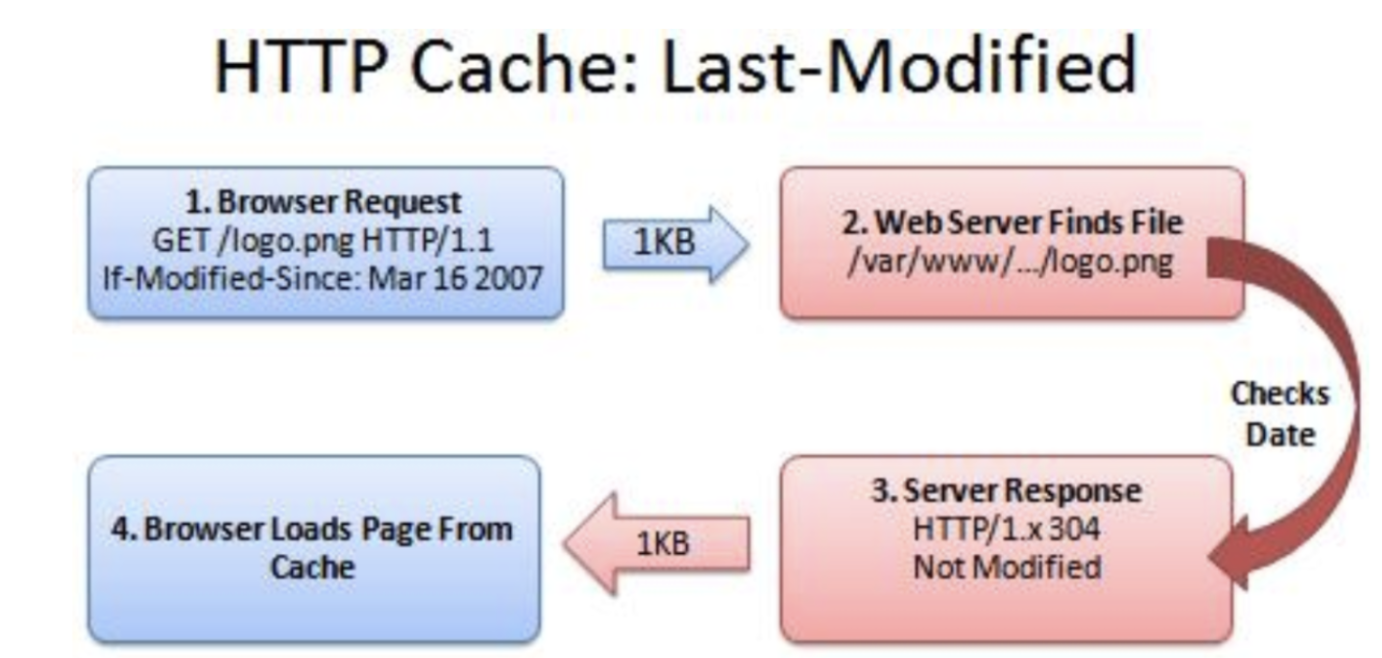
last-modified 也会有弊端,如果我们修改文件的时间过快或者修改了文件,但内容没有变化时,last-modified 的时间就不能处理文件是否发生变化了,这个时候 Etag 就诞生了
Etag
文件 hash 值
通过文件 hash 值判断缓存文件是否修改,从而判断是否请求新资源
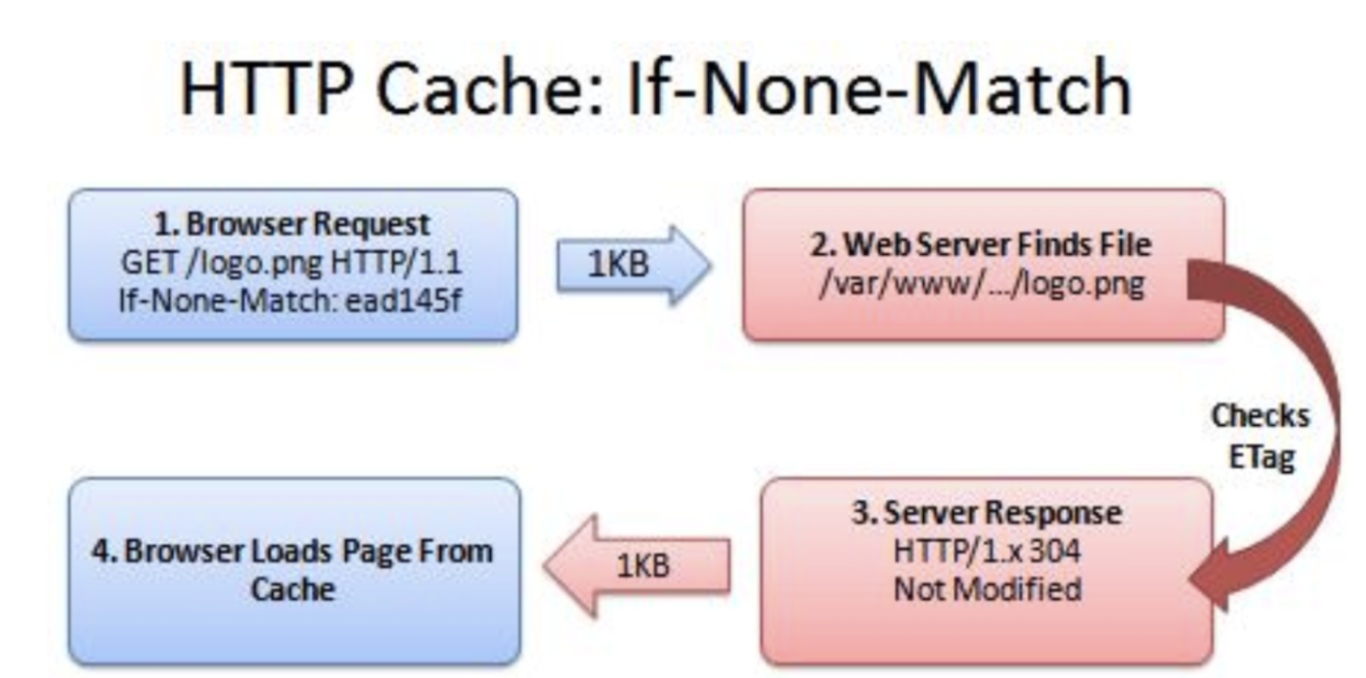
如果还存在一些还在使用 http 1.0 的场景的话,Etag 将不会起作用。
资源缓存方案
- HTML(no-cache + etag/last-modified)
- css、js(md5码/timestamp/version + 长缓存)
- Image(随机名字+长缓存)
请求包优化
众所周知,请求资源时,如果资源越大,延时越大
代码压缩/合并(css、js)
现在的工程化已经能够做到帮我们处理这一项了。
gzip
减少文件大小。gzip压缩比率在3到10倍左右,可以大大节省服务器的网络带宽。
需要服务器和浏览器支持,对文件进行压缩后返回到用户端解压加载
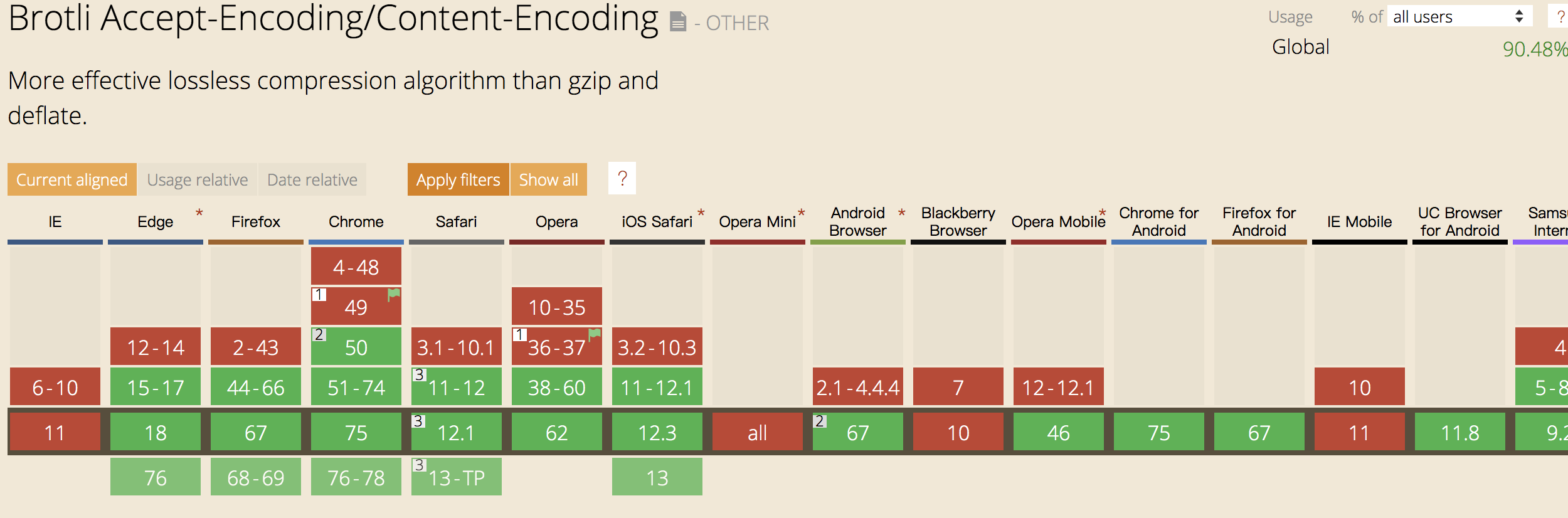
一般在小的文件上配置 gzip 是没有必要的,毕竟如果服务器压缩,浏览器解压再加上加载文件的总时间都超过直接加载文件的时间的话,使用 gzip 还有什么意义呢?
若需配置 gzip,在请求的 headers 中加上这么一句就可以了
accept-encoding:gzip
如果使用 nginx 作为 web 服务器的话,可在 nginx.conf 中对文件进行配置
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
gzip on; #开启gzip
gzip_min_length 1k; #低于1kb的资源不压缩
gzip_comp_level 3; #压缩级别【1-9】,越大压缩率越高,同时消耗cpu资源也越多,建议设置在4左右。
#需要压缩哪些响应类型的资源,多个空格隔开。不建议压缩图片,因为图片压缩后不仅降低不了多少文件大小,反而还占用了大量的服务器压缩资源。
gzip_types text/plain application/javascript application/x-javascript text/javascript text/xml text/css;
gzip_disable "MSIE [1-6]\."; #配置禁用gzip条件,支持正则。此处表示ie6及以下不启用gzip(因为ie低版本不支持)
gzip_vary on; #是否添加“Vary: Accept-Encoding”响应头
server {
listen 80;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
gzip也有一个非常明显的缺点,毕竟不管是服务器的压缩还是浏览器的解压,都会占用服务端和客户端的 CPU 资源。所以需要根据自身情况考虑后再决定是否有必要使用 gzip。
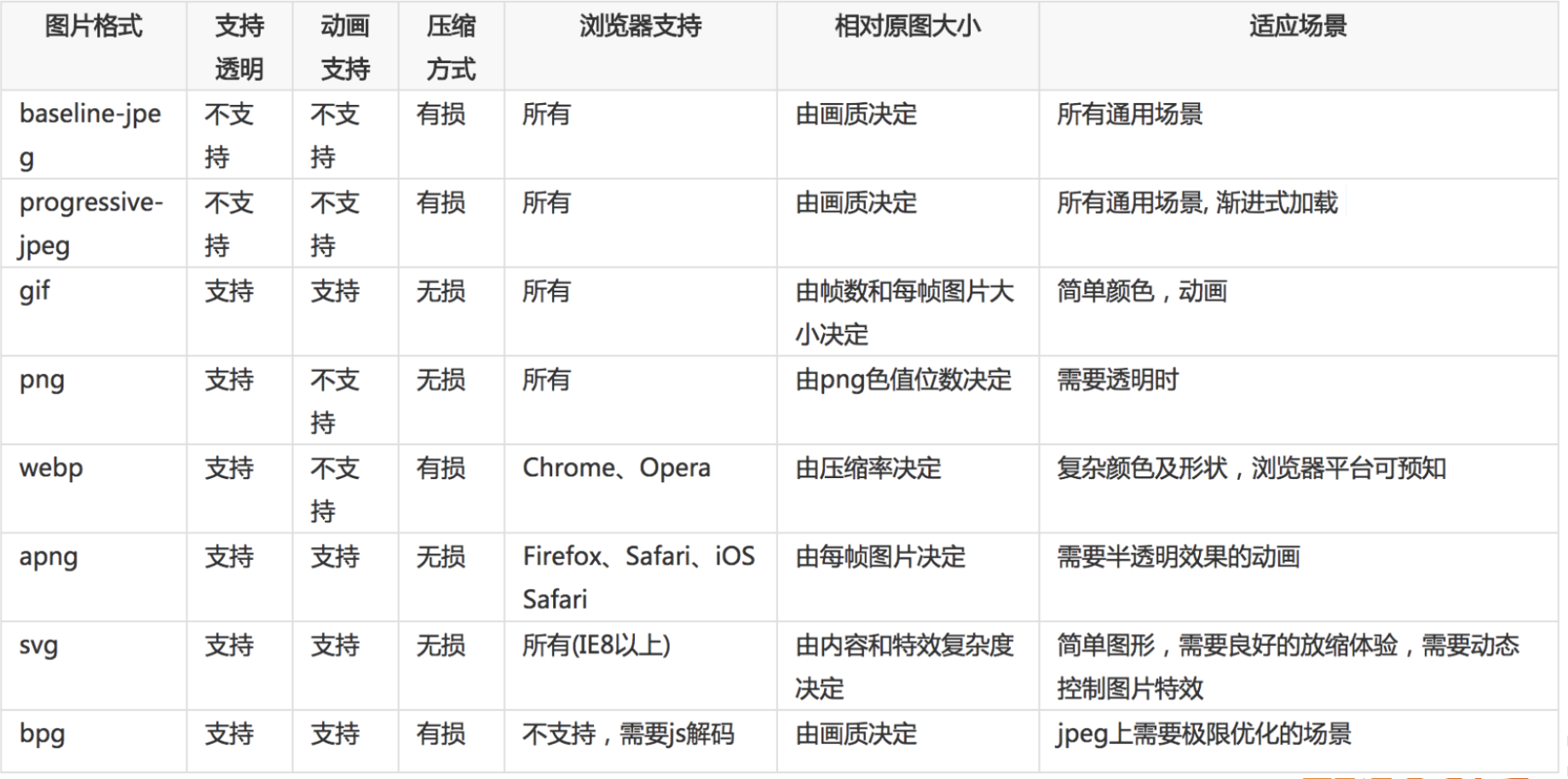
图片优化
图片一般是页面中最大的资源,所以图片的优化很重要
在加载图片的时候,可通过配置(一般由创建图片的角色操作)渐进式图片提高用户的体验。关于渐进式图片的配置和使用效果可参见张鑫旭的渐进式图片及其相关
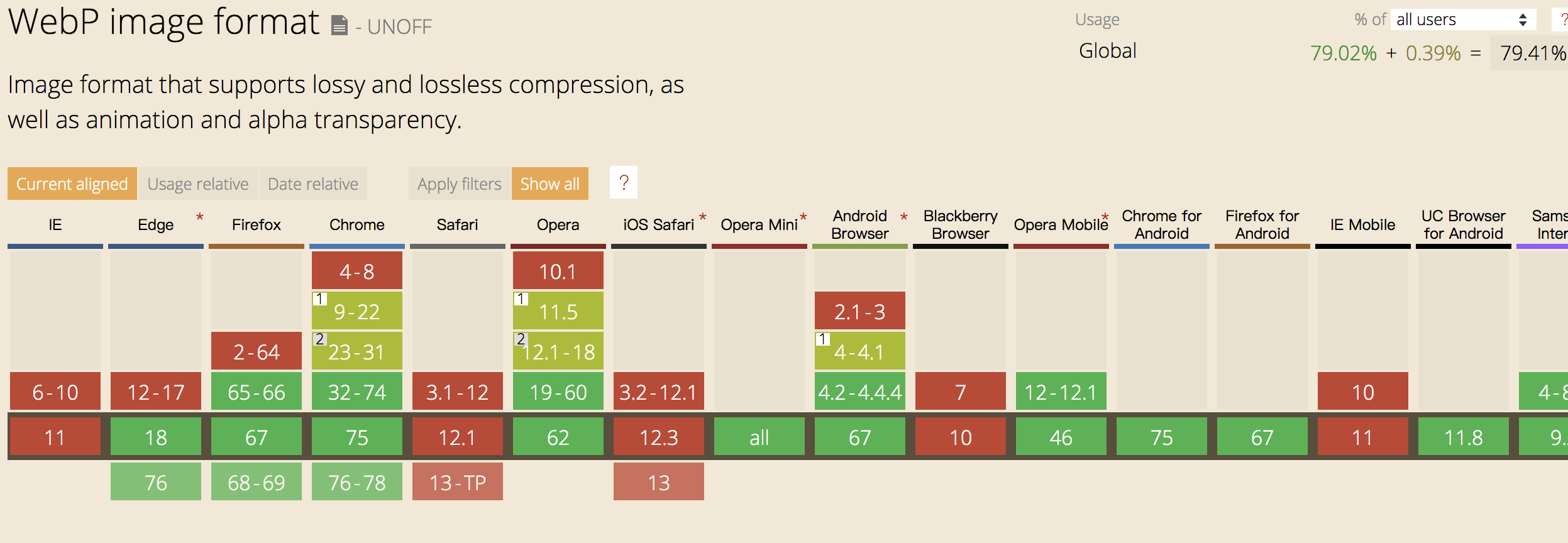
很多人会觉得 webp 的图片的大小会小很多,所以加载会很快,但webp的兼容性并不好
图标型图片
如果使用图标型图片时,可以通过2种方式:
- 雪碧图
- iconfont 图标字体(推荐)
小图 -> 大图
在一般的场景下,我们都可以使用视觉欺诈的方式去处理图片
- ⼩图是⼤图的缩略图,然后放到⼤图的⼤⼩
- ⼤图保存成图⽚渐进模式
- ⼩图 onload 之后再加载⼤图,加载完成后直接替换⼩图
其他
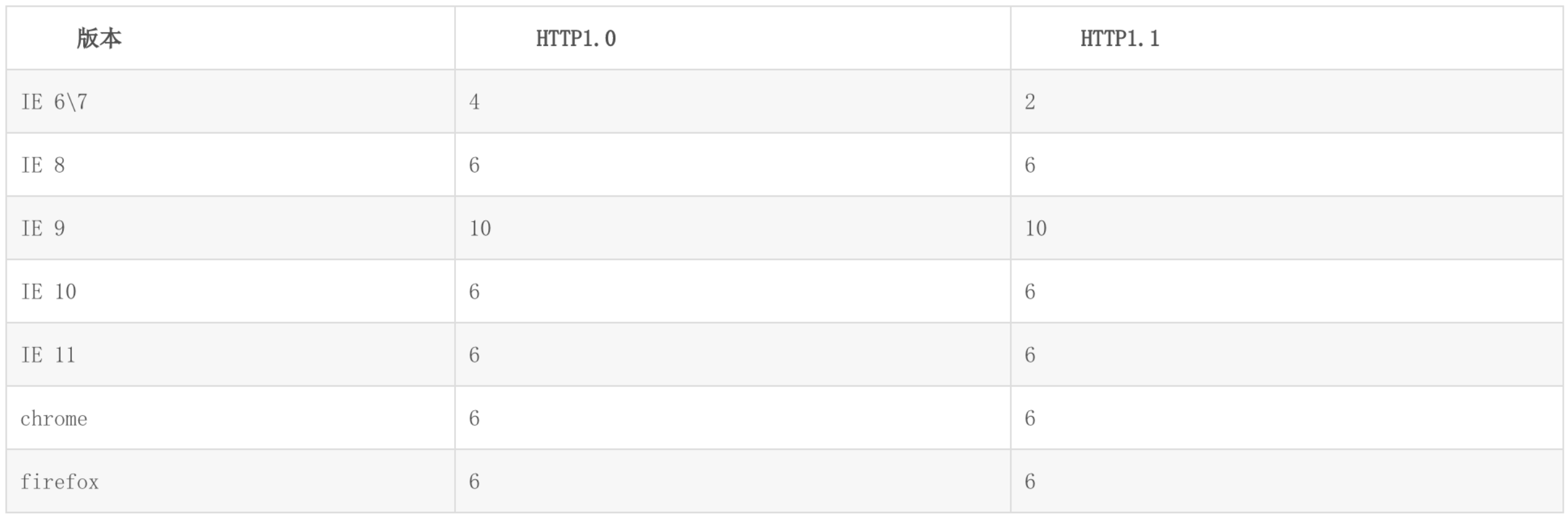
从网络层面,我们前端能做得到的优化非常有限。相比之下,HTTP 连接这一层面的优化才是我们网络优化的核心。
- 减少请求次数
前面说的资源合并,合理利用浏览器的并行请求数量
- 减少单次请求所花费的时间
前面说的资源压缩
webpack 工程优化
现在大部分工程都会使用 webpack 打包处理。大家在使用时会不会觉得打包的过程太长?打包完的文件体积太大?
优化构建速度
resolve
资源搜索过程优化
- resolve.modules
告诉webpack去哪些目录下寻找第三方模块
默认值为['node_modules'],会依次查找 ./node_modules、 ../node_modules、 ../../node_modules
resolve.modules:[path.resolve(__dirname, 'node_modules')]
- resolve.alias
可以给一些包(开发包/依赖包)设置别名,使得 webpack 在打包时查找文件时无需层层查找
resolve.alias:{
'@pages':patch.resolve(__dirname, '/src/pages')
}
module
- module.noParse
告诉Webpack不必解析哪些文件,可以用来排除对非模块化库文件的解析
module:{ noParse:[/webim\.min\.js$/,/chart\.js$/] }
loader
- include、exclude
减少不必要的转译
module: {
rules: [
{
test: /\.js$/,
exclude: /(node_modules|bower_components)/,
use: {
loader: 'babel-loader',
options: {
presets: ['@babel/preset-env']
}
}
}
]
}
- babel-loader 参数:cacheDirectory
缓存没有发生改变的文件的转译资源,无需再次转译
module: {
rules: [
{
test: /\.js$/,
exclude: /(node_modules|bower_components)/,
use: {
loader: 'babel-loader?cacheDirectory=true',
options: {
presets: ['@babel/preset-env']
}
}
}
]
}
- HappyPack
webpack 是单线程的,就算存在多个任务,也是排队依次进行处理。而 webpack 打包过程中,loader 解析最耗时。
HappyPack 可以充分利用 CPU 在多核并发的优势,把任务分解给多个子进程去并发的执行,子进程处理完后再把结果发送给主进程
const path = require('path');
const ExtractTextPlugin = require('extract-text-webpack-plugin');
const HappyPack = require('happypack');
module.exports = {
module: {
rules: [
{
test: /\.js$/,
// 把对 .js 文件的处理转交给 id 为 babel 的 HappyPack 实例
use: ['happypack/loader?id=babel'],
// 排除 node_modules 目录下的文件,node_modules 目录下的文件都是采用的 ES5 语法,没必要再通过 Babel 去转换
exclude: path.resolve(__dirname, 'node_modules'),
},
{
// 把对 .css 文件的处理转交给 id 为 css 的 HappyPack 实例
test: /\.css$/,
use: ExtractTextPlugin.extract({
use: ['happypack/loader?id=css'],
}),
},
]
},
plugins: [
new HappyPack({
// 用唯一的标识符 id 来代表当前的 HappyPack 是用来处理一类特定的文件
id: 'babel',
// 如何处理 .js 文件,用法和 Loader 配置中一样
loaders: ['babel-loader?cacheDirectory'],
// ... 其它配置项
}),
new HappyPack({
id: 'css',
// 如何处理 .css 文件,用法和 Loader 配置中一样
loaders: ['css-loader'],
}),
new ExtractTextPlugin({
filename: `[name].css`,
}),
],
};
DllPlugin
DllPlugin 插件会把第三方库单独打包到一个文件中,这个文件就是一个单纯的依赖库。这个依赖库不会跟着业务代码一起被重新打包,只有当依赖自身发生版本变化时才会重新打包。
注: 该插件主要使用的是已打包好的文件缓存
用 DllPlugin 处理文件,要分两步走:
- 基于 dll 专属的配置文件,打包 dll 库
// webpack_dll.config.js
const path = require('path')
const webpack = require('webpack')
module.exports = {
mode: 'production',
entry: {
lodash: ['lodash'],
jquery: ['jquery']
},
output: {
filename: '[name].dll.js',
path: path.resolve(__dirname, '../dll'),
library: '[name]'
},
plugins: [
new webpack.DllPlugin({
name: '[name]',
path: path.resolve(__dirname, '../dll/[name].manifest.json') // 用这个插件来分析打包后的这个库,把库里的第三方映射关系放在了这个 json 的文件下,这个文件在 dll 目录下
})
]
}
配置执行 webpack_dll.config.js 文件的指令,并执行
"scripts": {
"build:dll": "webpack --config ./build/webpack.dll.js"
}
最终构建出的文件:
|-- jquery.dll.js
|-- jquery.manifest.json
|-- lodash.dll.js
└── lodash.manifest.json
- 基于 webpack.config.js 文件,打包业务代码
在主config文件里使用 DllReferencePlugin 插件引入 xx.manifest.json 文件
//webpack.config.js
const path = require('path');
const DllReferencePlugin = require('webpack/lib/DllReferencePlugin');
module.exports = {
entry:{ main:'./main.js' },
//... 省略output、loader等的配置
plugins:[
new DllReferencePlugin({
// manifest就是我们第一步中打包出来的json文件
manifest:require('./dist/jquery.manifest.json')
}),
new DllReferenctPlugin({
// manifest就是我们第一步中打包出来的json文件
manifest:require('./dist/lodash.manifest.json')
})
]
}
打包后的文件体积优化
包组成可视化工具——webpack-bundle-analyzer,它会以矩形树图的形式将包内各个模块的大小和依赖关系呈现出来,截取官网图如下:
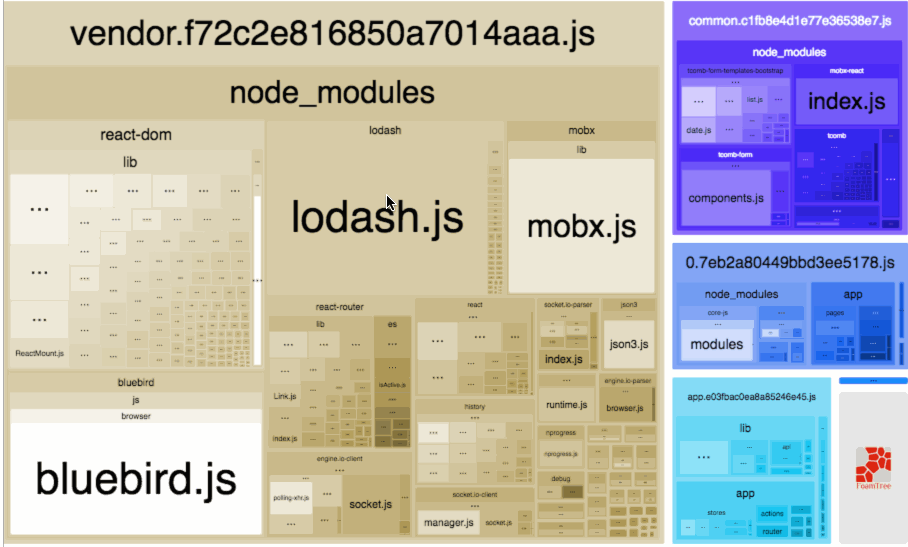
在使用时,我们只需要将其以插件的形式引入:
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
module.exports = {
plugins: [
new BundleAnalyzerPlugin({
openAnalyzer: true,
})
]
}
压缩
- UglifyJsPlugin
在 webpack3 中,引入 UglifyJsPlugin 插件对 js 进行压缩,webpack4 现在已经默认使用 uglifyjs-webpack-plugin 对代码做压缩了—— 在 webpack4 中,我们是通过配置 optimization.minimize 与 optimization.minimizer 来自定义压缩相关的操作。
module.exports = {
//... 省略其他配置
optimization: {
runtimeChunk: {
name: 'manifest'
},
minimizer: true, // [new UglifyJsPlugin({...})]
splitChunks:{
chunks: 'async',
}
}
}
移除 JavaScript 上下文中的未引用代码(dead-code),从而减少打包后文件的体积。它依赖于 ES2015 模块系统中的静态结构特性,例如 import 和 export。
从定义中可以看出,Tree-Shaking 的针对性很强,它更适合用来处理模块级别的冗余代码。至于粒度更细的冗余代码的去除,可以通过配置插件对 js 和 css 进行压缩分离处理,如上面的 UglifyJsPlugin。
- compresion-webpack-plugin
使用不同的算法对压缩后的文件进行再压缩
const path = require('path');
const CompressionPlugin = require('compression-webpack-plugin')
module.exports = {
plugins: [
new CompressionPlugin({
test: /\.(js|css|html)$/,
// include: /\/src/,
filename: '[path].gz[query]',
algorithm: 'gzip', //算法
// threshold: 8192,
}),
]
}
使用该插件后的文件大小差别如下图所示,可以看出至少减少了 一半 的大小,使用压缩文件也有一些缺点,在上面的gzip中也有提到。
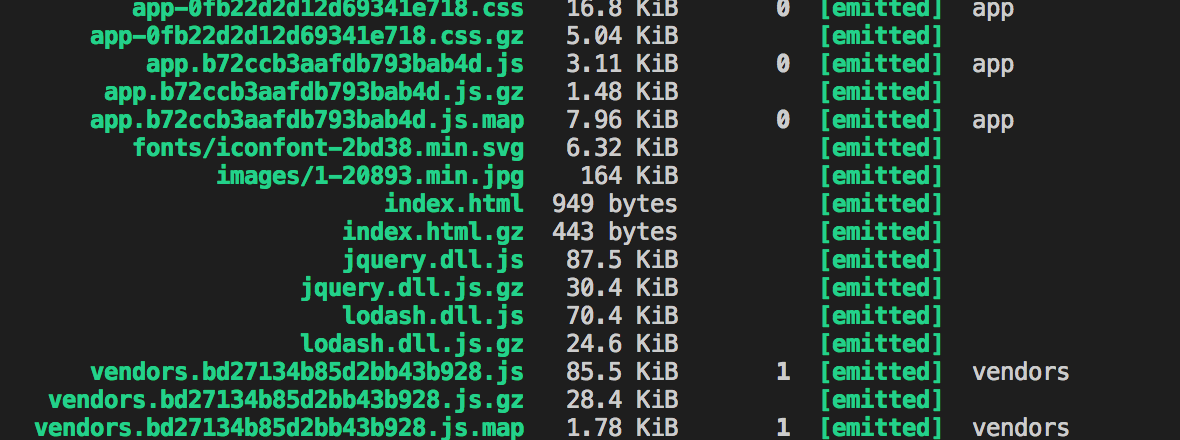
按需加载
主要场景:单页应用
举个例子:使用 vue 构建一个单页应用,其中有十个路由,通过 vue-router 控制这些路由,每个路由对应的页面的业务都不简单。打包发布这个项目后,打开网站极大概率会出现长时间等待
这时候我们可以选择按需加载路由或组件,当前路由对应的页面只加载当前页面相关的组件或路由。
// 按需加载路由
{
path: '/promisedemo',
name: 'PromiseDemo',
component: () => import('../components/PromiseDemo')
// 或者使用下面的写法
// component: resolve => resolve(require('../components/PromiseDemo'))
},
{
path: '/hello',
name: 'Hello',
// component: Hello
component: () => import('../components/Hello')
// 或者使用下面的写法
// component: resolve => resolve(require('../components/Hello'))
}
有时候我们想把某个路由下的所有组件都打包在同个异步块 (chunk) 中。只需要使用 命名 chunk,一个特殊的注释语法来提供 chunk name (需要 Webpack > 2.4)。引自:组件按组分块
const Foo = () => import(/* webpackChunkName: "group-foo" */ './Foo.vue')
const Bar = () => import(/* webpackChunkName: "group-foo" */ './Bar.vue')
const Baz = () => import(/* webpackChunkName: "group-foo" */ './Baz.vue')
