


背景
在线上项目中,我们需要统计下用户在使用该产品的行为与使用情况,通过这些统计数据进行处理与分析,从用户的角度去了解该产品的使用与体验,从而更好的进行产品的迭代与升级,更加符合用户的体验,更加贴近用户使用习惯。 因此,我们在业务中需要添加一些用户行为统计的需求,如:
- 收集用户在页面的浏览量或点击量
- 访问某个站点不同 IP 的人数
- 用户在页面中停留的时间
- 用户在页面中触发的行为
- 用户滚屏行为
这些都是用户数据的统计点,这也是前端数据监控的着重点。除了数据监控,前端监测还包括了性能监控和异常监控。性能监控有以下:
- 首屏加载时间
- 白屏加载时间
- http 响应时间
- 资源下载整体时间
- 页面渲染时间
- 页面交互动画完成时间
异常监控包括了:监控脚本异常与样式异常。
为什么需要前端监控
埋点就是用户数据的采集,获取用户行为以及跟踪产品用户体验情况。 埋点后,将收集到的用户数据进行监控及处理,并以之为基础,指明产品优化的方向,是产品需求的来源,检验功能是否达到预期的佐证。 数据采集与上报是整个流程中的重要一环,只有确保前端数据生产的全面、准确、及时,最终的数据结果才是可靠的、有价值的。
前端监控分为三种:数据监控、性能监控、异常监控。如下图所示:
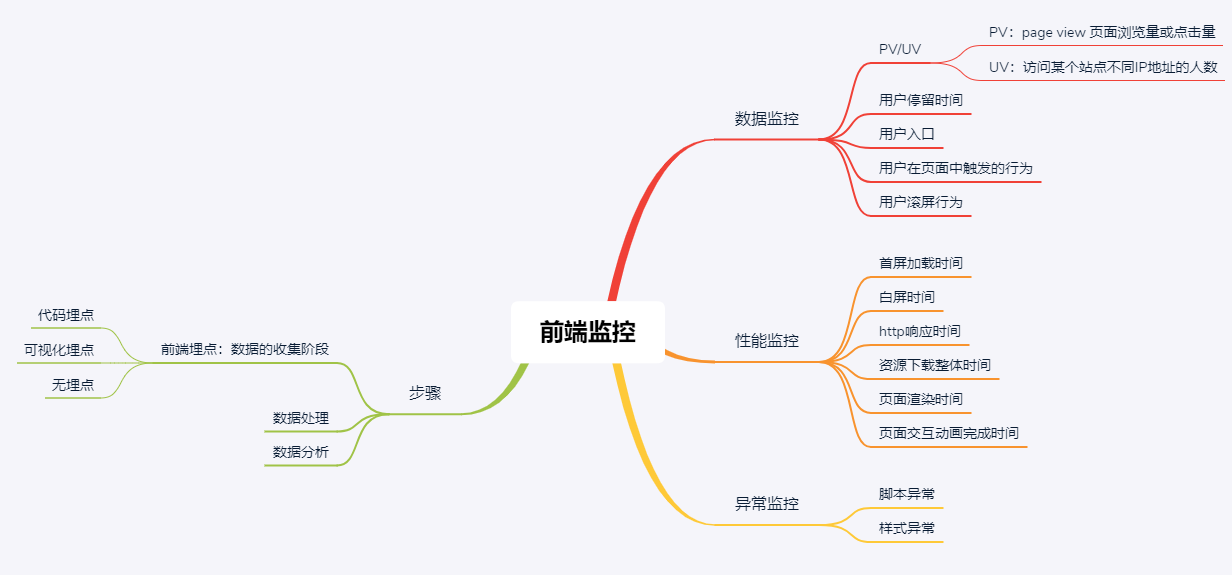
数据监控可以知道用户的来源,可以促进产品的推广,知道用户在页面中停留的时间,可以针对停留较长时间的页面进行广告推送等,增加推广源。
性能监控可以让开发人员更好的对产品进行有效的优化操作,增强用户体验。
异常监控可以及时上报异常情况,可以避免线上故障的发生与减少故障带来的损失。
常见工作流程如下:
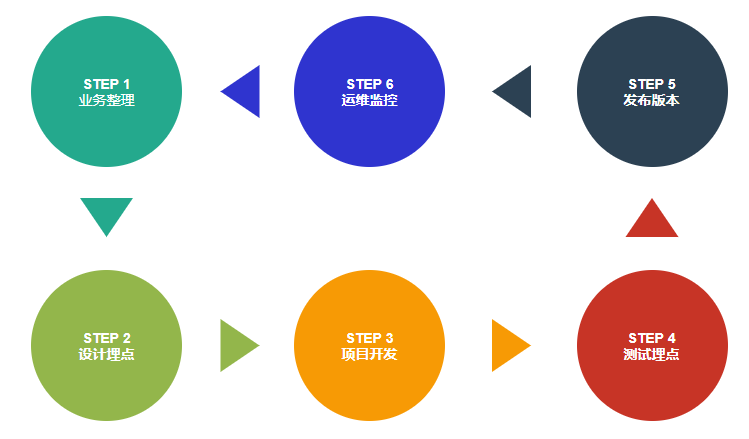
前端数据采集
前端数据采集也就是前端埋点和上报,前端埋点方法有三种:代码埋点,可视化埋点和无痕埋点。 埋点的技术实质,是先监听软件应用运行过程中的事件,当需要关注的事件发生时进行判断和捕获。
代码埋点
代码埋点就是以嵌入代码的形式进行埋点,例如用户通过点击事件触发某个接口调用,我们就可以在点击调用的接口中,插入一段代码或者传入某些参数,将数据直接传递给服务端。 如:
- 在用户登录应用时,可以将用户信息传送到服务器,统计该用户的登录次数,或者其他信息。
- 在用户点击跳转某个页面时,可以将 from, to 路由地址传输给服务器进行统计,可以清楚知道用户的访问轨迹
优点:可以在任意时刻,精确的发送或保存所需要的数据信息。
缺点:工作量大,每个组件的埋点代码都需要相对应的添加。
{
----------------接口本身提供----------------
currentUrl,
fromUrl,
timestamp,
userAgent:{
os,
netWord,
}
----------------业务代码配置和自定义上报数据----------------
type,
appid,
data:{
uid,
uname
},
...
}
可视化埋点
通过可视化工具配置采集节点,在前端自动解析配置并上报埋点数据,从而实现所谓的“无痕埋点”,代表方案是已经开源的 Mixpanel,可以从 这篇文章 了解 Mixpanel 的使用。
优点:埋点只需业务同学接入监控,无需在开发中插入代码。
缺点:可配置组件有限,不能手动定制,只有可视化工具提供。
无埋点
无埋点不是说不需要埋点,而是所有的前端事件都被绑定一个标识,通过这个标识把所有有关的事件都记录下来,不需要开发人员添加额外代码。 通过定义上传记录文件,配合解析文件,将数据变成我们想要的数据,并由数据分析人员进行分析实现无埋点统计,代表方案是国内的 GrowingIO。 GrowingIO 并不是免费的,在开发测试可以有一个免费的账号使用,如果项目正式上线后就需要收费了。
优点:无需开发,业务人员埋点即可;先上报,后埋点。
缺点:sdk 开发人员需提供一套无痕埋点技术成品,包括能正确获取 PV,UV,Action,Time 等多项统计指标。前期技术投入大。
无埋点和可视化埋点均不需要开发支持,仅数据业务同学进行设置即可。但两者数据上报-埋点设置存在较大的差异:无埋点支持在数据上报之后再进行埋点设置,因而数据采集与上报的量远远大于可视化埋点。
何时进行监控
介绍了上面三种埋点方式,那我们在产品项目中如何去运用呢?什么时候进行埋点,什么地方进行监控呢?
其实监控时间分为三部分:
- 用户进入应用初始化
- 用户在应用中的交互与交互后的响应
- 用户在应用中所触发捕获的错误
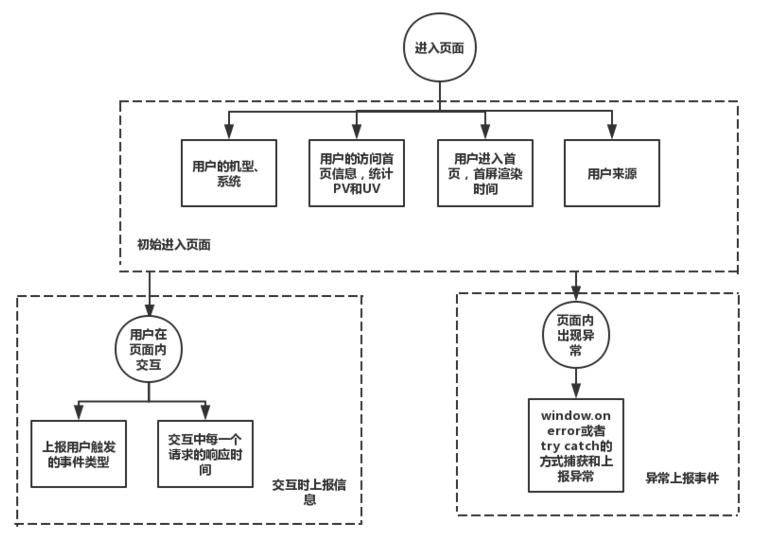
如何设计监控
如何设计我们产品所需要监控的数据? 我们需要考虑 Web 端真实用户体验数据,从访问速度、页面运行稳定性和服务调用成功率三个方面监控前端的健康度,来不断的升级迭代我们的产品。
可通过以下几个方面进行细分:
-
页面性能日志:网络请求耗时、DOM 解析耗时、资源加载耗时、白屏时间、页面完全加载时间等...
-
访问统计日志:统计 PV、UV 数据
-
页面稳定性日志:监控页面脚本的错误率来衡量页面的稳定性
-
接口调用日志:提供接口调用结果及耗时等相关信息,可以让开发人员快速发现并定位出错的问题
-
自定义上报日志
如何优化监控数据的上报
在添加完监控数据后,可能会增加接口请求或者页面渲染的压力,这时我们就需要优化我们的前端监控代码或者请求的接口。
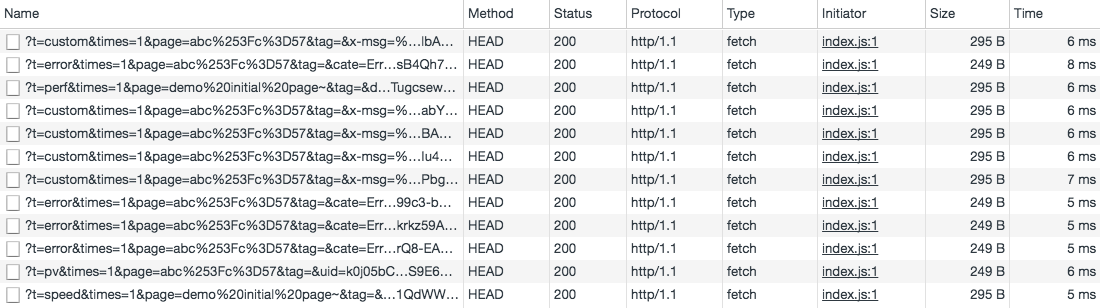
HTTP No Content
有的日志上报只关心日志是否有上报,而不关心上报的数据,如:监控用户点击某个按钮触发次数,这个我们只要上报服务器一个事件即可,完全不需要有返回内容。所以我们使用 HTTP HEAD 上报的方式,可以避免响应体响应数据而造成的资源损耗,只要有一个请求状态码记录就可以。
fetch(`${url}?t=click&page=foo&target=btn`, {
mode: "no-cors",
method: "HEAD",
});
HTTP 2.0
HTTP 2.0 头部压缩
每次的 HTPP 请求中都会携带一些相同的请求资源及特性,如 HOST、user-agent、Accept 等。这些数据占用 300-800 byte 的传输量,如果还携带 cookie ,请求头可能占据 1 kb 的空间,而实际所需要上报的日志数据仅占 50 byte。 在 HTTP 1.x 中,每次日志上报请求头都携带了大量的重复数据导致性能浪费。
而 HTTP/2 头部压缩采用 Huffman Code 压缩请求头,并用动态表更新每次请求不同的数据,从而将每次请求的头部压缩到很小。
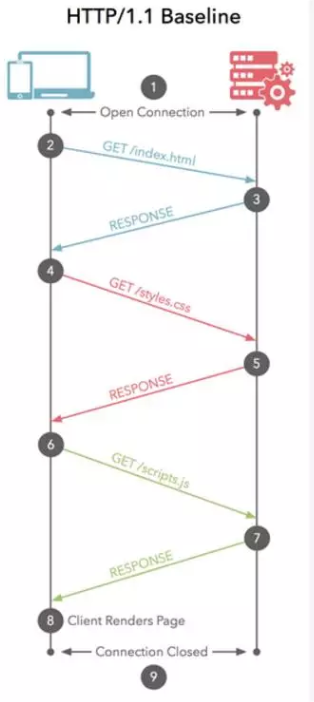
HTTP/1.1
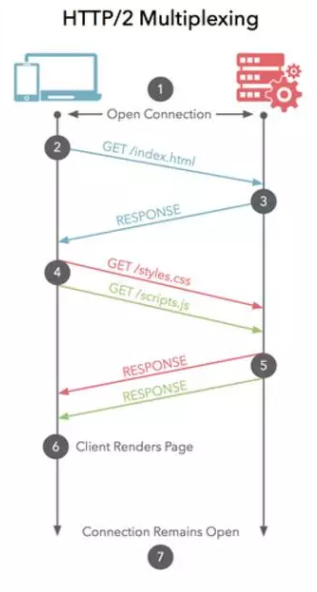
HTTP2
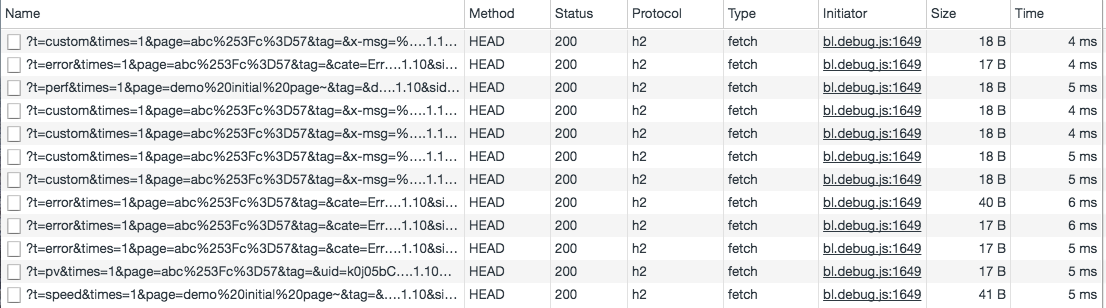
HTTP 2.0 多路复用
用户浏览器和日志服务器之间产生多次 HTTP 请求,而在 HTTP/1.1 Keep-Alive 下,日志上报会以串行的方式传输,并让后面的日志上报延时。
然而 HTTP 2.0 使用了多路复用,能够合并上报,节省网络链接开销。
总结
在本文中介绍了以下几点:
- 什么是前端监控:统计用户在使用该产品的行为与使用情况
- 为什么需要前端监控:更好的进行产品的迭代与升级,指明产品优化的方向,检验功能是否达到预期
- 何时进行前端监控:用户在进入应用、用户在应用中的交互以及用户在交互中的报错
- 如何设计监控:以页面性能、访问量、页面稳定性、接口调用情况等方向入手
- 如何优化监控与数据上报:只传请求头部,无需返回值;采用 HTTP 2.0 的头部压缩与多路复用特性
在设计前端监控时,我们需要多方面去考量,在不影响业务性能的前提下,完成我们的监控。 即使是在业务访问量较大或者性能要求较高的情况下,我们也需要做好前端监控,这是我们产品开发与迭代必不可少的一部分,也是我们产品提升与自我佐证的方法之一。
参考资料
站在巨人的肩膀上看得更远
